
基于神经网络与特征融合的胶囊内镜图像识别模型
2021-09-15 11:48:46张大斌魏晓雍刘杰民
计算机应用与软件 2021年9期
王 孟 张大斌 魏晓雍 张 晖 刘杰民
1(贵州大学机械工程学院 贵州 贵阳 550001)
2(贵州银行博士后流动站 贵州 贵阳 550001)
3(贵州省人民医院 贵州 贵阳 550001)
0 引 言
社会的快节奏发展下,人们日常生活饮食非常不规律和不健康,导致消化道疾病患病率长期以来居高不下。我国现已成为胃病大国[1-3],每年新增胃癌50万例以上。传统消化道检测手段,如钡餐造影、胃镜和血清筛查等,存在辐射高、敏感度低和舒适性差等缺点。胶囊内镜(WCE)体积小且具备无线传输功能,能够通过肠胃蠕动实现整个消化道的拍摄,且患者无任何不适,因而得以应用。但每个患者所拍摄的图片多达5万幅,严重降低了医生审阅的效率,使其不能推广使用。
目前,不乏对WCE计算机辅助诊断的研究。传统机器视觉领域,研究者针对有差别的病灶分别设计了个性化特征检测算法。文献[4]利用局部二值模式和拉普拉斯金字塔进行溃疡多尺度特征提取,结合SVM分类器实现了95.11%的识别准确率。文献[5]丢弃了WCE亮度信息,借助SVM和多层感知器对颜色通道特征分类,并实现了小肠肿瘤全自动分割,该算法比小波和小曲率变换速度快了25倍。文献[6]对围绕单个像素的块定义了索引值,从索引值的直方图中提取颜色和纹理特征,结合主成分分析法检测消化道出血,准确率高达97.85%。深度学习领域的WCE诊断中,研究者通常采用经典神经网络进行迁移学习。文献[7]采用预训练的Alex Net训练上万幅WCE图片,检测溃疡和糜烂的准确率为95.16%和95.34%。文献[8]使用大型非医疗图像数据库对ResYOLO目标检测算法进行预训练,之后用结肠镜图像对参数微调,结合ECO跟踪器来整合WCE时间信息,对息肉检测准确率达到88.6%。也有将传统机器视觉和深度学习相结合的研究者。文献[9]提出一种WCE图像异常的自动检测和定位方法,首先使用预训练的弱监督卷积神经网络划分WCE为异常与正常,再利用显著性检测算法检测兴趣点,最后通过迭代聚类统一算法定位异常病灶,实验准确率高达96%。上述基于传统机器视觉的识别算法需要针对不同病灶设计不同算法,基于迁移学习的模型存在预训练数据与样本数据差异大的问题,传统机器视觉与深度学习结合的方法使得算法结构复杂,不能广泛使用。
因此,本文提出了基于神经网络与特征融合的胶囊内镜图像识别模型。本模型借助卷积神经网络自动学习图像特征的特点,分别提取WCE颜色、形状和纹理特征,再通过Bagging算法进行特征融合。本模型是首次将卷积特征提取与Bagging特征融合相结合的模型,并采用了分离输入并训练的模式,替代了传统RGB通道训练,实现了一种对WCE图像识别具有通用性、结构简单、可应用于实际的医疗辅助诊断模型。
1 图像预处理
胶囊内镜图像的位深度为24,水平和垂直分辨率均为96 dpi,为医生诊断提供了丰富信息。医生利用颜色、形状和纹理特征对WCE进行诊断。因此,分别进行G分量提取、Log变换、直方图均衡化,以突出WCE颜色、形状及纹理特征,削弱特征间相互影响,从而利用卷积神经网络分别提取WCE颜色、形状和纹理特征,再进行特征融合识别。
1.1 G分量提取
RGB图像由红色像素分量(R)、绿色像素分量(G)和蓝色像素分量(B)通过矩阵叠加形式组成。胶囊内镜拍摄对象为整个消化道,颜色呈浅红色至深红色。内镜下,Z线处食管白色黏膜与红色胃黏膜交汇边界清晰,染色增强的息肉与常规组织存在明显颜色差异,溃疡表面被白色纤维蛋白覆盖。为分析WCE颜色通道间的差异,统计50幅息肉和溃疡病灶图R、G、B通道颜色值的均值和标准差,见表1。
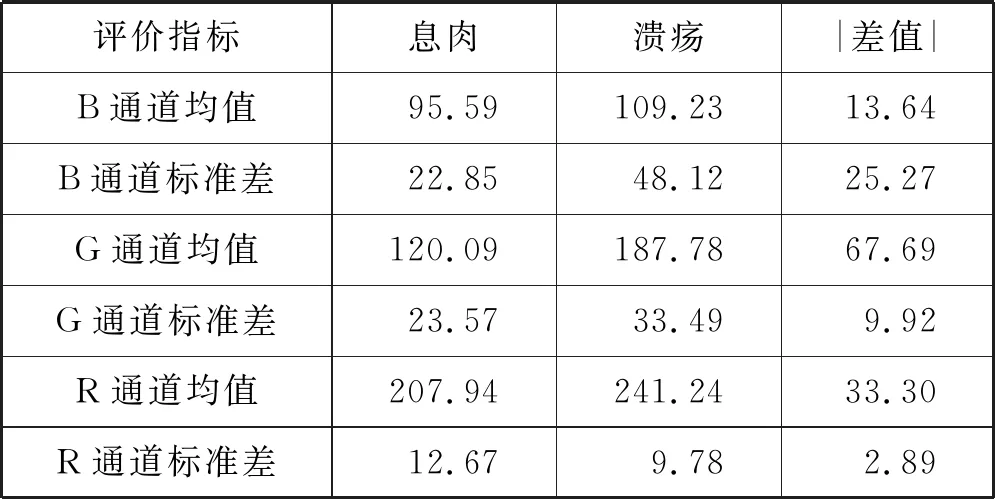
表1 息肉与溃疡病灶图RGB通道评价
表1中,两种疾病颜色均值的差值大小为G>R>B, 说明G通道灰度值分布差异比R和B通道大,G通道颜色分布信息更为丰富。标准差的差值大小为B>G>R,即B和G通道包含的颜色细节信息比R通道丰富。综合两个评价指标,G通道均值与标准差综合表现强于R和B通道,能够表征胶囊内镜的颜色信息。因此提取G通道特征作为WCE颜色特征,舍弃B和R通道。
1.2 Log灰度图像变换
消化道不同器官在形状上有显著差异。盲肠与回盲肠相接且有多个囊袋状沟壑,幽门呈规则的圆口或椭圆口状且内有环向肌肉,食管呈现出深隧道形状。不同病灶也存在形状差异,息肉是一种小隆起且呈圆形或椭圆形的肉块,溃疡表现为消化道表皮组织平面片状溃烂或隆起。因此,形状特征是内镜诊断的重要信息。为了凸显形状特征,采用Log变换来减少颜色和纹理信息。Log变换原理如式(1)和图1所示。
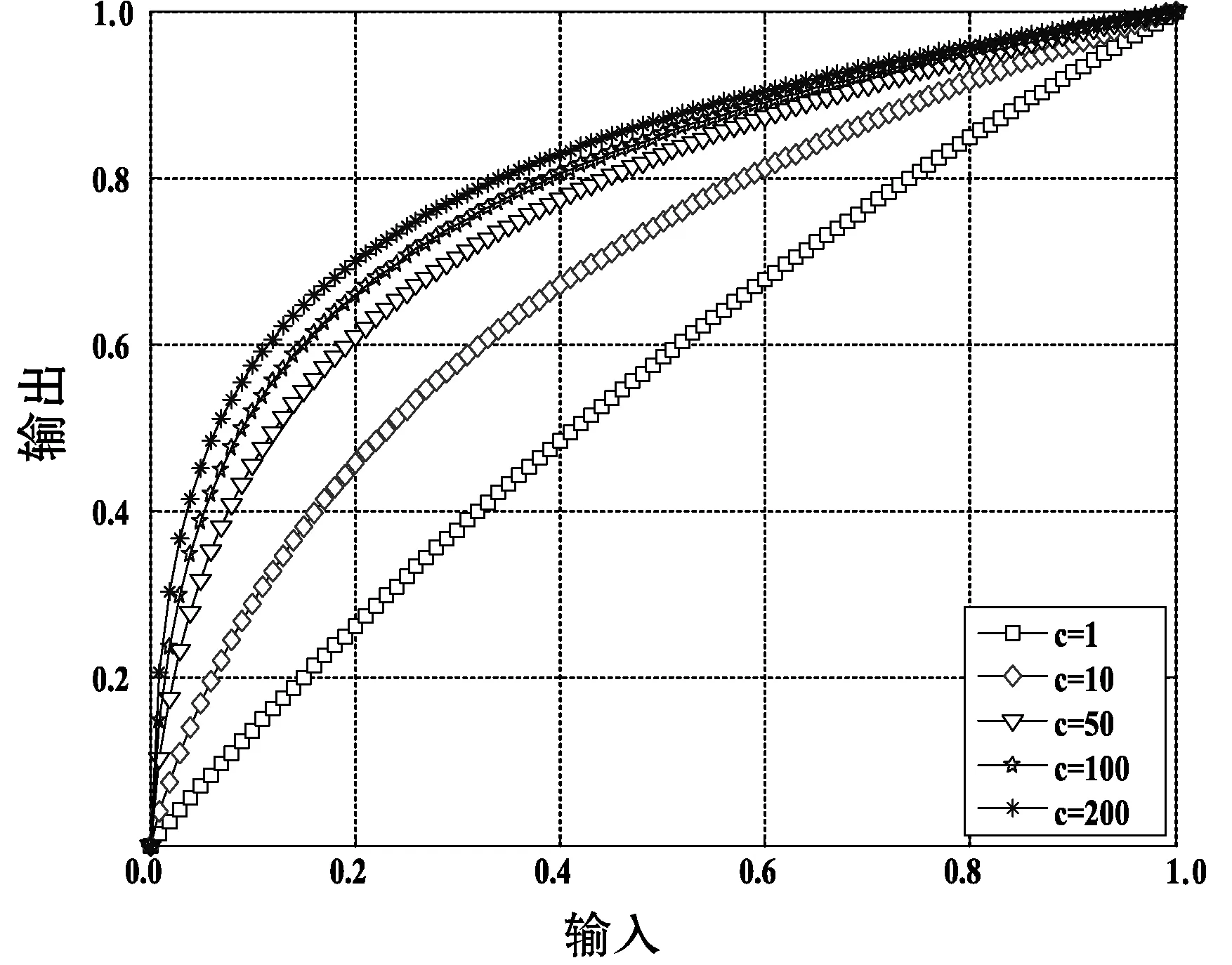
图1 Log变换原理图
(1)
式中:x为输入的灰度值;y为经Log变换后得到的输出灰度值;c为可调常数项,用以调整图像亮度。结合式(1)和图1可看出,输入灰度值大时,函数斜率小,压缩了高灰度区域。相反,灰度值小时,函数斜率大,暗区灰度得到提升与扩展。从而均衡了图像颜色和纹理信息,突出局部形状信息。
取c=10,对胶囊内镜图像Log变换。如图2所示,Log变换提升了内壁皱褶处附近的整体亮度,肠道弱光照的延伸部分的亮度也得到了提高,突出了息肉形状特征。整幅图的灰度梯度得到平均,大大减少了颜色和纹理对形状信息的影响,因此提取Log变换图像作为WCE形状特征。
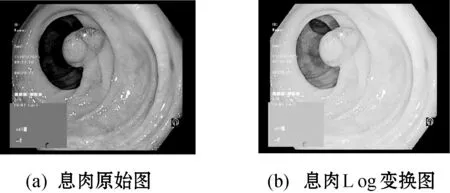
图2 Log变换前后的息肉图像
1.3 直方图均衡化
纹理特征也是区分器官与疾病的信息。食管内壁光滑、纹理不明显,胃呈现出大量较深的褶皱,小肠表面呈绒毛状。息肉表面纹理与所处器官有关,溃疡表面有许多因腐败而产生的小细纹。提升图像对比度能够有效突出纹理特征。
直方图均衡化是一种高效的对比度提升算法。原理如下:
(2)
式中:0≤rk≤1,k=0,1,…,255;Ok为变换后的输出值;rj为灰度值;Pr(rj)是灰度级rj的概率密度函数;nj为包含灰度级rj的数量;n为图像总像素量。该变换使用rj的累计分布函数,生成一幅灰度密度均匀的图像,增加了灰度动态分布范围。对胶囊内镜图像进行直方图均衡化处理,如图3(b)所示。原始图像3(a)中息肉的灰度值得到提高,周围组织的灰度值降低,提高了WCE的对比度,息肉轮廓的梯度得到加强。因此提取直方图均衡化图特征作为WCE纹理特征。
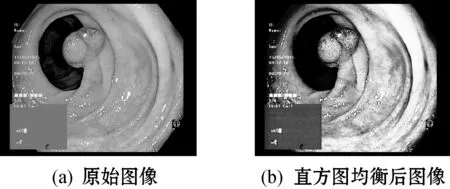
图3 直方图均衡化前后的息肉图像
2 卷积神经网络与特征融合设计
特征提取是图像识别的重要研究内容,传统算法中效果较好的特征提取算法有针对边缘检测的Canny算法、轮廓检测的Douglas-Peucker算法、直线和圆检测的Hough算法以及斑点检测的SIFT算法等。卷积神经网络是一种能自学习核参数的滤波器,在特征提取过程中,能够自动提取图像的深层特征,如纹理、形状和颜色。它大大减少了传统特征提取过程的算法设计和参数设计。因此,本文对预处理过后的三种WCE图像分别应用卷积神经网络,能够自动提取WCE颜色、形状和纹理特征,避免了为不同病灶的不同特征设计专用的特征提取器。之后采用Bagging进行特征融合,比Softmax分类器更充分地融合高层次图像特征,也更快地使网络收敛。
2.1 网络输入
本文使用来自Vestre Viken公司公开的Kvasir数据集[10],包含来自胃肠道(GI)的胶囊内镜图像的数据集。数据集分为8类,按0~7排序,共8 000幅图。即具有解剖标志的Z线、幽门和盲肠,为医生判断图像所处消化道位置提供了导航;具有临床意义的食管炎、息肉和溃疡性结肠炎,属于消化道常见疾病;此外,还有对病灶医学处理后的图像,息肉染色增强和息肉染色边缘切除。数据集分类和标注工作由专业医生完成,每个类包含1 000幅图,均采用JPEG压缩编码。
调整数据集图像大小为224×224,同一幅图分别进行G通道分离、Log变换以及直方图均衡化。将三者分别输入到具有相同结构的卷积神经网络进行特征提取。设计模型如图4所示。

图4 神经网络特征融合模型
2.2 卷积层
将具有特征提取功能的卷积核和神经网络结合,能够自动提取图像特征。VGG网络[11]中采用2个3×3卷积代替5×5卷积,3个3×3卷积代替7×7卷积,实现了相同卷积视野的情况下大大减少参数量。借鉴该小卷积核实现大视野的特点,本网络采用卷积核大小均为3×3,核数量采用随层数递增方式。针对本次数据量,layer-1、layer-2、layer-3核数量分别为64、128和128,对图像低维度特征进行提取;layer-4和layer-5均为256,对高维度抽象特征进行提取。同时,对每个卷积层进行归一化(batch normalization),加快模型迭代的收敛速度。
2.3 池化层
为了充分利用5层卷积层,必须设计池化层,以筛选出有效特征以及提升网络的训练效率。本文全采用最大池化(max_pool),能有效提取局部最佳特征。前4层卷积均采用3×3 max_pool,对有效特征进行优选。为保留高维特征以进行特征融合,layer-5采用2×2max_pool,使卷积层输出结果满足一维向量。
2.4 特征融合
Bagging(bootstrap AGGregatING)是基于自助采样(bootstrap sampling)的经典并行式集成学习方法。首先,从标注好的包含k个样本的数据集随机选取一个样本放入采样集,同时仍将该样本放回数据集,使其在下次采样时仍可能被选中。经过k次操作后,产生了包含k个样本的采样集。由此,可以采样出n个包含k个样本的采样集,然后对每个采样集训练出一个基学习器,将这些基学习器结合,通过投票方法来实现预测。当分类中出现票数相同情况,则根据基学习器的投票置信度来确定结果。
本模型选择Bagging的原因为:
(1) 相比常用的神经网络后期特征融合(AFS_NN),该方法经过多次采样,能够更充分地融合高层次图像特征,实现了小数据量下更好的预测效果。
(2) Bagging能够协助神经网络类基学习器早期停止训练,以减少过拟合现象,比Softmax分类器实现了更快的收敛。
(3) 神经网络类基学习器效果易受样本扰动,从方差角度看,Bagging能够有效降低学习器的方差。
2.5 模型训练
1) 训练流程。
(1) 数据集划分:从原始数据集中随机抽取6 400幅图作为训练集,其中每一类包含800幅图;剩余1 600幅作为测试集,每一类包含200幅图。
(2) 图像预处理:分离出G通道、Log灰度变换和灰度直方图均衡化。
(3) 特征提取:三者分别输入到三个相同结构的神经网络,对每种特征进行提取,三个网络相互独立。
(4) 特征融合:提取的三种特征共768个特征值,输入到一层包含256个神经元的全连接神经网络,再通过Bagging分类器进行分类。
(5) 输出:0~7分别对应了8种分类。
2) 参数设置。
(1) 模型训练方法采用RMSProp算法,learning rate=0.001,rho=0.9, decay=0。
(2) layer6设置dropout=0.5。
(3) batch size=50,epochs=300。
3 实 验
本节对提出的模型进行大量实验。实验在CPU为i7- 7700HQ,GPU为GTX1050,24 GB内存电脑上完成。主要从网络输入、网络训练、损失函数、特征融合算法、传统机器视觉和深度学习等方面进行实验对比,即本模型与RGB输入模型的对比,与不同输入模态模型对比,与不同优化器和损失函数模型对比,与不同特征融合算法对比,与传统图像识别和经典神经网络模型对比。
3.1 与RGB输入模型对比
经典神经网络模型均为RGB输入模型,将WCE图像的RGB三通道直接输入到本文设计的神经网络进行训练与识别,不进行特征融合。为展示图像预处理和特征融合对WCE识别的效果,与RGB输入模型进行对比。图5展示了模型训练周期情况。图6展示了模型ROC曲线。
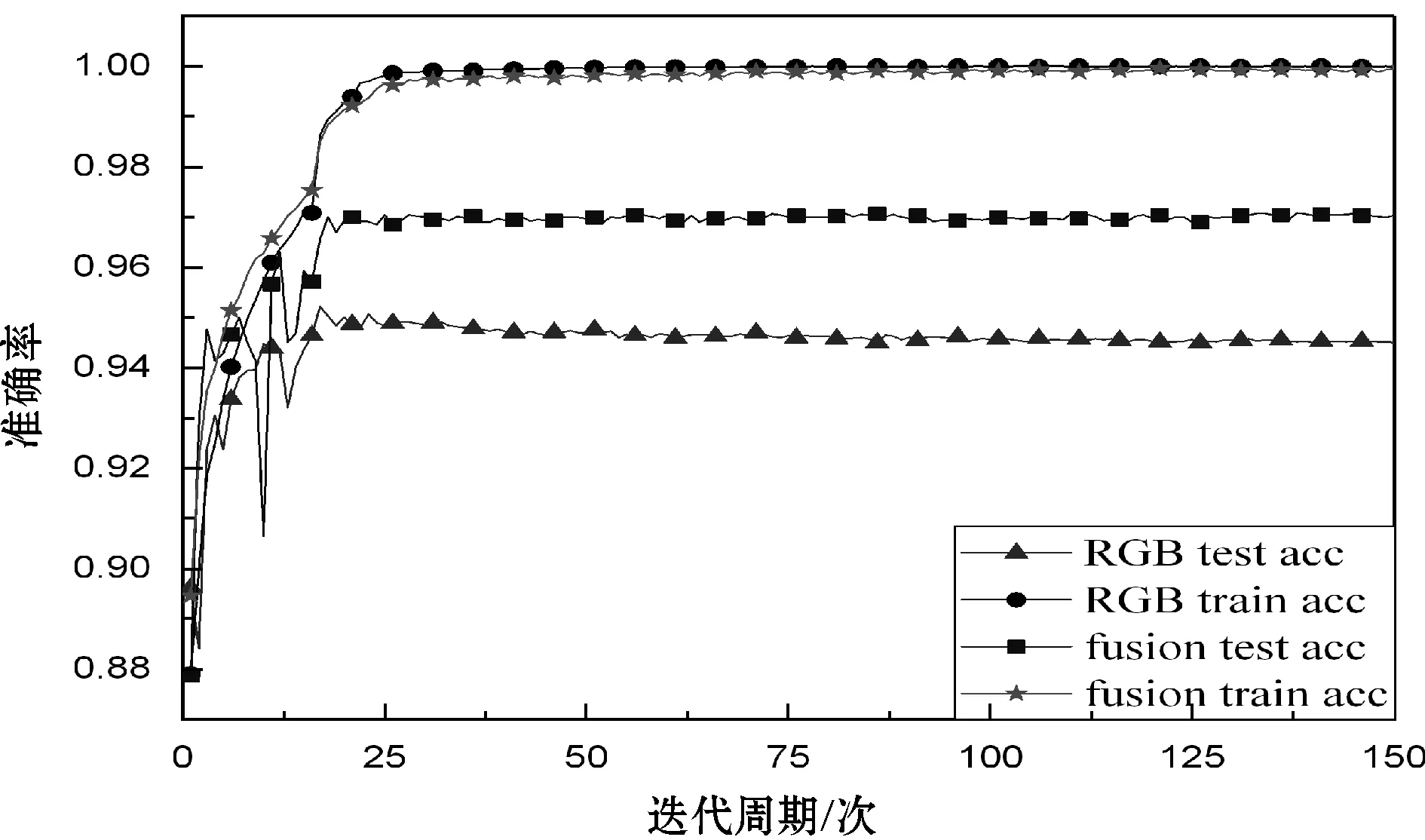
图5 本文模型与RGB模型准确率
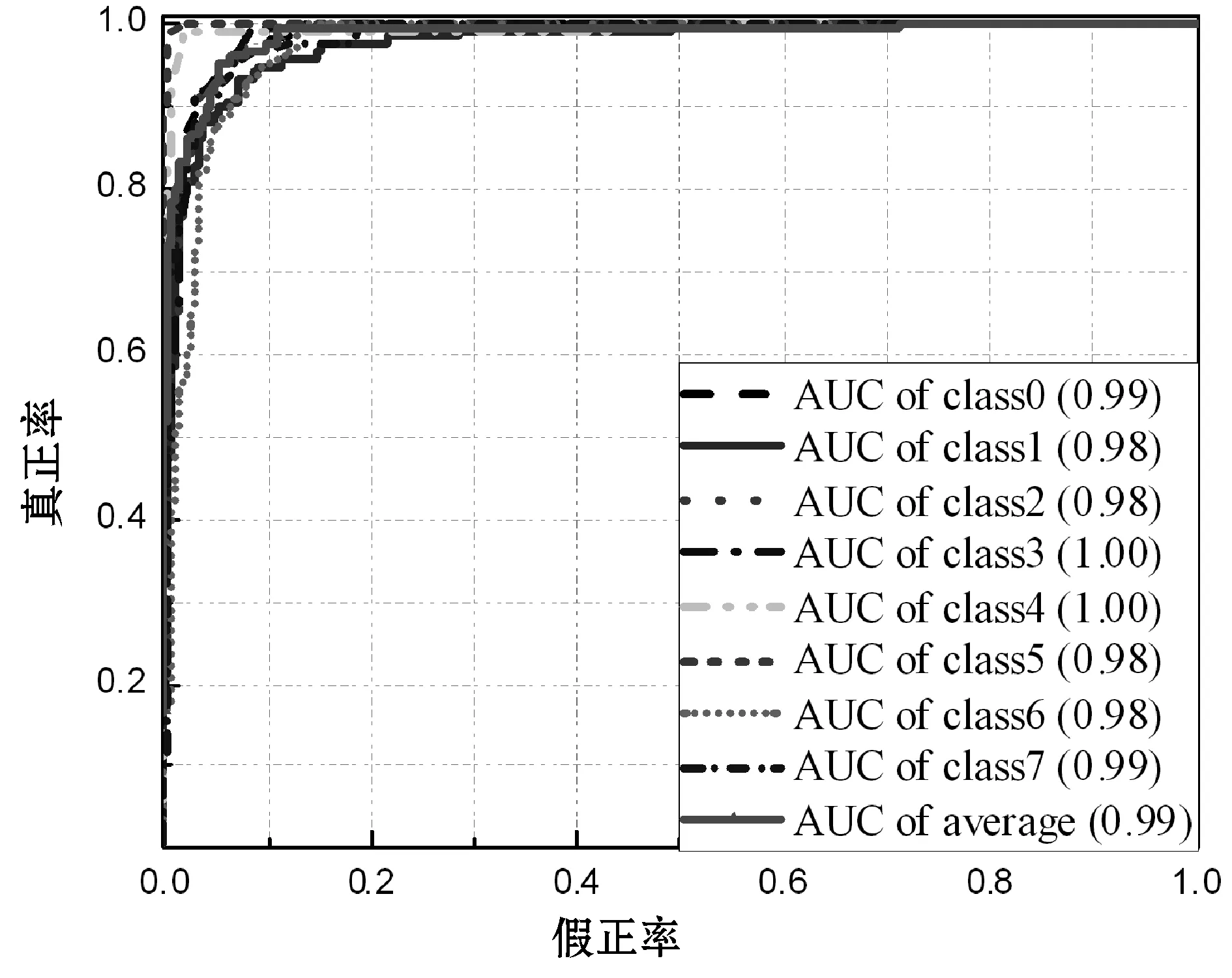
(a) 本文模型ROC曲线

(b) RGB模型ROC曲线
从图5可以看出,本文模型和基于本文神经网络架构的传统RGB模型,迭代周期到40次时都达到了稳定,且未产生过拟合或欠拟合现象,说明本文设置的归一化、dropout和学习率等参数合理,能够加快模型收敛速度。图5中,两模型训练集的准确率相当,达到99.75%。特征融合模型测试集的准确率达到96.89%,比传统RGB输入模型高出2.14%,表明预处理与特征融合明显提升了神经网络识别准确率。
ROC曲线是衡量模型实际效果的工具,其原理为:
fpr=fp/(fp+tn)
(3)
tpr=tp/(tp+fn)
(4)
式中:fp和fn表示正常和异常的错误检测数,tp和tn分别表示正常和异常的正确检测数。称fpr为假正率,tpr为真正率。ROC曲线以fpr为横坐标,tpr为纵坐标。tpr的提高必定伴随着fpr的提高,只有当tpr高且fpr低时,模型的预测效果才好。即ROC曲线越靠近左上角时,模型越好。常用ROC曲线与右侧坐标轴围成的面积(AUC)来衡量ROC,AUC值越接近1,则模型效果越好。
从图6可以看出,本文模型ROC曲线的平均AUC值达到了0.99。每一个类对应的AUC值均不低于0.98,其中盲肠和幽门达到了1.00,足以应用于实际场景。而RGB输入模型的AUC均值为0.98,比前者低0.01。各分类的AUC值分布区间为0.97~1.00,超出本模型0.01,实际应用中出现误判的概率比本文模型高。说明预处理与特征融合模型稳定性优于RGB输入模型。
表2展示了本文模型和RGB输入模型预测指标平均值。其中各指标适用于二分类问题,因此对8类数据分别设计了对应的二分类场景。如计算息肉预测指标时,验证集设置为150幅息肉图像和50幅其他分类图像,并设置息肉为正样本,其余为负样本。表2统计了8分类预测指标的平均值。

表2 本文模型和RGB输入模型预测指标平均值
灵敏度衡量了模型对于正样本的识别率,特异度衡量了模型对负样本的识别率。表2中,本文模型比RGB输入模型的灵敏度高出5.13%,特异度则高出0.13%,即本文模型对正样本的识别能力显著强于RGB输入模型,而对负样本识别能力则几乎持平。考虑所设置的验证集,本文模型的识别能力明显强于传统RGB模型。两模型损失值均为0.05,更加验证了本文卷积网络架构的合理性,能够达到较好的收敛能力。
几种指标的对比说明本文所设计的神经网络具有优秀的收敛能力与稳定性。同时,图像预处理和特征融合能提供更加准确的多元特征,比传统RGB具备更好的识别效果。
3.2 与不同输入模态模型对比
本模型将G通道、Log变换通道和直方图均衡化通道三个模态作为输入。为验证不同模态对模型识别准确率的贡献程度,将R通道、G通道、B通道、Log变换通道和直方图均衡化通道随机组合成3通道,输入本文模型进行训练与识别。10种输入组合的平均准确率如表3所示。其中R、G、B、L和Z分别表示R、G、B、Log变换和直方图均衡化通道。
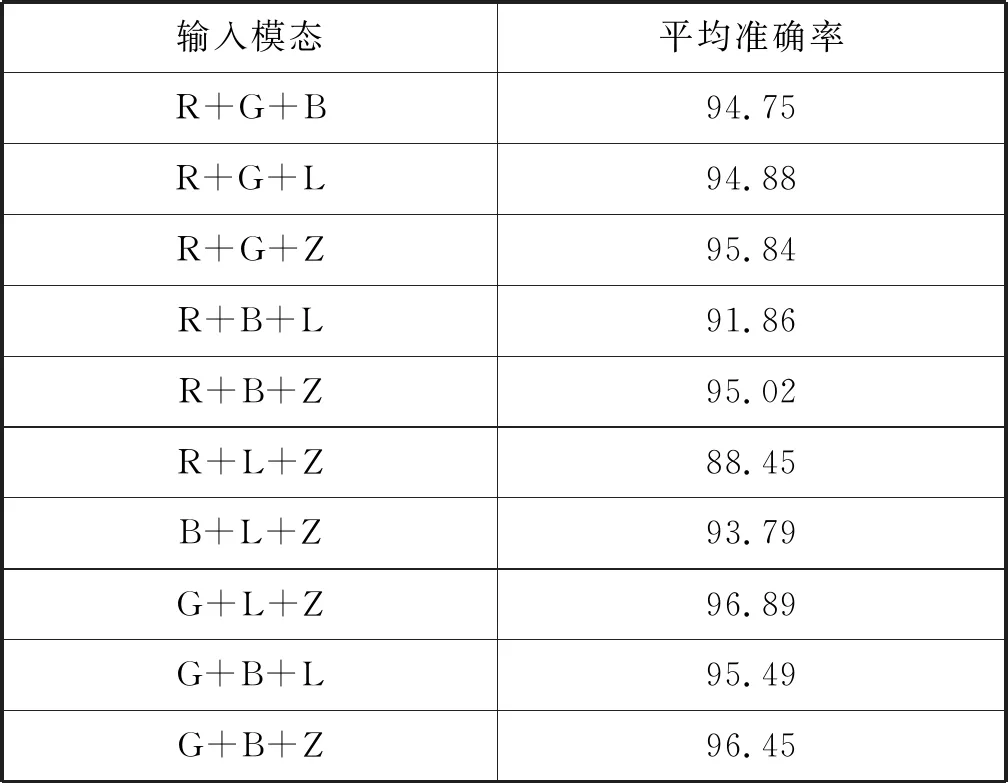
表3 不同输入模态下本文模型的平均准确率(%)
表3中对比R+L+Z、B+L+Z和G+L+Z可知,RGB三种模态中对识别准确率贡献最大的是G通道,表明前述对于G通道包含更多颜色信息的计算是正确的。对比R+G+B和R+G+L,验证了Log变换预处理为卷积操作提供更多图像细节,提升图像识别能力。对比R+G+B和R+G+Z知直方图均衡化预处理对图像识别效果的提升好于传统颜色通道B。因此,本文模型均选择了相同条件下贡献最大的模态作为输入,即G+L+Z,表3也验证了所选模态达到了最高准确率。
3.3 与不同优化器、损失函数模型对比
为了得到模型最佳的训练效果,本文测试了三种常用优化算法和三种损失函数,即均方根反向传播算法(RMSprop)、带动量的随机梯度下降算法(SGD+Nesterov_Momentum=0.9)和Adagrad,以及均方误差损失函数(mean_squared_error)、二元交叉熵损失函数(binary_crossentropy)和交叉熵损失函数(categorical_crossentropy)。实验结果如表4所示。
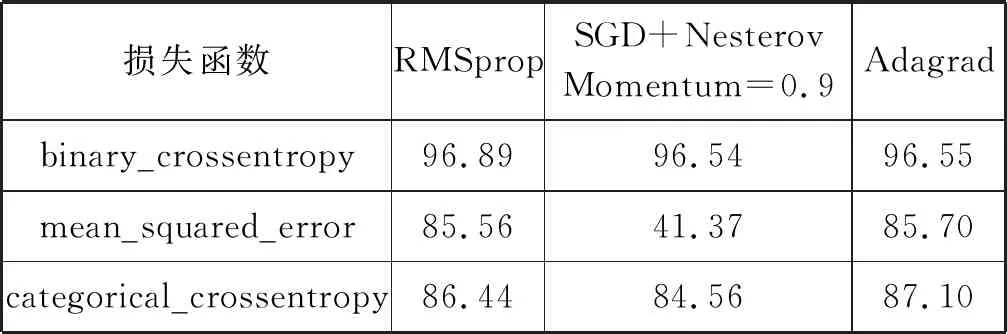
表4 不同优化算法与损失函数的平均准确率(%)
表4中,采用二元交叉熵损失函数时,三种优化算法准确率均高于96.5%,其中RMSprop达到96.89%。均方误差损失函数下,Adagard准确率比RMSprop高0.14百分点,而带动量的随机梯度度下降算法准确率为41.37%,不足50%,不具备优化能力。采用交叉熵损失函数时,Adagrad准确率最高。可见,二元交叉熵损失函数与RMSprop结合效果最好,后两个损失函数与Adagrad结合效果最好。因此本文选择准确率最高的二元交叉熵损失函数和均方根反向传播算法进行训练。
3.4 与其他特征融合算法对比
本文模型采用Bagging特征融合算法替代了常规Softmax分类算法。为了评估Bagging算法对特征融合的贡献程度,将模型中特征融合算法改为Softmax分类器、随机森林分类器(RF)、SVM分类器,保持模型其他部分不变,与本文模型进行对比。实验结果如表5所示。
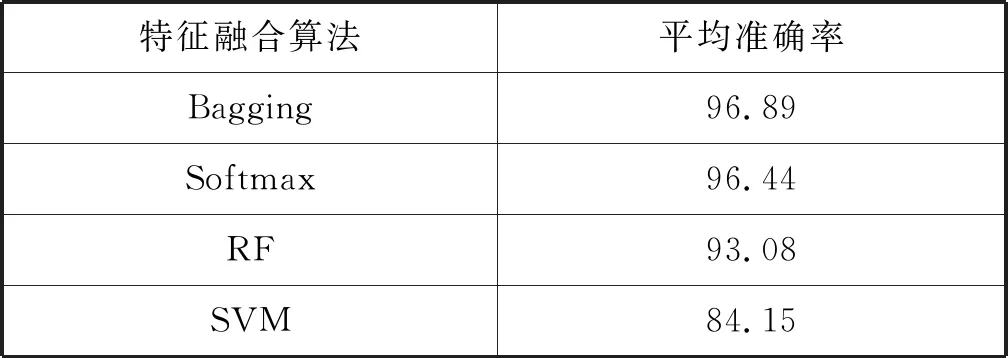
表5 不同特征融合算法平均准确率(%)
表5中,Bagging进行了多次采样操作,以及具备快速收敛能力,因此准确率比Softmax算法提升了0.45百分点。随机森林分类器同样采用了多次采样操作,但通过多棵决策树训练的方式增加了算法复杂度,对数据量要求较高,准确率比Bagging低3.81百分点。SVM分类器属于较低维的线性分类器,而本文Layer6输出的抽象特征属于高维特征,因此SVM分类效果较差,只有84.15%,远低于Bagging。可见,本文提出的利用卷积网络和Bagging特征融合的模型比传统Softmax等分类器更具优势。
3.5 与传统机器视觉和经典网络模型对比
所提出的模型是将传统机器视觉中的图像预处理与经典神经网络相结合,为了展示本文模型的优势,分别与几种传统机器视觉模型和经典神经网络进行了对比,结果如表6所示。

表6 不同模型各分类准确率比较(%)
(1) ResNet和AlexNet:借助深度神经网络和百万训练数据量,对常规图像识别准确率超过90%。
(2) GIST:基于一维感知(自然、开放、粗糙、膨胀和险峻)的特征检测算子,主要用于空间结构的特征检测;
(3) SIFT:基于图像尺度、角度等空间特征不变量的斑点特征检测算子,用于局部特征提取。
(4) COLOR:基于k_means聚类出的128个颜色描述符,进行颜色特征提取的算法。
表6中,神经网络类模型准确率普遍高于传统机器视觉,尤其对于息肉和溃疡等病灶的识别效果显著好于GIST、SHIFT和COLOR。GIST+SIFT和SIFT+COLOR识别染色息肉和染色切除的准确率明显高于其他分类,对于包含复杂特征的息肉、幽门和Z线等识别较差。可见传统机器视觉模型对于复杂分类的效果较差。ReNet和AlexNet网络结构复杂,待训练的参数量高达62 M。宝贵的医疗数据只能在预训练的ResNet和AlexNet网络上进行微调。两者准确率分别为94.72%和94.84%,高于传统模型至少10.23百分点,但是由于预训练数据和胶囊内镜图像存在较大差异,两模型准确率受到了限制。本文模型参数量不足2 M,可以直接训练小数量级WCE图像,平均准确率能达到96.89%,比其他模型高出2.05百分点以上。其中两类疾病,息肉和溃疡性结肠炎准确率均高于其他模型1.3百分点以上。表明本文模型对于复杂分类和小数量级数据的训练具有更好的效果。
4 结 语
深度学习在医疗领域的应用,可以大大提高医生诊断效率。因此,本文构建了基于神经网络与特征融合的胶囊内镜图像识别模型。该模型首先通过预处理获取颜色、形状和纹理信息突出的图像,采用卷积神经网络分别提取其不同特征,再用Bagging算法对提取的特征进行融合与识别。同时设计了大量实验验证该模型。
所用测试集包含了肠道定位、疾病病灶和疾病医学处理等方面的图像,使得模型的训练更加符合实际应用场景。尤其对于息肉病灶的识别非常重要,近年来针对WCE定位和溃疡检测的研究较多,准确率为70.60%~95.61%[12-15],却少有对息肉识别的研究。Zhang等[16]在预训练250万个非医学数据集的特征后,实现了87.3%的息肉识别准确率。而本文模型首次尝试将卷积特征提取与Bagging特征融合相结合,可直接训练息肉图像,并达到了96.42%的准确率以及0.99的AUC值,远高于传统机器视觉(SVM、GIST+SIFT等)和现有深度学习(RGB模型、ResNet等)识别准确率,开创了新的基于深度学习的息肉识别方法。本文的训练集仅包含6 400幅图像,8分类平均准确率达到了96.89%,相同准确率下数据量要求远小于其他大型神经网络。可知对图像进行预处理以突出特征的方法,能够在小数据量情况下实现神经网络的良好识别效果,解决了医疗领域数据宝贵的困境。最后,本文模型在各项指标中均取得了良好成绩,实际应用中能够辅助医生进行疾病诊断。
未来的研究还有几方面需要完成:
(1) 提高模型的鲁棒性。实际WCE图像中,光照强度随镜头位置改变而变化,清晰程度也受到聚焦距离影响,肠道清洁程度更加影响病灶识别。需要针对上述干扰因素来提高模型的鲁棒性。
(2) 提升模型复杂度。本文模型是基于小数据量设计的,随着数据量的增加,需要增加神经网络层数、增加功能模块、更加精确的特征预处理以及更加符合WCE图像的网络设计。
(3) 搭建基于在线学习的云服务平台。消化道疾病一直在发展变化,基于在线学习的识别模型才能够满足疾病特征的时效性。云服务平台能够整合医疗领域出现的新病例、提供网络诊断功能,大大提升诊断效率。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
家庭医学(下半月)(2020年3期)2020-05-30 12:42:10
电子制作(2019年11期)2019-07-04 00:34:38
中国生殖健康(2019年3期)2019-02-01 06:12:08
中国交通信息化(2018年5期)2018-08-21 03:37:40
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
中国当代医药(2015年31期)2015-03-01 02:08:23
