
图像特征注意力与自适应注意力融合的图像内容中文描述
2021-09-18 06:21孔东一
计算机应用 2021年9期
赵 宏,孔东一
(兰州理工大学计算机与通信学院,兰州 730050)
(*通信作者电子邮箱kdongyi@163.com)
0 引言
图像内容描述主要工作是通过计算机视觉(Computer Vision,CV)识别图像内的实体、实体属性及实体间的关系,然后利用自然语言处理(Natural Language Processing,NLP)技术生成一段合理的描述语句。图像内容描述属于多模态任务的一种,通过计算机视觉与自然语言处理技术的交叉融合,从而实现图像到文本描述之间的跨模态转换[1]。当前国内外的图像内容描述研究工作,根据技术类型主要分为三类:基于模板的方法、基于检索的方法和基于深度学习的编解码方法。
计算机视觉与自然语言处理领域借助于深度学习的快速发展,使得图像特征提取和语句生成效果大大提升,基于深度学习的编解码方法进行图像内容描述,其效果已经远远超过前两种图像内容描述方法,因此本文使用基于深度学习的编解码方法进行图像内容描述研究。
图像由实体、实体的属性以及实体间的关系组成,例如图1 中有一个男人正在骑一匹棕色的马,“男人”和“马”是实体,“棕色”是“马”的属性,“骑”就是“男人”和“马”之间的关系,实体间的关系等这类信息隐含在图像结构中,不易被网络模型检测和识别。Jiang等[2]研究表明人类在处理隐含信息时可以吸引并引导注意力。Bahrami 等[3]研究表明人类的注意力可以调节隐含信息所引发的大脑活动。因此,人类在对图像进行描述时,在重点关注图像实体对象的同时也会合理地关注实体间的关系等类似的隐含信息。现有文献中,通过引入注意力机制来将文本描述中的词语对应到图像中相应的区域,从而提高文本描述的生成效果,但是存在以下问题:1)人类在描述图像时,更加关注图像中的重点内容,同时会合理地关注隐含信息,现有模型如自适应注意力[4],虽然对实体及实体属性等重点内容进行了重点关注,但该方法是通过忽略或降低了对某些隐含信息的注意力关注换取的,会导致一些内容的关注信息减弱或缺失。2)现有工作中,图像特征注意力机制[5]虽然可以均等地关注图像实体、实体属性及实体间关系等内容,但是并没有考虑对图像中重点内容对象进行加强关注。

图1 图像的实体、实体的属性以及实体间关系Fig.1 Entities,properties of entities and relationship between entities in an image
如表1 所示,由于上述问题,现有模型在对图像进行中文描述时,会出现重点内容如图中颜色、对象动作等识别错误,以及未重点关注到图像内主体对象如图中生成的描述未关注到图中的草莓,而是关注了大棚内后方蔬菜形状的物体上。

表1 注意力信息缺失或减弱及重点内容未加强关注Tab.1 Attention information weakening or missing and not focusing on key content
针对上述问题,本文首先通过图像特征注意力来关注图像中实体、实体属性及实体间的关系等内容,然后使用自适应注意力机制来对图像内的重点对象进行加强关注,使得在突出图像中重点对象的同时合理地关注图像中的隐含信息,模拟人类在描述图像时对图像的关注度,从而更加精准地提取图像内的主体内容,使描述语句更加合理准确。
1 相关工作
Mao 等[6]提出了一种多模式递归神经网络(multimodal Recurrent Neural Network,m-RNN)模型。该模型首次将卷积神经网络(Convolutional Neural Network,CNN)与RNN 结合,解决了传统的基于模板和基于检索方法对图像进行描述时,生成的描述语句存在生硬、单一且受限于数据集文本等问题。Vinyals 等[7]提出了NIC(Neural Image Caption)模型,该模型使用长短期记忆(Long Short-Term Memory,LSTM)网络替换m-RNN 模型中的RNN,增强模型的长期记忆能力,显著地改善了图像描述的生成效果。上述工作利用编码-解码结构,通过CNN提取图像语义特征信息,经过RNN解码后生成图像描述语句,得益于深度神经网络的特征提取能力和自然语言生成能力,使得生成的描述语句结构合理、通顺自然。
文献[6]的NIC 模型不同于文献[7]的m-RNN 模型,m-RNN 模型在RNN 解码的每个时刻,都将图像特征信息输入到模型中,因此容易放大图像噪声,引起过拟合问题;NIC 模型在训练每张图像时,图像特征信息只输入一次,在循环训练每个词语时,图像特征信息完全依靠LSTM 的长期记忆,该模型虽然解决了过拟合问题,但是会由于LSTM 长期记忆的减弱问题,而导致图像特征信息逐渐减弱。为解决上述图像内容描述研究中出现的问题,Xu 等[5]借鉴来自于机器翻译领域的注意力机制,在编码-解码结构的图像描述模型基础上,加入图像特征注意力机制对模型进行改进。图像特征注意力机制将描述文本中的词汇与图像中每个特征进行权重计算,生成一个带有权重信息的图像特征向量,解码网络每一时刻接收不同权重的图像特征信息,从而解决过拟合及图像特征信息减弱的问题。
文献[5]中通过图像特征注意力机制在图像特征与词语之间建立注意力关注机制,但是该模型并未考虑对实体及实体属性的突出关注。Lu 等[4]建立了自适应注意力机制,通过引入视觉哨兵对文本词汇在图像中的重要度进行计算,由视觉哨兵决定最终的预测词汇是使用语言模型直接生成,还是使用空间注意力对词向量进行注意力权重计算后生成。Anderson 等[8]使用Faster R-CNN 代替CNN 对图像进行目标检测,进而识别出图像中的实体并进行注意力关注。但是上述两个模型在注意力关注时,会忽略某些实体、实体属性及实体间的关系,造成图像注意力信息的缺失,导致模型不能很好地学习到图像与词汇间的映射关系,影响图像描述生成效果。
2 注意力融合的图像内容中文描述模型
2.1 图像内容中文描述模型框架
本文提出的图像特征注意力与自适应注意力融合的图像内容中文描述模型框架如图2 所示。在训练时,将原始图像进行图像预处理后,送入预训练的CNN 中得到图像特征向量;图像文本描述语句使用分词工具进行分词,将分词后的词语进行汇总统计并去除低频词语,为每个词语进行唯一编号后形成词典表,然后使用词典表将所有图像文本描述语句进行编号形成数字序列;使用Word2Vec工具以词嵌入的方式对上述数字序列进行文本向量化,形成高维度词向量矩阵;将上述图像特征向量与词向量一起送入图像特征注意力模块中,从而计算得到带有权重信息的图像特征语义向量,紧接着将其送入LSTM 网络进行解码预测得到当前时刻的隐藏状态,该隐藏状态中蕴含着词向量对图像特征的注意力视觉信息以及语句间的语义信息;然后将生成的隐藏状态送入自适应注意力模块,以自适应方式对当前时刻不同区域图像特征的关注度进行动态调节,从而实现图像特征重点内容的加强关注;最后模型利用SoftMax 算法来将生成的词向量概率矩阵还原为文本语句。在测试时,将测试图片经过预处理后送入模型预测得到描述语句,利用评价算法计算得分。

图2 图像内容中文描述框架Fig.2 Framework of Chinese image captioning
2.1.1 编码器网络
模型中Encoder 部分使用预训练的ResNet152 作为图像特征提取网络,ResNet 网络作为大规模视觉识别竞赛ILSVRC2015的冠军,在网络中引入残差结构解决了梯度消失问题[9],网络层深度可以达到152 层,在图像特征提取和识别效果上有着非常高的准确率。本文将ResNet152 网络的倒数第二层输出大小为1×1的平均池化层和最后一层全连接层替换成一个输出大小为14×14 的平均池化层,最终得到图像特征向量的维度为2048×14×14,这里将得到的图像特征向量Va用式(1)表示:

其中:vi∈R2048是图像特征向量中任意位置的图像特征;k表示图像特征的个数。
为了使自适应注意力模块的图像特征与LSTM 输出的隐藏状态ht维度匹配,使用带有ReLU(Rectified Linear Unit)激活函数的全连接层进行维度调整,通过式(2)~(4)计算输入到自适应注意力模型的图像特征向量Vb。

其中:∈Rm,m为LSTM 输出的词向量维度大小;Wy为全连接层需要训练的权重参数;by为全连接层需要训练的偏置参数。
2.1.2 解码器网络
模型中Decoder 部分使用LSTM 对图像特征进行解码,LSTM 由经典的RNN 改进而来,解决了RNN 中的梯度消失和长期依赖问题[10],传统LSTM网络结构如图3(a)所示。

图3 传统LSTM与改进LSTM的网络结构示意图Fig.3 Schematic diagrams of traditional LSTM and improved LSTM network structures
LSTM通过三个门控单元来对网络中的信息进行控制,计算过程如下:
首先,利用式(5)的输入门it来控制网络需要存储和处理的信息。

其中:Wi为输入门的权重参数;bi为输入门的偏移参数;σ为Sigmoid 激活函数;ht-1为t-1 时刻网络的短期记忆输出;xt为t时刻网络的输入。
然后,利用式(6)计算长期记忆ct,通过式(7)的遗忘门ft来控制网络丢弃无用信息,为t时刻网络的中间量用式(8)表示。

其中:Wf为遗忘门的权重参数;bf为遗忘门的偏移参数;Wc为中间量的权重参数;bc为中间量的偏移参数;⊙表示矩阵元素相乘。
最后,利用式(9)的输出门ot来控制短期记忆ht的输出,如式(10)所示。
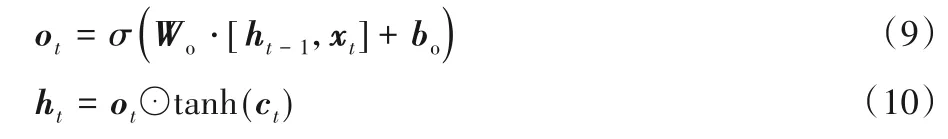
其中:Wo为输出门的权重参数;bo为输出门的偏移参数。
图像特征注意力计算生成的带有注意力权重信息的图像特征信息与数据集标签中的词向量融合后作为解码器的输入信息,因此解码器的LSTM 中存储了图像隐藏信息和语言语义信息,在传统LSTM 中加入一个新的门控单元gt,用于提取这些信息,如图3(b)。从而在LSTM 中提取出新的输出,包含图像和语义的隐藏信息st,用于自适应注意力模块的输入,计算过程如式(11)~(12)所示。LSTM 的隐藏信息ht和st中虽然都包含有图像特征注意力信息和语言语义信息,但是st会通过训练过程更加匹配自适应注意力的自适应调节任务,而ht主要用于最后的词向量的计算输出。

其中:Wg和bg为新增加门控需要学习的权重参数和偏置参数。
在t0时刻,将图像特征Va进行加权平均并通过单层感知机训练,作为LSTM 启动输入信息c0和h0,计算过程如式(13)~(14)所示。

其中:finit,c和finit,h为单层感知机计算函数;vi为式(1)中的图像特征;k表示图像特征的个数。
2.2 图像特征注意力与自适应注意力融合
2.2.1 图像特征注意力机制
通过图像特征注意力将训练集的文本描述的词汇信息映射到对应的图像特征区域,计算过程如下:
首先计算时刻t图像特征各个区域的注意力权重,通过式(15)的多层感知器(MultiLayer Perceptron,MLP)来耦合图像特征区域vi和解码器LSTM 上一时刻输出的隐藏信息ht-1。将上述计算结果送入式(16)所示的softmax 函数来计算t时刻第i个图像特征区域的权重值φti,可以得到图像各个区域的权重分布φt,权重分布的和为1,即=1,这些权重分布代表了t时刻的词向量信息对图像各个区域的关注程度。

其中:Wf_att、We、bf_att和be为多层感知机需要学习的权重参数和偏置参数;vi为式(1)所表示的图像特征;k表示图像特征的个数。
然后通过式(17)将上述计算的权重分布φti施加到对应的图像区域,其中阈值λt用来让注意力模型集中关注图像特征中的目标,如式(18)所示,最后得到t时刻带有权重信息的图像特征向量qt。

其中:L为图像特征区域的个数;Wβ为阈值λt需要学习的权重参数。
2.2.2 自适应注意力机制
利用自适应注意力机制从图像特征Vb和LSTM 里蕴含有图像特征注意力的隐藏信息ht中提取出加强注意力信息et;通过自适应的方式来调节图像和语言语义的隐藏信息st与自适应注意力信息et之间的依赖比例,从而达到对图像特征中的重点内容再次加强关注的目的。计算过程如下:
首先通过式(19)~(21)计算自适应注意力的加强关注信息et,为自适应注意力提供图像中的注意力信息。

然后利用式(22)中的视觉哨兵模块βt,来自适应地调节该注意力机制的输出rt,从而决定rt是更加依赖基于自适应注意力加强关注后的信息et,还是更依赖基于图像特征注意力提取的隐藏信息st。

其中:st在式(12)求得;视觉哨兵模块βt计算过程如式(23)~(24)所示。

其中:式(24)表示βt取自向量∈Rk+1的最后一个元素由语义隐藏信息ht和图像隐藏信息st融合而来。
2.2.3 注意力融合机制
基于人类在图像描述时的注意力机制,本文将图像特征注意力和自适应注意力进行深度融合,如图4所示。
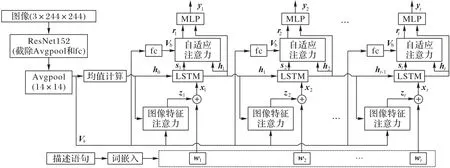
图4 注意力融合机制示意图Fig.4 Schematic diagram of attention fusion mechanism
首先将上述图像特征注意力生成的带有权重信息的图像特征向量qt与文本描述词嵌入后的词向量wt进行向量拼接,得到LSTM的输入xt,如式(25)所示。

其中:{;}代表将两个向量进行拼接。
然后把拼接后的向量xt送入LSTM,预测出当前时刻的LSTM 的图像及语言语义隐藏状态ht和st,通过式(26)融合为,用来指导自适应注意力的视觉哨兵模块,从而自适应地调节对图像产生注意力的加强程度,决定某个图像区域中是否更依赖于再次提取的图像加强关注信息et。如式(22)所示,当某个图像特征区域中隐藏信息st比重较大时,则该区域的图像关注信息主要由图像特征注意力提供;当加强关注信息et比重较大时,则该区域图像关注信息会在图像特征注意力基础上二次加强关注。通过上述过程,实现在图像内其他内容关注度不减弱或丢失的前提下,对图像中的主体内容进行再次加强关注。

其中:Wz和Wh与式(19)中的权重参数相同。
最后通过多层感知机MLP 将自适应注意力输出rt和LSTM 隐藏状态ht融合,然后利用softmax 函数求得模型最终输出的词向量yt,如式(27)~(28)所示。

其中:Wp、Wy和bp、by为多层感知机需要学习的权重参数和偏置参数。
不同于文献[4]中的自适应注意力模型只对图像特征内的不同内容进行不同程度的关注,这会减弱或丢失对实体间关系等隐含信息的关注度。本模型对图像特征中重点区域进行注意力加强关注,同时由于前面已经利用图像特征注意力提取了所有注意力信息,自适应注意力模型是在包含了所有注意力信息的隐藏状态st和ht的基础上,有针对性地再次加强关注,因此不会减弱或丢失对图像中隐含信息的关注,而文献[4]中LSTM的隐藏状态中并不包含图像注意力信息。
2.3 损失函数计算
本文使用交叉熵损失函数来计算模型预测生成的词向量yt与数据集中语句描述标签的词向量的损失值,通过最小化损失函数的值来对模型进行训练,交叉熵损失函数计算过程如式(29)所示。

其中:C为描述语句的长度;表示t时刻生成的词向量yt预测为的概率。
为了使图像特征注意力中的每个图像特征区域都得到关注,在损失函数中加入正则项,使得模型在解码阶段的所有时刻的任一图像特征区域权重值之和均相等,即≈1,从而使图像特征注意力所关注的每个图像区域参与到文本描述生成过程中。模型的损失函数如式(30)所示。

其中:η为正则项的参数,本文取1;k为图像特征的个数;C为描述语句的长度。
3 实验与结果分析
3.1 实验平台
本文实验的硬件平台为Intel Xeon Silver 4116 CPU@2.10 GHz 处理器,运行内存为128 GB,显卡为NVIDIA Tesla T4 GPU,显存为16 GB,软件平台使用支持GPU 加速运算的PyTorch 深度学习框架,配置NVIDIA CUDA 10.1 及cuDNNV7.6深度学习加速库。
3.2 数据集及评价指标
为了验证本文模型的有效性,选取在图像内容中文描述领域涉及场景最全面、语言描述最丰富、规模最大的ICC 数据集[11]进行实验。数据集中训练集、验证集和测试集分别有210 000 张、30 000 张和30 000 张图片,每张图片对应5 句中文语句描述,如图5所示。

图5 ICC图像内容中文描述数据集示例Fig.5 Examples of ICC Chinese image captioning dataset
为客观评测模型性能,本文使用广泛用于图像内容描述领域的BLEU(BiLingual Evaluation Understudy)[12]、METEOR(Metric for Evaluation of Translation with Explicit ORdering)[13]、ROUGEL(Recall-Oriented Understudy for Gisting Evaluation with Longest common subsequence)[14]和CIDEr(Consensusbased Image Description Evaluation)[15]作为评价指标,为本文模型和对比模型计算评价得分,从而客观评价模型的语句描述生成效果。值得注意的是,CIDEr 评价指标是专门设计用于客观评价图像描述任务的指标,本文将在对比其他评价指标得分基础上,重点分析CIDEr评价指标得分差异。
3.3 实验参数设置
在图像预处理时,将数据集原始图片大小缩放至256×256 像素大小,在模型读取图片时,进行15°随机旋转,并对图像进行随机裁剪,得到224×224 像素大小的图像。在描述语句预处理时,采用“jieba”分词工具对数据集中的描述文本进行分词,对分词后的描述词汇进行汇总统计,将大于低频阈值的词汇形成词汇表,本文选取的低频词汇阈值为5,最终得到7 768 个词汇。解码器中的LSTM 输入的词嵌入向量维度、输出维度、图像特征注意力和自适应注意力层维度大小均设置为512,在生成词向量时,使用Dropout 技术[16]防止模型过拟合,Dropout取值为0.5。
模型训练阶段,使用Adam[17]优化算法对模型参数进行优化,批训练大小为64;初始学习率为0.000 1,每轮次训练结束后,若模型在验证集上评价得分连续3 个轮次没有增长时,将学习率衰减0.1;为防止梯度爆炸,在反向传播时进行梯度裁剪。在模型训练起步阶段,首先固定编码器网络的参数,训练到模型在验证集评价得分不再增长时,对编码器参数进行微调,使编码器和解码器进行联合训练。
3.4 实验结果及分析
训练过程中,每轮次训练结束后,在验证集进行推理预测并计算评价指标得分,每轮次得分结果绘制曲线如图6 所示,保存验证集上评价得分最高的模型,在训练结束后在测试集进行测试。在图6 中第10 轮次得分有明显的跳跃式增长,因为模型解码器刚开始的参数是随机初始化的,并不具备有效的解码能力,为防止产生的误差反向传播到编码器,刚开始训练时固定编码器中预训练的ResNet 网络参数。当验证集评价得分不再上升时,说明解码器已经具备模型解码能力,并且达到解码器参数优化的瓶颈,此时进行ResNet 网络的参数微调,让预训练的编码器更加适应本模型的任务,因此模型评价得分迅速增加。

图6 模型各轮次评价指标得分Fig.6 Evaluation index scores of models in each round
为验证模型的有效性,本文使用相同的实验环境,分别搭建基于自适应注意力和基于图像特征注意力的图像内容描述模型,在ICC 数据集进行模型对比实验,实验评价得分结果如表2 所示。从表2 可可知,在图像内容中文描述任务上,单一的图像特征注意力比自适应注意力模型性能要好;相较于单一的基于自适应注意力和基于图像特征注意力的模型,本文模型进行注意力融合后,模型识别性能大幅提升,尤其是CIDEr 评价指标,分别提升10.1%和7.8%,说明本文模型有效提升了图像内容描述任务的性能。

表2 不同注意力机制模型下的评价指标得分对比Tab.2 Comparison of evaluation index scores under different attention mechanism models
本文还与图像描述领域具有权威代表性的研究工作进行了对比,表3为对比结果。

表3 本文模型与其他模型的性能对比Tab.3 Performance comparison of proposed model with other models
表3 中:Baseline-NIC 模型[11]使用NIC 模型对其公开的ICC 数据集进行性能测试的结果。基于自底向上和自顶向下(Bottom-Up and Top-Down,BUTD)注意力的图像描述模型[8]使用Faster R-CNN 提取图像内的实体对象,该模型的实验结果为文献[18]在ICC 数据集上的复现结果,结果表明在图像内容中文描述任务上,BUTD 模型在BLEU、METEOR 和ROUGEL 评价指标上优于NIC 模型,但是CIDEr 评价指标逊色于NIC 模型。全局注意力机制模型[18]在BUTD 模型基础上加入了全局注意力机制,结果表明该模型的CIDEr 评价指标上有优化提升,其他指标与BUTD 模型持平。相较于以上三种模型,本文模型评价指标得分均有大幅提升,分别提升10.9%、12.1%和10.3%。
除此之外,本文还进行了主观对比实验。如表4 中第一个实例,自适应注意力模型成功识别出实体对象“草莓”,但是由于对衣服颜色属性的注意力信息减弱,将白色衣服识别为红色;图像特征注意力由于没有注意力的重点关注机制,将注意力重点关注到了图像后方蔬菜形状的物体上,并没有重点关注实体对象“草莓”;第二个实例,自适应注意力和图像特征注意力模型在图像内的行为描述出现错误,本文模型成功描述出“下棋”这一行为动作;第三个实例,自适应注意力和图像特征注意力模型并没有将注意力聚焦到“喂”这个隐含信息上,因此两者描述没有抓住图像重点,本文模型合理准确地对该图像进行了描述。由对比效果可知,本文模型相较于单一注意力模型能够生成更加准确、质量更高的图像中文描述语句。

表4 各模型描述效果在实例中的主观对比Tab.4 Subjective comparison of different model description effects for examples
4 结语
本文提出一种图像特征注意力与自适应注意力融合的图像内容中文描述模型,通过图像特征注意力对图像特征进行全面关注,然后使用自适应注意力对图像特征重点区域再次加强关注,很好地模拟了人类的注意力过程,提升了模型对图像的关注和理解能力,使模型对图像的内容描述性能大幅提高。最后将本文模型与单一注意力模型进行了对比实验测试,并与其他前沿的图像描述方法进行对比,实验结果表明本文模型相较于其他模型性能提升明显,图像的内容识别更加准确,描述语句更加合理。
猜你喜欢
心理学报(2022年5期)2022-05-16
新高考·高一数学(2022年3期)2022-04-28
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
当代陕西(2020年17期)2020-10-28
当代陕西(2019年5期)2019-03-21
人大建设(2018年5期)2018-08-16
证券市场红周刊(2018年3期)2018-05-14
21世纪商业评论(2018年3期)2018-03-02
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
