
实现记忆检索和回忆中漫游的自传体记忆模型
2021-09-15 11:20:38刘征
计算机应用与软件 2021年9期
刘 征
(河南牧业经济学院信息工程学院 河南 郑州 450044)
0 引 言
认知模型是人工智能领域研究的重要方向之一,其中自传体记忆(Autobiographical Memory, AM)是一种编码、存储和指导检索与个人经历相关的所有事件集信息[1]。自传体记忆是人类思维的重要组成部分,但国内对自传体记忆的建模研究较少。回忆通常被认为是自传体记忆的一种功能,在自我接受和自我改变中起着至关重要的作用。回忆中漫游是指回忆一系列前后相关的自传体记忆,这些自传体记忆跨越不同的生活事件,这也是回忆疗法的基础,通常用于改善老年人的心理和认知健康[2]。事件集记忆和自传体记忆是两个密切相关的术语,两者都是指一个人所经历的过去事件的记忆集合,其中自传体记忆可以被认为是一种特殊类型的事件集记忆。从个人的角度来看,自传体记忆包含了一个人一生的经历,但是现有的大多数计算事件集和自传体记忆模块在使用“和/或”表示方式上没有明显的区别。
记忆模块是各种认知模型的重要组成部分。文献[3]提出的认知模型除了短期“和/或”工作记忆模块外,还包括长期记忆模块。这些认知模型可以不指定其所用长期记忆模块的确切类型,如事件集[4]、语义[5]或自传体[6]。文献[7]的特定模型明确地描述了一个事件集记忆模块的组合,其主要用于通过挖掘存储的历史数据来执行基于事例的推理。文献[8]提出了一种独立于其他认知模块的计算事件集记忆模型,并明确定义了计算机游戏中已发生过去事件的形成、检索和遗忘,但该模型的使用仅限于对历史数据的回忆,不包含作为输入字段之一的情绪,而这是自传体记忆中的一个重要元素。文献[9]提出的Xapagy自传体记忆模型被设计为实现叙事推理,其活动大致类似于人类在故事中所表现出来的一些心理过程。Xapagy结合了复杂的自然语言处理方法,但其使用仅限于讲故事。文献[10]开发了一种在线系统,使得用户能够基于他们的移动数据,构建出可视化记忆,作为可视化自传体记忆的一种形式,以便进行自我反省和分享经验。文献[11]将人与机器人的交互作用存储为自传体记忆,可以使类人机器人积累经验并提取出规律性。但是在检索存储记忆时,前面提到的自传体记忆模型都仅使用最小数量的索引知识调用简单的检索,仅检索全部记忆、特定用户的全部记忆,或构成所选动词的全部记忆。文献[12]提出了一种基于关键词查询的自传体记忆模型用于记忆检索。该模型以描述游戏环境中发生事件的句子形式输入记忆,并保存全部已解析关键词的链接图,其中与链接相关的权值表示关键词对的共存。而在关于事件集记忆和自传体记忆模型的文献中,很少有关于漫游现象的研究。文献[13]试图用自陷吸引子神经网络模仿短期和长期联想记忆中的漫游效应,并将网络中的漫游称为允许“稀疏连接的网络在远离初始状态的吸引子附近徘徊”机制。
不同于前面提到的自传体记忆模型,本文提出一种可以实现记忆检索和回忆中漫游的自传体记忆模型,旨在捕捉记忆,包括一个人生活经历的图片快照以及相关的背景,即时间、地点、人物、活动和情绪,可以采用不同类型的线索来检索编码的自传体记忆,并模仿人类思维在回忆中的漫游现象。基于精确的、部分的和含噪记忆检索线索的实验结果表明,所给模型具有鲁棒的和灵活的记忆检索,尤其是对于含噪线索的响应具有更好的性能,同时还能通过回忆一系列前后关联的记忆模仿思维漫游。
1 自传体记忆模型的心理学基础
在心理学家建立的各种自传体记忆模型中,通常从一般到具体将自传体记忆知识分为3个层次:生命周期、一般事件和特定事件知识,如图1所示。如果线索是具体和个人相关的,则自传体记忆可以直接被访问;如果线索是一般的,则必须生成检索过程,以得到相关记忆检索的更多具体线索。直接检索与生成检索之间的主要区别是:生成检索中的控制过程对检索过程进行调整。这两种记忆检索方式之间的差异得到了神经影像学证据的支持。

图1 自传体记忆层次结构示意图
2 模型构建及分析
2.1 模型结构
图2为本文自传体记忆模型的网络体系结构。该结构是一个自上而下的3层网络结构,其中F3层、F2层和F1层分别编码生命周期、一般事件和特定事件知识3个层次。对比图1和图2即可得出它们之间的对应关系,如“在A工作”的生活经历可表示为F3中的代码(学习集),与这一事件集的相关事件“上班的第一天”“在C办公室工作”和“周五晚上在W喝酒”可以表示为F2中的代码(学习事件),其中一个具体的事件,如“周五晚上在W喝酒”可以在F1中读出,即周五晚上(时间)、在W(地点)、和同事(人物)、饮酒(活动)、感到快乐(情绪),以及图像记忆(图像)。

图2 本文自传体记忆模型的网络体系结构
本文模型利用自组织网络的动态性,其底层将特定事件知识进行编码,其中特定事件知识由5W1H构成,即时间(何时,When)、地点(何地,Where)、人物(谁,Who)、活动(干什么,What)、意象(哪一种,Which)和情绪(如何,How),中间层通过关联特定事件知识对事件进行编码,顶层通过关联相关事件对事件集进行编码。自传体记忆的记忆检索首先发生在底层,由底层提供检索线索。按照自下而上的记忆搜索过程,可以分别在中间层和顶层识别相应的事件和事件集,所以可以通过执行自上而下的记忆读出过程来检索。
根据图2所示的F1层(由6个输入字段构成)和F2层(由1个关联字段构成),下面给出本文自传体记忆模型的动态性分析。
关联字段:令y=(y1,y2, …,yC)表示F2中的激活向量,其中C表示F2中的代码数。
参数:自传体记忆的动态性受与下层中全部输入字段相关联参数的调节,即选择参数αk>0、学习速率参数βk∈[0,1]、贡献参数γk∈[0,1](∑γk=1)和警戒参数ρk∈[0,1]。
代码激活:自下而上的知识搜索从计算F2中全部代码的激活(选择函数值)开始。具体来说,给定xk,对于每个F2代码j,选择函数Tj计算如下:
(1)
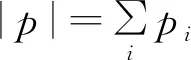
代码竞争:代码竞争过程中,识别具有最高选择函数值的F2代码,获胜者标记为指标J,其中:
TJ=argmax{Tj:对于全部F2代码j}
(2)
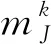
(3)
如果违反任何警戒约束,则会发生失配重置,其中在输入表示期间将TJ设置为0。因此,另一个F2代码将被选为新的赢家。这个搜索和评估过程将保证到结束,因为将识别一个满足警戒标准的已提交代码或未提交代码(全部权值被初始化为1以满足标准)来编码新的输入模式。一旦一个未提交代码被采用,一个新的未提交代码将自动添加到F2中,然后自传体记忆模型就可自组织其网络结构。

(4)
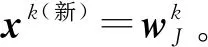
模板掩蔽:由于融合ART的动态性,并不是全部输入向量都必须提供给知识检索。在这种情况下,缺失向量xk的所有值(包括补集)都设置为1。
2.2 事件的编码和检索
在图2所给自传体记忆模型中,F1中的输入字段分别编码5W1H。为了使激活向量xk紧凑和通用,采用归一化值来表示时间和地点,并用明确的值来呈现人物、活动、情绪和意象。
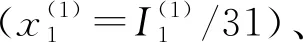
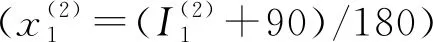
人物向量(x(3)):它是一个二进制值向量,表示参与事件的人。它的长度对应于基于关系的人的分类。
活动向量(x(4)):它是一个二进制值向量,表示事件的内容。它的长度对应于活动的分类。
情绪向量(x(5)):它是一个二进制值向量,表示事件期间的感觉如何。情绪是我们过去经历中的一个重要组成部分,它影响着自传体记忆的编码和检索。把情绪分为9种,即中性、惊讶、兴奋、快乐、满意、疲倦、悲伤、痛苦和恼怒。因此,x(5)的长度为18。这种分类遵循文献[15]建立的快乐-唤醒模型。
图像向量(x(6)):它是一个二进制值向量,表示与事件相关的图片记忆。它的值被编码存储在图像的文件路径。在记忆检索过程中,该向量不与其他向量一起作为检索线索的一部分。因此,在算法3和算法4中只有F1的前5个输入字段被调用。
在自传体记忆模型的F2层编码事件,事件编码和检索过程的伪代码如算法1所示。
算法1事件编码和检索过程的伪代码
Step1给定输入模式Ik,在F1中编码xk;
Step2激活F2中的全部代码;
//见式(1)
Step3repeat选择获胜者代码J;
//见式(2)
Step4until共鸣发生;
//见式(3)
Step5if需要编码then执行学习;
//见式(4)
Step6endif
Step8endif
2.3 事件集的编码和检索
假设一个事件集的相关事件发生在t0,t1,…,tn,令yti表示发生在ti事件的激活值。则为了编码事件序列,需要始终保持ytn>ytn-1>…>yt0,因此采用衰减参数τ∈(0,1)来调节激活衰减,使得在每一个新的时间步有yj(新)=yj(旧)(1-τ)。
在自传体记忆模型的F3层编码事件集,以关联F2中编码的相关事件。其中,事件集编码和检索过程的伪代码如算法2所示。
算法2事件集编码和检索过程的伪代码
Step1for 一个事件集的全部后续事件 do
Step2在F2中选择关于F1中xk的获胜者代码J;
Step3yJ←1;
Step4for 全部F2中事先选择的代码 do
Step5yi(新)←yi(旧)(1-τ);
Step6end for
Step7end for
Step8在F3中选择关于y的获胜者代码J′;
Step10end if
Step12end if
2.4 回忆中漫游
在所给自传体记忆模型中,漫游是指规则记忆检索过程,其中后续记忆是基于高度相似但是随机变化的线索来检索的。下面讨论如何使得所给自传体记忆模型能够在回忆中漫游。漫游包括2个主要过程,即在每次迭代中,采用变化的线索,改变检索线索并迭代地检索自传体记忆。
算法3给出改变一个检索线索过程的伪代码,在概念上类似于遗传算法中的染色体变异[16]。所给模型将这一改变过程概括为在给定检索线索的情况下,有意识地在随机确定的位置向其添加受调节的噪声来实现。改变过程受2个参数调节:变异率T∈[0,1]和噪声级L∈[0,1],采用变异率T来控制某一字段中检索线索值的变异概率,并用噪声级L来控制改变量。
算法3记忆检索线索的变异伪代码
Step1给定一个记忆检索线索x={x1,x2,…,x5};
Step2for 全部xi∈xdo
Step3ifrand()≤Tthen
//选第i个字段作为变异

Step5ifi≤2&&rand()≤2/|xi| then
//对于归一化向量,选择第j个值进行变异
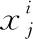
Step8else ifi≤3&&rand()≤2(1+L)/|xi| then
//对于二值向量
Step10end if
Step11end for
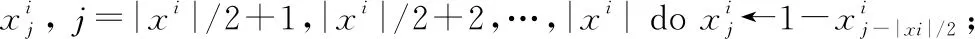
//计算补集
Step13end for
Step14end if
Step15end for
算法4给出所给自传体记忆模型在回忆中漫游过程实现的伪代码。其中漫游过程为:在每次迭代开始时给定的记忆检索线索基础上,首先使用给定的线索来检索最相关的事件,该事件尚未包含在检索的记忆集中,然后将检索到的事件追加到记忆集中,再用变化的检索线索进行下一次迭代。算法4的终止准则是通过检索一个预先确定的事件数量N。这个准则可以很容易地删除或修改,以便进行连续检索。
算法4自传体记忆模型在回忆中漫游过程实现的伪代码
Step1给定一个记忆检索线索x={x1,x2,…,x5};
Step2ρk←0,k=1,2,…,6;
//在记忆检索过程中移除全部警戒标准
Step3M=∅;
Step4repeat
Step5repeat 在F2中识别关于x的E;
//寻找获胜者事件
Step6yE←0;
//抑制其激活值
Step7untilE∉M
Step8M←M∪{E};
//保存在M中的检索顺序
Step9变异x;
//见算法3
Step10until |M|=N;
Step11检索M中的全部事件
3 实 验
实验数据主要由我国某体育明星53个事件的快照以及相应的背景构成。53个事件是由12个事件集构成,每个事件集包含3至7个事件。从在线网页直接提取了除情绪外的所有特征,情绪是从图片及其背景中手工提取出来的。根据所收集的数据集,定义8种类型人物关系:家庭、邻居、配偶、朋友、同学、同事、熟人和陌生人,以及15类活动:餐饮、休闲、旅游、度假、购物、夜间外出、娱乐、体育、锻炼、工作、聚会、社交、庆祝、婚礼和学校。在对输入向量进行形式化处理后,将数据样本提交至本文自传体记忆模型中,在F2中对53个事件进行编码(采用算法1),在F3中对12个事件集进行编码(采用算法2)。实验采用的自传体记忆参数如表1所示,其中大多数都是采用标准参数值,在实验中不需要调整。
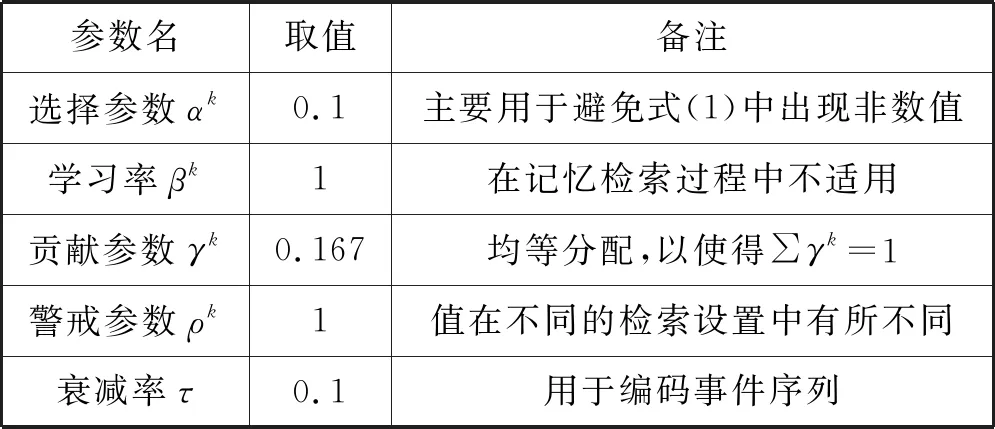
表1 实验采用的自传体记忆模型参数
3.1 采用精确、部分和含噪线索的记忆检索
采用本文自传体记忆模型对记忆进行编码后,首先采用以下3种类型的线索测试记忆检索的性能:
(1) 精确线索:从数据集中随机选取一个事件,并采用其表示向量x=(x(1),x(2),…,x(5))作为精确检索线索;
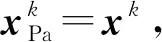
(3) 含噪线索:在所选取的xPa字段中(其中xPa≠(1,1,1,1,1)),给定一个部分线索xPa和含噪线索级L′,引入噪声来得到含噪线索xNo。将噪声引入检索线索的过程遵循算法3中描述的从Step 4到Step 13的过程,其中L=L′。
选择基于关键字的查询方法作为比较基准,该方法被许多现有照片或记忆存储库所采用。其检索准则是基于给定的检索线索是否与存储的记录的相应部分完全匹配。实验中在执行基于关键字的查询对给定的检索线索做出响应后,将对一组事件进行检索。如果最初用于生成给定线索的事件可以在检索集中找到,则认为检索是成功的,否则,认为是失败的。
本文自传体记忆模型处理含噪线索时,可以降低警戒参数ρk,这样用户即使提供了不完整的线索,也可以检索某些记忆,这个特性是目前许多其他现有照片或记忆存储库类型应用所不具备的优势。为了响应给定的检索线索,本文自传体记忆模型检索一组记忆并将它们回放给用户。对于每个实验,重复10次,每次随机选择或生成检索线索,并将结果汇总,以供进一步分析。
由于采用生成部分线索和计算成功检索的准则,因此本文自传体记忆模型和基于关键字的查询方法对精确和部分检索线索的响应都获得了100%的成功率;但处理含噪线索时却很有挑战性,因为不确定性虽然可以通过我们的大脑很好地进行处理,但不一定能通过许多计算模型来处理。图3为本文自传体记忆模型和基于关键字查询方法对不同线索完整性百分数P和不同含噪线索级L′的含噪线索的记忆检索响应实验结果。
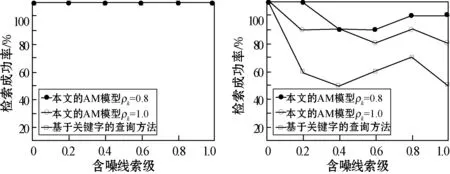
(a) P=0 (b) P=20
当P=0时,所给方法都能检索数据集中的全部事件,因此在图3(a)中都达到100%的成功率。但随着P值的增大,检索线索由越来越多的输入字段构成,因此,随着线索完整性百分数P值和含噪线索级L′值的增大,本文自传体记忆模型和基于关键字查询方法的记忆检索性能都普遍下降。同时可以看出,本文自传体记忆模型明显在对含噪线索响应的成功检索率方面表现得更好。通过降低在处理含噪线索时的警戒值,本文自传体记忆模型可以更好地处理检索过程中出现的不确定性。因此,在处理不完整信息方面,本文模型更倾向于追求类似于人的智慧,表现出更好的性能。
3.2 在回忆中漫游
为了测试本文自传体记忆模型在回忆中漫游的性能,采用表2给出的变异率T和噪声级L的不同组合用于不同设置中作为在回忆中漫游性能的比较。选取T=0.2或T=0.4,可以在变异过程中使期望线索的1个或2个字段分别按平均值改变,选取L=0.1或L=0.2在漫游过程中生成比较小的噪声。同时,还测试了极端情况WSS和WRR,即T和L设置为边界值。
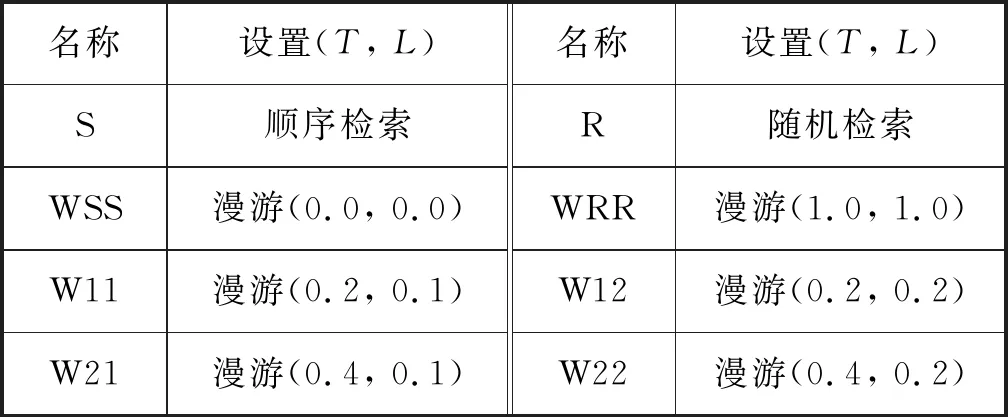
表2 实验参数设置的命名约定
表3为本文自传体记忆模型在W22配置漫游过程检索到的部分记忆序列,其图像回放如图4所示。表3很好地说明了本文自传体记忆模型从第5集(包括5个事件)到第10集(包括7个事件)的漫游,然后在2步后漫游返回第5集。
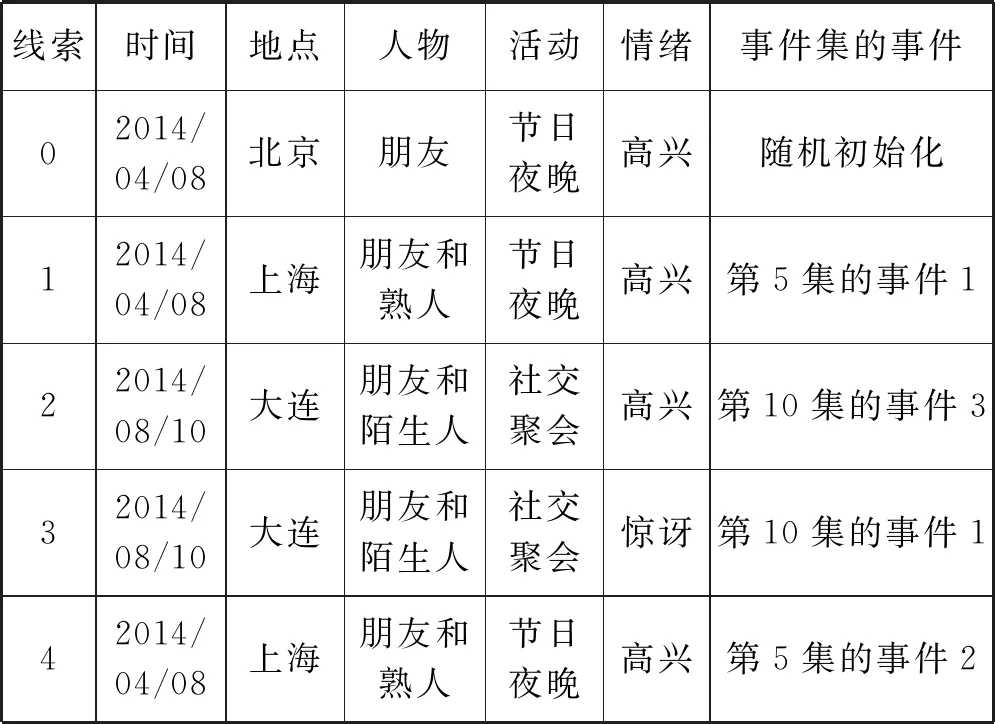
表3 检索到的自传体记忆部分子序列
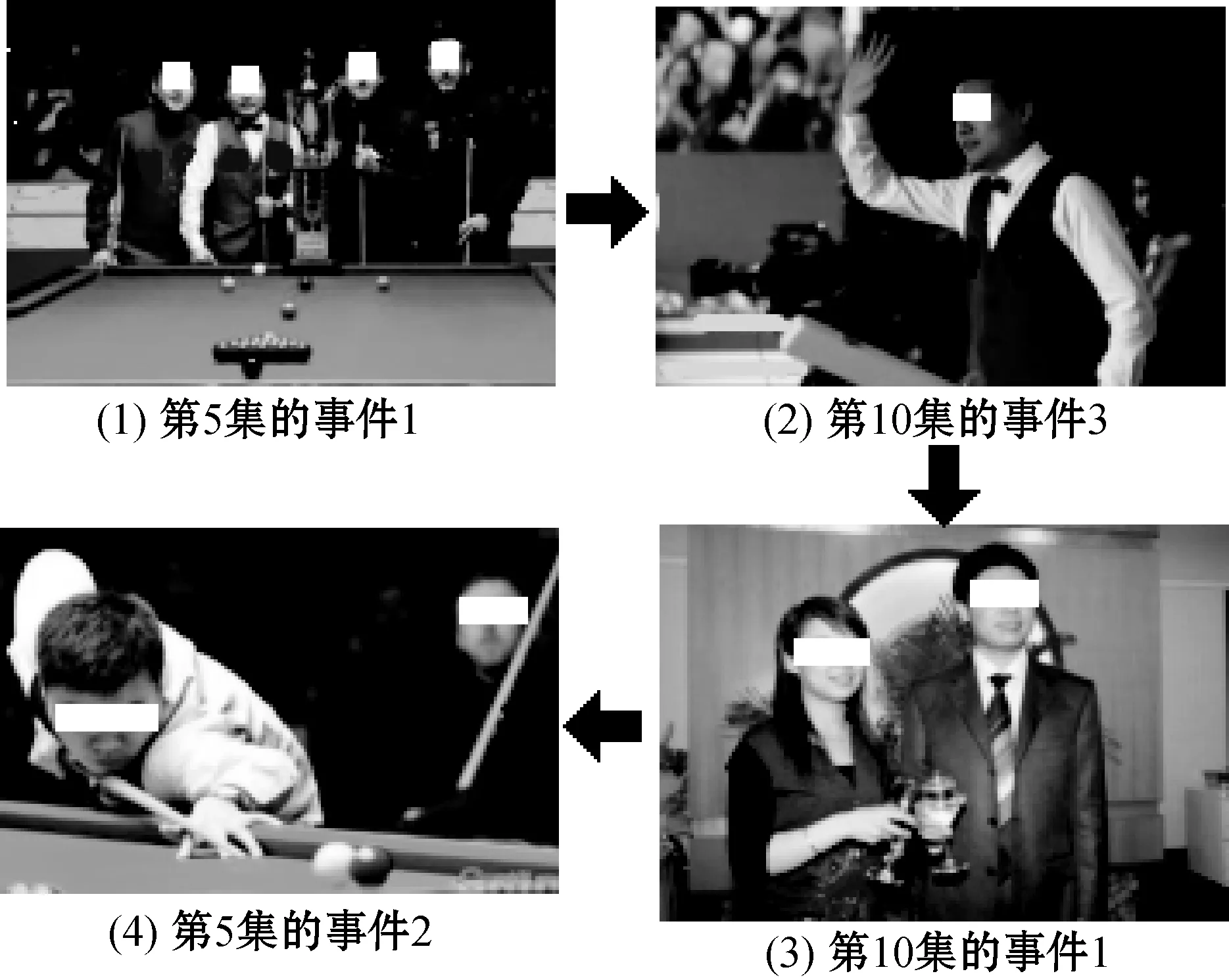
图4 根据表3所示顺序检索的事件图像回放
由此可知,本文自传体记忆模型能够有效地检索一个人的自传体记忆的一个适度子集,并且能够模仿在回忆中漫游的现象。
4 结 语
为了捕捉自传体记忆,本文给出一种可实现记忆检索和回忆中漫游的自传体记忆模型。该模型不仅用于建模用户生活经历的在线自主主体中自传体记忆的编码和检索,而且还能够模仿人类自传体记忆中的心灵漫游现象。由实验结果表明,本文自传体记忆模型在对含噪线索的记忆检索方面的性能优于传统基于关键字的查询方法,这是因为后者无法处理许多现有照片或记忆存储库中的含噪线索。同时本文自传体记忆模型能够实现在回忆中漫游,可以模仿一个人跨越不同事件集的前后相关联的记忆序列,即一个人自传体记忆的一个适度子集。下一步将对本文自传体记忆模型的感知、识别和推理能力进行重点研究,以期能够提升本文自传体记忆模型的实际应用价值。
猜你喜欢
动漫星空(2018年11期)2018-10-26 02:24:02
动漫星空(2018年2期)2018-10-26 02:11:00
动漫星空(2018年9期)2018-10-26 01:16:48
动漫星空(2018年5期)2018-10-26 01:15:02
意林·少年版(2018年10期)2018-05-30 16:24:42
百科探秘·航空航天(2016年6期)2016-12-01 11:44:34
湖湘论坛(2016年6期)2016-02-27 15:24:21
教育教学论坛(2014年11期)2014-08-01 01:36:42
中国现当代社会文化学术沙龙辑录(2011年0期)2011-10-27 02:14:27
早期教育(家庭教育)(2009年9期)2009-10-20 04:28:58
