
TACLeBench中内核程序循环级推测并行性分析
2021-09-18 06:22孟慧玲王耀彬王欣夷刘志勤
计算机应用 2021年9期
孟慧玲,王耀彬*,李 凌,杨 洋,王欣夷,刘志勤
(1.西南科技大学计算机科学与技术学院,绵阳四川 621010;2.四川省计算机研究院,成都 610041)
(*通信作者电子邮箱wangyaobin@foxmail.com)
0 引言
当前多核平台加速串行程序时,存在数据依赖限制以及资源利用率低等问题[1-2],线程级推测(Thread-Level Speculation,TLS)技术[3-4]可开发出更多可用的线程级并行性,保证程序正确性的同时,提高程序性能,成为有效利用多核处理器的途径之一。该技术将需要执行的串行程序分为一个非推测线程和多个推测线程,使多个线程并行执行[5];同时保持程序的原始顺序,打破线程间的数据依赖对线程并行执行造成的影响,减少程序执行时间,提高加速比。
威斯康星大学首次将Multiscalar[6]作为线程级推测方案提出后,各种不同的线程级推测方案开始陆续出现。例如斯坦福大学研发的Hydra 技术方案[7]、Hammond 等[8]提出的TCC(Transactional Coherence and Consistency)技术方案、卡内基梅隆大学提出的STAMPede技术方案[9]等。目前,刘斌等[10]提出了一种基于性能推测的线程循环选择方法,最终Olden 基准测试集加速比性能平均提升了12.34%;李美蓉等[11]提出了一种自适应的循环并行粒度调节方法,提升了SPEC CPU 基准测试集性能,并减少了推测开销;Salamanca 等[12]对硬件事务内存(Hardware Transactional Memory,HTM)支持与线程级推测(TLS)的循环并行化的应用进行了详细分析,并描述了在此类机器中HTM 上实现TLS 的仔细评估,实验结果表明,某些循环加速比可达到3.8。可以看出,TLS技术已在多种串行程序并行化工作中得到有效应用。
TACLeBench[13]是来自全球多个不同研究小组和工具供应商的基准测试程序集合。文献[14]使用TACLeBench 基准,通过仿真多核ARM(Advancd RISC Machine)处理器来验证mcQEMU 模拟器时间模型,实验结果表明,与四核NXP i.MX6Quad 处理器相比,mcQEMU 的时间估计误差平均仅为15%;文献[15]利用TACLeBench 基准对GCC(GNU Compiler Collection)与LLVM(Low Level Virtual Machine)进行比较,结果显示,LLVM 在88%的实验中编译速度更快,而在51%的实验中,GCC 与LLVM 产生的二进制大小几乎相同;文献[16]利用TACLeBench 基准验证设计的重用检测方法,并针对不同数据的访问进行表征,发现优化后,最坏情况下数据访问的时间可减少到6.5%。但目前,TACLeBench 内核基准仍未在线程级推测方面得到有效分析。
本文主要目的是分析将TLS 技术应用于TACLeBench 中内核基准程序时,程序循环结构在推测并行化中的性能提升潜能。在TACLeBench 用于实现小型内核功能的基准中,选取7 个具有代表性的程序,设计了一种动态剖析机制,结合核心数据结构计算循环部分读写时间,分析程序线程粒度、并行区域覆盖率、线程间数据依赖特征对程序加速比大小的影响,并综合程序加速比与资源利用率判断内核基准程序适宜处理器核心数目范围。
1 推测模型和剖析机制
1.1 推测模型
线程推测方案对象通常为程序循环结构或子程序。由于循环迭代独立性较强,可反复执行导致循环结构所需执行时间较长,并且循环结构确定线程的开始和结束相对容易[17],因此目前推测并行技术主要针对程序循环结构进行分析,本文也针对程序循环结构展开研究。
循环推测[17-18]将每个循环部分分别作为推测对象,循环推测并行执行时,只需维持一个非推测线程,其余推测线程在非推测线程执行结束后,得到非推测权限,从而成为下一个非推测线程来维护程序正确性。图1 展示了传统的串行执行方式,程序按照顺序依次执行。图2 为循环结构的推测执行方式,在推测执行过程中,当有线程产生时,头处理器首先响应该线程,并分发“Loop_Start”的信号告知其他处理器加载循环的各个迭代。当头处理器处理完当前线程后,逻辑上的下一个处理器成为新的头处理器继续处理该线程。当最后一个处理器处理完成后,会发送“Loop_End”信号结束当前线程的循环迭代执行。为保证剖析机制的速度与开销,以及开发程序线程级推测并行性,本文的推测模型为与平台无关的理想机器模型,在该模型中,线程的生成、提交和回退没有开销。

图1 串行执行模型Fig.1 Serial execution model
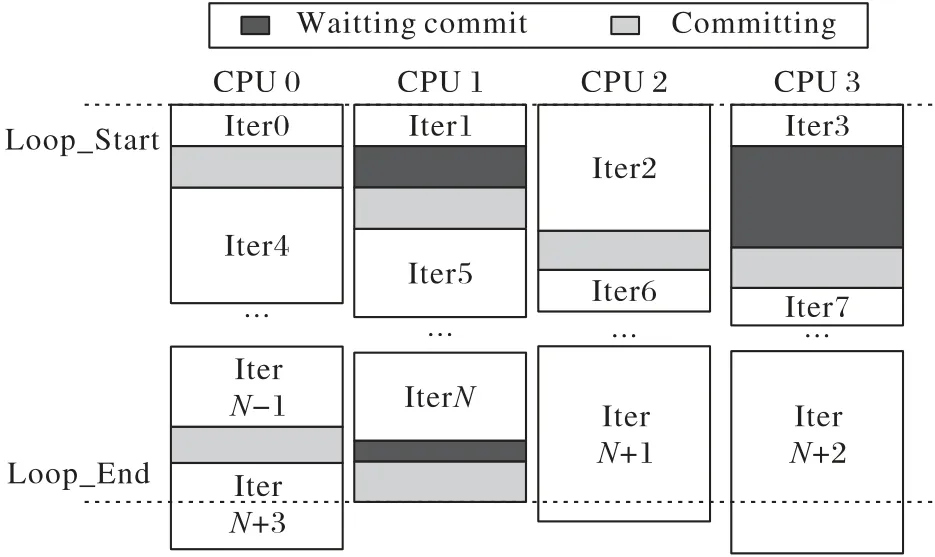
图2 循环结构推测执行模型Fig.2 Loop structure speculative execution model
1.2 剖析机制
利用剖析技术对程序运行时特征进行剖析操作能提高线程推测的成功率,在一定程度上对程序进行正确性维护,从而保证程序运行的正确性,并提高程序并行效率。该技术在程序预执行后,搜集相关信息并反馈给编译器,令编译器进行线程划分。本文设计了针对程序循环结构的剖析工具Proloop,利用该工具剖析程序可得到程序并行区域覆盖率、线程粒度、数据间依赖等信息。
本文相关剖析方案如图3 所示:首先使用GNU Prof 工具对程序进行初始化分析,得到函数运行时间,选取程序运行时间超过5%的部分为候选程序代码片段,并在其循环结构中插入剖析标识;随后使用交叉编译工具对选中的片段进行交叉编译操作,得到剖析工具可识别的文件;最后利用ProLoop对所选中的片段进行剖析,使用ThreadList链保存推测线程相关信息,hash 表保存访存操作相关信息。结合剖析所得线程粒度、线程间数据依赖程度等数据与程序源码进行对比分析后,得出综合分析结果。
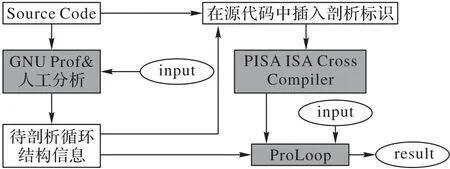
图3 循环结构剖析方案设计Fig.3 Loop structure analysis scheme design
程序循环标识如图4 所示,在程序循环结构中,插入的两个循环标识分别为profiling_loop_start 和profiling_loop_end。其中profiling_loop_start 接收循环标识以及循环变量地址,而profiling_loop_end则代表循环结构结束。在程序执行过程中,循环id被保存在4号寄存器中,循环变量地址则保存在5号寄存器中。

图4 循环标识示意图Fig.4 Schematic diagram of loop identifier
循环结构剖析的核心数据结构如图5 所示,首先将程序所有循环分解为iteration_list_entry_t,再将得到的每个iteration_list_entry_t分为多个iteration_t,该数据结构用于存储程序循环结构中的循环id、循环变量值以及循环展开开始执行与结束时间。剖析中所有热点循环串行执行的时间,与整个程序串行执行时间的比值,即为程序并行区域覆盖率。此外,hash_list 记录存储器写入操作,hash_next 记录下一次循环展开对存储器操作的地址指针,hash_pre 记录上一次循环展开对存储器操作的地址指针。当剖析工具检索到程序后续代码读取某一存储单元时,会对其进行拦截,对比该程序存储单元最后一次写入时间与当前读取时间,将当前时间设置为其中较大的一个,程序推测时间与该程序串行运行时间的比值即为程序最终加速比。

图5 循环结构剖析的核心数据结构Fig.5 Core data structures for loop structure analysis
1.3 性能影响因素
TLS 性能影响因素有推测并行区域覆盖率、线程粒度规模、线程间数据依赖等。根据Amdahl 定律,程序可并行区域覆盖率越高,最终加速比越好。线程粒度为程序一个循环迭代的指令条数,线程粒度太小会使程序能耗开销增大,过大又会使处理器缓存溢出。线程间数据依赖也是TLS重要影响因素,文献[18]将线程间依赖关系看作生产者和消费者之间的关系,如图6 所示。生产距离为线程开始执行到线程对特定内存单元最后一次写入操作之间的指令数,消费距离则是线程开始执行到线程对特定内存单元第一次读操作之间的指令数。通过程序消费距离和生产距离的比值,可以得到线程间数据依赖数值。将消费距离比上生产距离,若比值范围为(0,0.6],说明产生了数据依赖冲突,将此时的数据依赖定义为致命依赖,并且数值越小产生的数据依赖冲突越严重;若比值在(0.6,1.0]的范围内,认为此时会发生数据依赖冲突,将该依赖定义为危险依赖;若比值大于1.0,则定义为安全依赖,认为此时不会发生数据依赖冲突。

图6 生产距离与消费距离Fig.6 Production distance and consumption distance
2 实验数据分析
选取TACLeBench 的1.9 版本中用于实现小型内核功能的基准中7个具有代表性的程序,所选应用程序如表1所示。

表1 基准测试程序集说明Tab.1 Description of benchmark test programs
本实验平台为基于Linux的Ubuntu 14.04开发版本;指令集为Simplescalar工具集中的PISA(Programme for lnternational Student Assessment)指令集;编译器为Simplescalar 工具集中提供并改进的gcc-2.7.2.3;剖析器为Simplescalar的功能模拟器sim-fast修改扩充版本。
2.1 性能影响因素分析
并行区域覆盖率如图7 所示,并行区域覆盖率越高越利于使用线程级推测分析,由于TACLeBench 内核基准程序的并行区域覆盖率都为100%,因此并行区域覆盖率对内核基准程序加速比影响较小。

图7 并行区域覆盖率Fig.7 Parallel area coverage
本文所选程序线程粒度如图8 所示,大小在101~103范围内,由于Hydra 项目组提出了线程粒度最适宜的范围是在以102~104条指令为单位的规模为宜,因此设计内核程序的推测多核处理器时,推测缓存容量应比通用设计降低一个量级,以避免增大程序开销。

图8 线程粒度Fig.8 Thread granularity
线程间的数据依赖结果如图9 所示。除filterbank 以及binarysearch 致命依赖较高,其余程序致命依赖都在1%以下,程序致命依赖所占比值越高,最终得到的加速比数值越低,因此,filterbank 以及binarysearch 致命依赖过高是导致其加速比低的重要原因之一。

图9 线程间数据依赖Fig.9 Data dependency between threads
综合各程序并行区域覆盖率、线程粒度以及线程间数据依赖结果分析发现:内核基准大部分程序并行区域覆盖率较高,线程粒度适中,但大部分程序存在不同程度的致命依赖以及危险依赖。
2.2 加速比分析
本文选取TACLeBench 中7 个具有代表性的内核基准程序,对比程序在2 核、4 核、8 核、16 核、32 核、64 核和无限核下的加速比情况,分析程序在循环级推测并行化中的性能提升潜能。不同核数即为循环设置不同数量的推测线程,由空闲处理器同时加载并运行各个线程。无限核为程序同一循环结构中所有推测线程设置相同的起始时间,使所有线程同步执行。
bsort程序加速比结果如图10(a)所示,核数从2核增加到64 核时,加速比接近线性增长,64 核时,接近峰值。对其性能影响因素分析可知,程序覆盖率达到100%,线程粒度较其他程序偏高,但程序致命依赖以及危险依赖占比都为0%,因此最终程序加速比结果非常理想,达到20.79。
对lms进行剖析,所得加速比如图10(b)所示,核数在4核到64 核之间时,加速比基本稳定在2.4 左右,核数从64 核增加到无限核时,加速比突然提升。由程序源码可得,lms 运行时间占比最大的循环迭代次数远超过64 核时提供的最大推测线程数,无限核时,所有迭代才能并行执行,从而避免处理器闲置时间,因此,加速比在利用有限核加速时,加速效果不如无限核加速效果。综合实验结果分析发现,该程序并行区域覆盖率达到100%,程序线程粒度为53,由于程序运行时间占比最大的函数中,存在指针变量以及函数调用,导致程序存在致命依赖,但致命依赖占比较小,并且函数整体循环结构较多,所以该程序最终加速比结果很好。
从图10(c)可以看出,st的加速比在2核到16核之间增长幅度较大,16 核之后增长缓慢,32 核时加速比接近峰值。通过程序源码分析发现,st 为计算两个大小为1 000 的数字数组的总和、均值、方差和标准差,程序总体较为复杂,并且循环迭代次数较多。在程序运行时长稍短的函数中,存在较多指针数据结构,但运行时长占比较大的函数中没有产生依赖,因此程序没有产生致命依赖,并且危险依赖比值较少,最终程序加速比结果较好。
cosf程序加速比结果如图10(d)所示,程序在2 核到32 核之间,加速比增长较快,32 核之后,增长逐渐缓慢,程序并行区域覆盖率达到100%,线程粒度适中。对程序源码进行分析发现,程序较为复杂,尽管程序循环较少,但循环部分包含在程序运行时间占比较大的结构中,并且程序不存在指针以及循环嵌套等结构,导致cosf 的致命依赖以及危险依赖占比都为0%,因此最终加速比结果仍达到4.19。
从图10(e)可得,matrix1 在2 核到16 核之间,加速比呈线性增长,并于16 核时达到程序加速比峰值,考虑资源合理利用,对matrix1 程序应选择2 核到16 核使用以避免造成资源浪费。通过对程序性能影响因素分析发现,该程序线程粒度大小适中并且不存在致命依赖,因此程序整体加速比表现较好,但由于该程序循环迭代次数较少,16 核时分配的推测线程足以让所有迭代同步执行,因此在16 核时,便达到了程序的并行执行限度。
filterbank 在不同核数下的加速比如10(f)所示,核数由2核增加到4 核时,加速比得到了最大限度的提升,随后加速比趋于稳定,虽然该程序并行区域覆盖率达到100%,程序线程粒度为47,但程序致命依赖过高,通过对程序源码分析发现,程序循环次数较少,并且程序多个循环结构中存在函数嵌套调用,导致程序危险依赖达到63%,因此4 核之后加速比没有随着核数继续增加。
由图10(g)可得,随着核数的增加,binarysearch 的加速比没有发生改变。通过性能影响因素分析,该程序线程粒度达到515,造成其程序能耗开销较大,并且该程序致命依赖达到78%,对程序代码分析可得,该程序为15 个整数元素的二进制搜索,程序整体循环次数较少,函数运行时间占比最大的函数中不存在循环结构,此外,该函数在运行时长较短的函数循环中被调用,导致程序致命依赖严重。因此,程序最终加速效果较差。

图10 程序在不同核数下的加速比Fig.10 Program speedup ratios with different cores
利用TLS 技术对TACLeBench 内核基准程序进行最大潜能挖掘,对比各程序加速比结果,除binarysearch 外,其余程序最大加速比都在2以上,其中bsort程序加速效果最好,最大加速比超过20,通过其他方法对其进行加速[19],加速结果在5以下,因此,bsort适合利用循环级推测开发并行性。
对程序性能影响因素与加速比综合分析发现,当程序代码存在函数嵌套调用等原因造成函数致命依赖严重时,即使程序并行区域覆盖率较高,线程粒度适当,程序最终加速效果也不理想,如filterbank;对致命依赖严重,线程粒度过大的程序,使用TLS 技术基本没有加速效果,如binarysearch;对致命依赖占比较低的程序,最终加速效果也较好,如bsort、lms、st、cosf、matrix1。因此,在程序三个性能影响因素中,数据依赖影响最严重。
2.3 数据归一化分析
对本实验所有程序加速比进行归一化分析结果如图11所示,大部分程序随着核数的增加,加速比增长幅度逐渐变小。其中binarysearch 程序由于循环结构过少、线程粒度过大并且致命依赖过高导致最终加速效果较差,利用TLS 技术对其进行分析效果不理想,其余大部分程序在4 核到16 核之间加速比提升所占比重较大,因此对内核基准程序进行推测并行分析时,综合考虑性能提升与资源浪费,核心数目应尽量选择4核到16核之间。

图11 程序加速比归一化分析Fig.11 Normalized analysis of program speedup ratio
3 结语
本文利用TLS 技术对TACLeBench 中内核基准中的部分程序进行循环级线程推测分析,对比各程序加速比结果,除binarysearch 外,其余程序最大加速比都在2以上,综合加速比与各性能影响因素,总结出以下结论:
1)本文使用线程级循环推测技术可以使TACLeBench 中的内核测试基准程序性能得到较好提升,大部分程序加速结果较好,其中bsort程序加速比最好,能达到20.79。
2)对于TACLeBench,大部分程序核心数目在4核到16核之间时,加速比增加幅度在50%以上,因此内核基准在选择程序核数来进行分析时,应尽量将核数控制为4 核到16 核以避免造成资源的浪费。
本实验选取TACLeBench 内核基准中较适合作循环推测的程序进行分析,由于线程级推测也可应用于子程序分析上,因此后续将利用TLS 技术,设计针对子程序的剖析机制对TACLeBench 内核基准进行分析,并将最终加速结果与本文作对比,分析哪种推测并行方式更适合内核基准程序。
猜你喜欢
计算机应用与软件(2022年9期)2022-10-10
今日农业(2022年15期)2022-09-20
佳木斯大学学报(自然科学版)(2022年3期)2022-06-27
现代电子技术(2022年8期)2022-04-13
体育科技文献通报(2022年1期)2022-01-15
苏州科技大学学报(自然科学版)(2021年4期)2021-12-02
今日农业(2021年21期)2021-11-26
小型微型计算机系统(2020年10期)2020-10-21
价值工程(2018年3期)2018-01-23
新作文·高中版(2017年6期)2017-07-06
