
基于关联规则及BP神经网络的风电场输出功率预测
2021-09-11 03:28雷蕾潇张新燕
安徽大学学报(自然科学版) 2021年5期
雷蕾潇,张新燕,孙 珂
(新疆大学 电气工程学院,新疆 乌鲁木齐 830046)
随着经济的发展,能源短缺与环境污染问题越来越严重.风力发电是可再生能源领域中最成熟、最具规模开发条件的发电方式之一.风电场输出功率预测是保障风能安全、稳定、高效的技术手段.根据采集的实时气象、输出功率等数据,分析、挖掘数据特征,预测风电场输出功率,对全网电力平衡及保障系统安全稳定运行具有重要意义.气象因素的不确定性、不稳定性及数据间的相关性增加了风电场输出功率预测的难度.电网智能化使数据数量增加、质量下降,在一定程度上降低了风电场输出功率预测的准确度.
常用的输出功率预测方法有:时间序列法、灰色预测法和卡尔曼滤波、BP(back propagation)神经网络、支持向量机、回归预测等.文献[8]采用Random Forest算法对风速、风向进行预测,提高了风电场输出功率预测的准确度.文献[9]提出了天气数值预报与多元线性回归相结合的模型,拟合出准确度高、误差小的回归方程,利用风电场输出功率的实测数据对该模型进行验证,提高了输出功率预测的准确度.文献[10]对神经网络算法进行改进,使用大量实测数据进行训练,提高了输出功率预测的准确度.文献[11]使用灰色关联度和支持向量机分析气象因素与负荷间的变化,能对短期预测进行精细控制.文献[12]考虑实时气象耦合作用,采用时域卷积网络提升了预测的准确度.文献[13]采用K-means 算法对样本数据进行聚类分析,根据聚类结果选取同类历史负荷为训练样本数据,提高了预测的准确度.
在复杂的风电场运行环境下,单一的气象因素不能准确反映气象对输出功率的影响,且在数据存储和传输的过程中会出现数据异常或空缺的情况,降低了预测的准确度.因此,笔者提出基于关联规则及BP神经网络的风电场输出功率预测方法,该方法对异常和缺失数据进行处理,采用改进K-means聚类算法对温度/风速气象数据进行聚类分析,使用Apriori算法挖掘风电场输出功率与气象因素间的关联规则,将关联规则应用于BP神经网络,以提高预测的准确度.
1 风电场输出功率预测前的数据预处理
笔者将风电场作为研究对象,使用聚类分析及数据间的关联规则,结合BP神经网络预测风电场的输出功率.在功率预测前,须对历史数据进行预处理.某时刻输出功率变化值超出波动范围时,计算数据偏离度,将其与设定的波动阈值进行比较,找出数据异常值和缺失值,并将异常值设为空值.偏离度及其相关参量的表达式为
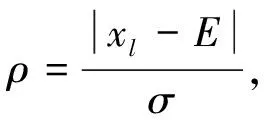
(1)
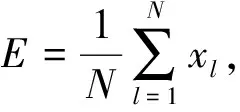
(2)

(3)
其中:ρ
为偏离度,x
为某点样本值,E
为样本均值,N
为样本数,l
为数据点的序号,σ
为标准差.将所得数据与前一天同一时段数据进行对比,采用拉格朗日插值法得到插补的风电场输出功率.利用Pearson相关系数对风电场输出功率与各数据特征值间的相关程度进行计算.相关系数及其有关参量的表达式为
(4)

(5)

(6)
其中:p
为相关系数,x
为某点的风电场输出功率,y
为某点的气象数据.2 基于关联规则及BP神经网络的风电场输出功率预测
2.1 改进的K-means算法
K-means算法是基于距离的动态聚类算法,通过聚类判定两对象间的相似度,距离越近,相似度越大.传统的K-means算法一般将开始的样本作为初始聚类中心,这种方式具有随机性和不确定性,易导致误差大、迭代次数多的问题出现.针对该问题,笔者提出改进的K-means算法.
数据集A
={(x
,y
),(x
,y
),…,(x
,y
)},数据点与原点(0,0)的距离为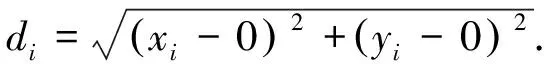
(7)
把极差与聚类数k
值的商记为单位聚类数的距离,其表达式为
(8)
其中:d
,d
为分别距离的最大、最小值.把第j
(j
=1,2,…,k
)类聚类中心的位置矢量的大小记为R
,其表达式为R
=j
×r.
(9)
误差平方和(SSE)是手肘法判定最佳聚类数的核心指标.SSE的表达式为
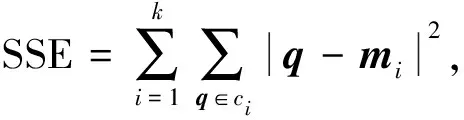
(10)
其中:c
表示样本的第i
簇;是c
中某样本点的位置矢量,是聚类中心的位置矢量.采用改进的K-means算法对测量的数据按照风速和温度特征进行聚类,具体步骤如下:
(1) 计算所有数据点与原点(0,0)距离d
.将R
作为初始聚类中心集合M
(a
),a
的初始值取为1.(2) 使用欧式距离计算公式计算x
与R
间的距离,其表达式为
(11)
(3) 计算各组新的聚类中心集合M
(a
+1).
(4) 若M
(a
+1)=M
(a
),则迭代结束,M
(a
)为聚类中心.否则,进行(2)步,直到迭代结束.该改进算法对温度/风速气象数据进行聚类分析,能减少重复扫描,降低寻找频繁项的时间,进而提高算法的效率.
2.2 改进的Apriori算法
Apriori算法通过循环搜索寻找频繁项,挖掘数据库中各项的相关性. Apriori算法主要完成以下两个任务:
(1) 将两个u
项频繁集连接为候选的(u
+1)项频繁集.(2) 通过设定的最小支持度排除不必要的中间结果,获得最高的频繁集.
Apriori算法结构简单、计算思路清晰、对关联规则的查找具有优势,但是其计算效率不高.针对Apriori算法的不足,笔者提出改进的Apriori算法.通过将关联规则中的支持度和可信度赋值给对应的初始权值,该改进算法能发现样本中不同数据类型间的联系,进而找到风电场输出功率与气象因素间的关联规则.将关联规则应用于风电场功率预测,可减少权值更迭的次数以及降低误差,从而提升风电场输出功率的预测准确度.
2.3 基于关联规则及BP神经网络的风电场输出功率预测
BP神经网络由输入层、隐含层和输出层构成.BP神经网络通过向前传递误差信息、修正权值,达到降低误差的目的,最终使输出达到期望值.笔者结合改进K-means算法、改进Apriori算法及BP神经网络,提出基于关联规则及BP神经网络的风电场输出功率预测方法.将关联规则引入BP神经网络,用BP神经网络预测输出功率.基于关联规则及BP神经网络的输出功率预测的具体步骤如下:
(1) 对数据进行归一化处理.
(2) 采用改进的K-means聚类算法对温度/风速气象数据进行聚类.
(3) 使用改进的Apriori算法挖掘温度/风速与输出功率间的关联规则.
(4) 将关联规则中的支持度和可信度赋值给对应的初始权值,取学习速率γ
=0.
1、训练期望误差ε
=0.
01.(5) 输入历史气象数据,将其作为训练样本,计算各层的输出.
(6) 计算理论输出与实际输出间的误差.
(7) 误差大于设定误差时,通过输出误差与权值的负梯度修正权值,使误差减小.
(8) 检查误差是否低于期望误差?若是,则输出风电场输出功率预测结果;若否,则继续训练、预测,直至符合期望误差的要求.
3 算例分析
3.1 数据处理
该文数据来源于某地风电场2015年1月1日至2018年12月31日每隔1 h整点实测的输出功率,共计15 056个数据.实测数据还包括温度、湿度、风速、大气压、风向等整点气象数据.通过预处理对风电场输出功率数据进行异常值识别、空缺值置零处理,且用拉格朗日插值及牛顿插值法对数据原始值进行插补.数据原始值及插补结果如表1所示.由表1可知,两种方法的插补结果完全相同.

表1 数据原始值及插补结果
整个样本数据按相同组距分成9段,每个数据段平均采样点数为500,在同一个数据段内取风速、温度、输出功率的平均值.
根据处理后的数据,计算各数据特征量间的Pearson相关系数.从相关系数可知,风电场输出功率与湿度、大气压及风向低度相关,风电场输出功率与温度及风速中度相关,故该文能挖掘出温度、风速与风电场输出功率间的关联规则.
3.2 预测结果
该文采用3层BP神经网络,输入层包含5个节点,隐含层包含2个节点,输出层包含1个节点.将风速、温度等气象因素作为神经网络的输入,将风电场输出功率作为神经网络的输出.将聚类数k
=10的关联规则的支持度和可信度赋值给对应的初始权值.取前2 160个数据作为训练样本,后240个数据作为测试样本.4种方法的预测误差如表2所示.由表2可知,相对其他3种方法,该文方法的最大相对误差、最小相对误差、平均相对误差均最小,其最大相对误差不超过5.78%,最小相对误差仅为0.01%.可见该文方法能提高风电场输出功率预测的准确度,具有有效性.
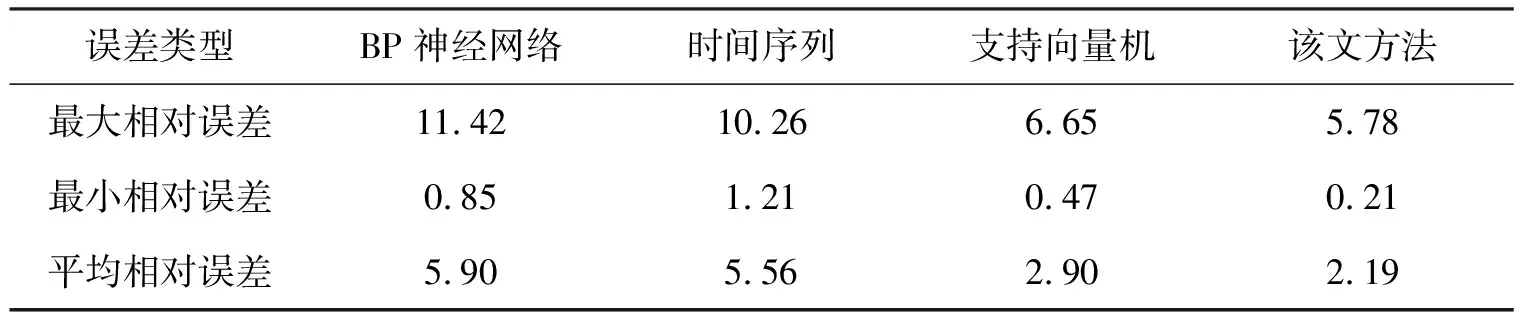
表2 4种方法的预测误差 %
该文方法能有较高的预测准确度,主要原因为:改进Apriori算法能挖掘出温度/风速与输出功率间的关联规则,且将此关联规则引入BP神经网络进行功率预测.
4 结束语
笔者结合改进K-means算法、改进Apriori算法及BP神经网络,提出了基于关联规则及BP神经网络的风电场输出功率预测方法.将4种方法的预测误差进行对比,结果表明:相对其他3种方法,该文方法的最大相对误差、最小相对误差、平均相对误差均最小.可见该文方法能提高风电场输出功率预测的准确度,具有有效性.
