
基于CFSFDP算法的边缘电力数据异常检测
2021-09-14 02:31张哲敏李琪林成贵学
四川电力技术 2021年4期
张哲敏,李琪林,严 平,成贵学
(1.上海电力大学计算机科学与技术学院,上海 200090;2.四川省电力公司计量中心,四川 成都 610045)
0 引 言
如今,随着智能电网的发展,电力系统中产生的数据量也不断增多。但安装在发电、输电、配电、用电各个环节各种类型的计量装置和系统,由于外部干扰等原因,会不可避免地出现异常数据,及时有效地检测出异常数据能够保障电力系统的稳定性和安全性。各种离群点检测算法能够检测出那些与正常数据行为或特征属性差别较大的异常数据或行为,有利于降低安全风险,减少经济损失。
目前,已经有一些文献研究了电力数据领域的异常值检测算法。它们可以大致分为基于距离的异常值检测、基于密度的异常值检测和基于聚类的异常值检测等。基于距离的异常值检测方法由EM Knorr、RT NG[1]等人在20世纪末提出,该方法认为与大多数样本的距离都大于某个固定阈值的点就是异常值点。但这种方法不能判断含有密度不同的多个类簇的数据集。基于密度的异常值检测的原理认为正常样本点所处的类簇密度要高于异常点样本所处的类簇密度。最具有代表性的是基于局部异常因子(local outlier faction, LOF)的异常值检测方法[2]。基于聚类的异常检测其目标是将数据点按照一定的规则划分到某一类中,而异常值检测的目标不属于任何簇的样本点k均值聚类算法,据此与正常样本点进行区别。目前,主要的基于聚类的异常值检测k均值聚类算法采用k-means和DBSCAN(density-based spatial clustering of applications with noise)算法进行聚类[3-4]。文献[5]针对传统电量数据异常检测方法的不足,提出了一种基于三次指数平滑模型和DBSCAN聚类的电量数据异常检测方法。文献[6]采用一种基于孤立森林的异常检测算法,实现大规模电能量数据的异常检测。文献[7]将DBSCAN和LOF算法相结合,即KDBLOF,将k近邻(k-nearest neighbors,KNN)思想引入到DBSCAN中,解决了原DBSCAN参数确定困难的问题。
电力数据经采集后会将所有数据上传至集中式数据中心,再使用异常值检测算法做数据清洗,其中异常数据的传输会造成大量的带宽浪费。在边缘端进行异常值检测,可以减少异常数据传输,节省带宽资源。但边缘端一般不具备较高计算能力的计算处理单元,所以需要复杂度低的算法。
基于密度峰值的快速聚类(clustering by fast search and find of density peaks,CFSFDP)算法是Alex Rodriguez[8]在2014年于《Science》上提出的一种快速寻找聚类中心的聚类算法,具有简洁、高效、参数少的特点,十分适合在边缘计算平台中使用。目前,已有不少研究将该算法应用于电力数据异常检测。文献[9]利用 KNN思想重新定义局部密度和距离,将CFSFDP用于电力大数据的异常值检测,但该方法需要人为设置经验参数,不具有普适性。文献[10]采用LOF算法和CFSFDP算法相结合的聚类算法进行电力数据异常值检测,弥补了CFSFDP算法对于局部密度变化大的数据识别能力弱的缺点;但该方法是通过人工选择决策图来实现聚类中心选取,存在主观因素的影响。
下面将CFSFDP算法应用于电力数据的异常检测,并提出了一种异常点的选择策略来实现异常点的自动选择。所提方法避免了原算法需要通过决策图人工输入来实现聚类,再从聚类后的数据中寻找异常点的繁琐步骤,降低了算法的冗余性并提高了寻找异常值的效率。
1 CFSFDP算法
CFSFDP算法在所提方法中主要基于两个重要的假设思想:一是假设聚类中心相较于其他的样本点局部密度较高,且被局部密度较低的点包围;二是假设各类簇聚类中心之间的距离较远。为了实现这2种假设,定义了两种度量方法。
第一个定义是每个点的局部密度,对于每个点i,它的局部密度ρ(i)的表示有2种方法,其中:式(1)为截止距离法;式(2)为核距离方法,适用于数据量较小的数据样本。

第二个定义是每个点距离高密度点的距离。对于每个点i,它距离高密度点的距离δ(i)的定义公式为
根据定义,只有局部密度较大或者全局最大的点,δ(i)才能够足够大。
CFSFDP算法计算局部密度ρ和更高密度距离δ,将数据集映射成二维图并构造一个决策图(如图1所示)。在决策图中,ρ和δ都很大的点(靠右靠上的点)即为聚类中心。在选择聚类中心后,再将剩余点分配给距离最近的聚类中心完成聚类。

图1 CFSFDP算法决策
CFSFDP算法能够在不确定聚类数目时快速地找到聚类中心,但只适用于特定结构的数据集。对于一些稀疏的数据集,如果经验参数设置不当,可能会取得较差的效果。此外,由于选取聚类中心时采用人为框图框选聚类中心的方式,存在主观因素,不同的选取会得到不同的结果,增加了算法冗余性的同时也不利于实现算法的批量自动化应用。
2 基于CFSFDP算法的异常值检测
2.1 CFSFDP检测异常值思路
根据CFSFDP算法提出的假设,从异常值检测的角度来看,可以认为局部密度较低且距离高密度点较远的样本点为异常值点。虽然异常值点距离密度较高的点的距离较正常样本点远,但聚类中心之间的距离同样也很远。如果此时该聚类中心的局部密度不够大,很有可能在人工选择异常值时出现将聚类中心误划分为异常值的情况。对此,引入了一个离群值的概念,将样本点的异常度进行量化,方便进行异常值的选择。
对于每个点i,它的离群值λi的定义公式为
当点i的局部密度ρi等于0时,此时离群值λi为无穷大,可以直接定义点i为异常值点。其他情况下,λi越高,点i成为异常值点的概率越大。
2.2 异常值点自动选择策略
通过离群值的定义,为了找出异常值点,可以将离群值大于一定标准的点定义为异常值点。但该标准通常为人工指定,仍然存在主观因素的影响,所以制定了以下策略来实现异常值点的自动选取。
将所有样本点按照离群值进行降序排列,取出前m%的点得到离群值排列图,如图2所示。可以看出,虽然离群值整体呈现下降趋势,但下降的程度有所不同,前面下降得快,后面下降得慢。即前半部分离群值相差大、不稳定,可以认为是异常值点;后半部分因为趋向稳定,离群值下降缓慢,可以认为是正常点。在下降程度发生最大变化的点是离群值总体下降由急变缓的拐点。拐点前的是异常值点,拐点后的是正常样本点。

图2 离群值降序排列
当表示下降趋势时,可以采用斜率进行表示,即
式中,ki,m表示区间[i,i+m]内的离群值λ变化率,该参数描述了这一区间λ的总体变化趋势。
对于某点前后下降趋势,可以用与前一点线段的斜率和后一点线段的斜率的比值来表示。
第一个点的下降趋势默认为0,且当该点的离群值与后一点相同时,该点的变化趋势与前一点相同。计算所有点的变化趋势比值,绘制出图3所示的变化率趋势图。拐点为使变化率k取得最大值时的点。
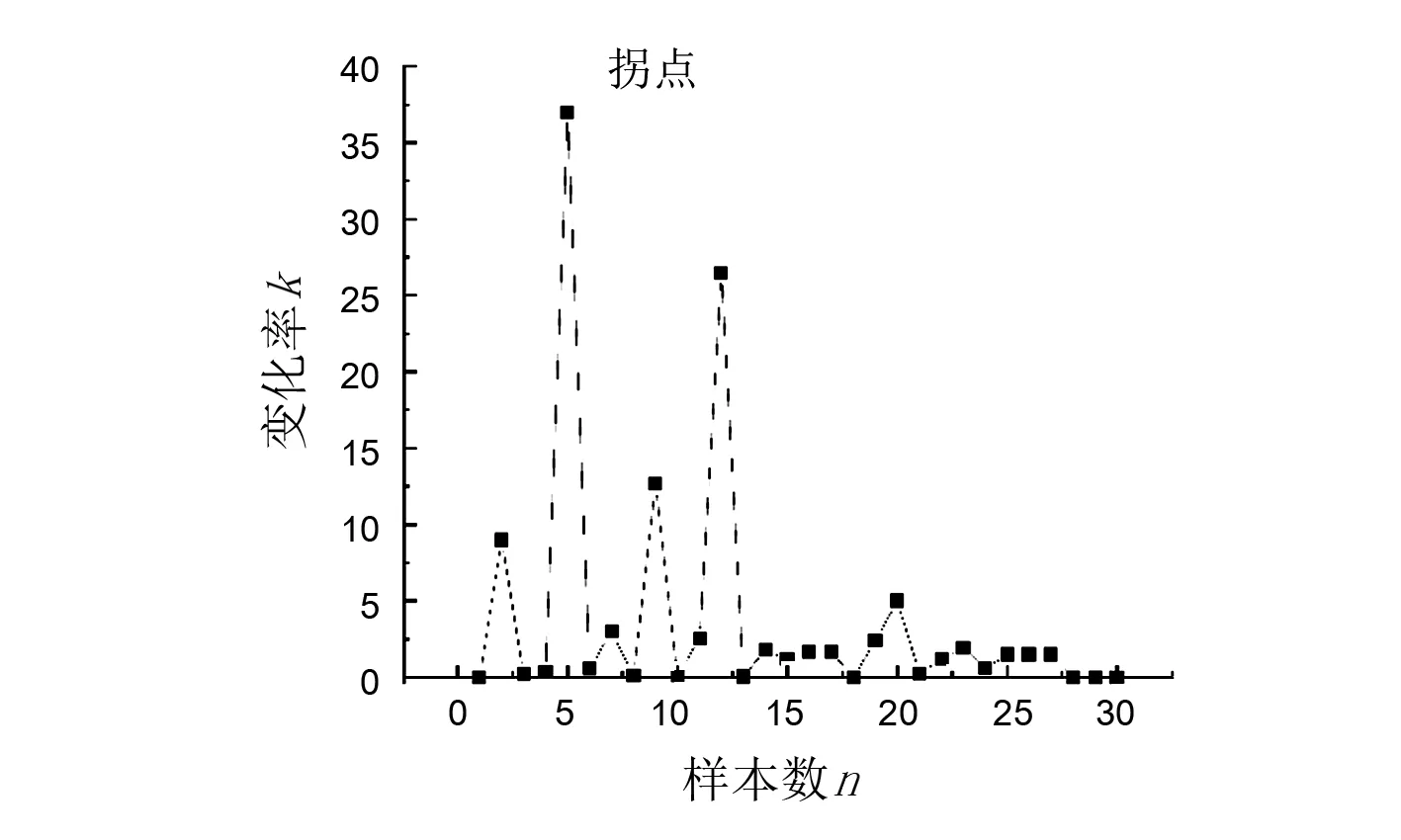
图3 变化率趋势
得到拐点后,可将拐点前的所有点,视为异常值点,使用CFSFDP算法寻找异常值点的具体步骤如下:
1)根据dc确定每一个点的局部密度ρi和距离δi。 2)计算每个点的离群值λi并从高到低排序。
3)取样本点前m%的点计算变化趋势ki。m为经验参数,一般选择5%~10%。
4)取使k取得最大值的拐点x。
5)挑选出拐点之前的点{1,2…,x}作为异常值点。
3 仿真验证
采用2017年1月至10月某公司的日用电数据作为研究对现象,采样间隔为15 min。用户日用电数据作为电力数据的一种,经常因为电能表故障和传输异常等原因,造成上传数据存在异常。但在电力数据的异常值检测场景中,异常值所占比例远低于正常对象。因此,只提取了数据集中的部分数据,使得最终实验数据中异常值与正常值的比值满足异常值检测的一般要求。并且,为了衡量用电数据异常检测算法的有效性,采用的数据提前进行了人工标注,即异常数据已经被标识,方便检验异常检测算法的效果。
在预处理阶段对数据进行了降维和归一化处理,是为了消除因为量纲不同和数量级差距所带来的影响,且可以加快算法的识别速度。按照式(7)对数据进行归一化处理。

(7)
为了评估基于CFSFDP寻找异常值算法的性能,与DBSCAN直接检测异常值、局部异常因子LOF算法进行了对比试验。DBSCAN直接检测异常值是先对数据进行聚类,获得不同的类簇;然后求取各个类簇聚类中心间的距离,如果距离过大则认为是异常用电数据。这里设置DBSCAN的参数ρ为0.2。
将算法检测出的异常值与数据样本的真实标签作对比,计算并选取检测率(detection rate)和误检率(false positive rate)作为算法评价标准,检测率和误检率的计算公式如下:

(8)

(9)
检测率和误检率的实验结果如图4、图5所示。由图可以看出:1)基于CFSFDP算法的异常检测在检测异常值时总体检测率较高,误检率较低,明显优于直接利用DBSCAN算法检测异常值和利用局部异常因子算法LOF检测异常值;2)对于不同月份的检测样本,直接利用DBSCAN算法的异常检测算法的检测率和误检率不同且波动较大,这是因为算法对不同数据样本具有独特性,DBSCAN只适用于部分样本。相对地,基于CFSFDP算法的异常检测就具有较好的适应性,对于不同月份的数据都能维持一个很高的检测率和很低的误检率,变化不大。其中部分月份检测率较其他月份有所降低,原因为该月平均用电量较其他月份有差别,需要提取更多该月样本进行单独检测。

图4 检测率实验结果
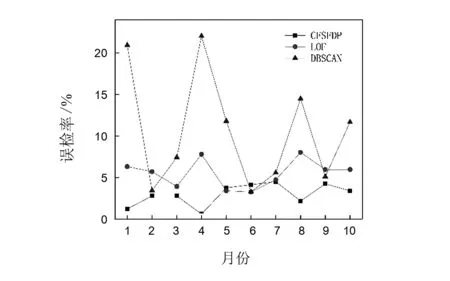
图5 误检率实验结果
同时,基于CFSFDP算法的异常检测还具有快速查找异常值的特点。在实验内存为8 GB、CPU为1.6 Hz的运行条件下,3种算法的计算耗时如表1所示。

表1 3种算法的计算时间
从表1可以看出,基于CFSFDP算法的异常检测运行时间是比其他两种算法都要短。这不仅证明了基于CFSFDP算法的异常检测可以减少计算量,具有快速找到异常值的特点,而且证明了其对大规模数据集具有更好的适应性。
综上,所提出的基于CFSFDP算法的异常检测同时具有检测率高、误检率低和运行时间少的特点。在电力生产、调度和决策过程中,可以起到良好的监督防范作用。在用户防窃电方面也能为电力企业提供有力的依据,能够更好地为电力生产和电力缴费服务。
4 结 语
上面对于电力数据的异常检测问题进行了研究,提出了一种基于CFSFDP聚类算法的电力数据异常值检测方法。该方法基于原本的密度峰值快速搜索算法提出的两点有关于聚类中心的假设,设立了离群值指标,在该指标的判断下寻找异常值点,实现了异常值点的快速寻找。同时根据离群值下降趋势,提出一种不需要进行人工选择的自动选择异常值点的策略,避免了进行人工选择时主观因素的影响。通过对比该方法与利用DBSCAN直接寻找异常值和利用局部异常因子LOF寻找异常值的方法,发现该方法能够有效、快速地寻找出异常值点,且该算法复杂度低,耗时短,适合作为边缘设备检测电力数据的算法。
猜你喜欢
计算机与现代化(2022年10期)2022-10-18
中华书画家(2021年12期)2022-01-06
散文诗(2020年1期)2020-07-20
铁道通信信号(2019年6期)2019-10-08
小型微型计算机系统(2018年8期)2018-09-07
环球市场信息导报(2017年36期)2017-12-24
雷达学报(2017年6期)2017-03-26
东方艺术·国画(2016年3期)2017-02-08
阅读(中年级)(2016年4期)2016-11-19
发明与创新(2016年38期)2016-08-22
