
基于企业知识图谱构建的实体关联查询系统
2021-09-18 06:21余敦辉
计算机应用 2021年9期
余敦辉,万 鹏,王 社
(1.湖北大学计算机与信息工程学院,武汉 430062;2.湖北省教育信息化工程技术研究中心(湖北大学),武汉 430062;3.武汉城市职业学院计算机与电子信息工程学院,武汉 430061)
(*通信作者电子邮箱369921179@qq.com)
0 引言
伴随互联网的迅猛发展,为满足用户信息获取的需求,查询和搜索系统的应用日趋普及。但是,目前查询系统大多建立在关系型数据库的基础之上,通过用户输入的检索词返回查询到的网页、图片、音视频等数据资源。而使用关系型数据库存储数据所存在的问题:一是在查询层面,图这种数据结构具有强大的语义表达能力,而传统的关系数据库在处理“图”型数据上却存在着诸多困难,针对表结构数据去做图结构层面的基于关系、属性的关联计算,导致在时间和空间的开销均比较大;二是存储层面,关系型数据库存储的数据量越大,对查询速度的影响就越明显,而且关系型数据库难以适应有实时性的数据关系;三是在数据展示层面,图数据库返回结果是图结构的知识,不需要额外的数据处理开销,就可以直接在页面上做图形渲染,实现知识图谱的可视化展示。
因此,考虑到近年来发展迅猛的图数据库在存储关系数据上的优势,本文从应用角度出发,以实际开发项目——企业信用认证服务平台为项目背景,分析并设计了基于知识图谱的外贸企业查询系统,并在此基础上提出一种实体关联的查询方法。
本文的主要工作如下:
1)针对现有的关系型数据库数据,设计一种自动化构建方法,根据图数据存储规范,生成节点关系映射图,完成表数据到图数据的转换,并实现数据实时更新;
2)提出了一种基于实体关联的查询方法,该方法同时考虑实体之间的属性和关系两类语义信息,并采用分层过滤模型提高查询效率,在查询速度和过滤性能上均有明显提升。
1 相关工作
在知识图谱的构建方面,目前国外许多机构都构建了千万级甚至上亿级的大规模知识图谱,如DBpedia、Freebase、GraphDB、Wikidata、WordNet、Yago 等;与此同时,国内也出现越来越多成熟的知识图谱产品,从早期上海交通大学构建的zhishi.me 知识库,到百度的知识图谱开放平台、搜狗的知立方、OpenKG中文知识图谱、Ownthink通用知识图谱等,越来越多的国内平台也已经投入到知识图谱的研究中,为开展知识图谱的各方面研究提供了数据支持。关于知识图谱构建的研究[1-2],已经有比较成熟的理论基础,而目前针对关系型数据库的表数据构建知识图谱也有比较成熟的方法,包括本文使用的Neo4j 也有自己的构建工具,但是还无法完全解决数据同步更新的问题。一般来说目前绝大多数商业平台主要还是以关系数据库存储为主,用户进行操作后,需要将数据更新到图数据库中,更新时需要考虑实体链接、实体消歧等问题,以及在更新时存在增、删、改等多种情况,因此结合实际项目的关系型数据库数据来构建知识图谱仍然具有很大的研究价值。
在知识图谱查询和搜索方面,目前主要研究搜索意图的理解以及实体搜索两大方面的内容,通过实体搜索可以发现更多相关实体或展示实体间的属性和关系。近年来,国内关于知识图谱相关的研究日益增多,李阳等[3]研究了知识图谱实体相似度计算的通用方法,为知识图谱查询和计算提供了参考依据;王鑫等[4]研究了目前知识图谱可视化查询领域主流的方法和技术,为知识图谱的可视化提供了理论支持;张玲玉等[5]和赵展浩等[6]分别从节点相关系数、图的拓扑结构两个方面来实现对图谱的查询,虽然在查询性能上实现了优化,但是查询时间较长,实时性较差;杨荣等[7]和苏永浩等[8]设计并实现了知识图谱查询系统,但是并没有发挥图数据库的强大的计算能力来进一步改进查询性能。目前知识图谱的查询[9-12]手段主要是以节点相似度[13-18]作为衡量标准,查询时会将相似度最高的实体作为返回结果,因此加强查询的语义关联性是研究重点。
2 系统整体构建流程
本文所实现的企业知识图谱的实体关联查询系统框架如图1所示,按构建流程顺序主要分为以下3个方面:

图1 系统框架Fig.1 System framework
1)企业知识图谱的构建:本文主要研究的知识图谱构建方法是根据图数据库的存储格式标准,定义节点属性和关系,并建立节点关系映射图,通过自动化脚本完成传统关系型数据库的表数据转化为图数据库的图数据任务。
2)基于实体关联的查询方法:构建好图数据库后,基于关联分析的查询会查询数据库中与目标实体在结构或属性上相似的图集合。在本文所实现的企业查询系统中,将节点相似度作为衡量企业关联度的一个标准,在此基础上,为了解决查询语义程度不高的问题,该方法不仅考虑了节点本身属性,还考虑了不同节点之间的关联关系,以此来发掘出与目标企业关联度最高的多家企业实体。本文实现的关联查询方法使用一种改进的相似度相关系数来进行计算,该方法将查询图中的特征提取出来,构建特征向量或特征集合,如果特征集合的维度相同,则考虑使用Jaccard、Overlap 等相关系数的计算;如果特征集合的维度不同,则考虑使用Cosine、Pearson等相关系数的计算。通过相关系数公式计算两个实体之间的相似性之后,再通过动态阈值完成对查询集合的过滤,就可以得到与目标节点相关联的查询结果集。
3)知识图谱前端可视化展示:本文使用节点链接的方法实现图谱的可视化表达,它将本体表示为互连节点,用点或圆等形状表示节点,节点间的边用连线表示,当前端获取到服务器发送的数据后,会按照图的数据格式标准,将数据以图的形式展示出来。同时在Web 端使用数据驱动文档(Data-Driven Documents,D3)为知识图谱数据构建力导向图物理模型,当用户拖动或者数据变化时,浏览器自动进行渲染,实现动态调整数据的排布。
3 系统架构设计与实现
3.1 外贸企业知识图谱的构建
要使用知识图谱作企业关联分析,首先需要构建知识图谱,本文以平台中查询所涉及到的表作为数据源,将传统关系型数据库中的表转化为图数据库的图结构数据。通过Python的pandas 库来对数据作预处理,使处理过后的数据满足图数据库存储的格式规范;再通过Python 的py2neo 库和pymysql库分别与图数据库neo4j 和关系型数据库mysql 进行连接,建立数据库通信管道,将数据从关系型数据库导入到图数据库中,最终构建出外贸企业的知识图谱。
其中企业知识图谱构建步骤如图2 所示,具体的构建步骤如下:

图2 外贸企业知识图谱构建步骤Fig.2 Steps for constructing knowledge graph of foreign trade enterprise
1)数据预处理:首先将企业信用认证平台中存储在关系数据库中的相关表TB_ENTERPRISEINFO_FUSE(企业信息融合表)和TB_COMPANY_REGISTER(公司注册信息表)去除掉数据类型为BLOB、CLOB 等非必要字段、敏感字段以及空数据较多的数据行,将数据以逗号分隔值(Comma-Separated Values,CSV)格式导出,最终导出约11万家外贸企业数据。
2)定义实体和关系,分析表字段之间的关系,根据表字段定义构建的知识图谱的实体和关系如下:
a)实 体:企业(enterprise)、地区(region)、出口国家(country)、企业类型(enterprise_type)。
b)关系:位于(locate)、出口(export)、类型(type)。
3)数据导入:通过Python 读取到CSV 格式数据后,根据上述的实体和关系对生成实体关系映射图,将数据格式化为py2neo 库中的Node、Relation 类数据,分别作为实体和关系类数据存储到图数据库中,并在本地日志中记录构建信息。
4)数据同步:以上为通用构建过程,之后程序会根据本地的图数据库构建日志信息,判断是否是第一次构建,是则会进行定时监听,通过表的时间戳字段和日志的时间比较检查是否有新的数据,完成数据同步。
最终构建的知识图谱存储的节点与关系信息如图3所示。

图3 外贸企业图数据库查询界面Fig.3 Foreign trade enterprise graph database query interface
3.2 外贸企业关联查询方法
企业关联查询从实体本身和实体之间的关联关系两个维度去考虑,计算出目标企业实体和待查询的企业实体之间的实体关联度和关系关联度,通过求和公式得到总的关联度得分,最终根据关联度得分的高低,筛选出得分最高的K(K>0)家企业作为查询的结果集,并返回给用户。
该企业关联分析总体分4个阶段:
1)路径过滤阶段。通过限制节点的公共关系个数将关联程度较低的节点先过滤出来,用来初步确定与目标企业有一定关联度的候选集,减少计算量,提高查询性能。
2)关系发掘阶段。根据实体之间的关联关系计算基于关系的关联度,同时设定关系阈值T1,将候选集中满足关系关联度>T1的查询实体筛选出来,作为查询候选集。
3)实体发掘阶段。将查询候选集作为输入,根据实体的本体标签计算基于实体的关联度,同时设定实体阈值T2,对候选集作进一步筛选和过滤。
4)总关联度排序阶段。根据关系关联度和实体关联度来对查询候选集中的实体进行总关联度计算,按总关联度得分高低进行排序,将排序后的结果作为查询结果集。
最终该企业关联分析计算方法流程如图4所示。

图4 关联分析计算流程Fig.4 Association analysis calculation flow
3.2.1 路径过滤阶段
当图数据库存储到百万甚至千万的数据量时,对每一个查询节点都进行关联分析会产生巨大的计算消耗,这就会使方法的时间复杂度大大提高,从而导致对企业的关联分析计算不再适用于对实时性要求比较高的外贸企业查询系统。所以在企业关联分析前先通过路径过滤方法快速过滤,用来初步筛选出一个待查询集合。
路径过滤阶段通过图的路径搜索方法快速找到和查询节点之间的关系路径,并计算路径的个数,则可以得到路径个数即为两个不同节点之间总的公共关系个数,并且以公共关系个数作为过滤条件,过滤出查询候选集。该过滤条件是下一阶段关系发掘阶段的充要条件,原因有两点:一是如果无公共关系,则可以近似认为两实体的关联度为0;二是如果两个节点之间的公共关系个数很少,则可以认为两实体之间的关联度较低,不在查询集合范围之内。如果关联节点之间满足至少有N(N>0)条公共关系的节点,则N越大过滤效果越好,以此来保证搜索到的节点能满足过滤条件。
由上可定义路径过滤阶段的过滤方法如图5 所示,记目标节点的自身关系个数为self以及与查询节点的公共路径个数为U,考虑到不同节点的self和U都不相同,则取U>self/2作为过滤条件。如图5所示,假设查询的目标企业节点有3个邻居节点,则自身关系个数为3,与目标关联的企业节点的公共路径个数为2 满足过滤条件,而非关联节点的公共路径个数为1 即不满足过滤条件。这样通过路径搜索过滤就大大减少了待计算的查询实体,提高方法效率和查询的实时性。

图5 路径过滤阶段的过滤方法Fig.5 Filtering method for path filtering stage
3.2.2 实体关系发掘阶段
根据企业的外贸出口、所在地区以及企业类型三种关联关系作为关系发掘的条件。首先设定过滤阈值,若待查询企业计算出的关系关联度大于该阈值,则将该企业作为备选结果集中的一个。针对不同种类的关联关系,所采取的计算方法也不同,在计算关联度时需要考虑三种关系的权重值。
由上可定义关系发掘的计算方法:将目标企业节点记为q,待查询企业节点记为g,计算权重表示为wi,两个节点所对应的关系集合记为Rq和Rg,其中集合中所对应的外贸出口、所在地区以及企业类型三个关联关系分别为Rq1、Rq2、Rq3和Rg1、Rg2、Rg3。则两节点的关联相似度得分可表示为:

在传统相似度的查询过滤方法中,一般会定义阈值作为过滤条件,设关系发掘的阈值为T1,那么过滤的不等式就可以表示为sim(q,g) >T1,但是在本系统中考虑到不同节点之间的三种关系总和存在差异,阈值应该不是唯一的,所以定义企业查询过滤的动态阈值Tdynamic随节点关系总数n的变化而变化,可以得到公式:

最后,总的过滤不等式就可以表示为:

如果查询的企业满足以上过滤条件,就将该查询企业作为查询候选集中的一个。
3.2.3 实体属性发掘阶段
经过关系发掘后,再对以上备选结果集中的企业进行本体发掘,根据备选结果集中企业节点的标签属性,包括成立时间、注册资本、注册地址以及公司名称一共4 个标签属性,其中标签属性的数据类型分为数值类型、日期类型、字符串类型,那么根据标签数据类型分别作不同的关联度计算,来综合进行实体关联度评价,设定实体关联相似度的阈值为T2,若计算的关联度小于T2,则将该企业从备选结果集中删除。
由此可定义本体发掘的计算方法:将目标企业节点记为q,待查询企业节点记为g,根据实体属性数据类型,记目标企业节点q数值类型、日期类型、字符串类型的标签分别为Lnum、Ldate、Lstring;待查询企业节点g数值类型、日期类型、字符串类型的标签分别为Lnum'、Ldate'、Lstring'。
则对数值型标签属性的关联相似度得分计算公式可表示为:

对日期型标签属性,可以考虑先将日期转化为时间戳的格式,即当前日期与指定日期所相差的毫秒数,此时日期型标签属性就转化为数值类型值,再通过以上数值型标签的关联度计算公式计算得到日期型的关联度得分Scoredate(q,g)。
对字符串类型标签属性,考虑使用莱文斯坦距离进行计算和度量,莱文斯坦是一种文本编辑距离的计算方法,它针对两个不同文本之间的直接差异程度制定量化规则来进行量测,量测的方式是看至少需要多少次编辑操作才能将其中一个字符串变成另外一个字符串,允许的编辑操作一般包括单个字符的替换、插入和删除操作。记两个文本之间的莱文斯坦距离为Distance(Lstring,Lstring'),且该值不等于0,则所有备选结果集中的最小莱文斯坦距离可表示为Min({d:Distance})。最终字符串类型标签的计算公式可表示为:
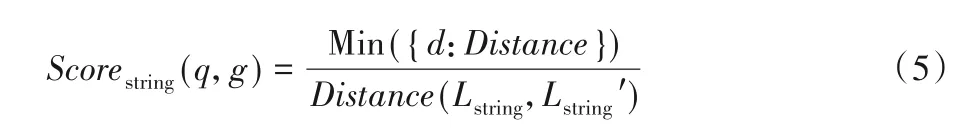
综合上述三种类型的标签关联度公式,可以得到总的标签关联度公式为:
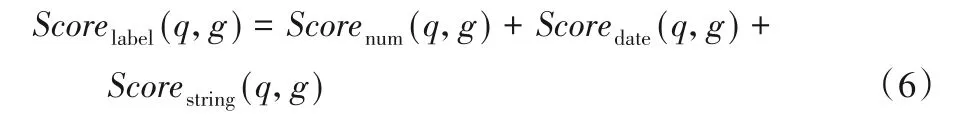
3.2.4 总关联度排序阶段
在最终的结果集中,结合本体发掘的关联相似度和关系发掘的关联相似度,对每个节点计算总得分后再进行排序,获得最终排序后的结果集,并返回给用户。
通过企业关联查询的整体流程可以发现,关系发掘阶段决定了查询候选集合的大小,在计算总关联度得分时应占据更大的比重,而本体发掘则只影响查询候选集的总关联度得分,所以记关联度比重分别为α、β(其中α+β=1,且α>β),则总关联度得分公式可表示为:

3.3 查询系统的前端可视化实现
知识图谱的可视化是数据可视化技术中的一个分支,它能够直观地将实体之间的关系给展示出来。在系统查询到关联数据后,需要利用可视化技术将查询到的数据显示到浏览器上,目前Web 前端有很多主流的可视化图形库,本次前端可视化选用D3 实现,它是一个JavaScript 的函数库,底层是通过可缩放矢量图形(Scalable Vector Graphics,SVG)来完成绘图任务,D3 将有关SVG 绘图的操作封装起来,使开发人员可以更好地注重于图表的布局和逻辑。
知识图谱是基于节点和链接关系的,目前有很多关于知识图谱的可视化方法,其中力导向图是节点链接可视表达中的一种,通过绑定节点、关系两类数据来进行渲染,每一个节点数据都会随机在浏览器上某坐标处生成一个圆形,在根据关系数据在两节点间绘制线段来描述关系,绘制完成后通过模拟两节点之间的牵引力,在斥力和引力的作用下,节点就从原本的随机无序布局不断位移,最后逐渐趋于平衡有序的布局。
根据力导向图原理,通过D3库将查询到的数据进行可视化展示,最终在浏览器显示的外贸企业知识图谱片段如图6所示。

图6 外贸企业知识图谱前端可视化片段Fig.6 Front-end visualized fragments of knowledge graph of foreign trade enterprises
3.4 系统查询结果展示
本文实现的外贸企业查询系统使用了JavaScript 的Node环境完成前后端开发工作,前端采用D3+Ajax 实现数据交互和图谱的可视化展示工作,后端采用koa2 框架为前端提供数据接口服务,并完成外贸企业的关联分析计算任务。
该查询系统是在实际项目的基础上,针对外贸企业查询这一功能所实现的Nodejs前后端分离项目。系统整体构建流程如下:
1)确定系统开发技术,包括前后端框架技术选型、图数据库存储、编程环境、开发工具和后台服务器。
2)完成结构化数据到图结构数据的转化以及图数据库的构建过程。
3)前后端联调,实现整体查询展示功能一体化。
根据构建流程成功运行系统服务之后,用户在页面输入查询内容时,前端会通过Ajax 向后端请求数据,后端服务器会自动查询关键词对应的目标企业和与目标企业相关联的其他企业信息作为结果返回,前端接收数据后将结果展示给用户。
以查询玉环某设备有限公司为例,最终后台查询结果及前端展示效果如图7所示。

图7 查询结果展示Fig.7 Query result display
4 实验与结果分析
4.1 系统环境
本文所实现的查询系统运行的具体硬件环境为:Intel Core i5-8300 CPU@ 2.30 GHz,GeForce GTX 1050 GPU,20 GB RAM,操作系统为Windows 10;具体软件环境为:开发语言为JavaScript,集成开发环境使用Visual Studio Code 的V1.49.2版本来编写代码,后端采用Node 的V12.18.2 版本实现关联查询功能,图数据库采用Neo4j的3.5.6版本来存储图数据。
4.2 实验结果与分析
本文选用了企业信用认证平台中约11 万条外贸企业测试用数据作为实验样本,构建了基于Neo4j 的图数据库,在此基础上根据节点自身的关系数来衡量节点的关联强度,并将企业节点分为弱关联节点(节点关系数小于10)、中等关联节点(节点关系数在10~20)、强关联节点(节点关系数大于20),根据节点分类情况,对每一类节点随机抽取10 家企业实体做关联查询,计算不同参数下的平均过滤性能,并和目前常见的查询方法比较过滤性能和查询时间。
图8 单独测试了路径过滤阶段随着查询节点和候选节点的公共关系N的变化,所得到的过滤结果集大小,由图8 的实验数据可以说明,按照一定的公共关系数作为过滤条件,可以过滤掉大部分的无关节点,减少无关节点的计算消耗和时间消耗。
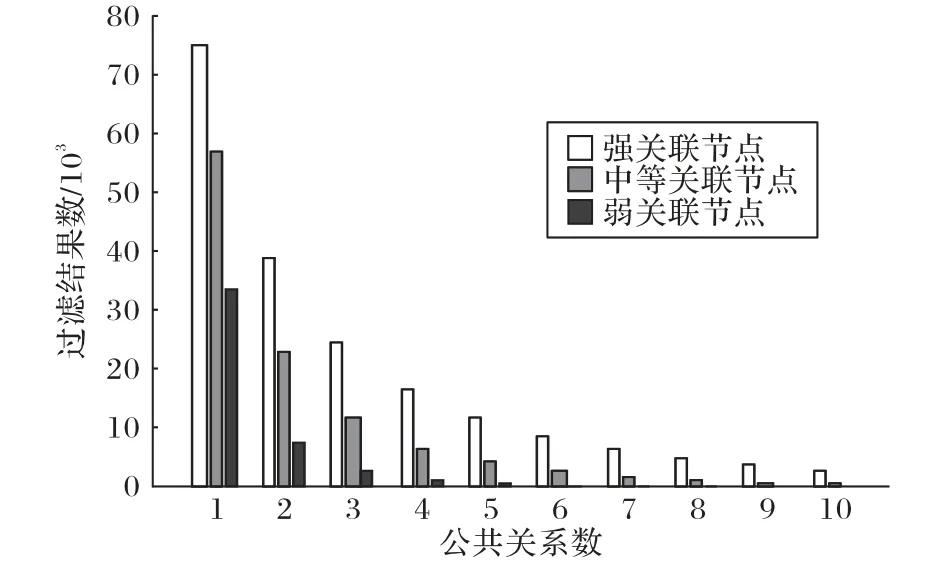
图8 过滤阶段公共关系数对过滤性能的影响Fig.8 Influence of the number of public relations in filtering stage on filtering performance
图9 单独测试了关联查询中关系发掘阶段的过滤性能,在原有的动态阈值T的基础上,每次变化间隔为0.05,记录不同的阈值所得到的过滤结果集大小。从图9 可看出,在动态阈值T附近的过滤性效趋于平稳,并且能够较好的过滤查询结果。

图9 动态阈值的变化对过滤性能的影响Fig.9 Influence of dynamic threshold change on filtering performance
图10 考虑了关系发掘阶段在极端情况下的过滤性能,极端情况指的是查询节点的公共关系数小于关系类型个数(本实验有3 类关系:locate、type、region),展示了针对动态阈值和传统过滤方法中使用静态阈值过滤的效果比较,可以看到极端情况下使用动态阈值的过滤性能明显要好于静态阈值。
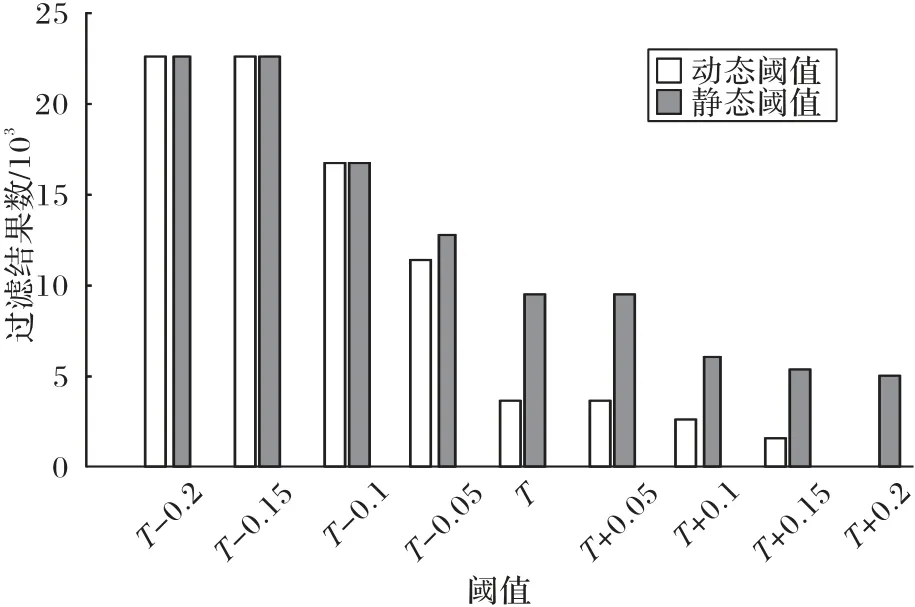
图10 极端情况下不同动静态阈值的过滤性能对比Fig.10 Comparison of filtering performance of different dynamic and static thresholds under extreme conditions
接下来,将本文系统的关联查询和仅单独使用Jaccard、Overlap 两种节点相似度计算方法进行对比,测试并比较了三种方法所得到的过滤结果数和查询时间,结果如图11~12 所示。横轴同样按查询节点的关系数分为弱关联节点、中等关联节点、强关联节点来比较,图11指出使用4层过滤的关联查询在查询效率上普遍优于其他方法,同时图12 指出关联查询和Jaccard 查询的过滤性能要明显比使用Overlap 计算关联程度更好,并且由于关联查询在本体发掘阶段考虑了节点本身的属性,会重新计算关联程度,这样就避免了在某些候选节点的关系关联度达不到阈值的情况下,使用Jaccard 计算后查询结果集过少甚至为0的情况。

图11 不同关联程度时三种方法查询时间对比Fig.11 Comparison of query time of three methods in different degrees of relevance

图12 不同关联程度时三种方法查询结果集个数对比Fig.12 Comparison of numbers of query result sets of three methods in different degrees of relevance
最后,为了验证方法的有效性,将该关联查询方法分别运行在关系数据库和图数据库上,同时选取基于邻居向量的Ness[19]方法和基于标签相似度的NeMa[20]两种代表性的图匹配查询方法与实体关联查询方法做性能对比,实验结果如图13~14所示。Ness 方法采用迭代验证,先进行标签匹配,再计算查询节点与目标节点的匹配开销;NeMa方法结合了节点标签和邻居结构计算相似度,来匹配相似节点。由于本文图谱的节点没有二路邻居,所以两个基准方法均以一路的邻居节点来进行实验。实验结果表明,关联查询方法并不适用在关系数据库上,在过滤性能相同的情况下,查询的时间开销较大,不适合应用在实时性要求较高的查询系统。在与两种基准方法的对比下,虽然查询关系数少节点的查询效率高于两种基准方法,但是由于极端情况下关系数多的查询节点对标签信息的计算增加,导致关联查询对强关联节点的查询时间要明显优于两种基准方法,最终查询时间相较于两种基准方法平均降低了28.5%;同时由于关联查询结合了属性和关系信息,其过滤性能在三种类型的节点上均优于两种基准方法,平均提高了29.6%。综合以上两点可以得出,采用四个阶段的关联查询不仅有更快的查询响应速度,而且查询的过滤性能也更强。
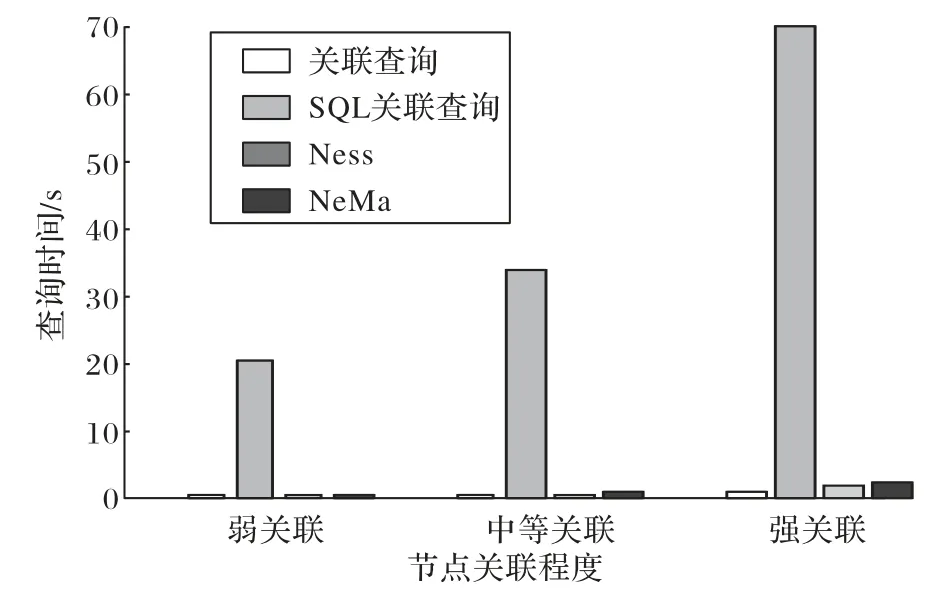
图13 不同关联程度时方法查询时间对比Fig.13 Comparison of query time of methods in different degrees of relevance

图14 不同关联程度时方法查询结果集个数对比Fig.14 Comparison of numbers of query result sets of methods in different degrees of relevance
5 结语
本文在知识图谱查询问题的研究中,以实际项目——外贸企业信用认证服务平台为背景,首先基于现有的关系型数据库数据构建企业知识图谱,然后提出了针对企业实体的关联查询方法,实现发掘与目标企业相关联其他企业的功能,可以为企业提供更多有价值的信息,促进企业之间的贸易与合作。
通过实验数据对比,验证了本文提出的查询方法在过滤性能和查询效率上均优于传统图查询方法。未来本文将进一步考虑加入更多的实体属性和关系来完善企业信息,降低数据噪声,并在原有查询的基础上加入更多的特征,提高查询的准确性。
猜你喜欢
体育科技文献通报(2022年4期)2022-10-21
中草药(2022年17期)2022-09-05
北京航空航天大学学报(2022年8期)2022-08-31
重庆大学学报(2022年2期)2022-02-28
建材发展导向(2021年19期)2021-12-06
计算机仿真(2021年6期)2021-11-17
智能计算机与应用(2020年4期)2020-08-31
智富时代(2019年2期)2019-04-18
智富时代(2019年2期)2019-04-18
新城乡(2018年6期)2018-07-09
