
基于PLS-MI组合的天牛须搜索BP神经网络模型对汽油辛烷值的预测性能
2021-09-15 00:46石翠翠刘媛华
石油炼制与化工 2021年9期
石翠翠,刘媛华
(上海理工大学管理学院,上海 200093)
目前,中国石化下属炼油厂的催化裂化汽油脱硫主要采用S Zorb工艺[1]。由于S Zorb工艺装置非常复杂,因而影响精制汽油研究法辛烷值(RON)的特征变量间存在高度非线性和相互强耦联的关系。传统关联分析和机理模型对高维度数据集的分析效果不理想,会造成催化裂化汽油精制过程的参数优化不及时,从而导致汽油产品辛烷值损失增大。因此,在对催化裂化汽油进行精制处理时,如何从S Zorb装置的操作条件、原料性质、待生吸附剂性质与再生吸附剂性质等方面精确预测汽油产品的辛烷值并进行影响因素分析,成为降低汽油辛烷值损失的难点问题。
随着汽油辛烷值数据不断向非线性、多模态等复杂系统方向发展,中国石化企业实验室信息管理系统(LIMS)获取的数据集转向非正态分布[2-3],导致基于传统特征变量选择方法模型的预测效果变差。因此,如何有效剔除冗余特征变量,建立新的特征变量选择方法是提高汽油辛烷值模型预测精度的关键[4]。为此,很多学者进行了有益的探索。Albahri[5]利用基团贡献法预测汽油的RON和马达法辛烷值(MON),发现基团贡献法只考虑基团之间的线性组合,其预测模型的稳定性差。Saldana等[6]研究发现定量结构性质关系(QSPR)模型在预测燃料十六烷值时的性能优于其他模型。Mendes[7]和Bao Xin等[8]发现采用偏最小二乘回归法预测汽油RON具有较好的稳定性和预测精度。从上述研究结果可知,由于变量因子与汽油辛烷值间的函数关系非常复杂,一些学者把智能优化算法与BP神经网络模型组合应用于汽油辛烷值的预测。Sadighi等[9]采用混合人工神经网络(BPNN)和遗传算法(GA)对汽油RON进行预测,提高了预测模型的稳定性和精确性。Wang Shutao等[10]用天牛须搜索(BAS)优化BP神经网络(BASBP)来预测汽油辛烷值,发现BASBP模型在训练中具有较高稳定性和收敛速率。
天牛须搜索算法虽然优于其他算法,但在提高模型的预测精确度上仍有较大空间。本研究以催化裂化汽油精制脱硫装置历史数据集为基础,提出了一种基于偏最小二乘法(PLS)和互信息(MI)组合的改进天牛须搜索算法(RSBAS)优化BP神经网络的模型(PLS-MI-RSBASBP)。该模型采用PLS和MI的组合降维法选取与汽油辛烷值强相关且弱冗余的特征变量,并用改进的天牛须搜索算法优化BP神经网络。在此基础上,用S Zorb工艺装置数据集对该模型进行多次训练与测试,得到最优的PLS-MI-RSBASBP模型;进而,采用该模型对精制汽油RON进行预测,为控制汽油辛烷值的关键变量因子提供依据。
1 模型算法
1.1 基本天牛须搜索算法
天牛须搜索算法(BAS)是根据天牛觅食时的探测行为和搜索行为提出的一种仿生智能算法,具有只需单个个体即可完成寻优的优点,运算量小[11]。天牛在觅食时,利用触须摆动接收空气中食物信息的浓度,从而搜索行动方向。在BAS算法中,食物为待优化的目标函数,某时刻(t)天牛质心的位置为自变量(xt),其表达式见式(1)。
(1)
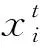
觅食过程中,天牛随机搜索未知区域,其搜索方向见式(2)。
(2)
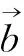
(3)
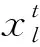
(4)
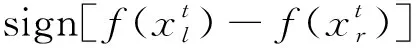
ht=rh×ht -1+0.01
(5)
stept=eta×stept -1
(6)
式中:rh为衰减系数;eta为0~1的衰减系数,一般取0.95。
1.2 改进的天牛须搜索算法
BAS算法虽然在优化性能方面优于其他部分算法,但收敛速率小、预测精度低、易陷入局部最优解,且对参数设置比较敏感,手动参数调节比较麻烦[12]。因此,国内外学者对BAS算法的步长更新[13-15]、位置更新[16]等方面进行了改进。本研究提出了一种随机更新步长的天牛须搜索算法(RSBAS),对BAS的参数与步长调节方面进行了改进,在自适应步长更新中引入随机数来提高BAS算法的优化性能。首先,按式(7)对模型的变量维数(d)进行优化。
d=Nin×Nhid+Nout×Nhid+Nhid+Nout
(7)
式中:Nin为输入层节点个数;Nhid为隐含层节点个数;Nout为输出层节点个数。
此外,考虑随机时滞情况,加入部分个体自身经验信息,并保持个体的多样性,在步长更新中引入一个随机数,增强算法的搜索能力。因此,步长更新算法由式(6)变为式(8)。
stept=r1×h0+r2×eta×stept -1
(8)
式中:r1和r2均为0~1的随机数。
2 组合预测模型的构建方法
2.1 RSBASBP神经网络模型
在BP神经网络(BPNN)的结构中,特征变量的权重、阈值,隐藏层的层数和每个层中神经元的数量都会影响其预测性能[17]。BPNN结构的复杂性取决于隐藏层的数量,隐藏层的层数由经验公式及试错的方法确定;而输入层和输出层的神经元数量由具体问题确定。BPNN的学习速率是固定的,收敛速率较小,训练时间较长,因而处理大样本数据时训练能力差,预测能力也差,且有时会出现“过拟合”现象,即随着训练能力的提高,预测能力会下降[18]。因此,采用RSBAS算法优化BP神经网络的特征变量权重和阈值,提升训练效率,避免“过拟合”现象,得到RSBASBP神经网络模型。其优化过程如下:
(1)由式(7)确定RSBAS模型的变量维数;利用MATLAB R2018a进行预测模型的多次调试,选择出预测模型最优的初始化参数,RSBAS模型中天牛的位置、步长及迭代次数。
(2)用式(4)更新天牛的位置及搜索方向,由式(8)更新搜索步长,计算并比较适应度函数fleft与fright的值,以选择较好的位置。
(3)判断适应度函数值是否达到预设精度或迭代次数,若满足则停止迭代,进入下一步,若不满足则返回第二步继续迭代。
(4)结束迭代,跳出循环,得到最优解xbest和fbest,并把此最优解作为BPNN模型特征变量的初始权值和阈值,构建的RSBAS优化BP神经网络预测模型如图1所示。
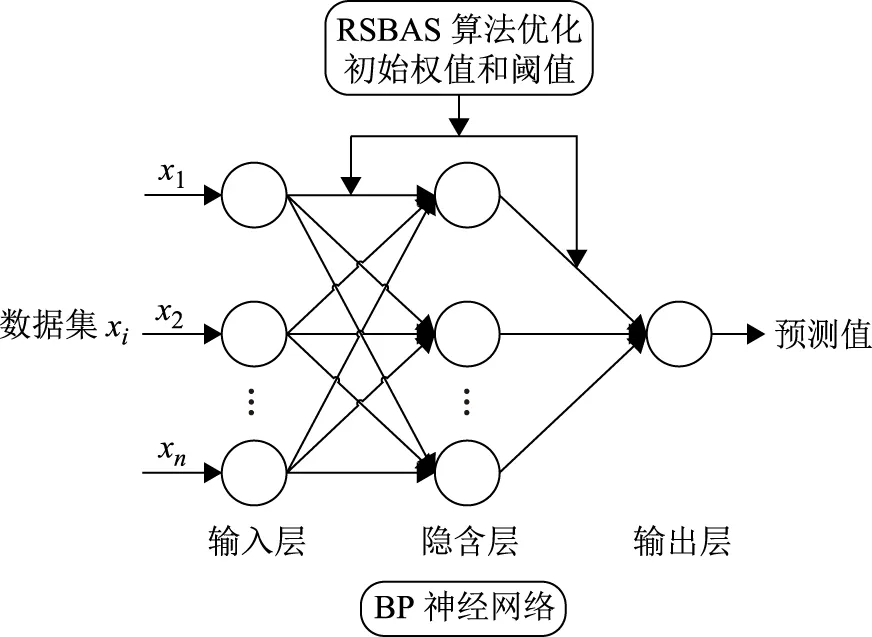
图1 RSBAS优化BP神经网络的预测模型框图
2.2 组合预测模型的构建方法
模型的原始数据集采自中国石化上海高桥石油化工有限公司实时数据库(霍尼韦尔PHD)及LIMS实验数据库。其中,操作变量数据来自于实时数据库,采集时间为2017年4月至2020年5月,采集样本数为325个,选取60个特征变量。
采集汽油辛烷值数据时,由于受到主观和客观因素的影响,获取的数据存在异常值,而且部分特征变量与目标变量的相关性较弱。为了消除变量间的共线问题,排除系统噪声的干扰,降低预测模型的复杂度,因此基于偏最小二乘法(PLS)和互信息(MI)组合方法,构建PLS-MI-RSBASBP组合预测模型。
首先,利用拉伊达(3σ)准则,以置信概率99.7%为标准,以3倍的标准偏差为界限,对数据集中的异常值进行修正处理[19]。
其次,采用偏最小二乘法(PLS)[20-21]计算特征变量xi(i=1,2,…,60)和目标变量y(汽油RON)的投影重要性值(VIP),提取VIP>1的特征变量,得到与y相关性较强的特征变量xi(i=1,2,…,24)数据集;然后,利用互信息(MI)[22-23]分析每个特征变量与目标变量间的非线性关系,计算特征变量xi(i=1,2,…,24)与y的互信息值,选择其中与RON强相关的特征变量xj(j=1,2,…,19)。
最后,把优选的19个特征变量作为RSBASBP模型的输入层,分别采用PLS-MI-RSBASBP网络模型、PLS-MI-BP网络模型、PLS-MI-GABP网络模型、PLS-MI-BASBP网络模型对汽油RON进行预测,并对比分析4种模型的预测结果。
3 基于组合模型的汽油RON预测
3.1 数据预处理

(9)
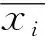
3.2 特征变量优选
首先,采用偏最小二乘法(PLS)的变量投影重要性(VIP)值分析特征变量xi(i=1,2,…,60)与目标变量y之间的相关性。根据PLS的原理[24]计算出每个特征变量的VIP值,提取VIP>1的相关特征变量,结果如图2所示。
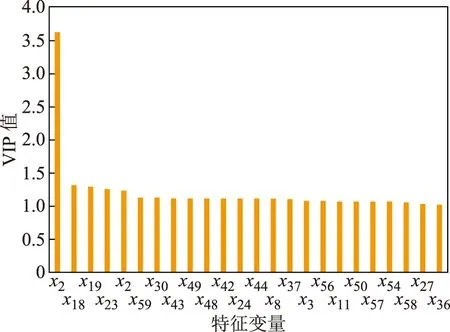
图2 变量投影重要性VIP值
由图2可知,采用PLS的VIP值分析筛选虽然剔除了部分冗余的弱相关变量,降低了特征变量集的维数,但在提取的特征变量中仍存在着弱相关变量,可解释性较弱。采用互信息(MI)算法选择特征变量,会在保留强相关特征的同时剔除冗余特征,但存在过度剔除现象,导致有用数据丢失。在采用PLS提取相关性较大特征变量的基础上,再用MI算法计算选择特征变量与汽油RON的MI值,可以避免有用信息的丢失,得到与汽油辛烷值相关性强且冗余度低的特征变量。具体优选结果如表1所示。
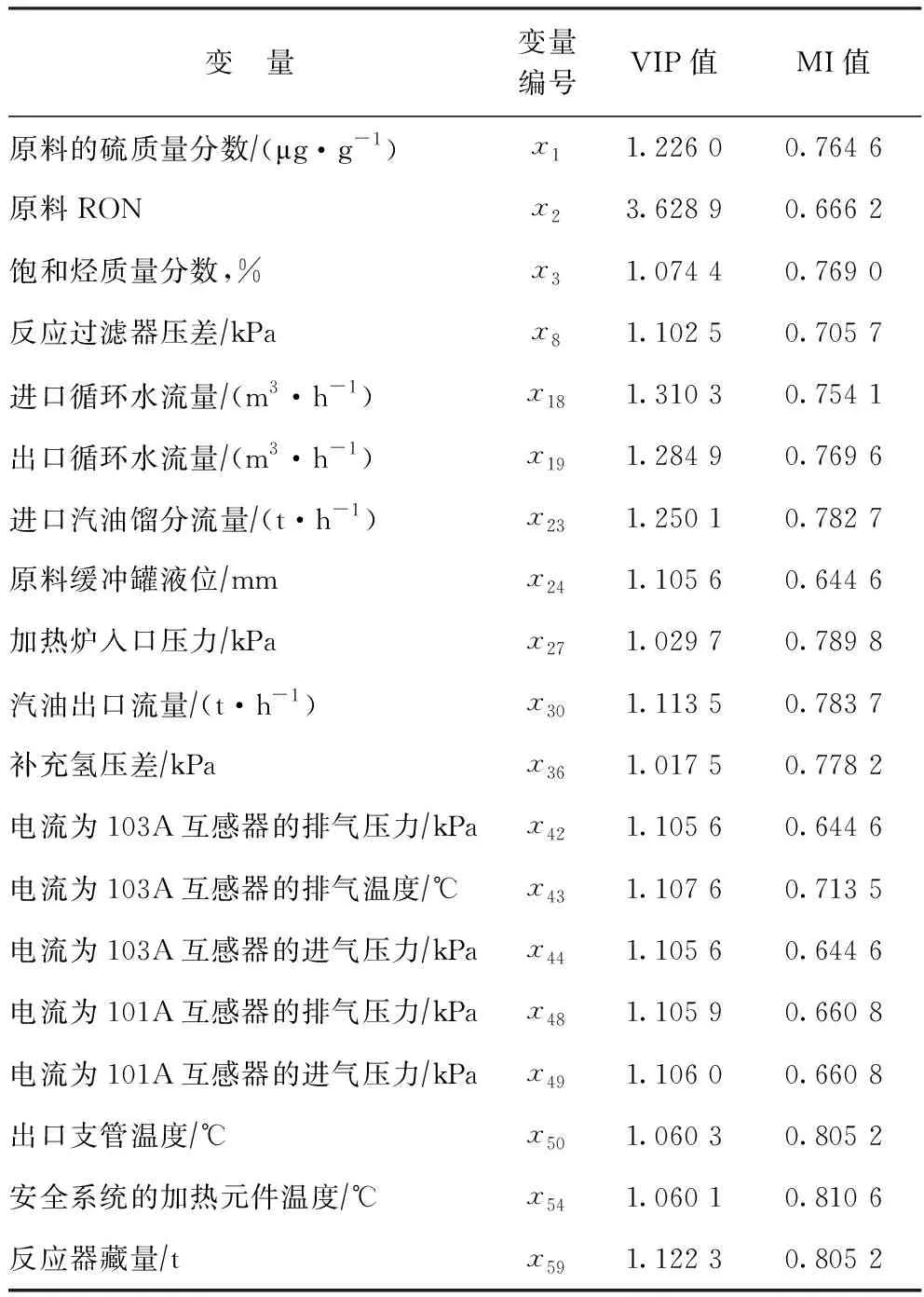
表1 优选的特征变量与汽油RON的VIP值和MI值
3.3 汽油RON的预测
为了考察组合预测模型对汽油RON的预测效果,分别对比用BP,GABP,BASBP,RSBASBP模型直接预测,用PLS特征提取的组合模型PLS-BP,PLS-GABP,PLS-BASBP,PLS-RSBASBP,MI-BP,MI-GABP,MI-BASBP,MI-RSBASBP预测以及用特征提取和特征选择的组合模型PLS-MI-BP,PLS-MI-GABP,PLS-MI-BASBP,PLS-MI-RSBASBP预测的结果。
在评价RON预测模型的性能时,选取平均绝对误差(MAE)、均方误差(MSE)和均方根误差(RMSE)作为评价指标,其具体计算方法见式(10)~(12)。
(10)
(11)
(12)
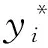
采用模型预测汽油RON时,将325个样本按4∶1的比例分为训练集和测试集,即前260组数据为训练集,后65组数据为测试集。模型直接预测、特征提取预测、特征提取与特征选择组合预测的特征变量个数分别为60,24,19个,作为模型的输入层神经元;目标变量为汽油RON,作为输出层神经元;隐含层的个数Nhid的确定,先由式(13)得到一个预估值,然后通过仿真计算,选取误差较小结果对应的层数,优化的隐含层个数为5。
(13)
式中:m与n分别为输入层与输出层神经元个数;a为1~10之间的常数。
采用BP,GABP,BASBP,RSBASBP模型对汽油辛烷值分别进行直接预测、特征提取预测、特征提取与特征选择组合预测,结果如图3所示。由图3可知,经PLS-MI方法降维处理后,各模型预测值与工业真实值的拟合度最高。

图3 不同模型在未降维和不同降维方法上的预测结果 —工业装置RON真实值; ○—RON直接预测值; 特征提取RON预测值; □—MI特征选择RON预测值; ☆—PLS-MI特征提取+特征选择RON预测值
不同模型预测值与工业真实值的误差比较如表2~表5所示。由表2~表5可知:在用PLS特征提取模型预测结果中,PLS-BP模型预测的MAE值低于BP模型,其他PLS特征提取模型的预测结果均明显优于直接预测结果;而用MI特征选择模型预测的结果不但没有提高预测性能,反而大幅降低了模型的预测精度,尤其是MI-BP的MSE和RMSE的值均超过了1,说明只采用MI选择特征变量,未评估特征子集的整体性能,导致大量有用信息丢失,模型预测性能降低。对比分析可知,PLS较MI方法能更有效提高模型预测性能,但二者都有一定的局限性;采用PLS-MI组合特征提取和特征选择方法较PLS、MI单一特征变量选取方法效果更好,预测误差更小、精度更高。
从表2~表5还可以看出,RSBASBP比GABP、BASBP模型的拟合效果更好,说明RSBAS算法可以避免BP神经网络的“过拟合”现象;对于非线性数据集,应采用RSBASBP模型的进行预测。

表2 不同特征变量选择方法的BP神经网络模型的仿真结果
将PLS-MI-BP,PLS-MI-GABP,PLS-MI-BASBP,PLS-MI-RSBASBP模型对汽油RON预测值和工业真实值进行拟合处理,如图4所示。从图4可以看出,4种组合模型都有较好的预测效果,但对一些突出值而言,PLS-MI-RSBASBP模型的拟合效果更好。因此,PLS-MI-RSBASBP模型的预测结果精度最高。
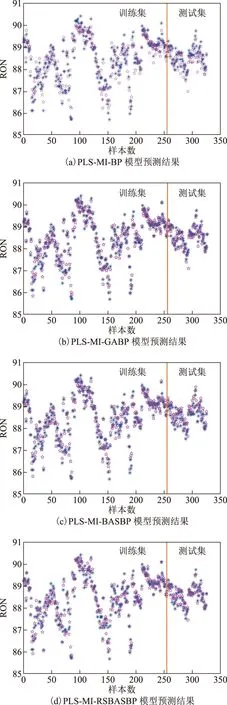
图4 4种PLS-MI组合模型的预测结果 —工业装置RON真实值; ☆—PLS-MI特征提取+特征选择模型RON预测值
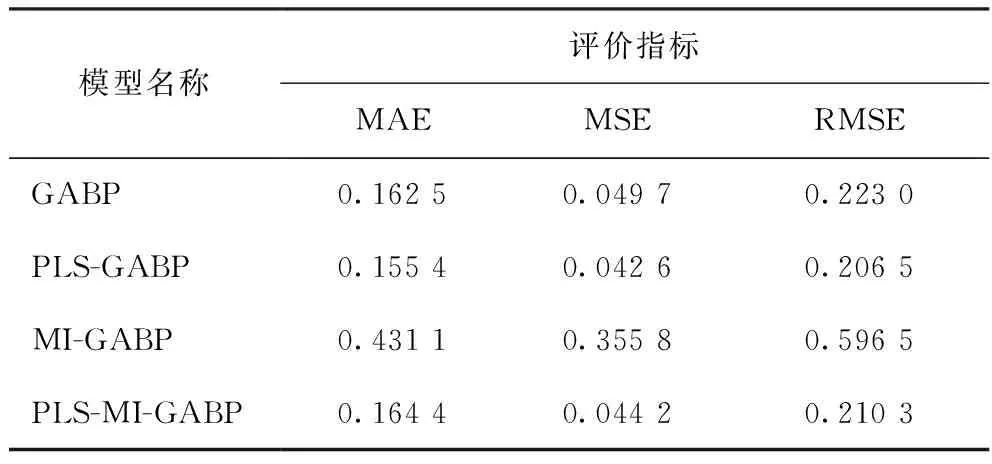
表3 不同特征变量选择方法的GABP网络模型的仿真结果
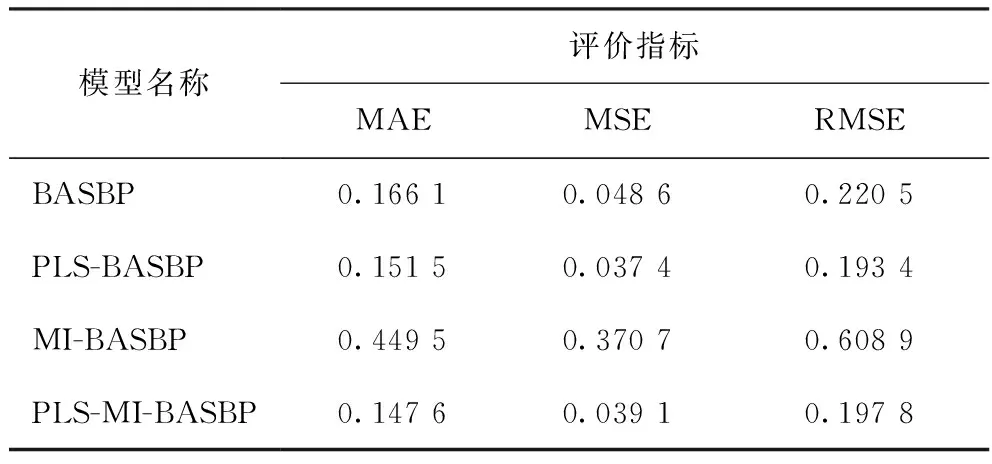
表4 不同特征变量选择方法的BASBP网络模型的仿真结果
综合比较采用PLS-MI组合方法优化后PLS-MI-BP,PLS-MI-GABP,PLS-MI-BASBP,PLS-MI-RSBASBP模型的预测值与工业真实值间的误差,结果如表6所示。从表6可以看出,4种模型预测结果中,PLS-MI-RSBASBP模型预测值与工业真实值的MAE,MSE,RMSE都是最小的。因此,PLS-MI-RSBASBP模型对汽油RON的预测性能最好。
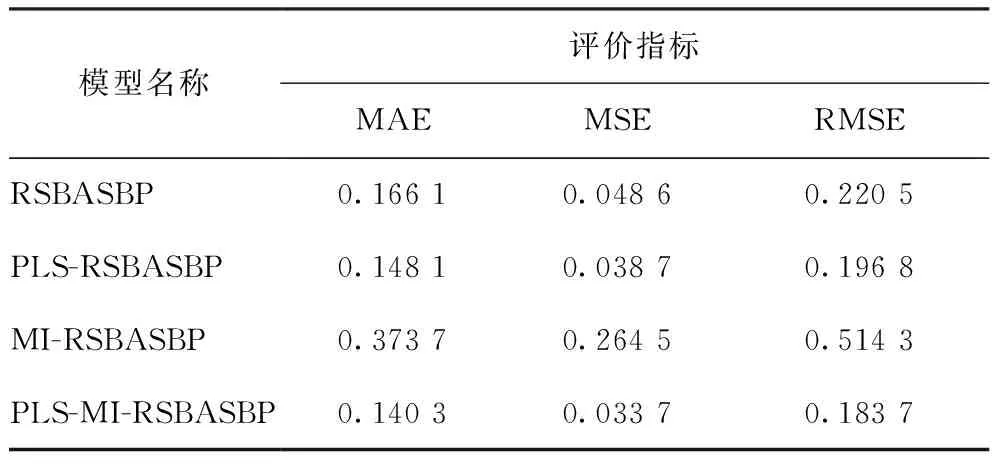
表5 不同特征变量选择方法的RSBASBP网络模型的仿真结果
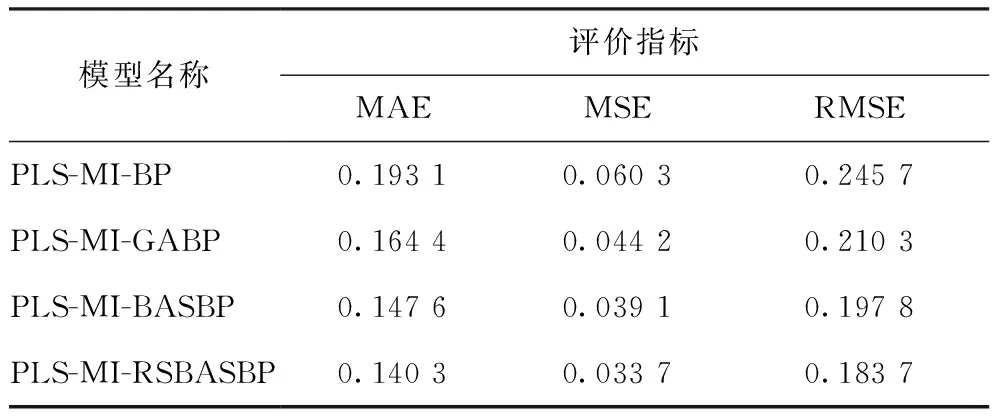
表6 4种PLS-MI组合模型的预测误差
4 结 论
对于催化裂化汽油精制脱硫S Zorb装置,基于偏最小二乘法和互信息组合的改进天牛须搜索算法优化BP神经网络的模型(PLS-MI-RSBASBP)可以大幅降低特征变量维度,对汽油RON的预测性能好。
该模型通过计算特征变量与目标变量投影重要性(VIP)和互信息(MI)值,筛选出与目标变量汽油RON强相关、低冗余的19个变量作为模型的输入特征变量,PLS-MI结合方法由于单一的PLS和MI方法,有效避免了模拟过程的“过拟合”现象,特征变量降维后的模型预测精确度提高。
与其他预测模型相比,PLS-MI-RABASBP模型对汽油辛烷值的预测值与装置真实值间的拟合度最高,预测误差最低,性能最好。
猜你喜欢
小哥白尼(野生动物)(2021年1期)2021-07-16
软件(2020年3期)2020-04-20
石油炼制与化工(2020年9期)2020-01-05
商品与质量(2019年44期)2019-11-28
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
小学生必读(低年级版)(2018年10期)2019-01-04
电子制作(2018年19期)2018-11-14
故事作文·低年级(2018年10期)2018-10-25
