
计算密集型大流量数据的接力计算与动态分流处理
2021-09-18 06:22包秋兰廖雪花朱洲森
计算机应用 2021年9期
廖 佳,陈 扬,包秋兰,廖雪花,朱洲森*
(1.四川师范大学物理与电子工程学院,成都 610101;2.四川师范大学计算机科学学院,成都 610101)
(*通信作者电子邮箱992827658@qq.com)
0 引言
随着社会的数字化转型、互联网的蓬勃发展以及国民经济的快速崛起,世界各个领域的数据呈爆炸式增长,大流量数据的处理问题引起了世界各国专家的广泛关注[1-2]。数据作为信息的载体,已经成为包括互联网经济、交通物流和社会生活等各个领域中最核心的资源[3]。在这些领域中,高效的计算能力是必不可少的条件之一。
我国在大数据计算应用领域发展迅速,主要集中在I/O密集型[4]和计算密集型[5]。目前I/O 密集型数据处理在我国应用领域先进而成熟,典型应用场景如春运期间抢购火车票、购物网站的“双十一”抢购商品、电商平台的秒杀抢购等。对于这些I/O 密集型应用,通过技术的不断革新和架构的不断优化,得到了进一步的提升和完善。但是计算密集型数据处理仍然处在发展阶段,对于大型应用的开发存在困难,主要集中在大型科学计算、省市级的社保医保数据的计算与服务、税务数据的计算与优化等方面。
对于计算密集型的应用,国内外学者在任务调度、资源分配等方面有一些相关研究。张楠等[6]提出了一种面向计算密集型任务的分布式任务调度平台,有效地提高了系统的资源利用率和稳定性。杨志豪等[7]研究了一种面向数据和计算双重密集型任务的私有云计算系统实现方案,通过对文件和并行处理模块的简化和优化,使得系统结构变得简单且方便使用。郝永生等[8]分析研究了计算密集型和数据密集型混合作业情况下的调度问题,对传统的网格作业调度算法进行了扩展,提出了三种调度算法:Emin-min、Ebest、Esufferage。Kolici等[9]从高计算需求的角度出发,介绍了利用现代高性能体系结构模拟调度和资源分配的计算密集型应用的一些研究成果。
对于计算密集型的应用,在我国目前还处于发展阶段。因此,本文提出一套计算密集型大流量数据的接力计算与动态分流处理模型。通过内存型数据存储模块中预存储信息确定计算任务的复杂等级,同时利用接力计算模块中计算节点的资源能力作为排序标准,将计算任务动态分配至指定接力计算节点并行处理,最终在数据分流模块整合计算结果,返回客户端展示,有效减轻了单服务器端的计算压力。
本文主要工作:1)采用内存型数据库预存计算参量,减少数据库对频繁使用参量的读写成本,同时内存数据库动态记录计算量与复杂度,供动态计算调节器使用;2)调节器动态调用数据存储资源(分布式数据库),将大流量的计算任务拆解为若干小任务由存储资源并行运算,并将并行运算的初步结果送往下一级处理层;3)后续两级到三级的接力处理层将复杂的计算任务并行地分层处理,将最后的计算结果以数据流的方式合并输出。
1 关键技术
1.1 微服务架构
微服务架构[10]是一种体系结构模式,它采用一组服务来构建一个应用程序,服务独立地部署在不同的进程中,可独立扩展伸缩,并且每个服务可采用不同的编程语言来实现。相较于传统的单体应用架构,微服务架构具有以下优势:
①独立部署。
由于微服务具有独立的运行进程,所以每个微服务可以独立进行部署。当某个微服务发生变化时,不需要重新编译和部署整个应用程序,大大缩短了应用的交付周期。
②降低复杂度。
微服务架构将单个模块应用程序分解为多个微服务,同时保持总体功能不变。每个服务都集中在一个单一的功能上,并通过接口清楚地表示服务边界。由于功能单一、复杂度低,小规模开发团队可以充分掌握,易于维护,开发效率高。
③技术选型多元化。
在微服务架构下,应用程序的技术选择是去中心化的,各个开发团队可以根据自身应用的业务需求开发,选择合适的架构和技术。
④容错性。
在微服务架构中,由于微服务之间彼此独立的特点,故障被隔离在单个服务中,系统的其他微服务模块可以通过重试、降级等机制在应用层实现容错,从而提高系统应用的容错性。
⑤可扩展性。
微服务架构中的每一个服务可以根据实际需要独立地进行扩展[11],充分体现了微服务架构的灵活性。
本文采用微服务架构搭建接力计算与动态分流处理模型。
1.2 非阻塞客户端WebClient
WebClient 是一个非阻塞、响应式的HTTP(HyperText Transfer Protocol)客户端工具,它以响应式流、背压的方式执行HTTP 请求。对于高并发的情况,可以利用非阻塞和响应式的特性使用少量的线程数进行处理[12]。本文利用这两个特性处理微服务各模块之间通信的问题。
采用微服务架构搭建整体框架,各个微服务模块之间如何远程进行访问服务资源是需要考虑的问题。目前,一般微服务中各个模块之间的调用有两种方式:RestTemplate 和Feign,都是采用HTTP 协议调取Restful API 的方式。但这两种方式都具有阻塞的缺点,当系统应用收到大量请求时,会造成请求堆积,响应时长增加。非阻塞客户端WebClient 的出现,可以完美解决上述问题。
本文在接力计算和数据同步过程中,各层接力计算节点利用WebClient 的非阻塞特性进行通信,传递计算和同步任务,获取处理结果。接力计算节点调用图如图1所示。

2 接力计算与动态分流处理模型
为解决现有大流量数据计算缓慢、响应时间长等问题,本文研究了一种计算密集型大流量数据的接力计算与动态分流处理模型,具有响应迅速、计算效率高、可扩展性好等优点。整个模型主要由数据分流模块、内存型数据存储模块、接力计算模块和数据存储模块四部分组成,模型图如图2所示。

图2 计算密集型大流量数据处理模型Fig.2 Computing-intensive large flow data processing model
2.1 接力计算与动态分流处理运行流程
由图2 可知,接力计算与动态分流处理模型通过四大模块之间的相互配合,共同完成大流量数据的快速计算。该模型的具体运行流程与各大模块的功能如下:
1)数据分流模块实现大流量数据的动态分流与合并。
该模块主要利用均衡算法将大流量数据均分至多个计算节点同时进行计算,计算完成后,将结果进行整合,返回至客户端进行展示。
2)接力计算模块完成大部分计算任务。
接力计算模块根据计算任务的分解方式,确定接力层数以及各层的节点数,通过各层各节点之间相互配合,完成大部分的计算任务。
3)内存型数据存储模块:微计算处理单元。
内存型数据存储模块具有读写速度快、性能好、易于扩展等优点[13],本文将具有使用频率较高、相对固定不变、已进行简单计算等特点的数据预存储在内存型数据存储模块中,方便其余三大模块在计算过程中快速读取所需数据。
4)数据存储模块:读写分离。
数据存储模块是克隆数据存储集群,采用读写分离,能有效减轻数据存储模块的负载压力[14]。其中,读取数据集中在(N-1)个数据存储端,而写入数据在N个数据存储端中并行执行。当写入数据出现错误时,进行回滚,保证存储端集群中的数据一致。
2.2 接力计算与动态分流处理模型优势
传统的大流量计算模式多为增加或升级硬件资源,譬如大型互联网企业双十一期间需要增加几千或上万台服务器,或人为拆解大流量为若干小任务,需要较长的时间完成大量的计算任务。
相较于传统大流量数据的计算方式,本文所提出的接力计算与动态分流处理模型有以下优势:
1)缓解硬件资源节点的计算压力。数据分流模块通过内存型存储模块中的数据快速确定计算任务的复杂等级X,利用均衡算法将计算任务分配至X个接力计算节点完成,有效缓解单一架构的计算压力。
2)易于扩展。本文的接力计算模块为集群式,体现为多层接力节点共同参与任务计算。上层接力节点的计算结果传递到下层接力节点继续参与计算。大流量数据的复杂运算可以利用多层接力节点异步处理计算任务,减轻传统单服务器端的计算压力。
3)数据同步。数据存储端集群采用读写分离的方式存储数据,有效减轻存储模块的负载压力;并且,通过执行SQL 捕获器的结果和引发错误后回滚的方式保证数据同步。
4)读写快速。利用内存型数据存储模块中读写数据快速的优点,将使用频率较高的数据预存储在内存型数据存储端中。
3 接力计算与动态分流处理模型设计与实现
根据接力计算与动态分流处理模型的说明,可以得到接力计算与动态分流处理模型的总体运行流程如图3所示。
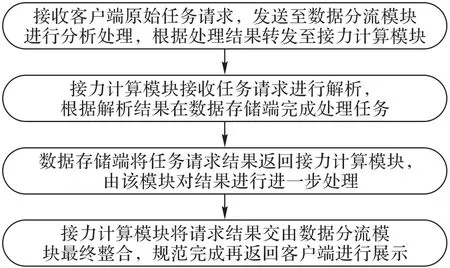
图3 接力计算与动态分流处理模型流程Fig.3 Flowchart of relay computation and dynamic diversion processing model
具体技术实现阐述如下:
1)数据分流模块对数据进行动态分流。
数据分流模块接收客户端原始任务请求,利用SQL 捕获器的结果判断任务类型。其中,增加、删除和更新操作属于数据同步任务,而读取操作属于计算任务。
SQL 捕获器的结果判定是计算任务时,先确定计算任务的复杂等级。本文将第一次请求数据的时间Tm预存储在内存型数据存储模块中,后续计算请求任务将Tm与自定义阈值时间T作对比,得到计算任务的复杂等级X:

其中:N为数据存储端的个数;Tm表示第一次请求数据时间;T表示自定义阈值时间;X表示参与计算节点数和计算任务的复杂等级;[]表示取整。
当Tm/T≤1 时,表示接力计算模块中的1 个接力计算节点得到全部计算任务Y。当Tm/T∈(1,N-2]时,使用式(2)计算每个接力计算节点获取的计算任务量R:
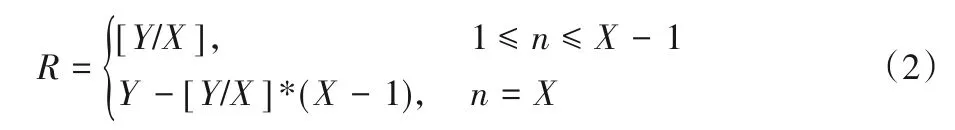
其中:n代表计算节点的编号;Y表示计算任务量。
当Tm/T>N-2,并且Y%X=0 时,使用式(3)计算每个接力计算节点获取的计算任务量R:

当Tm/T>N-2,并且Y%X≠0 时,使用式(4)计算每个接力计算节点获取的计算任务量R:
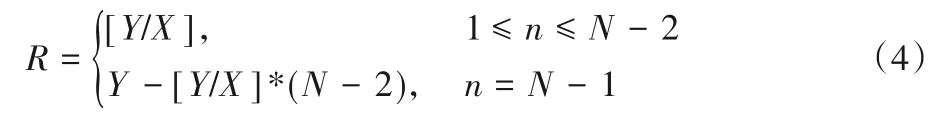
接力计算节点完成计算任务的分配时,需要先对接力计算节点进行编号。利用微服务架构中的服务发现功能获取第一层接力计算节点所在服务器端的IP 地址,通过IP 地址读取CPU 和内存使用率等信息,对节点资源能力按照从低到高进行排序,对各个节点进行编号(编号值n:1 →N-1)。每个接力计算节点分配的计算任务量R由式(2)~(4)可得。
SQL 捕获器结果判断是数据同步任务时,将SQL 捕获器结果和任务标识作为请求参数,直接转发到接力计算模块进一步处理。
2)数据存储模块实现数据提取、简单运算和数据同步的功能。
数据存储模块根据任务标识执行不同的任务,分别为计算任务和数据同步任务,以下将分为两方面进行介绍。
①计算任务。
数据存储模块执行计算任务时,将数据提取和简单运算放在该模块完成,例如查询计算人员的姓名、年龄等基本信息,可以从数据存储模块提取多位人员姓名、出生日期基本信息,通过编写的数据库函数实时计算年龄等信息。而在X个数据存储端完成计算任务时,先判断内存型数据存储模块是否存有当前所需数据,如果未保存,将数据写入内存型数据存储模块,方便后续请求从内存型数据存储模块中直接提取。计算完成后将半成品结果返回至接力计算模块进一步处理。
②数据同步任务。
数据存储模块执行数据同步任务时,N个数据存储端执行SQL 捕获器的结果(增加、删除和更新),N个接力计算节点记录执行情况并使用WebClient 相互通信。如果当前数据存储端执行成功,同时收到其余(N-1)个数据存储端执行成功的信息,接力计算节点向上一层接力处理模块返回执行成功的信息。
如果N个数据存储端中出现执行失败的情况,出错的接力计算节点使用WebClient向其余节点发送执行失败的信息,利用数据库ACID 特性[15]的原子性(ACID特性即原子性Atomic、一致性Consistency、隔离性Isolation和持久性Durability),对执行成功的模块进行事务回滚,恢复至执行前的数据状态,同时接力计算节点向上一层计算终端返回执行失败的信息,这样可以保证N个数据存储端中的数据完全相同。数据存储模块功能流程如图4所示。

图4 数据存储模块功能流程Fig.4 Function flowchart of data storage module
3)接力计算模块完成数据的大部分计算。
接力计算模块主要完成大部分的计算任务,可以自定义接力计算层数F,其中每层接力节点数m需要大于等于数据存储端数量N。
本文在确定最佳接力计算层数F时,需要对复杂计算任务完成分解。任务分解的思想在于将一个复杂计算任务通过某种方式分解为多个不同的、简单的子任务,可以将这些分解后的子任务交给多个接力计算模块完成,最终将多个模块计算完成的结果返回数据分流模块,进行整合规范。
本文在完成计算任务分解时,需先测量单机完成该任务所花费的时长。接着,将任务分解为多个无关联的计算子任务,分配至多层接力计算节点完成,记录任务完成时间。同时,考虑各模块的关联和依赖作用,将多个计算子任务合并在同一个接力节点完成,记录最终任务的完成时间。比较多种任务分解方式,得出最合理的任务分解方式,计算完成所花费的时间最短。
本文使用3层接力节点,每层接力节点包含3个接力计算节点,3 个数据存储端为例进行具体详述。接力计算模块结构如图5所示。
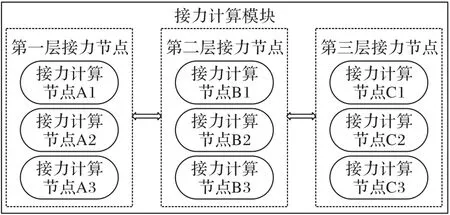
图5 接力计算模块结构图Fig.5 Structure diagram of relay computation module
数据分流模块对数据进行分流,根据式(1)确定复杂等级X的值,比如计算完成X的值为2,代表将计算任务分配至两个接力计算节点同时完成。将计算任务量划分成2 份,对第一层接力节点中3 个计算节点资源能力从高到低进行排序编号,将计算任务分配至编号1 和2 的接力计算节点完成,根据式(3)或式(4)得到每个接力计算节点分配的计算任务量R。节点资源能力计算公式如下:
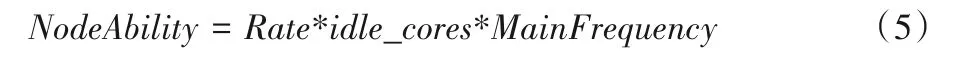
其中:NodeAbility代表计算节点的资源能力;Rate代表CPU 剩余利用率;idle_cores代表空闲CPU 核数;MainFrequency代表CPU主频。
处理数据完成后,对第二层接力计算节点资源能力按照式(5)计算后进行排序编号,转发对应编号节点的计算任务请求,比如第一层接力节点编号为1 的计算节点向第二层接力节点中编号为1 的计算节点转发请求,以此类推,第二层接力节点向第三层节点请求转发的规则也相同。节点计算结构如图6所示。
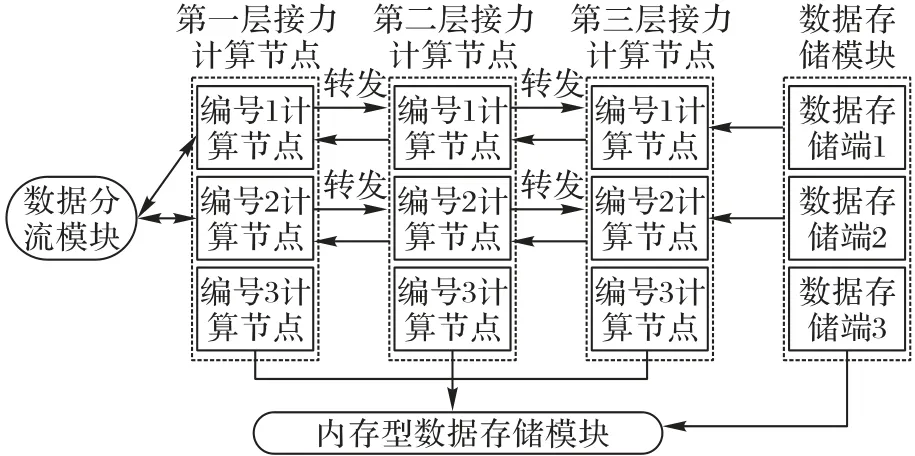
图6 节点计算结构图Fig.6 Node computation structure diagram
如上所述,请求到达第三层接力节点时,数据提取和简单运算放在数据存储模块完成,每个接力计算节点对应一个数据存储端,在计算过程中可以直接获取内存型数据存储模块中所需数据,计算完成的半成品结果在第三层、第二层和第一层接力节点中特制的计算模块进行进一步处理。第一层接力节点得到最终计算结果后,返回到数据分流模块,进行合并2个接力节点的计算结果,转换为客户端能够解析的数据类型,将整合规范后的结果返回客户端展示。接力计算模块中的各层节点之间的通信采用异步非阻塞的WebClient方式,不会阻塞后续程序运行。
接力计算模块处理数据同步任务时,计算结构图和处理计算任务时相同,如图6所示。
数据分流模块将SQL捕获器的结果和数据同步任务标识作为请求参数,转发至第一层接力节点中资源能力按照式(5)计算后进行排序编号为1 的计算节点,在解析请求参数中任务标识为数据同步任务时,将请求直接转发至第二层接力节点中资源能力也按照式(5)计算后进行排序编号为1 的计算节点,该节点接收请求后,转发至第三层中所有计算节点,在数据存储模块中并行执行SQL 捕获器结果。如前面所述,出现执行失败的情况时,3 个接力计算节点使用WebClient 相互通信,数据存储模块进行事务回滚,恢复至未执行前的数据状态。3 个接力计算节点将执行失败情况原路返回,在数据分流模块对执行情况进行整合,最终将任务完成情况返回给客户端。数据同步失败结构如图7所示。

图7 数据同步失败结构图Fig.7 Data synchronization failure structure diagram
4 测试与结果分析
本文通过计算保存在数据存储模块中的学生成绩数据,获取指定数据量的计算任务,完成对应学生总分、平均分等计算。将第一次多个计算节点请求数据的响应时间小于单个计算节点时的数据量预存储在内存型数据存储模块,后续请求数据量与内存型数据存储模块中作对比:如果超过该数据量,对数据进行分流;如果未超过该数据量,由单个计算节点完成,利用当前节点的资源能力判断任务分配至各层节点计算。
本文测试计算中,主要使用单个计算节点和两个计算节点(2 层接力节点,每层接力节点包含2 个接力计算节点和2个数据存储端)进行测试。模拟接力计算时,为简单处理只将提取学生成绩放在数据存储端完成,平均分放在第一层节点,总分放在第二层节点计算。
客户端将计算任务分配至数据分流模块,通过内存型数据存储模块中的数据判断是否进行分流,将分流请求数据量传送至第二层计算节点,提取学生多门成绩放在数据存储模块完成,将半成品计算结果以流的形式返回接力计算模块,分别计算学生的总分和平均分。计算完成,将结果返回数据分流模块进行整合,最终在客户端展示。每次客户端发送计算请求时,记录每次请求完成的响应时间。
需要说明的是,为了测试的真实性,测试在正式的生产环境进行,所以没有让计算进行同步回写存储,但不影响对模型与框架的验证与相应结论。
4.1 测试的物理环境
本文使用的物理环境包括如下:
数据分流模块运行环境:1 台Linux 服务器,操作系统CentOS-7.6 64 bit,运行内存8 GB,带宽10 Mb/s,Java 开发工具包jdk-1.8.0_181。
接力计算模块运行环境:2 台Linux 服务器,操作系统CentOS 7.6 64 bit,运行内存8 GB,带宽5 Mb/s,Java 开发工具包jdk-1.8.0_181。
数据存储模块运行环境:1 台Linux 服务器,关系型数据库管理系统MySQL 8.0.20,操作系统CentOS 7.6 64 bit,运行内存16 GB,带宽5 Mb/s,Java 开发工具包jdk-1.8.0_181。
4.2 测试结果和分析
4.2.1 运行结果
通过对不同数量级数据的多次测试,去除波动较大的测试结果后取平均值。学生成绩在单个节点和多个节点的计算完成时间的对比测试结果如表1所示。
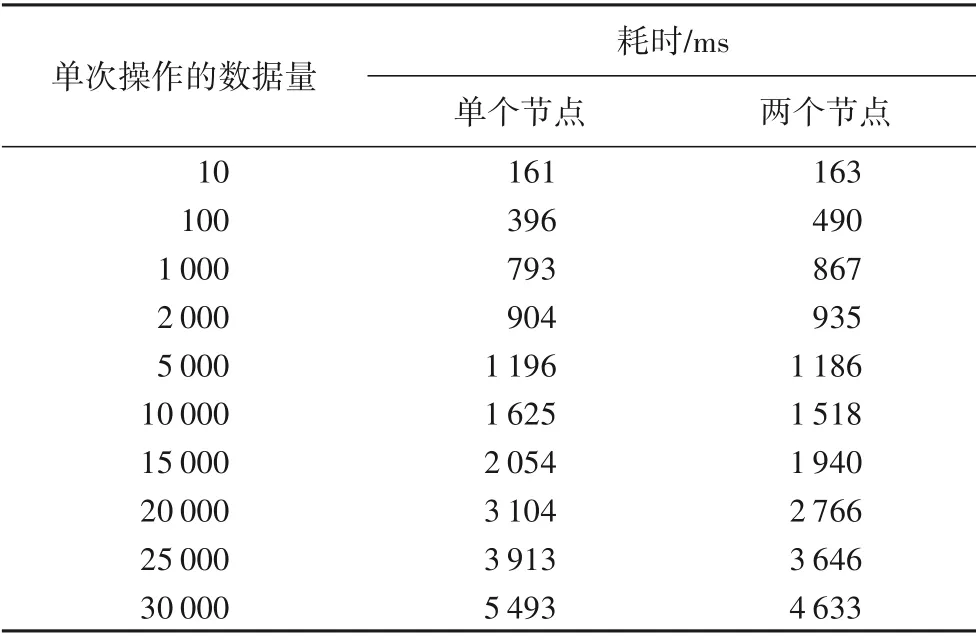
表1 单个节点与两个节点耗时对比Tab.1 Time consumption comparison between single node and two nodes
表2~3 展示的当计算请求数据量较大(30 000 条)和较小(100条)时,数据分流模块接收10次计算请求后,每次单个节点和多个节点分别从请求开始到返回计算结果的完成时间对比。需要注意的是,由于实验中服务器存在实时网络状态不同等原因,每次计算请求的完成时间是不相同的,所以表2~3展示的数据中,后续请求的完成时间可能会小于开始请求的完成时间。

表2 请求数据量大(30 000条)时的完成时间对比Tab.2 Comparison of completion time for requests with large amount of data(30 000 items)
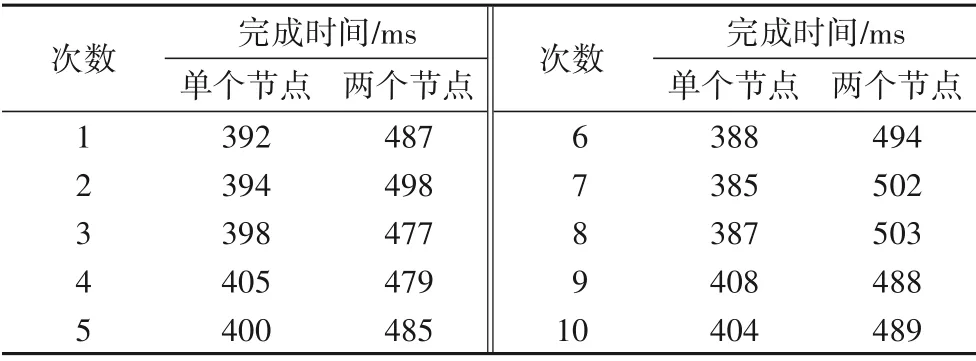
表3 请求数据量小(100条)时的完成时间对比Tab.3 Comparison of completion time for requests with small amount of data(100 items)
4.2.2 运行结果分析
根据运行的结果,分析表1~3 可知:在计算请求数据量较小的情况下,单个计算节点完成相同计算任务的时间会小于多个计算节点的完成时间;而计算请求数据量较大的情况,则刚好相反。这说明该模型的计算调节器可以通过判断请求数据量的大小来决定是否进行分流,避免在计算过程中过多资源的浪费。对于大流量数据的密集计算使用该模型可以降低运行时间,并且随着计算请求数据量的增大和计算复杂度的增加,模型的优势就越明显。并且,该模型通过三层(内存型数据存储模块、接力计算模块和数据存储模块)的接力计算,可以解决一般数据计算软件可能出现的运算速度缓慢、计算阻塞堆积等问题,也大幅减少了其中一层的运算和处理接近满负荷或积压,而另外两层出现等待或闲置的状况。通过不同数量级计算数据的测试,记录了单个节点和多个节点计算完成时间等指标,对指标数据的整理分析,说明了该模型能够显著提升数据计算的效率,对超高并发数据的处理、计算密集性数据的计算方法及类似应用场景,具有借鉴与参考性的价值。
5 结语
本文构建一种利用内存式数据存储技术为过渡,通过预存储、一体化转换、读写分离等构架与算法,探索快速处理存储模块数据的模型与构架,并着眼于通过内存式数据存储技术为枢纽,将大流量数据的计算任务,通过预加载、解耦、缓存机制等,衔接来自于动态分流进一步处理的数据,完成大流量数据的快速计算。该模型及其实现已经在实际的密集计算型的应用场景得到运用,在计算速度和资源成本方面都取得理想的结果[16]。该方案和相关技术对于计算密集型的应用领域和相关研究,都具有建设性的意义,也可降低信息化系统建设成本,实现资源充分利用。
猜你喜欢
模具制造(2022年7期)2022-08-29
北京大学学报(自然科学版)(2021年3期)2021-07-16
电脑知识与技术(2020年32期)2020-12-29
小型微型计算机系统(2020年12期)2020-12-09
电脑爱好者(2020年19期)2020-10-20
东坡赤壁诗词(2019年5期)2019-11-14
现代营销·理论(2019年10期)2019-09-10
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
奋斗(2018年4期)2018-05-14
中国知识产权(2016年12期)2016-12-12
