
基于多目标决策的时间序列数据挖掘算法
2021-09-05 11:43贾晓强
电子设计工程 2021年17期
贾晓强
(渭南师范学院计算机学院,陕西 渭南 714099)
计算机技术的发展使得用户需求日益增长,同时也使得数据呈爆炸式增加,大数据的发展给各行各业带来了前所未有的便利,特别是医学、金融、生物、工程、通信等行业都在发展的过程中积累了许多的数据,其中有些数据的排序方式是按照时间排序的,这就是时间序列数据。当得到了这些积累下的数据之后,就需要对时间序列数据进行深度挖掘。具体到某个领域的时间序列数据是非常庞大和复杂的,从这些数据中获得有用的信息是一项非常繁琐的工作。而由于现有的时间序列算法挖掘的数据携带噪音,如何解决数据挖掘中的噪音问题就很有必要。
1 目标决策理论与方法
1.1 多目标决策
在多个决策者相互之间出现矛盾的情况下如何解决多目标决策问题[1-3]就需要做目标规划、找出多个指标点、利用多属性效用方法求解多目标问题等。在对某个决策做出选择的时候,会预先设计出多个解决方案,在进行多目标决策时,为了能够寻找到最优解,主要将其中刚好可以解决的问题,但不是超出及格线的解决方案剔除掉,再通过科学分析的方式将类似的解决方案进行合并,选择几个综合的目标。
1.2 多目标决策的方法
在日常生活和管理中,常会遇到带有相互矛盾指标的决策。例如成本和质量的指标矛盾关系,要想质量保持在上等水平的同时又要成本很少,这明显是不太可能的事情,提高成本才能保证质量。为了能够在矛盾的指标中寻找最好的决策方案,就需要用到多目标决策理论,其中多目标决策的方法有TOPSIS、层次分析法、灰色关联分析法、简单线性加权求和法等。该文将着重介绍模型所使用的两种方法。
1.2.1 层次分析法AHP
层次分析法的基本思想就是通过将目标问题建立层次结构模型并结合专家建议构建判断矩阵,从而得到最优的方案,具体的计算步骤如下:
1)构建由目标层、方案层、准则层组成的决策层级结构。
2)构造判断矩阵。通过比例标度表(如表1所示),对两两层级进行互相打分。
3)计算最大特征向量、权重和特征根。
4)根据一致比率进行一致性校验。
5)分析一致性检验结果,得出最好的方案。
AHP比例标度表如表1所示。

表1 AHP比例标度表
1.2.2 TOPSIS方法
TOPSIS方法又称逼近于理想解的排序方法,是一种常用且有效的多目标决策方法。其步骤如下:首先,将源数据作归一化处理;然后,从多个目标中通过矩阵找出最好和最坏目标;最后,利用欧氏距离来计算各个评价目标与正理想解和反理想解的距离,从而获取各目标和理想解的贴近度,并按理想贴近度进行排序。若该值越接近1,则评价目标越接近最好目标,否则越接近最坏目标。
2 时间序列数据挖掘
时间序列是在不同时间上同一种现象相继观察值排列而成的一组数字序列,它以时间为标准来分析问题的[4-6]。对于时间序列数据来说,它存在于各行各业。例如金融数据、DNA序列、机器故障追踪检测等,因为时序性一般都是以时间为节点,所以导致了其数据是非常大的,这对数据挖掘工作造成了一定的困难,所以在进行时间序列数据挖掘的过程中,需要对时序数列进行一个排序,实际场景往往是基于一个或多个时间序列的数据,从数据中提取出时序的特征、数值、周期、趋势,进行一系列科学的分析,从中挖掘到所需要的内容,去发现时序的规律。
3 算法构造
3.1 时间序列数据挖掘研究背景
互联网技术的飞速发展和物联网技术的兴起,计算机时代已经慢慢步入大数据时代。随着时间序列数据的出现,数据的容量变得越来越大,如何通过计算机从海量数据中挖掘出有用的时间序列数据是当务之急。时间序列是以时间为节点,通过节点在计算机上进行排序,计算出每个节点之间的归属度,然后对计算结果进行分析,但是在挖掘时间序列的过程中会出现噪声干扰的情况,为了克服或者减小噪声[7-8]对时间序列数据挖掘的影响,引入了依托于多目标决策的时间序列数据挖掘算法。
3.2 多目标决策方式在时间序列数据挖掘算法的应用
多目标决策理论一向极富挑战性,且非常活跃,在多目标决策过程中,要关注决策背景[9-10],在面对多个目标之间出现冲突的时候,要对矛盾和分歧进行考虑,在解决问题的时候要考虑到统筹学、统计学、管理学等多个学科交叉,排序出多个方法理论体系,将排序提出的多个方法运用在多目标决策理论的基础上,再对时间序列数据进行深度[11-12]挖掘,得到想要的内容。
该文以国家历史宏观经济指标为基础,通过采用TOPSIS方法和层次分析法AHP计算出国家年度的贴近度并排序,使用熵权法确定时间序列的权重,用K-means聚类[13-14]方法对国家贴近度聚类,进行敏感度分析后确定模型的好坏来判断是否计算加速比。具体步骤如下:
1)构建初始矩阵
选择m个评价指标和n个评价对象,并构成矩阵。其中,效益指标和效用指标的公式分别为:
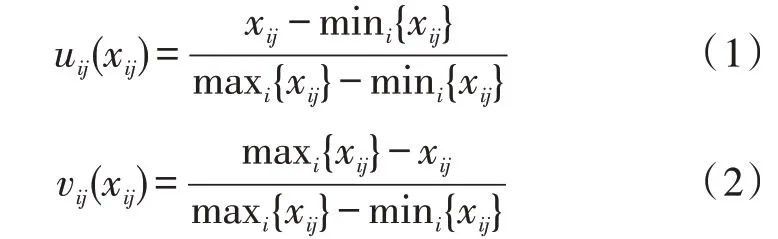
标准矩阵为:

2)AHP确定指标权重
由于AHP主观因素占据较大比重,所以采用一致性检验的方法来避免评价不准确情况的发生。
3)加权标准化矩阵
根据式(1)和式(2)得到加权标准化矩阵:

由上述过程可以得到标准化矩阵到正理想解的距离为:
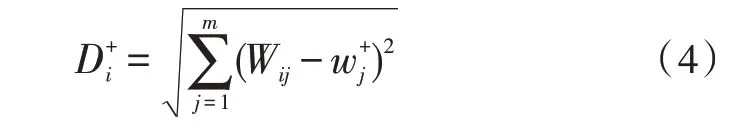
标准化矩阵到负理想解的距离为:
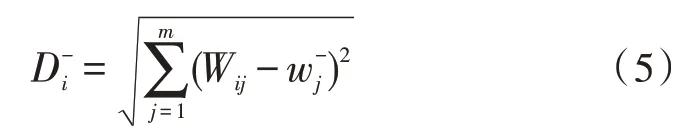
4)时间序列处理
在信息论中,熵越大对应的不确定性就越大。将熵引入时间序列中,其反映各评价对象在某一时间上和所有时间内的差异。对此,可引入线性规划,得实际贴近度:
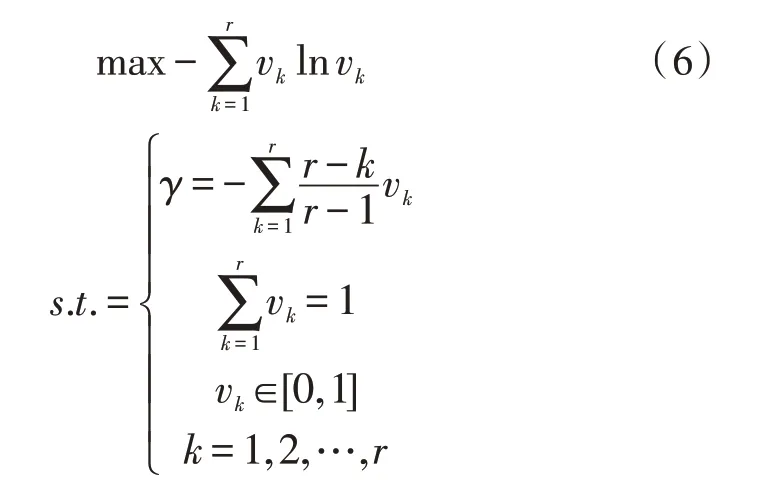
其中,vk表示各个时期的权重,k表示时期数,γ表示时期的重要性,并且其值在0~1之间,其值越接近于1,表示非常重视远期数据,否则相反。
5)K-means聚类
K-means聚类是以距离为依据的分类方法,可直接划分出结果。可直接将上述得到的国家效用值进行排序,对排序结果进行聚类,对聚类的结果计算加速比,其中,p表示节点数量,T1表示顺序执行算法的时间,Tp表示当有p个节点时,并行算法所执行的时间。
4 实验结果仿真
4.1 实验数据
该文选取的是1990-2006年间世界银行公布的32个国家,其中欧洲、亚洲、美洲和澳洲的国家分别有17、7、6、2个,考虑到模型的有效实施,不考虑发生的突发事件等因素。
4.2 实验目标
文中提出基于多目标决策时间序列数据挖掘方法,对国家主权信用违约风险进行了定量分析,预通过模型发现高危的国家(效用值最低),来分析经济危机时的国家信用风险情况。
通过实验发现,目标国家中的8个高风险国家和6个低风险国家是稳定不变的,说明具有高的主权违约风险的国家,有较大可能出现主权。对比次贷危机后主权信用违约[15]发生的实际情况,可以看到几乎与模型结果一致。用K-means聚类方法来对国家贴近度聚类,进行敏感度分析后确定模型的好坏来判断是否计算加速比,聚类结果如图1所示。
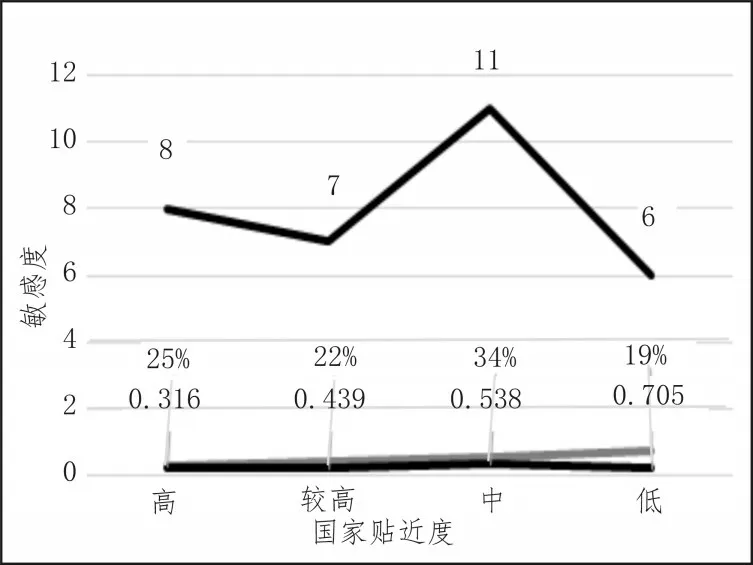
图1 K-means聚类结果
4.3 实验结果
通过聚类分析方法得到具有良好效果的多目标决策方法TOPSIS和AHP,但是为了保证依托于多目标决策的时间序列数据挖掘算法的整体是有效的,该文选择在Hadoop平台上进行可扩展性和加速比的测试。
加速比主要是测量数据处理规模和计算资源增长时,算法的处理能力。例如在处理数据时,数据的处理速度随着数据的增多和变复杂也在同时不断优化、加速,这就表明加速比好,该文将多个时间序列数据挖掘的方式的加速比进行对比,分别为基于多目标决策、基于中心度和基于时空模式,如图2~4所示。
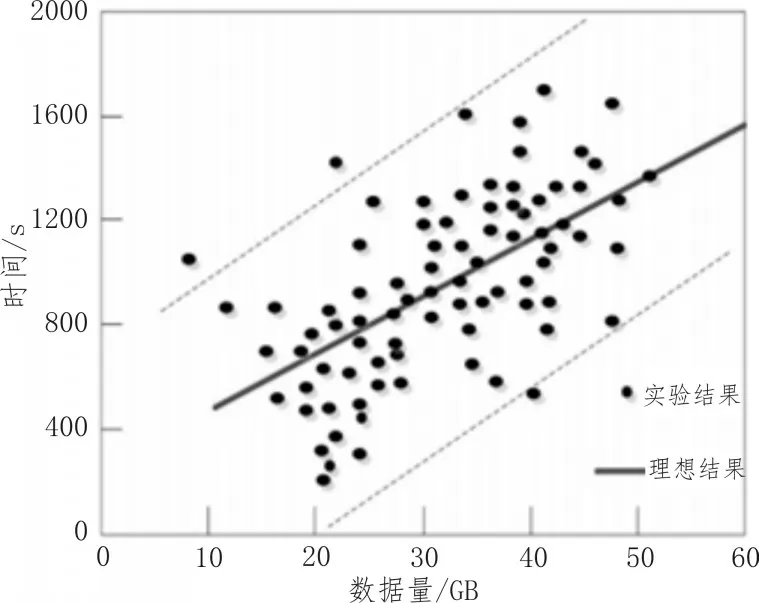
图2 基于多目标决策的时间序列数据挖掘算法的加速比
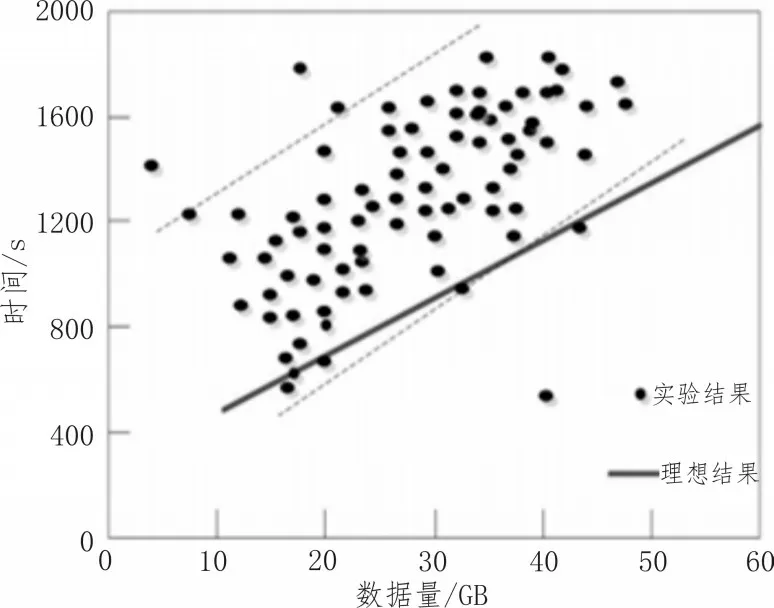
图3 基于中心度的时间序列数据挖掘算法的加速比
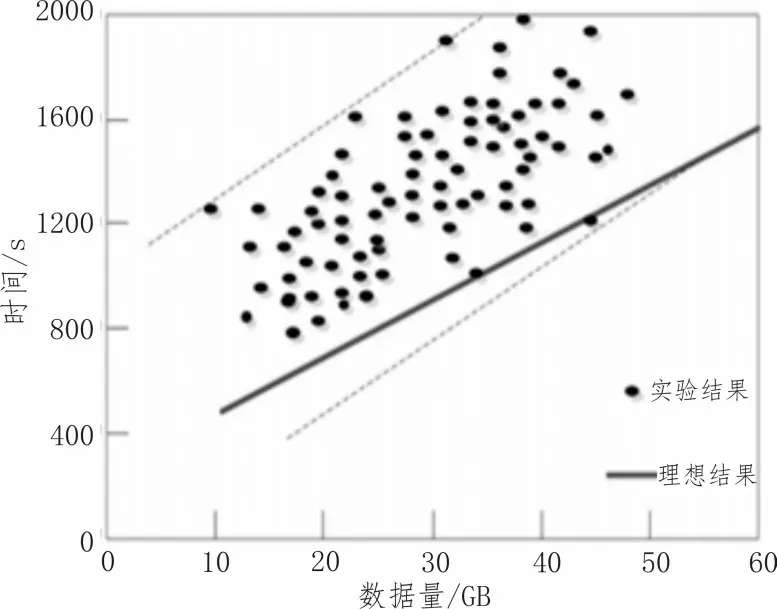
图4 基于时空模式的时间序列数据挖掘算法的加速比
从测试结果可以清晰地看出3种方法所得结果具有明显的差别。其中基于中心度和基于时空模式的时间序列数据挖掘算法都较为明显地偏离了理想结果,并且比较杂乱,无明显规律,而基于多目标决策与理想结果偏差很小,并且呈线性增长。此外在处理相同数据量时,在理想结果下后两者所需要的处理时间比采用多目标决策方法所需的处理时间多很多。这就表明基于多目标决策的时间序列数据挖掘算法的加速比很高,因为这种算法在进行时间序列数据挖掘的时候,减少了噪声对数据挖掘的影响,提高了时间序列数据挖掘算法的加速比。
然而随着硬件的增加,在数据挖掘中算法处理资源时,若所用的时间呈线性减少则表明算法具有良好的扩展性。为了证明基于多目标决策的时间序列数据挖掘算法具有很好的扩展性,该文将基于多目标决策、基于时空模式、基于中心度这3种方式进行对比,来证明基于多目标决策的优势[16]。如图5所示。
分析图5可以发现,基于中心度和时空模式的时间序列算法图线都在基于多目标决策时间序列算法之上,说明前两者所用时间要明显大于后者。此外也可以发现基于时空模式和基于中心度的时间序列数据挖掘算法所需要的时间随着节点的增加而增多,但是基于多目标决策的时间序列数据挖掘算法随着节点的增加呈下降的趋势,由此可以证明基于多目标决策的时间序列数据挖掘算法具有很好的扩展性,是其他两个方式不能比拟的。
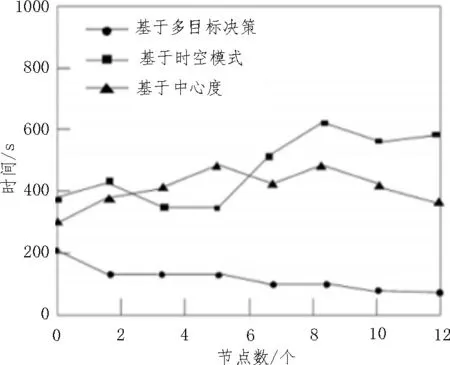
图5 3种不同时间序列数据挖掘算法所用时间对比
4.4 实验评估
为了验证模型的有效性,进行敏感性分析。发现改变任意一个权重,不影响排序的结果。而TOPSIS方法是动态的,所以通过敏感性分析可以进一步研究动态TOPSIS模型的权重参数的临界值,寻找关键指标的变化区间,对模型参数的适用性进行分析,提高该模型的鲁棒性。以国外直接投资为例发现其区间为[0.08,1],即该区间内的取值将不影响其国家主权信用风险[16]排序。由此可以发现使用多目标决策方法TOPSIS得到的效果是良好的,可证明所建模型具有很强的鲁棒性。
5 结束语
时间序列数据不同于传统的数据,它是以时间为节点的,在进行数据挖掘时也是按照时间顺序挖掘的。在时间轴下,时间序列数据的分布比较离散和稀疏,在数据的挖掘过程中会受到很多噪音干扰,通过3种方式来进行时间序列数据挖掘,得出基于多目标决策的时间序列数据挖掘算法是最适合的,是最能挖掘出有效信息的,效率也是最高的。而该文的不足之处在于只是研究众多领域数据中的金融数据,并没有将其他领域如医学领域数据进行实验并验证,所以下一步工作是将不同领域的数据代入模型进行实验和分析,并探索不同的多目标决策分析方法,对比不同的聚类方法,得到最佳的模型。
猜你喜欢
中学生数理化·七年级数学人教版(2022年11期)2022-02-14
大众投资指南(2021年35期)2021-02-16
科普童话·学霸日记(2020年1期)2020-05-08
铁道通信信号(2019年6期)2019-10-08
小天使·一年级语数英综合(2019年2期)2019-01-10
电力与能源(2017年6期)2017-05-14
雷达学报(2017年6期)2017-03-26
信息通信技术(2015年6期)2015-12-26
电子设计工程(2015年6期)2015-02-27
华东师范大学学报(自然科学版)(2014年6期)2014-02-27
