
基于条件变分自编码网络的短文本分类
2021-09-16 03:12:48郑山红李万龙
计算机应用与软件 2021年9期
康 宸 郑山红 李万龙
(长春工业大学 吉林 长春 130012)
0 引 言
文本分类是基于文本中的词项等一些内置属性,能够成功地将每个文档分类到预先定义好的类别中。在自然语言处理文本挖掘领域,文本分类是一项重要的研究内容,被广泛应用于Web搜索、日志分析、信息过滤和情感分析等领域[1]。随着互联网大数据的发展,短文本数据的规模迅速增长,对短文本进行高效准确的分类显得非常重要。与长文本分类不同,由于文本主题特征稀疏,短文本中有利于文本分类的主题特征不够充分,因此导致传统的文本分类模型处理短文本的分类效果不佳。
文本分类的相关工作可以追溯到20世纪50年代。文本分类包含以下六个主要步骤:准备训练和测试数据、文本规范化处理、特征抽取、模型训练、模型预测与评估、应用部署,其中特征抽取以及模型训练尤为重要。传统的特征抽取方法有通过计算特征权重选定阈值过滤特征的统计方式,如互信息(MI)[2]、χ2统计量(CHI)[2]和期望交叉熵[2]等。由于这些方法都是基于统计的方式进行特征抽取,不仅需要繁琐的特征工程,而且对于字符数比较少的短文本特征抽取不够充分,最终的分类效果往往很差。随着统计机器学习的发展,特征抽取可以不依靠繁琐的特征工程,而是由模型自己训练得到,但是需要额外的表示文本。常见的文本表示包括词袋模型和向量空间模型(VSM),这些文本表示方式在长文本分类中有很好的效果,但是对于短文本,这些文本表示导致维度高且系数,模型训练过程参数众多且有效特征稀疏,训练模型很容易发生过拟合,如基于SVM的统计机器学习文本分类算法[3-4]。随着深度学习的发展,文本分类不再需要繁琐的特征抽取工作,而是由深度学习模型参数拟合训练进行抽取,利用LSTM及一维卷积等网络模型架构自动抽取文本分类的主题特征。LSTM网络擅长处理全部序列信息特征,将整个序列数据看成一个数据点,序列中的词项信息状态进行保留传递,但是在处理短文本分类中,LSTM网络处理的文本序列稀疏,并且对于文本分类任务,n-gram特征可能对文本分类任务更为有效。因此Kim等[5]提出了一维卷积,不同于LSTM提取文本全部序列信息,一维卷积神经网络能够根据filter来学习局部序列信息,因此在对n-gram特征敏感的分类任务上表现尤为突出。但是使用一维卷积对短文本进行特征抽取过程中,短文本字符限制导致提取出来的n-gram语法主题特征不足,导致一维卷积处理短文本时主题特征挖掘不够充分。
本文将预训练好的LDA的主题词项分布拼接成单通道的文本特征表示,然后应用二维卷积进行特征的抽取统计参数,根据统计参数生成文本主题的潜在空间,构建文本分类模型仅需要将文本映射到主题潜在空间中,由映射后的主题特征作为文本分类的输入,类别标签作为输出,构造全连接层的分类器。不仅弥补了短文本分类主题特征不够充分,同时也利用了二维卷积神经网络层次化结构的优点。
1 预训练LDA主题模型
主题模型是对文字中隐含主题的一种建模方法。主题可以看成是词项的概率分布,主题模型通过词项在文档级的共现信息抽取语义相关的主题集合,并能够将词项空间中的文档映射到主题空间,得到文档在低维空间中的表达[6]。Blei等[7]提出了基于贝叶斯思想的LDA主题模型,主题分布及主题词项分布是由两个先验Dirichlet分布生成,然后不断迭代求解出最终的主题分布和主题词项分布。
本文采用Gibbs采样的方式迭代求解LDA主题模型的参数,在求解过程中每次都对联合分布中的某一个分量进行采样,其他的分量保持不变,最终将所有分量都计算一次。推导后的Gibbs采样求解LDA主题模型迭代公式如下:
(1)

2 模型设计
由于深度学习能够通过参数拟合学习出有益于文本分类的主题特征,并通过分类器进行分类,而抽取有益于文本分类主题特征关系到最终分类效果的好坏。因此,本文利用具有标签指导的条件变分自编码网络生成文本主题的潜在空间,进而通过预训练的方式将待分类的文本映射到文本主题潜在空间中得到主题特征,使用得到的特征进行文本分类。基于条件变分自编码网络进行文本分类分为两个步骤:(1) 预训练文本主题的潜在空间模型。通过构建条件变分自编码生成文本主题的潜在空间。(2) 训练文本分类模型。利用预训练的文本主题潜在空间映射文本得到主题特征进行短文本分类。
2.1 预训练文本主题潜在空间模型
变分自编码网络最流行的应用是创造性地从图像的潜在空间中采样,并创建全新图像以及编辑现有的图像。通过训练数据变分自编码能够学习到连续且具有良好结构的图像潜在空间,而这种空间同样适用于文本数据。同时为了更好地重构原始特征,将文本的类别标签加入变分自编码网络作为条件指导重构文本主题特征。预训练文本主题潜在空间模型分为Encoder与Decoder两个部分,Encoder部分如图1所示,Decoder部分如图2所示。

图1 Encoder

图2 Decoder
2.1.1文本主题特征图
不论是传统的文本分类模型还是应用机器学习模型,都需要将文本字符表示成计算机能够识别的数值,这个过程被称为文本向量化。常见的文本向量化方式有one-hot编码及词嵌入。其中one-hot编码是将每个单词与一位唯一的整数索引相关联,然后将这个整数索引i转换为长度为N的二进制向量(N是给定词汇表大小),其中只有第i位置的元素是1,其余的所有元素都是0。这种方式将文本中词项看成独立元素,忽略了文本中词项与词项之间的关系,并且由于N通常很大,导致文本向量化后的维度稀疏,模型很容易过拟合。词嵌入方式是根据词项共现将文本中的词项表示为相对低维的密集型向量,向量中包含词的语义信息,常见的词嵌入方式有Word2vec和GloVe等[8]。但是对于文本分类任务来说,词项主题信息比词项语义信息更有利。对于短文本而言,如何充分挖掘词项的主题信息至关重要,本文将LDA预训练的主题词项分布作为短文本分类的特征,采用拼接的方式,将短文本中每个词项拼接成文本主题特征图,然后经过二维卷积对拼接后的文本主题特征图进行特征提取。文本主题特征如图3所示。

图3 文本主题特征
将短文本表示为拼接的主题词项向量特征图,之后可以通过二维卷积来进行特征提取。对于短文本分类任务而言,将短文本拼接成单通道的特征图,是将短文本特征类比于图像特征,当然文本具有不同于图像的特点,但是对于文本分类任务来说,通道中的每一个维度都可能影响最终的分类结果。对于拥有j个词项的短文本来说,其某一个维度可能包含着关于体育主题特征,在应用二维卷积进行抽取特征后,关于这个维度的特征可能尤为的突出。对于文本分类任务来说,完整的词项序列或者比较长的词项序列可能帮助不大,但是简短连续的词项对可能会对文本主题有帮助,而在二维卷积处理文本主题特征图的时候,可以选定一个filter,每一次卷积操作考虑filter width个主题向量维度特征和filter height个连续词项对。
2.1.2文本转换为统计分布参数
变分自编码网络生成图像,假定潜在正态分布能够输入图像。将所定义的潜在空间分布定义为正态分布,正态分布能够很好地模拟图像的生成。对于文本主题特征图而言,需要生成具有连续且高度结构化的文本主题潜在空间,并且能够生成输入的文本主题特征图。在LDA主题模型中,生成主题分布及主题词项分布使用的是多维Beta分布的Dirichlet分布,选择单维度的Beta分布,指定生成参数的维度可以模拟Dirichlet分布,因此将潜在空间的分布定义为Beta分布。Beta分布的概率密度函数表达式为:
(2)
式中:α、β是两个正值参数,称为形状参数。B(α,β)计算如下:
为了能够应用梯度下降法迭代求解参数。变分自编码网络使用重参数技巧,虽然已知潜在空间分布为Beta分布,但是生成的统计参数是通过模型计算出来的,需要靠梯度优化算法反过来优化这些统计参数,从潜在空间“采样”操作是不可导的,而“采样”的结果是可导的。“采样”的过程计算式表示为:
Z=zmean+exp(zvariance)×ε
(3)
式中:Zmean和Zvariance分别为Z的均值和方差;ε是一个很小的随机张量。由于使用Beta分布作为潜在空间的分布,因此具体重参数技巧公式为:
(4)
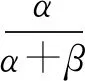
2.1.3条件变分自编码的损失函数
条件变分自编码的参数是由两个损失函数来进行训练的,分别为输入文本特征图A与输出文本特征图的重构损失,以及能够帮助生成的主题潜在空间Z学习到良好结构的正则化损失。由于传统的条件变分自编码网络假设正态分布生成图像,因此传统的条件变分自编码的正则化损失就是计算两个正态分布p1和q1的KL散度,具体公式如下:
(5)

而在前面为了生成更加结构化、对文本分类更加有益的文本主题潜在空间,假定潜在空间分布是由Beta分布构成,因此对应的正则化损失函数是计算两个Beta分布的KL散度,具体公式如下:
p2~Beta(α,β)
q2~Beta(α′,β′)
(β′-β)ψ(β)+(α′-α+β′-β)ψ(α+β)
(6)
式中:p2服从参数为α、β的Beta分布;q2服从参数为α′、β′的Beta分布;ψ为双伽玛函数;KL(p2,q2)表示计算两个Beta分布的KL散度。KL散度计算的是两个分布之间的距离,但是不满足对称性。Beta分布和正态分布所有点的概率密度都是非负的,不存在某一个区域的概率值为0,KL散度无穷大的情况。
2.2 训练文本分类模型
预训练得到的文本主题潜在空间具有连续和高度结构化的特点。由于假定文本主题潜在空间的分布为Beta分布,因此潜在空间能够将文本映射为相应的主题特征编码。接下来就可以利用这些主题特征编码来训练文本分类模型。训练模型结构如图4所示。
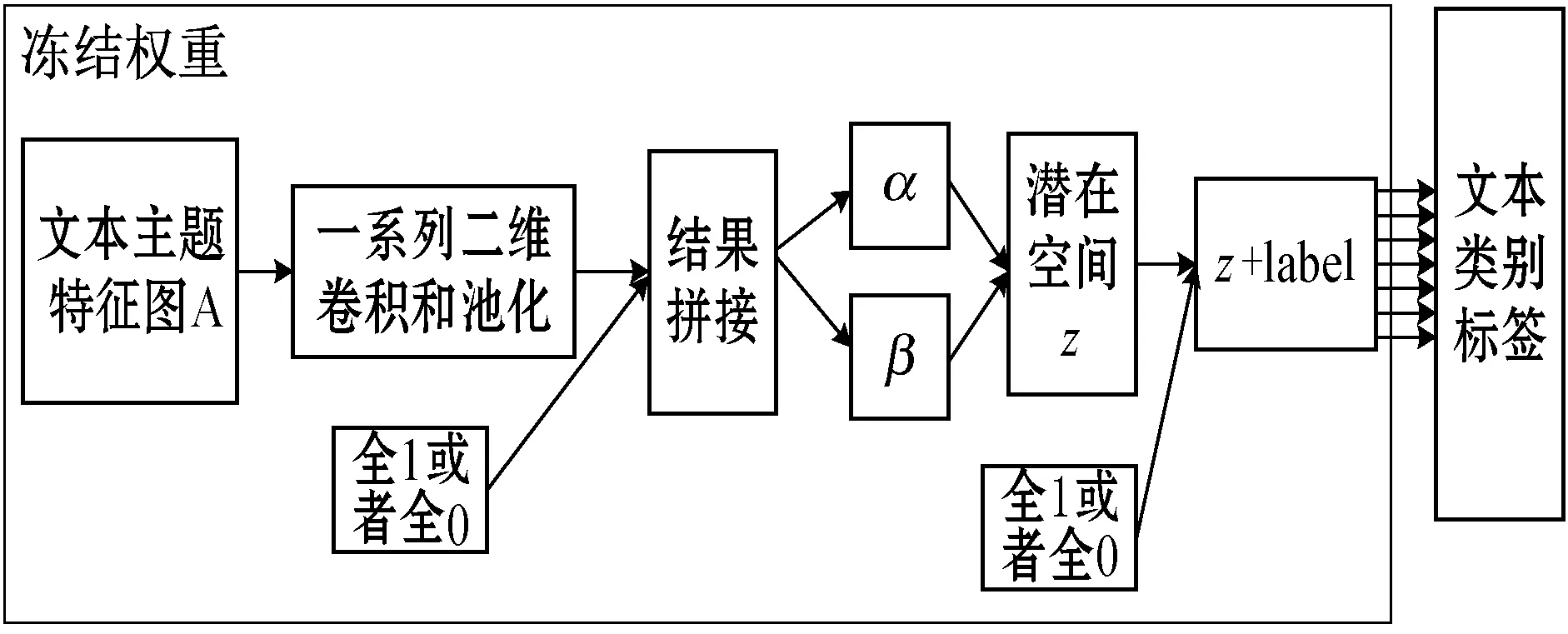
图4 利用文本主题潜在空间端到端的训练文本分类
利用文本主题潜在空间进行端到端的文本分类,将预训练文本主题潜在空间模型的Encoder架构保留,并将文本映射到文本主题潜在空间后的文本主题特征作为分类器的特征进行分类。为了避免训练导致学习好的参数权重遭到破坏,在训练文本分类需要冻结生成文本主题潜在空间的Encoder部分。
由于预训练文本主题潜在空间过程中引入了标签作为指导,有助于更好地重构文本主题特征图。但是在利用生成的文本潜在空间进行文本分类的过程中,没有重构文本主题特征图的过程,因此不再需要类别标签作为条件。但是在整个过程中使用的是预训练好的模型架构参数权重都是固定不变的,并且测试模型的时候也不能知道文本的已知的类别标签,因此在利用潜在空间进行端到端的文本分类过程中,将作为条件的类别标签设置为全0或者全1,忽略此时文本标签的指导作用。
3 实 验
3.1 预训练主题词项分布
在55 000条搜狗新闻文本数据集上预训练LDA主题模型,共计375 030个词项,将主题数设置为4~100(间隔8),困惑度随主题数的变化情况如图5所示。

图5 主题数与困惑度的折线图
图5中主题数量与困惑度呈现递减的趋势,但是当主题数量为64时,递减逐渐趋于平缓。因此为了得到更好的主题词项分布,将主题数量设置为64,两个超参数α和β分别设置为0.78和0.01[7]。
3.2 实验数据
采用搜狗实验室公开的2012年6月到7月搜狐新闻数据集,从中均匀提取10个类别的60 000条新闻数据集。将其中的45 000条新闻数据作为训练集,5 000条新闻数据集作为验证集以及10 000条新闻数据集作为测试集。提取每条新闻数据标题作为短文本数据集,同时为了避免构造的文本主题特征图过于稀疏,除了过滤掉短文本中停用词之外,还需要过滤掉一些主题不够明显的词项。
在计算两个Beta分布的KL散度时,为了得到更好的文本主题分布,将其中的一个Beta分布参数都设置为0.01。
3.3 对比算法
本文提出的条件变分自编码网络解决文本分类问题,文本的主题信息对文本分类有很大的帮助,因此将在LDA主题模型上预训练的主题词项分布作为短文本的词项向量,通过拼接的方式拼接成拥有单通道的文本主题特征图,通过二维卷积将文本主题特征体转换为Beta分布的两个统计参数α和β,进而生成文本主题的潜在空间。在训练文本分类的过程中,将文本映射到预训练的文本主题潜在空间的特征作为输入,具体的10个类别作为输出的全连接分类器。为了方便将基于条件变分自编码的短文本分类算法记为CVAE-TC,进行对比的分类算法有传统分类模型的SVM、LSTM以及简单的fastText模型[9],用于分类效果比较好的一维卷积Text-CNN模型[5],还有将图像注意力机制加入到文本中的HAN模型[10]。
3.4 实验结果
实验对比了CVAE-TC、SVM、LSTM、Bi-LSTM、fastText以及Text-CNN和HAN七种文本分类模型。CVAE-TC模型在文本分类过程中包含两个步骤,一个是预训练文本主题潜在空间;另一个过程是利用文本主题潜在空间进行文本分类的过程。仅考虑文本分类过程时间效率与最快的fastText模型相近,为了公平把预训练文本主题潜在空间的过程算入CVAE-TC模型的训练时间中。不同模型在精度以及总的训练时长上的对比如表1所示。
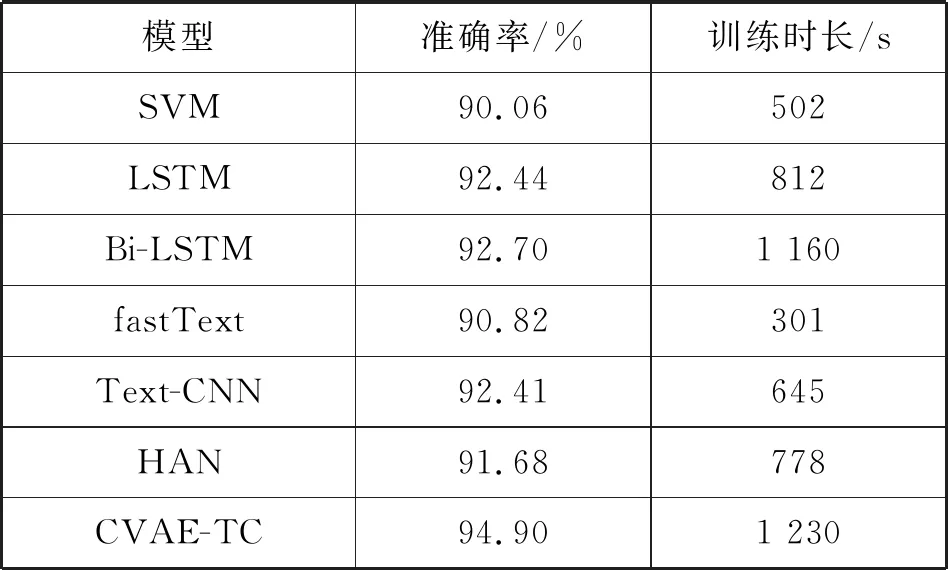
表1 不同模型在短文本分类上的对比(10 epoch)
其中短文本分类算法在精度上对比如图6所示。

图6 七种分类算法精度柱状图
可以看出,在七种分类算法中CVAE-TC的分类准确度最高达到了94.90%,而对于其他的分类算法在短文本上的分类效果不佳,没有充分地挖掘短文本中的主题信息。在传统的文本分类算法中,Text-CNN比LSTM等一些模型分类效果好,这也说明了对于文本分类任务来说,连续的词项对比完整的词项序列更有用。而CVAE-TE将短文本的主题信息直接将引入文本特征中,通过拼接成单通道的文本主题特征图的形式,应用二维卷积神经网络对连续个词项的部分相同维度的主题特征进行提取。从分类精度上可以看出,预训练的文本主题潜在空间不仅有很强的鲁棒性,而且能够更好地映射出文本的主题信息。
七种分类算法中的训练时长对比如图7所示。

图7 七种分类算法总的训练时长
处理短文本特征的时候,相对于长文本特征少,因此使用简单模型的时候,训练时长会非常的短,比如fastText。CVAE-TC由于包含预训练文本主题潜在空间的部分,因此需要的时间是最长的。但是由于将文本转换为单通道的特征图,可以应用成熟的图像领域技术进行优化。
从多维文本主题潜在空间中采样一组点,并将其解码成单通道的文本主题特征图,通过可视化的方式显示20×20=400个文本主题特征图,如图8所示。

图8 采样文本主题潜在空间
虽然采样文本主题潜在空间可视化不如采样图像潜在空间的可视化直观,但是由于文本主题特征图任意维度的特征值都在0~1之间,因此可以通过灰度图像的可视化来可视化主题特征。维度值越接近于0可视化的结果越黑,表示维度主题不够明显,而维度值接近1,可视化的结果越白,表示当前维度的主题突出。通过图8采样后的可视化可以看出,得到的文本主题潜在空间具有很强的连续性,主题从左到右呈现一种逐渐过渡。
4 结 语
本文提出了基于变分自编码的短文本分类模型,通过预训练的LDA的主题词项拼接单通道特征图作为短文本的分类特征。通过二维卷积提取及Beta分布来生成文本主题的潜在空间,之后利用文本主题的潜在空间进行文本分类。短文本分类的效果得到了明显的提升,但是在构造特征图过程中,虽然过滤掉短文本停用词及主题特征不明显的词项,避免了主题词项特征稀疏问题,但是由于维度比较大,导致某些维度的特征值比较小,增加了运算难度和时间效率复杂度,并且在重构的过程中很难保证这些特征值比较小的维度。未来工作主要是优化文本主题特征以提升算法的效率。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
电子制作(2019年11期)2019-07-04 00:34:38
时代英语·高二(2018年7期)2018-12-03 09:23:06
哲学评论(2018年1期)2018-09-14 02:34:18
时代英语·高二(2018年3期)2018-06-06 05:24:36
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
电视技术(2014年19期)2014-03-11 15:38:20
阅读与作文(英语高中版)(2013年12期)2013-12-11 08:20:08
阅读与作文(英语高中版)(2013年11期)2013-11-13 05:36:26
上海理工大学学报(社会科学版)(2011年4期)2011-09-26 11:01:32
