
复杂噪声环境下语音识别研究
2021-09-15 02:36张允耀黄鹤鸣张会云
计算机与现代化 2021年9期
张允耀,黄鹤鸣,张会云
(1.青海师范大学计算机学院,青海 西宁 810008; 2.藏文信息处理教育部重点实验室,青海 西宁 810008)
0 引 言
语音是人与人之间交流的一种重要方式,随着人工智能(Artificial Intelligence, AI)时代的到来,语音逐渐成为人机交互的重要发展途径之一。语音与通信密不可分,而通信是一个编码与解码的过程,可以将语音理解为信息的一种编码形式,接收方收到语音后,通过特定规则解码语音以获得信息。自动语音识别(Automatic Speech Recognition, ASR)[1]是计算机将人类语音信号转录为文本的过程。一般来说,ASR研究可分为孤立词语音识别、连续语音识别、大词汇量连续语音识别、语音情感识别、说话人识别(声纹识别)以及语音增强等内容。其中,孤立词语音识别是自动语音识别的基础,因此,对孤立词识别的研究具有重要意义。
语音识别过程通常包括预处理、特征提取、声学建模、语言建模等几个阶段[2]。在传统的语音识别任务中,上述各部分的训练过程往往是相互独立的。相较于联合训练,这种方法可能无法很好地适配具体的识别任务,即提取的特征可能与具体的识别任务不匹配,从而导致识别率下降。梅尔频率倒谱系数(Mel Frequency Cepstrum Coefficient, MFCC)是传统语音识别中最具代表性的特征,由于MFCC特征的提取早于模型训练,没有进行二者间的联合训练,而且该特征中语音的高频部分损失较大,导致所提取的特征与识别任务并不完全匹配[1]。
本文引入深度自编码器(Deep Auto Encoder, DAE)为特征提取器,使用双向长短时记忆网络(Bidirectional Long Short Term Memory Networks, BiLSTM)作为声学模型,并将两者进行联合训练,从而找到最适合识别任务的特征,同时使模型之间的匹配度达到最高,进一步提升识别率。
衡量一个语音识别系统性能的指标有识别率、鲁棒性以及泛化性。一般语音识别系统对于干净语音表现出很好的识别性能,而对于含噪语音识别性能较差,为此,需对语音进行增强。传统的语音增强方法有:谱减法、维纳滤波、基于统计模型的方法和基于子空间的方法等[3]。而针对复杂噪声环境下语音识别来说,目前的方法主要集中在特征提取与声学模型上,如何在复杂噪声环境下提取出更具鲁棒性的特征与训练更具鲁棒性的声学模型是重中之重。
近年来,随着深度学习兴起,语音识别领域的研究者相继将迁移学习、自编码器、循环神经网络等技术应用于鲁棒性语音识别,并取得了可观的性能[4-8]。
在迁移学习中[4],可以将声学模型分为特征提取层和分类器层,由于含噪语音与干净语音之间具有共性,因而可以使用迁移学习技术来提高语音识别系统的鲁棒性。具体的操作流程为:首先,使用干净语音训练一个较好的语音识别模型;然后,迁移该模型的特征提取层参数并重新初始化分类器层;最后,使用含噪语音重新训练,其中特征提取器层参数保持冻结或给予较小的学习率来更新;另外,通过阅读相关文献可以发现基于迁移学习,可以迁移分类器层参数,而重新初始化特征提取器层参数,通过冻结分类器层参数来胁迫特征提取器层学习含噪语音与干净语音之间的共性特征。上述特性都可以提高语音识别系统的鲁棒性。
自编码器网络可以实现输入特征的编码和解码[8],可以提取输入语音的关键特征向量,相较于传统的MFCC,这种特征具有更多的原始信息,从而能够更好地表征语音。
循环神经网络(Recurrent Neural Network, RNN)隐藏层之间的结点是有连接的,隐藏层的输入不仅包括输入层的输出,还包括上一时刻隐藏层的输出,这种连接特性能使RNN对序列数据进行很好建模[9]。LSTM是一种特殊的循环神经网络,它通过记忆单元和门控机制对先前时刻的信息进行选择性记忆。语音是序列性数据,当前词既与上文信息有关又与下文信息有关,而BiLSTM可从正反2个方向对数据进行训练,因此,引入BiLSTM对语音进行上下文建模。
本文通过使用DAE来提取含噪语音与干净语音之间的噪声不变特征[10],结合迁移学习的思想,将DAE的特征提取器层迁移并与声学模型结合,以此来提高噪声数据训练下的识别准确率。
1 自编码器网络
含噪语音与干净语音之间具有一定的相似性,为了有效提取这种相似性特征,本文采用自编码器来提取。为了保留更多的原始信息,采用含噪语音的FBANK[11]特征作为输入,该特征拟合人耳接收的特性,符合声音信号的本质。传统的MFCC特征需要进行离散余弦变换(Discrete Cosine Transform, DCT),而DCT变换是线性的,这种操作会丢失原语音信号中的一些非线性成分。与传统的MFCC特征相比,FBANK特征因为不需要DCT变换,因而具有更多的原始特征。此外,本文采用均方误差(Mean Squared Error, MSE)作为目标函数来最小化含噪语音与干净语音之间的差异。
传统的自编码器包括普通自编码器、多层自编码器、卷积自编码器、降噪自编码器以及正则自编码器[12]等多个类型。自编码器一般分为编码器和解码器2个部分,如图1所示。
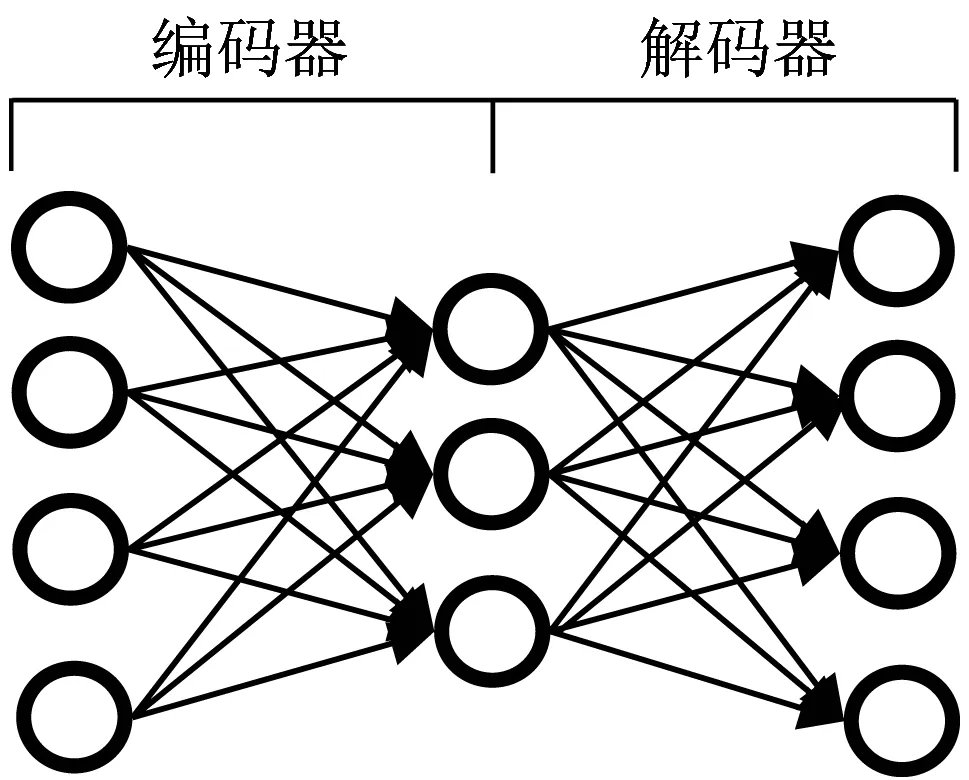
图1 自编码器结构
图1展示的是一个自编码器结构,输入层到隐藏层之间的网络结构被称为编码器,实现输入特征的压缩和编码;隐藏层到输出层之间的网络结构被称为解码器,实现中间隐藏层神经元输出的解压和解码。
DAE是自编码器的一种变体,本文构造具有多个隐藏层的深度自编码器来提取噪声的不变特征。自编码器结构中,编码器的第一层输出h1为:
h1=f(wijxi+bj)
(1)
其中,xi是44维的含噪语音特征向量,wij为权重矩阵,bj为偏置向量。第一层的输出h1是第二层的输入,第二层输出h2的计算方式与h1的计算方式一致,以此类推。最终的相似性特征,即自编码器网络中间隐藏层的输出。
为了通过训练使模型得到更好的性能,采用均方误差(MSE)损失函数指导训练过程。MSE损失函数定义为:
(2)
其中,X表示干净语音,Y*表示自编码器网络的输出。通过均方误差损失函数可以很容易计算出含噪语音与干净语音之间的差别。相较于其它损失函数,均方误差损失函数更加直观更容易理解。
2 LSTM声学模型
RNN能够有效处理时间序列数据,因此,RNN处理语音数据时有较好的性能。在语音识别中,当前词与上下文信息密切相关,通过循环机制可以很好地对其进行建模。但RNN存在梯度爆炸以及梯度消失问题,LSTM是RNN的一种变体[13-14],它巧妙地通过门控机制引入加法运算来缓解RNN中的梯度消失,从而较好地解决了梯度问题。图2展示的是LSTM的基本单元结构。
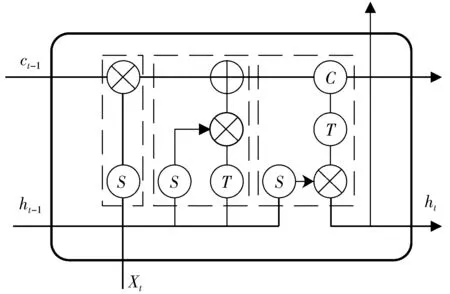
图2 LSTM单元结构
图2中,从左至右的虚线框区域分别为遗忘门、输入门和输出门,S结点表示Sigmoid激活函数,T结点表示Tanh激活函数,ct-1表示前一时刻细胞单元状态,C表示当前细胞单元状态,Xt表示当前的输入,ht-1表示前一时刻的输入,ht表示当前时刻的隐状态。具体的计算公式为:
ft=σ(Wfxt+Vfht-1)
(3)
it=σ(Wixt+Viht-1)*tanh(Wixt+Viht-1)
(4)
ct=ct-1*ft+it
(5)
ot=σ(Woxt+Voht-1)
(6)
ht=ot*tanh(ct)
(7)
在式(3)~式(7)中,Wf、Wi、Wo分别是上一隐层与当前记忆单元的遗忘权重、输入权重和输出权重,Vf、Vi、Vo分别是同一层隐状态之间的遗忘权重、输入权重和输出权重,σ(·)代表激活函数sigmoid,*代表点积运算。激活函数Sigmoid的取值范围是(0,1),表示在遗忘门中当前细胞单元被遗忘的概率,在输入门中表示当前输入信息中被输入到细胞单元的信息占比,而在输出门中表示更新后的细胞单元信息被输出到下一个LSTM单元的占比。
BiLSTM网络从正反2个方向对输入的数据进行训练,可以学习到更多的上下文信息。而且通过堆栈双向长短时记忆网络(Stack_BiLSTM)[15]能够增加神经网络的深度,从而学习到更抽象的高层隐特征向量。因此,本文在声学建模中主要使用BiLSTM。
3 模型联合训练
预训练好自编码器模型后,保留其参数及结构,将其迁移到声学模型进行联合训练,通过微调参数使其完全匹配声学模型处理的任务。相应的模型架构如图3所示。

图3 迁移后的联合模型架构
通过图3得知,自编码器拥有多个隐藏层结构,其中,编码器由5层Dense构成,解码器由4层Dense构成。训练好该模型后,将编码器层参数迁移到声学模型中。
声学模型由2层BiLSTM网络以及全连接层构成,使用Softmax激活函数得到每个样本的预测概率,利用交叉熵损失函数(Cross Entropy Loss, CE)对网络模型进行训练。其中,Softmax激活函数的定义为:
(8)
而函数LCE定义为:
(9)
4 实 验
本文在Google Commands数据集上设计了不同的对照实验以验证本文提出模型Encoder+Stack_BiLSTM+Fine的有效性,实验所采用的评价指标是准确率与混淆矩阵。
4.1 数据集
Google Commands数据集包含30个类别的孤立词语音,每个类别包含不同年龄段的男声、女声以及不同语速的语音片段等,语音内容主要包括数字和命令词。分别从每种语音类别中随机抽取500条样本,共计得到15000条样本。数据集的采样率为2.205 kHz,以16 bit量化存储为WAV格式。
将干净语音分别与粉红噪声(pink_noise)、高斯噪声(white_noise)、exercise_bike、doing_the_dishes、dude_miaowing、running_tap等6种不同类型的噪声混合,信噪比类型设置为0 dB与5 dB。在验证鲁棒性层面,主要使用含高斯噪声的含噪语音来验证,并将其划分为训练集和测试集,验证泛化性层面,使用含其它噪声的含噪语音来验证。
4.2 实验设置
本文的实验主要为了验证在低信噪比情况下含噪语音是否能够保持一定的识别率,因此,本文实验过程中,以信噪比0 dB与5 dB为例。
具体的信噪比公式为:
(10)
其中,Psignal为信号功率,Pnoise为噪声功率,Asignal为信号幅度,Anoise为噪声幅度。信噪比越大,表明噪声所占比重较少,语音比较清晰,而信噪比越小,表明噪声所占比重较多,语音受到的破坏比较严重。
本文整体模型的训练过程为:1)对孤立词语音进行标注;2)使用python_speech_feature库提取含噪孤立词语音的FBANK特征并将其用于DAE训练;3)从DAE中提取噪声不变特征,用于声学模型的训练。
本文采用一定的规则挑选特征,舍弃维度小于44的特征,得到40×44的FBANK特征。同时采用深度学习框架Tensorflow、Keras进行声学模型的构建。为了更加直观地看出含噪语音与干净语音之间的差别,本文使用信噪比为0 dB的高斯噪声混合。图4为干净语音的语谱图,图5为混合高斯噪声后语音的语谱图,其中,横轴表示时间、纵轴表示频率。对比图4和图5可以看出:1)在相同时间点,2个语音信号在不同频率上的能量不同;2)相较于图4,图5丢失了很多细节。由于在实际生活中需要处理的语音往往带有噪声和混响,因此,增强语音识别系统的鲁棒性与泛化性至关重要。

图5 含噪语音的语谱图
4.3 模型鲁棒性对比实验
本文采用深度神经网络(Deep Neural Network, DNN)为基线模型,进行模型鲁棒性对比实验,主要研究在低信噪比情况下含噪语音的识别准确率。为了验证本文所提出方法的有效性,首先,训练拥有9个隐藏层的DAE;其次,数据预处理后将含高斯噪声的含噪语音作为训练数据,干净语音作为标签,优化器采用RMSprop[17],激活函数使用SELU[18],为了加快模型训练速度,本文方法加入了批标准化层(Batch Normalization, BN);最后,使用损失函数MSE衡量网络输出分布与干净语音之间的差别。表1对比了在使用不同激活函数的情况下,DAE达到的损失值。

表1 不同激活函数下的损失
通过对比上述使用3种不同的激活函数得到的损失,可以发现在使用SELU激活函数时取得了最低的损失值,探究原因,SELU可以使训练数据自动归一化到零均值和单位方差,因此,使用SELU不仅可以提高训练速度,而且可以取得更低的损失。
训练DAE的过程中,通过迭代200个epoch,发现DAE损失下降至21.03%左右,并趋近于收敛,以此判断出DAE训练的终止条件。在迭代中,损失函数的变化过程如图6所示。

图6 自编码器训练损失
为了构建具有一定鲁棒性的语音识别系统,首先,在干净孤立词数据集上提取FBANK特征;然后,用该特征分别训练DNN、CNN[19]、BiLSTM以及Stack_BiLSTM声学模型;最后,使用含高斯噪声的孤立词数据集进行评估。每种实验的epoch均设置为100。对比实验如表2所示。
表2中,本文所提出的语音识别系统编号为5和6,其训练过程为:1)通过自编码器提取含噪孤立词语音的噪声不变特征;2)用该特征训练声学模型Stack_BiLSTM;3)对级联噪声自编码器的编码器层进行语音识别。其中,编号为5的识别系统,Encoder为固定参数;编号为6的识别系统,Encoder采用Adadelta优化器给予较小的学习率进行微调,而使用含噪语音关键特征训练好的Stack_BiLSTM参数保持不变,以辅助Encoder进一步学习噪声不变特征。
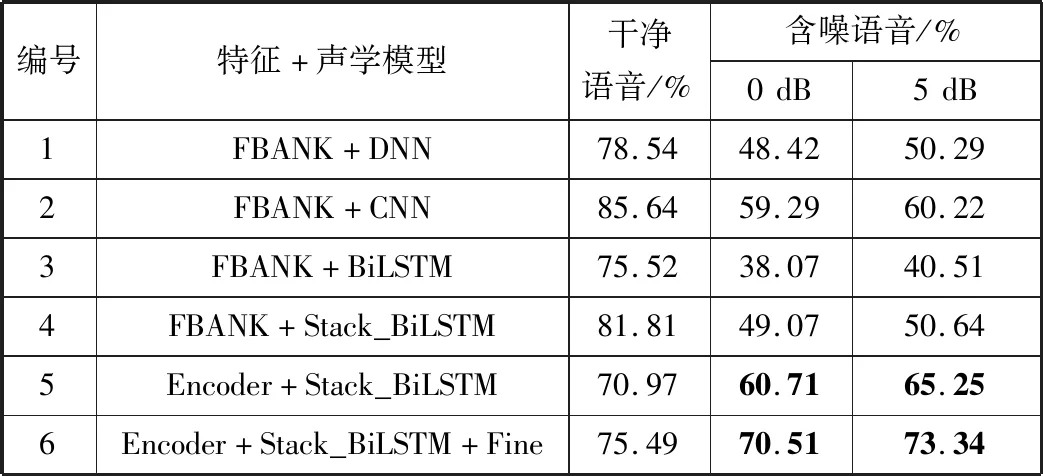
表2 不同信噪比含噪语音在各声学模型中的识别率
通过对比表2中编号1~编号4的识别系统的性能发现:无论是对干净语音还是含噪语音,CNN的识别准确率均为最优。这是由于使用不同尺度的卷积核形成了不同空间维度的特征图。然而,CNN存在耗时长、计算量大的问题,故本文没用采用。通过表2可以看出:DNN与Stack_BiLSTM的性能差别不大,但BiLSTM更加符合具有序列性的语音。因此,本文选用Stack_BiLSTM作为声学模型。
通过与基线模型相比,可以得出编号为6的识别系统的识别准确率在信噪比为0 dB时提升了约22个百分点,在信噪比为5 dB时提升了约23个百分点;与传统模型结构中识别率最高的CNN相比,本文提出的方法在信噪比为0 dB时提升了约11个百分点,而信噪比为5 dB时提升了约13个百分点。但是由于本文所提出模型是在含噪语音条件下提取相似性特征训练而成的,故直接使用干净语音进行测试性能有所下降。
相较于基线系统,本文提出的模型每个epoch需要2 s,而基线系统的每个epoch需要1 s,虽然时间复杂度增加了,但总体识别率得到了一定提升,从而验证了本文方法确实可以提高低信噪比情况下语音识别的识别率。
4.4 模型泛化性对比实验
这里本文利用除含高斯噪声外的含噪语音来验证本文所提出方法的泛化性。为了简洁,用model A表示Encoder+Stack_BiLSTM,用model B表示Encoder+Stack_BiLSTM+Fine。
通过对比上述2种模型在其余5种含噪语音上的识别率,可以判断模型是否提取到了噪声语音和干净语音之间的相似性特征,即噪声不变特征,由此判断联合优化训练是否取得了更好的识别结果。表3和表4是2种模型在其余5种不同信噪比含噪语音上的对比实验。
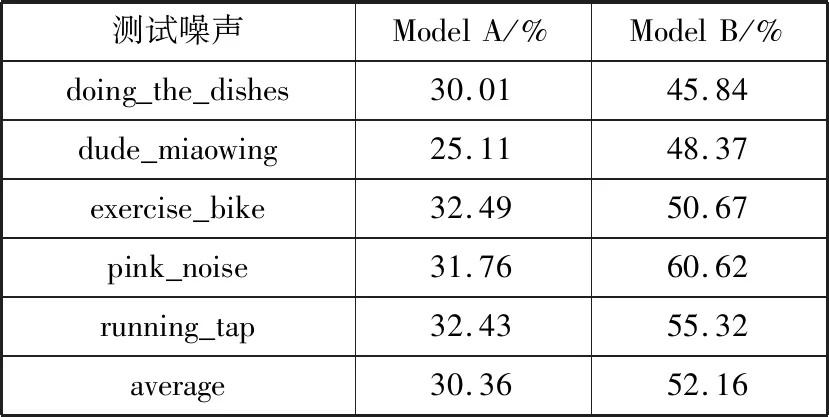
表3 SNR为0 dB时2种模型的识别结果
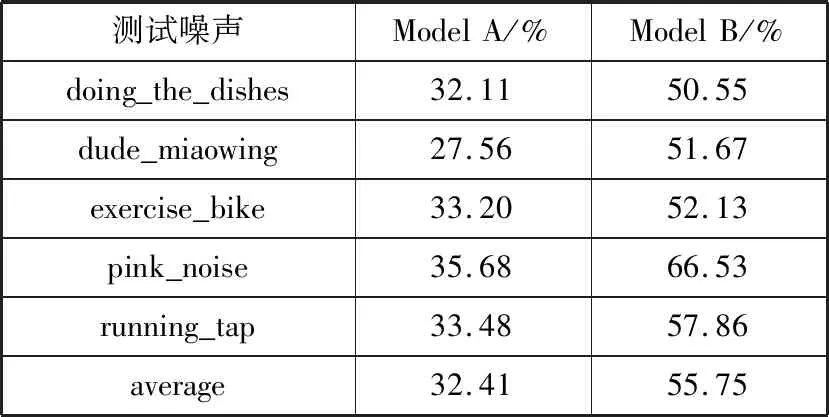
表4 SNR为5 dB时2种模型的识别结果
从表3、表4可以看出:
1)在pink_noise噪声条件下,Model B的识别性能最好,准确率在信噪比为0 dB与5 dB时分别达到了60.62%与66.53%的识别效果,这是因为该类型噪声与white_noise较为接近,都属于平稳噪声,相对于不平稳噪声来说,比较容易识别。
2)整体而言,在5个测试集上,无论是信噪比为0 dB还是5 dB,Model A与Model B均表现出了较为稳定的识别率,表明2类模型的泛化性较好。
3)2类模型的平均识别率相差较大,根据表中的结果,信噪比为0 dB时,Model A的平均识别率为30.36%,而Model B的平均识别率为52.16%,信噪比为5 dB时,Model A的平均识别率为32.41%,而Model B的平均识别率为55.75%。表明经过微调,Model B的性能更优。
4.5 评价指标
除了识别准确率,本文还采用混淆矩阵[20]评估模型性能。在混淆矩阵中,每一行代表每个类别所含语音样本的数量,每一列代表预测为该类别的语音样本数量,对角线数字表示相应类别的语音样本被正确识别的数量。对角线颜色越深,表示对应的语音样本识别准确率越高。
图7展示了本文方法Encoder+Stack_BiLSTM+Fine模型测试在信噪比为0 dB时含高斯噪声的含噪语音所得到的混淆矩阵。
从图7可以看出:孤立词sheila有394个样本被正确识别,准确率为78.8%,这是一个比较可观的识别结果;孤立词one仅有181个样本被预测正确,识别准确率仅为36.2%,说明噪声严重破坏了语音细节特征;将孤立词one识别为on的次数为47,识别为no的次数为49,说明孤立词on和no与孤立词one的语谱图相似。
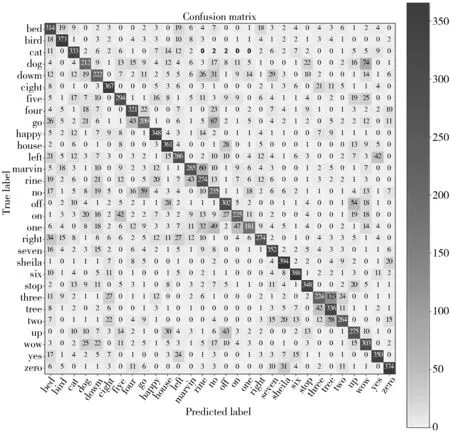
图7 本文方法在White_noise上的混淆矩阵
4.6 网络性能对比
为了突出本文所提出模型性能的优势,验证该方法确实可以提高低信噪比情况下语音识别的性能,现使用前人的研究方法进行实验并与本文方法进行对比。具体的实验结果对比如表5所示。
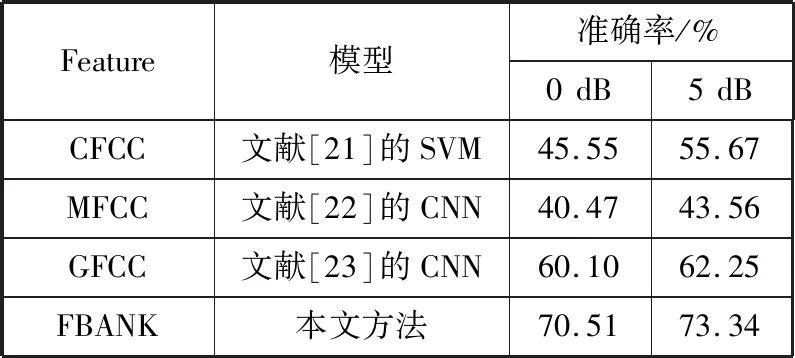
表5 本文方法与其他模型的性能对比
在表5中,上述前人的成果因所使用的数据集均不同,故只能借鉴前人的研究方法,通过在本文所使用的数据集上进行实验得到上述结果。通过对比发现,本文所提出模型无论信噪比为0 dB还是5 dB,均表现出了较好的识别结果。
5 结束语
本文提出了一种新的提升含噪语音识别鲁棒性与泛化性的声学模型Encoder+Stack_BiLSTM+Fine,该模型由DAE和Stack_BiLSTM组成。其中,DAE用于特征提取,Stack_BiLSTM用于声学建模,在声学建模过程中,迁移DAE中编码器的结构和参数。在含噪Google Commands数据集上的实验表明,该模型具有很好的性能,同时具有较好的泛化性。
在以后的研究中,将不断改进深度自编码器的结构以及使用不同类型的声学模型,以此来探索更有效的增强鲁棒性的方法。
猜你喜欢
家庭影院技术(2020年6期)2020-07-27
计算机工程(2020年3期)2020-03-19
农业机械学报(2020年2期)2020-03-09
中华建设(2019年7期)2019-08-27
中国听力语言康复科学杂志(2019年3期)2019-06-24
家庭影院技术(2019年1期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年10期)2018-11-02
中国交通信息化(2018年3期)2018-06-13
项目管理技术(2016年12期)2016-06-15
