
基于知识蒸馏的深度无监督离散跨模态哈希
2021-09-18 06:21强浩鹏
计算机应用 2021年9期
张 成,万 源,强浩鹏
(武汉理工大学理学院,武汉 430070)
(*通信作者电子邮箱wanyuan@whut.edu.cn)
0 引言
随着图像、文本、视频等多媒体数据快速增长,不同模态间的跨模态检索近年来引起了人们的广泛关注。跨模态检索的目标在于给定一个模态查询对象,找到另一模态中语义相似的集合,如图像检索文本、文本检索图像等。为了满足现实世界中检索速度快、存储空间小的检索需求,哈希算法通过二进制哈希码表示原始数据,在近似近邻搜索[1]应用中时间复杂度可以达到常量或次线性[2],因此被广泛用于跨模态检索。
当前的跨模态哈希方法大致可以分为传统跨模态哈希方法[3]和深度跨模态哈希方法[4]。传统跨模态哈希方法利用手工提取的浅层特征学习哈希码,将训练过程分为两步:1)提取数据手工特征(如尺度不变特征变换(Scale-Invariant Feature Transform,SIFT)[5]特征);2)将手工特征投影到汉明空间。典型的传统跨模态哈希方法如跨视图哈希(Cross View Hashing,CVH)[6]基于单视图谱哈希提出将不同视图的相似样本映射为相似哈希码;语义关联最大化(Semantic Correlation Maximization,SCM)[7]通过语义相似度矩阵分解来减少样本间相似度计算时间;跨模态相似性敏感哈希(Cross-Modality Similarity Sensitive Hashing,CMSSH)[8]利用提升方法联合不同模态数据的表征与相似度,将数据到公共汉明空间的映射表示为二进制分类问题;语义保留哈希(Semantics-Preserving Hashing,SePH)[9]通过最小化模态间KL散度(Kullback-Leibler Divergence,KLD)来让不同模态数据分布相同。这些方法特征提取的过程独立于哈希码学习,因而学习到的手工特征并非哈希码的最优解。近年来,深度学习因其在特征学习方面的优异性能而广泛应用于人脸识别[10]、图像检索[11]、目标检测[12]等领域。相较于浅层方法利用手工提取的特征学习哈希码,深度跨模态哈希方法直接学习从原始数据到汉明空间的映射函数,能更有效地找到原始数据与哈希码间的潜在关联。
根据训练过程是否引入标签信息,深度跨模态哈希方法又分为有监督哈希学习和无监督哈希学习。深度有监督哈希方法如深度跨模态哈希(Deep Cross-Modal Hashing,DCMH)[13]采用端到端的神经网络框架,将特征与哈希码学习联合到一个统一的框架中,但对标签的语义信息缺乏有效利用;自监督对抗哈希(Self-Supervised Adversarial Hashing,SSAH)[14]构建自监督标签网络,并利用对抗性来缩小不同模态间的语义鸿沟;成对关系指导的深度哈希(Pairwise Relationship guided Deep Hashing,PRDH)[15]提出不相关约束来解决不同位的哈希码之间存在的冗余问题;基于三元组的深度哈希(Triplet-based Deep Hashing,TDH)[16]通过概率模型定义跨模态三元组损失,并利用图拉普拉斯来探究样本对是否相似;基于排序深度跨模态哈希(Ranking-based Deep Cross-Modal Hashing,RDCMH)[17]利用特征和标签的余弦相似度矩阵来得到一个半监督语义排序列表,并联合语义排序信息到哈希码的学习过程中。
然而在实际应用中,有监督方法[18]需要大量人工标签标注的实例,但这些标签信息的收集过程往往成本昂贵且容易出错,因而这些算法不能有效地扩展到大规模数据当中。无监督深度跨模态哈希方法通过寻找未标注实例间的关联信息来实现高效检索,在大规模数据应用中更加灵活。Wu等[19]利用图拉普拉斯约束项保护原始数据的邻域结构,提出了一种无监督深度跨模态哈希(Unsupervised Deep Cross-Modal Hashing,UDCMH)方法;Zhang 等[20]利用不同模态间的对抗性来拟合数据的流形分布,提出了无监督生成对抗跨模态哈希(Unsupervised Generative Adversarial Cross-Modal Hashing,UGACH)方法;Wang 等[21]通过引入虚拟标签来增强哈希码的辨别能力,提出了基于虚拟标签回归的无监督深度跨模态哈希(Unsupervised Deep Cross-modal Hashing with Virtual Label Regression,UDCH-VLR)方法;Su 等[22]提出了深度联合语义重构哈希(Deep Joint-Semantics Reconstructing Hashing,DJSRH)方法,构建联合语义关联矩阵来发掘模态间潜在的语义一致性,但在哈希码学习过程中放松了离散约束条件,存在较大量化误差。虽然以上方法获得了不错的检索性能,然而这些方法通过数据本身分布或预训练神经网络得到的样本相似度信息并不能完全满足其训练需求。
为解决以上问题,本文提出基于知识蒸馏的深度无监督离散跨模态哈希(Deep Unsupervised Discrete Cross-modal Hashing,DUDCH)方法,主要工作包括:
1)结合知识蒸馏中知识迁移的思想,利用预训练的无监督老师模型中实例关联信息重构对称相似度矩阵,保证了成对实例间的相似性;
2)在哈希码的学习过程中采用离散循环坐标下降法迭代更新离散哈希码的每一位,有效降低离散哈希码间的冗余性;
3)采用端到端无监督模型作为老师模型,构建了非对称有监督模型作为学生模型,能有效提高模型的运行效率。
1 相关工作
1.1 无监督跨模态哈希
无监督跨模态哈希方法可以分为浅层方法与深度方法两类。浅层无监督方法中媒体间哈希(Inter-Media Hashing,IMH)[23]利用谱哈希建立保留模态内与模态间一致性的公共汉明空间;协同矩阵分解哈希(Collective Matrix Factorization Hashing,CMFH)[24]通过协同矩阵分解将不同模态投影到联合的语义空间来学习统一哈希码;复合相关量化(Composite Correlation Quantization,CCQ)[25]联合寻找将不同模态转化为同构潜在空间的相关极大映射,并学习将同构潜在特征转化为紧凑二进制码的复合量化器;潜在语义稀疏哈希(Latent Semantic Sparse Hashing,LSSH)[26]利用稀疏编码来捕捉图像的显著结构并通过矩阵分解来得到文本的潜在概念,挖掘潜藏在数据当中的语义信息。这些方法不能有效捕捉不同模态数据到汉明空间的复杂非线性映射,因而许多无监督跨模态方法在哈希码的学习中引入深度神经网络来构建从数据到哈希码的非线性映射。
深度无监督跨模态哈希方法在相似度矩阵获取方式上有所不同。UDCMH[19]利用图拉普拉斯约束项中喜好矩阵来评价不同哈希码间相似程度,但喜好矩阵的构建依赖于采集样本分布的好坏,故DJSRH[22]利用图像深度特征与文本词袋特征的联合语义矩阵来探究不同样本间关联程度;相较于直接采用预训练神经网络来判别样本间相关程度,无监督知识蒸馏(Unsupervised Knowledge Distillation,UKD)[27]提出深度无监督跨模态哈希模型能提供更加精确的相似性度量,但在构建过程中忽视了相似度矩阵的对称性;除了直观求取样本间相似度矩阵,UGACH 和无监督耦合循环生成对抗性哈希(Unsupervised coupled Cycle generative adversarial Hashing,UCH)[28]利用不同模态间的对抗性来拟合不同模态的流形分布,但都存在着训练困难、时间复杂度高问题。
1.2 知识蒸馏
知识蒸馏首次由Hinton 等[29]提出,其主要思想是通过提取大型老师模型学习到的先验知识来帮助小型学生模型训练,有效节省了模型的计算量和计算资源,常常被用于模型压缩与部署,其具体实现则是通过最小化老师与学生模型输出的KL 散度,使得二者的分布相同。在此基础上,Furlanello等[30]发现两个同等复杂的模型有利于学生网络更好学习到老师模型传授到的知识,并通过反复迭代的方法使学生模型的性能逼近老师模型。Yang 等[31]通过适当降低老师模型的置信度和增加老师模型“容忍度”,有效提升学生模型的表现。Chen 等[32]通过匹配两个样本排名得到的概率分布来蒸馏用于深度度量学习的知识,探究不同样本之间的相似性。然而,以上方法在意同类型模型间知识的传递,UKD 关注于无监督与有监督模型间关联信息的传递,利用无监督老师模型得到可供有监督学生模型学习的样本相似度矩阵。
本文受UKD 启发,利用预训练好的无监督老师模型的实值哈希码构建实例相似度矩阵,代替标签实现学生模型的有监督学习,提出深度无监督离散跨模态哈希DUDCH 方法,但在构造上有以下几点不同:1)老师模型中将对抗无监督模型UGACH替换为端到端无监督模型DJSRH,学生模型中将对称有监督模型DCMH 替换为非对称有监督模型;2)构造对称相似度矩阵时引入判断相似程度的阈值,保证成对样本的相似性;3)哈希码学习过程中依次按位更新离散的哈希码,减小了哈希码的量化误差。具体的网络框架如图1所示。

图1 知识蒸馏网络框架Fig.1 Network framework of knowledge distillation
2 深度无监督离散跨模态哈希
2.1 符号和问题定义
O=表示图像文本对集合,X=[x1,x2,…,xn]∈Rn×w×h×3表示图像矩阵,Y=[y1,y2,…,yn]∈Rn×c表示文本矩阵,n表示数据大小,w表示图像宽度,h表示图像高度,c表示文本词袋向量的维度。S∈{-1,+1}n×n表示成对相似度矩阵,Sij表示相似度矩阵S第i行第j列的元素。当Sij=+1时,第i个实例oi与第j个实例oj为相关对;否则,Sij=-1。深度跨模态哈希的目的是找寻两个从原始数据到汉明空间的非线性映射函数:Hv,t=hv,t(X,Y;θv,t)∈[-1,+1]n×k,其中:X和Y表示图像文本数据;k表示哈希码的长度;hv,t为图像与文本学习到的哈希函数;Hv,t为图像与文本网络学习到的连续哈希码矩阵;θv,t分别为图像与文本网络的网络权重。Bv,t=sign(Hv,t)表示图像和文本网络学习到的二进制哈希码矩阵,其中:sign(⋅)表示符号函数,当;否则,=-1。
2.2 深度网络结构
为能更容易了解图1 模型的深度网络结构,本节给出训练模型的具体解释。对于图像网络,老师模型采用DJSRH 模型中的预训练深度神经网络AlexNet[33],并沿用其相同的参数设置;学生模型采用预训练的卷积神经网络CNN-F[34]。二者均包含5个卷积层和3个全连接层,在图像网络最后的输出层(fc8)中输出的节点被改为哈希码的长度k来获得连续哈希码,并用Tanh作为激活函数。
对于文本网络,DUDCH 采用三层全连接层:前两层隐藏层有4 096 个输出节点,用线性整流函数(Rectified Linear Unit,ReLU)作为激活函数,最后一层输出层有k个输出节点,用Tanh作为激活函数。
2.3 知识蒸馏
2.3.1 无监督老师模型
不同于UKD 采用对抗性老师模型UGACH,本文采用端到端无监督模型DJSRH 作为老师模型进行快速蒸馏。DJSRH 本身能够学习到一个联合图像-文本信息的余弦相似度矩阵,将作为本文蒸馏法的对照组,具体的对比将放到实验中3.4.4节进行说明。
跨模态哈希的关键在于寻找图像文本对之间潜在的语义关联信息。在一个训练良好的无监督模型中,这些数据间的关联信息被保存在学习到的深度特征表示中。计算样本对之间相关度的常用策略有两种:1)特征间的欧氏距离;2)特征间的余弦相似度。本文通过度量不同样本对实值哈希码的欧氏距离来判断样本对是否相似。为了方便理解,l2范数归一化的实值哈希码欧氏距离和相似度的联系为:

其中:fi表示第i个实例学习到的实值哈希码向量;Sij表示第i和j个实例之间的相似度。不同实例间哈希码的欧氏距离越小,二者越相似。UKD 设置哈希码欧氏距离矩阵D:Dij=中每行前l个元素下标对应的实例为相似样本对,破坏了相似性矩阵的对称性。
本文为了保证重构实例相似度矩阵的对称性,设置与相似对数量l正比的阈值λ来判断不同样本对之间是否相似。设=dr(fi-fj)为距离矩阵D中升序排序的第r个元素,设置阈值λ=,其中r=(n-1)l,n为训练集数量。当第i个与第j个实例哈希码的欧氏距离Dij=Dji≤λ时,二者为相似样本对,Sij=Sji=1;当Dij=Dji>λ时,Sij=Sji=-1,故重构实例间相似性矩阵满足对称性。
此外,对比组DJSRH 批次大小联合图像与文本信息的语义相似度矩阵的构建如下:
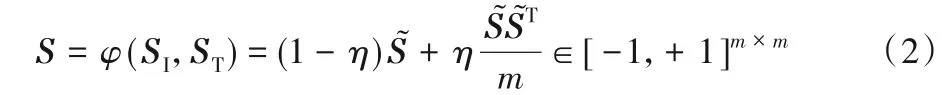
其中:SI和ST分别为批次大小图像与文本深度特征的余弦相似度矩阵;η为超参数为SI和ST的线性组合。

然而,DJSRH 在训练过程中产生的联合语义矩阵S只有批量大小,且处在变化中,无法用作整个训练集的相似度矩阵,故本文采用测试过程中固定网络产生的联合语义相似度矩阵来进行对比实验。
2.3.2 有监督学生模型
在UKD 中,对称学生模型DCMH 时间复杂度高且无法学习多层次语义相似度矩阵。受非对称策略[35]启发,本文将训练集分为两个部分:1)整个数据库集直接通过矩阵运算学习哈希码;2)少量查询集通过神经网络训练得到哈希码。其中,整个训练集O作为数据库集,随机采样O中m个数据点作为查询集OΩ,m≪n。此时,数据库点的下标为Γ={1,2,…,n},查询集点下标为Ω={i1,i2,…,im},Ω⊂Γ。
为了学习相似度矩阵的多层次语义关联,本文方法DUDCH 通过二进制哈希码内积和相似度间的关系S=B⋅BT/k定义损失函数,其模态内与模态间损失定义如下:
1)模态内损失。
图像、文本模态内损失包含两个部分:1)非对称损失。查询集和数据库集中哈希码内积与重构相似度矩阵间的l2损失。2)量化损失。查询集中实值哈希码与离散哈希码间的l2损失。具体定义如下:


其中:BΓ∈{-1,+1}n×k与BΩ∈{-1,+1}m×k分别表示数据库集与查询集直接学习到的离散哈希码矩阵;=SΩ×Γ∈{-1,1}m×n表示查询集与数据库集间重构相似度矩阵。
2)模态间损失。
为解决不同模态间的语义鸿沟,让不同模态的哈希码在公共汉明空间拥有与单一模态相同的语义关联信息,图像文本模态间对称损失定义如下:

此时,式(6)的矩阵形式如下:

其中:=SΩ×Ω∈[-1,+1]Ω×Ω为图像与文本查询集间的重构相似度矩阵。
2.4 学生模型优化算法
无监督老师模型代替标签提供先验的实例相似度矩阵,有监督学生模型则学习从原始数据到汉明空间的复杂非线性映射,故在式(5)与式(7)的基础上,学生模型最终优化函数如下:

同时求解式(8)中θv、θt、B是非凸问题,但交替优化各个变量是凸的,从而得到全局最优解,具体的迭代更新过程如下:
1)固定θt、B,更新θv,式(8)重写如下:



通过不断地迭代更新参数θv、θt、B,直到满足收敛或达到最大迭代次数来优化式(8)中各个参数,具体优化过程如下。
算法1 非对称离散学生模型优化算法。
输入 图像矩阵X和文本矩阵Y,重构相似度矩阵S,哈希码长度k。
输出 图像和文本神经网络参数θv和θt,离散哈希码B。
初始化:θv、θt和B,超参数α和β,批次大小m,最大迭代次数Tmax,图像与文本迭代次数T=10。
1)Repeat
2)在数据库集中随机采样生成查询集及其下标Γ,并以此来切分重构相似度矩阵S
3)Repeat
4)根据式(10)更新图像神经网络参数θv
5)Until迭代次数达到图像迭代次数T
6)Repeat
7)根据式(11)更新文本神经网络参数θt
8)Until迭代次数达到文本迭代次数T
9)根据式(16)按位更新离散的哈希码B
10)Until迭代次数达到最大迭代次数Tmax或收敛
3 实验与分析
本文在两个常用的基准数据集MIRFLICKR-25K[38]和NUS-WIDE[39]上进行实验,并与六个先进的跨模态哈希方法CMSSH[8]、SCM[7]、CVH[6]、CMFH[24]、CCQ[25]、DJSRH[22]作比较。其中,前两个是经典的有监督跨模态哈希方法,后四个是经典的无监督跨模态哈希方法。
3.1 数据集
MIRFLICKR-25K:该数据集包含来自Flickr 的25 000 个文本-图像实例对,每个实例对被标注24 个语义标签。遵循UGACH 的实验设置,本文设置图像为4 096 维VGG 深度特征,设置文本为1 386 维词袋向量。对于有监督方法,随机挑选5 000个图像文本对作为训练集。
NUS-WIDE:该数据集包含269 498 个文本-图像实例对和81 个语义标签。本文挑选实例对中标注10 个最频繁的语义标签,总共186 577 个实例对用于实验。类似地,本文设置图像为4 096 维VGG 深度特征,设置文本为1 000 维词袋向量。有监督方法中随机挑选5 000个图像文本对作为训练集。
3.2 评估标准
本文采用平均精度均值(mean Average Precision,mAP)和精度召回率(Precision Recall,PR)曲线作为评价策略。mAP 为所有查询集精度均值的平均值,对于第i个测试实例,精度均值AP(i)定义如下:
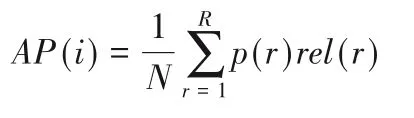
其中:N表示在检索集中相关实例的数量;p(r)表示返回的第r个实例的精度。如果第r个返回的实例与第i个检索实例相关,rel(r)=1;否则,rel(r)=0。
PR 曲线反映模型不同召回率下的精度,它的横纵坐标分别由以下公式得到:

其中:TP(True Positives)表示真正例:FP(False Positives)表示假正例:FN(False Negatives)表示假负例。
3.3 实验设置
本文在老师模型中保持DJSRH 的基本设置,但为得到更准确的实例间相似度信息,将训练集数量提高为15 000,其他参数不变。在有监督学生模型训练过程中,对于MIRFLICKR-25K 和NUS-WIDE 数据集,本文随机采样15 000个实例作为数据库集,2 000个实例作为测试集。在数据库集中随机抽取3 000 个实例作为查询集。相似度矩阵中相似对数量设置为5 000,式(8)中超参数设置为α=200,β=100。这些超参数的灵敏度分析将在3.4.3 节中进行具体比较。在图像与文本网络中,最大迭代次数为50,学习率设置为10-5,批次大小设置为128。为了网络的稳定性,图像与文本网络在重复更新迭代10次后按位更新哈希码。
3.4 实验结果与分析
3.4.1 检索表现
表1 给出不同方法在MIRFLICKR-25K 与NUS-WIDE 数据集上不同码长的mAP 值。可以看出,组合模型DUDCH 的mAP 值比老师无监督模型DJSRH 更高,这说明本文运用知识蒸馏联合两种模型得到了超过单一模型的表现,说明了该方法的有效性。
在MIRFLICKR-25K 和NUS-WIDE 数据集上,DUDCH 比排名第二的无监督跨模态哈希方法DJSRH 在图像检索文本任务上mAP 大约平均增长了2.83 个百分点和6.53 个百分点,在文本检索图像任务上平均增长了0.70个百分点和3.95个百分点。这说明了本文离散非对称学生网络有效学习到老师模型提供的先验样本关联信息,验证了哈希码离散求解的有效性。此外,从表1 中可以看出,DUDCH 中mAP 值不随着码位的增长而增长,这说明DUDCH 对于哈希码长度并不敏感,在较小码位上也能有着出色的表现。
另外,从表1中可以看出,深度无监督算法DJSRH 与浅层有监督算法CMSSH 与SCM 相比mAP 值有着明显的提升,这说明神经网络学习到的深度特征更有利于哈希码的学习。

表1 在MIRFLICKR-25K与NUS-WIDE数据集上不同哈希码长度时不同方法的mAP比较Tab.1 mAP comparison of different methods on MIRFLICKR-25K and NUS-WIDE datasets with different Hash code length
图2 与图3 分别给出了DUDCH 在MIRFLICKR-25K 和NUS-WIDE 数据集上哈希码长度为128比特时不同方法的PR曲线。从图2~3 中可以看出:1)DUDCH 在NUS-WIDE 数据集上的表现要远远好于MIRFLICKR-25K,说明DUDCH 在更大规模数据集上的优势更明显;2)尽管DUDCH 在低召回率的表现不好,但随着召回率增加,精度相较于其他方法下降不明显,使得PR 曲线下面积要明显大于其他方法,这也说明DUDCH 相较于其他方法在检索性能上有着显著提升;3)DUDCH 在图像检索文本任务上检索性能要明显好于文本检索图像。

图2 在MIRFLICKR-25K数据集上哈希码长度为128比特时不同方法的PR曲线Fig.2 PR curves of different methods on MIRFLICKR-25K dataset with Hash code length of 128 bit

图3 在NUS-WIDE数据集上哈希码长度为128比特时不同方法的PR曲线Fig.3 PR curves of different methods on NUS-WIDE dataset with Hash code length of 128 bit
3.4.2 对比UKD方法
本文给出了在MIRFLICKR-25K 训练集上码长为16 比特的情况下对比UKD 学生模型DCMH 的训练时间-mAP 图,具体情况如图4 所示。可以看出,DUDCH 每次迭代的训练时间大约为0.08 h,DCMH 每次迭代训练时间大约为0.15 h,二者在约2.7 h 时接近收敛,此时,DUDCH 和UKD 在图像检索文本/文本检索图像任务上mAP 值分别为0.716/0.687和0.677/0.657,DUDCH 对比UKD 在图像检索文本(I2T)/文本检索图像(T2I)任务上mAP 分别提升了3.90 个百分点/3.00 个百分点,说明了本文方法对比UKD 学生模型具有更强的学习能力。由于DUDCH 设置迭代次数为50,UKD 设置DCMH 迭代次数为30,故在同等的时间上DUDCH 迭代次数更多,迭代速度更快。造成本文模型训练效率高于UKD 的主要原因为以下三点:
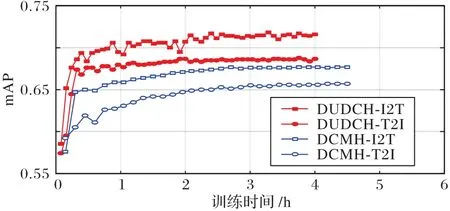
图4 MIRFLICKR-25K数据集上哈希码长度为16比特时不同蒸馏法的训练时间Fig.4 Training time of different knowledge distillation methods on MIRFLICKR-25K dataset with Hash code length of 16 bit
1)UKD 学生模型采取传统的对称哈希方法训练整个训练集大小的神经网络,时间复杂度至少为O(n2),而本文采用非对称方式训练的时间复杂度为O(n);
2)不同于UKD 学生模型直接将整个训练集样本放入深度神经网络中学习,本文则将训练数据集分为直接按位学习得到的整个数据库样本与通过神经网络学习的少量查询集样本,而神经网络训练时间远远大于矩阵运算时间,由于m≪n,使得总体训练时间要远远小于DCMH。
3)由于UKD 中老师模型UGACH 采用对抗性神经网络,花费了大量时间在样本相似对选取与模型的预训练上,模型训练时间远远超过DJSRH,故在图4 并未给出不同老师模型的时间复杂度对比图。
3.4.3 参数灵敏度
为确定相似样本对的最佳数量以及式(8)中超参数α、β的最佳大小,在图5 与图6 中给出了这些超参数的灵敏度分析。实验中训练数据集同为MIRFLICKR-25K 数据集,哈希码长度分别为16 与128 比特,迭代次数为30,横坐标为超参数值,纵坐标为mAP 值。相似样本对大小设置范围为1 000 到8 000,而式(8)中超参数α、β大小设置范围为{1,10,100,500}。

图5 MIRFLICKR-25K数据集上哈希码长度为16比特时不同相似对的mAP值Fig.5 mAPs values of different similarity pairs on MIRFLICKR-25K dataset wit h Hash code length of 16 bit

图6 两种超参数的灵敏度分析Fig.6 Sensitivity analysis of two hyper-parameters
从图5 中可以得出以下结论:少量的相似对信息会误导模型度量不同实例相似性过多趋向于不相关,导致模型获得了较差的检索性能。随着模型得到了越来越多的关联信息后,其性能不断上升并趋于稳定,在相似对数量为5 000时,模型的平均mAP 达到顶点。另外,从图6 中可以发现:超参数α和β对于图像检索文本几乎没有影响,对于文本检索图像有着细微的影响,当参数α和β分别在[100,500]与[10,100]时,模型精确度微微上升,其他地方或缓慢下降或平缓。通过以上分析,可以发现在一个较大的范围中本文方法并不敏感,说明了该方法的鲁棒性与有效性。
3.4.4 蒸馏法对比
老师模型DJSRH 自身能够学习到一种联合图像与文本语义关联信息的余弦相似度矩阵,这可能成为另一种有效的蒸馏法。本文在图7 中给出了它在数据集为MIRFLICKR-25K、码长为128比特情况下不同迭代次数下的mAP图。

图7 在MIRFLICKR-25K上哈希码长度为128比特时不同蒸馏法的mAP值Fig.7 mAPs values of different knowledge distillation methods on MIRFLICKR-25K dataset with Hash code length of 128 bit
从图7通过对比可以发现,DUDCH 和DJSRH 在图像检索文本(I2T)上mAP 值分别为0.716 和0.631,DJSRH 方法相较于本文方法DUDCH 在图像检索文本上中mAP 值下降了8.50个百分点,且在文本检索图像上模型一直处于动荡状态,说明蒸馏出的实例相似度矩阵不能够有效表达出实例间的关联关系,因此,不能够作为新的蒸馏知识来帮助有监督学生模型训练。
4 结语
本文提出了一种基于知识蒸馏的深度无监督离散跨模态哈希方法DUDCH。该方法利用预训练无监督老师模型中的实例间关联信息代替标签帮助学生模型有监督训练,在计算实例间相似度矩阵中保证其对称性。另外,该算法采用端到端无监督模型作为老师模型,非对称有监督模型作为学生模型,有效缩短了模型的运行时间。最后,该算法在哈希码的求解过程中不放松哈希码的离散约束条件,按位学习离散哈希码。
在两种准基跨模态数据集中与六种先进的跨模态哈希方法对比mAP 值与PR 曲线图,表现了该算法的有效性。另外,从收敛性和参数设置来看,DUDCH 有效降低了组合模型的运行时间,且对参数变化并不灵敏,显示出了较好的鲁棒性。在将来,我们将考虑如何将组合模型联合到统一框架当中。
猜你喜欢
汽车实用技术(2022年10期)2022-06-09
昆明医科大学学报(2022年3期)2022-04-19
中国传媒大学学报(自然科学版)(2021年1期)2021-06-09
电脑爱好者(2021年8期)2021-04-21
电脑爱好者(2021年1期)2021-01-13
电脑爱好者(2020年20期)2020-10-22
电脑爱好者(2015年13期)2015-09-10
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
电影新作(2014年1期)2014-02-27
