
基于fastText的恶意域名分类方法
2021-09-05 11:43匡立伟
电子设计工程 2021年17期
姜 天,匡立伟
(1.武汉邮电科学研究院,湖北 武汉 430073;2.烽火通信科技股份有限公司,湖北 武汉 430073)
僵尸网络(botnet)通常由大量被感染恶意代码的主机(bot)、命令和控制服务器(C&C server)以及主控端(Botmaster)构成。攻击者使用主控端向C&C server发送操作指令,服务器再将命令下达到各个被控制主机,进而实现对目标终端的分布式拒绝服务(Distributed Denial of Service,DDOS)、垃圾邮件分发以及恶意软件下载等网络攻击[1]。为了防止C&C服务器的域名被黑名单拦截,避免出现主机域名无法解析的情况,攻击者会使用一种域名变换技术(Domain-Flux)来达到高频率映射C&C服务器域名到IP地址的目的[2],域名生成算法(DGA)则是该技术的具体实现。首先DGA会定期生成大量的随机域名,接着C&Cserver选择其中指定的域名进行注册,注册完成后被控制主机能够解析服务器的地址。
使用DGA生成恶意域名,一定程度上增强了僵尸网络的隐蔽性和灵活性。针对字符级别的DGA域名检测,文中提出的方法能够对DGA家族进行识别和分类,并且能够有效提升发现和追踪僵尸网络的能力。
1 相关研究
对于字符级别的恶意域名,目前主要分为基于统计特征的机器学习和基于深度学习模型两种检测方式[3]。
由于正常域名和恶意域名之间的差异主要体现在主机名上,因此通过人工提取字符的统计特征,然后使用相应的机器学习算法即可完成DGA检测任务。文献[4]提取了域名字符的统计特征和n-gram特征,并使用3种机器学习模型来评估域名特征识别性能。实验结果表明,使用特征组合的n-gram(n=1,2,3)模型所得的精确率和召回率较高,并且多层感知器(MLP)的DGA域名检测准确率高于其他两种算法。文献[5]提出一种基于大数据平台的DGA检测系统,其核心由分类分析和聚类分析模块构成。该系统使用预训练好的随机森林模型来分离正常域名和可疑DGA域名,使用X-means算法对DGA域名进行无监督式聚类检测。文献[6]使用隐马尔可夫模型中的Baum-Welch算法和Viterbi算法对未知域名进行分类,实验结果显示,该模型可以实现恶意域名的快速高效检测。
随着自然语言处理和计算机视觉等人工智能领域的发展,一些深度学习模型也逐渐被运用在恶意域名检测任务中[7]。文献[8]提出一种基于LSTM的恶意域名分类与检测模型。通过二分类和多分类实验结果的统计数据可以看到,该模型能够较为准确地识别DGA域名。文献[9]提出DBD(Deep Bot Detect)检测模型,该模型由文本预处理、最优特征提取和分类模块构成。DBD模型的训练参数较少、训练速度快且发生过拟合的概率较小。文献[10]使用word-hashing技术,首先将域名转换成高维稀疏向量,然后通过深度神经网络(DNN)的隐藏层来学习bigram特征,最后使用输出层输出分类结果。模型整体的泛化能力强,且准确率比使用自然语言特征分类算法得到的结果高。
2 fastText模型及其原理
fastText是Facebook AI Research在2016年开源的一个被用于对词向量和句子分类进行高效学习训练的工具库。该工具可以在监督和非监督模式下训练单词和句子的向量表示。训练完成后生成的词向量,可以进一步用在其他模型的初始化和特征选择等任务中[11]。
fastText作为一种快速文本分类工具,其最大的特点是速度快。相比较其他文本分类模型,诸如逻辑回归(Logistic Regression)和神经网络(Neural Network)等,fastText在保留了较高分类准确度的情况下,还极大地缩短了训练和测试的时间。除此之外,使用fastText也不需要提供预训练好的词向量。
2.1 基础架构
一个简单有效的文本分类框架通常使用词袋模型(Bag of Words,BoW)来表示独立的句子,同时搭配一个训练好的线性分类器(比如逻辑回归和支持向量机等)。但由于线性分类器不能在特征和类别信息之间共享参数,这样会限制模型整体的泛化能力,因此需要将分类器分解为低阶矩阵[12]。
fastText将上述思路与神经网络的分层思想相结合,构成了一种快速文本分类器的设计方案。图1展示了fastText的基础架构。
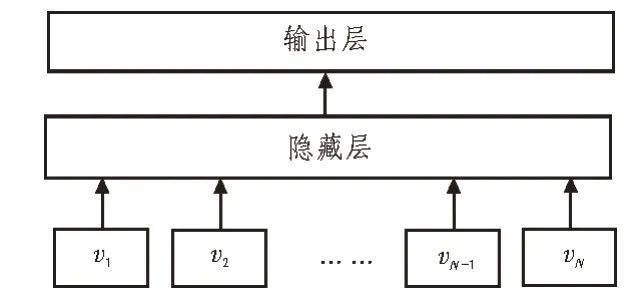
图1 fastText基础架构
从图1中可以看出,fastText模型主要由输入层、隐藏层和输出层构成。首先通过输入层传入文本对应的n-gram向量,接着在隐藏层进行词向量的叠加平均处理,最后在输出层采用分层softmax预测结果,输出文档的判别类别[13]。因此,fastText的目标是将极大似然转化为对数似然,同时使其最小化。式(1)展示了目标函数的计算方法。
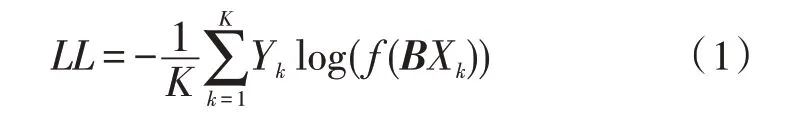
其中,Yk表示第k份样本对应的标签值,f表示使用softmax函数预测类别,B是一个权重矩阵,Xk代表文本特征向量。式(2)展示了Xk的计算方法。

func表示叠加平均函数,用来计算文本的特征向量。A是一个权重矩阵,vN(N=1,2,…)代表文本中的n-gram词向量。
2.2 分层softmax
当判别类别过多时,使用标准softmax计算概率值会非常耗时。因此,fastText采用基于哈夫曼树(Huffman Tree)的分层softmax(Hierarchical softmax),在计算目标类别的概率值P(y=j)时,只关心一条路径上的所有节点,而无需考虑其他节点的状态[14]。式(3)是计算从根节点到达y2节点(假设途经一个非叶子节点n(y2,1))概率值的过程。

∂代表sigmoid函数,θn(y,m)表示第m个节点的参数,X是softmax层的输入矩阵。以此类推,当最终输出类别为w时,对应的概率值可以用式(4)来表示。
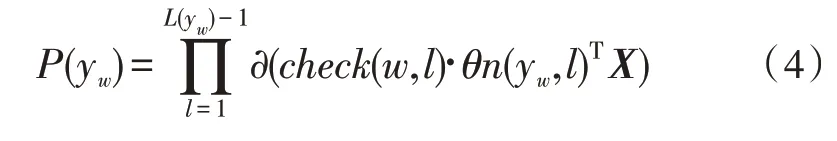
其中,L(yw)用来计算节点w距离根节点的深度,是一种自定义的函数。当第l+1个节点是n(yw,l)的左孩子时,check函数的返回值为1;当第l+1个节点是n(yw,l)的右孩子时,check函数的返回值为-1。
2.3 n-gram特征
根据划分粒度的不同,提取到的特征可以分为词粒度的n-gram特征和字符粒度的n-gram特征[15]。fastText同时支持两种切分模式,因此可以根据实际情况来设置相关的参数。文中提出的方法采用词粒度的切分方式,将分割开的域名字符当做独立的单词,整个域名字符串当做一个句子,从而分析域名字符排列顺序的合理性。
假设提取域名“baidu”的bigram特征,那么根据滑动窗口大小(n=2)进行划分,可以得到[“
fastText使用n-gram来提取文本特征,一方面可以使模型学习到局部单词顺序的部分信息,另一方面可以从字符级别n-gram中构造单词的词向量。这样即使有不在语料库中的词语出现,也可以利用预训练好的字符向量来组合表示[16]。
3 实验
3.1 实验环境
实验机器安装的操作系统为win10(64位),Python版本为3.5.4,sklearn版本为0.21.2,Keras的版本为2.3.0且以TensorFlow作为后端运行,tensorflowgpu的版本号为1.14.0。
3.2 实验思路
实验过程中模拟fastText的标准三层架构,依次使用Embedding(嵌入层)、GlobalAveragePooling1D(全局平均池化层)和Dense(全连接层)来拼接成最终的分类模型。使用定义好的评价指标来量化各参考模型的分类效果,在分析模型性能的同时讨论影响最终结果的参数因素和参数优化规则。
3.3 数据收集与处理
实验数据主要由两部分组成,一部分是从Alexa网站选取了排名前100万的域名,并将这些数据标记为正常样本(whitesample);另一部分是从安全实验室Netlab官网上下载的DGA种子文件,文件大小约为84 MB,其中包含了44种不同的恶意域名家族,共计1 256 160个DGA域名。
实验过程中采用了字符级n-gram切割方式,首先将组成域名的各个独立字符转换为ASCII码序号的表示形式,然后使用散列表(字典)存储n-gram特征的键值对,并且将n-gram特征值添加到每一个字符序列集合的尾部。由于嵌入层需要输入向量的维度保持一致,因此还需要使用pad_sequences函数来截取或填充数据。实验过程中保留了域名原来的“{二级域名.顶级域名}”结构。实验数据按照6∶4的比例划分为训练集和测试集。
3.4 参考模型
实验过程中除了使用fastText对恶意域名进行分类,还另选了两种深度学习模型(LSTM和CNNLSTM)以及一种机器学习模型(XGBoost)来对比测试。图2展示了提出的基于fastText的域名分类模型结构。
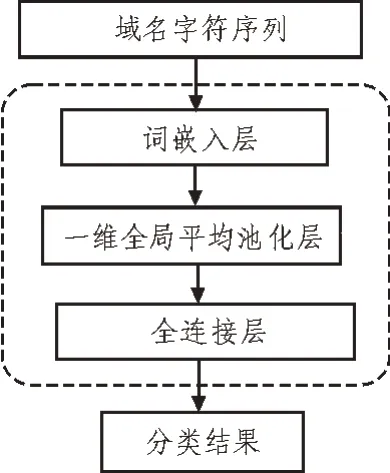
图2 基于fastText的域名分类模型结构图
从图2可知,携带n-gram特征的域名字符序列被送入模型后,首先经过词嵌入层转化为多维向量。接着使用一维全局平均池化层作为模型的隐藏层,用来对上一层输出的向量进行特征映射;最后的全连接层用来对特征映射进行softmax分类,并输出分类结果。
3.5 分类评估标准
在评估模型的过程中,用到了混淆矩阵中的3个一级指标,分别是TP(True Positive)、FN(False Negative)和FP(False Positive)。下面分别介绍各个指标代表的含义以及相关二级评价指标的计算方法。
TP代表真实值为positive,并且模型将样本划分到positive类的个数;FN代表真实值为positive,而模型认为是negative的数量;FP代表真实值为negative,而模型认为是positive的样本数量。由此可以使用式(5)得到精确率(Precision)的计算结果。精确率代表在模型预测为positive的所有结果中,模型预测正确的比重。
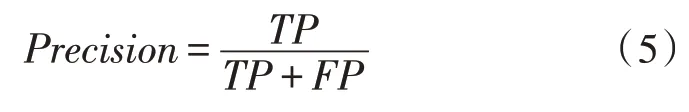
召回率表示在真实值为positive的所有结果中,模型预测正确的比重。式(6)是召回率(Recall)的计算方法。

F1值综合了精确率和召回率的结果。式(7)是F1值的计算方法。

除此以外,后续实验中还增加了两个评价指标。使用Accuracy(准确率)来表示被分对的样本比例,使用Loss(损失)来记录模型最终的损失值。
3.6 实验结果与分析
表1汇总了4种模型的分类情况,其中精确率、召回率和F1值均是指在45种类别上的平均表现。
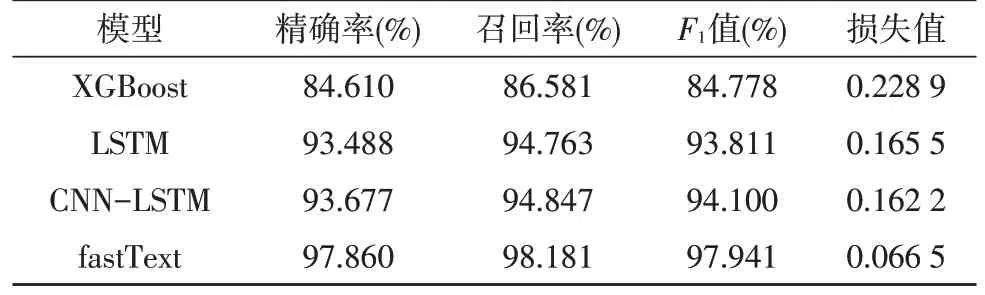
表1 模型分类结果表
从表1中可以明显看到,使用提出的fastText模型获得的3个二级指标对应的值均高于其他模型。其中,fastText的精确率比其他两种深度学习模型的值高约4%,比机器学习模型的值高约13%。fastText的召回率和F1值也较其他模型有很大提升,且模型最终的损失值也维持在0.1以下。
实验过程中还发现,分层softmax在效果上略差于完全softmax。考虑到分层softmax是完全softmax的一个近似,同时分层softmax可以在大数据集上高效地建立模型,但通常会以损失精度的几个百分点为代价,因此,fastText使用分层softmax得到的精确率略低于97.860%。
综上所述,fastText之所以能够具有较高的分类性能,主要得益于模型使用了字符的n-gram特征,以及在隐藏层对多个特征映射作spatial average(空间平均)。而其他模型的隐藏层通常包含大量参数,这样一方面影响了整个模型的泛化能力,另一方面增加了模型的训练开销。fastText不仅可以更深层次地学习域名字符的分布规律,同时降低了模型训练的难度。
3.7 模型性能的影响因素
由于在实验过程中涉及到超参数的设置,而这些参数的取值也在一定程度上决定了模型最终的分类性能,因此下面讨论部分参数对分类结果的影响,以及参数的优化规则。
3.7.1 词向量维度
Embedding的主要功能是数据降维和稠密表示,实验过程中使用多维向量来转换字符序列和n-gram特征。实验设置了几个依次递增的词向量维度作为自变量,图3展示了词向量维度分别为50、100、150、200、250、300时的模型准确率。
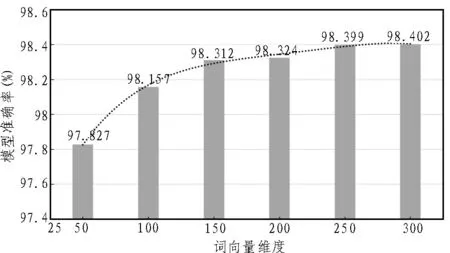
图3 向量维度与准确率关系图
准确率(Accuracy)反映了全体预测正确占全部样本的比例,是一个综合评价指标。图3统计了不同词向量维度下的模型准确率,并且利用四次函数拟合出准确率的变化趋势。从图3中可以直观看出,在向量维度等差增长的同时,准确率也在随着自变量由快渐慢地增长,当维度数达到200时基本趋于平稳。
由此可知,当词向量维度过低时通常表示能力不够,模型的准确率也维持在一个相对较低的水平。当词向量维度过高时,虽然模型的准确率相对较高,但在训练过程中容易出现过拟合现象,同时伴随Diminishing Return(收益递减)[17]的产生。
3.7.2 批处理大小
批梯度下降法(Mini-batches Learning)能最准确地朝着极值方向更新参数,同时每次迭代选取批处理大小(batch_size)的样本进行更新。图4展示了批处理个数分别为64、128、192、256时的模型损失值。
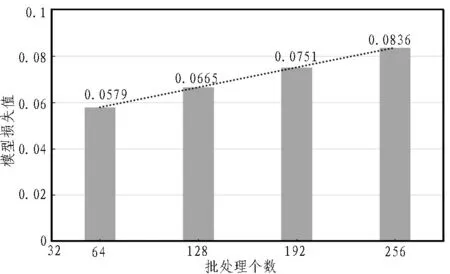
图4 批处理大小与损失值关系图
同样,使用四次函数来绘制损失值的变化趋势,可以看出,损失值随着自变量的增加而增加,且变化增幅趋于线性。经初步分析可知,当batch_size取值较小时,其每次迭代下降的方向并不是最准确的,Loss是在小范围内震荡下降的,这样有利于跳出局部最小值,从而寻找下一个Loss更低的区域[18]。而当batch_size取值较大时,虽然减少了训练时间以及加速了网络收敛,但是Loss值会很大概率落入局部最小区域,最终影响模型的分类性能。
4 结论
文中提出一种基于fastText的恶意域名分类方法。通过提取域名字符以及n-gram特征来生成词向量,使用隐藏层对向量进行全局平均池化,并将softmax与全连接层相结合来对恶意域名进行分类。实验结果显示,fastText模型的各项性能指标优于其他方法,同时模型复杂度和训练难度也相对较小。实验部分讨论了影响模型性能的参数因素,比较了不同取值条件下模型的泛化能力。
下一步会研究如何进一步提升模型整体的分类性能,同时考虑如何将fastText更广泛地应用在网络安全领域中。
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
数字通信世界(2019年3期)2019-04-19
中国教育网络(2018年12期)2019-01-18
少儿美术(快乐历史地理)(2018年7期)2018-11-16
中国交通信息化(2018年5期)2018-08-21
计算机与网络(2018年10期)2018-02-15
