
一种改进用户相似度的协同过滤推荐算法
2021-09-05 11:43刘小豫
电子设计工程 2021年17期
魏 浩,刘小豫,张 伟
(咸阳师范学院计算机学院,陕西 咸阳 712000)
随着互联网的高速发展,社会进入了一个“信息爆炸”时代。尤其伴随着电子商务的快速成长和网络购物的迅速普及,如何使用户在数量庞大的商品中快速、高效地找到感兴趣的商品,是电子商务网站面临的一个重大挑战。虽然用户能够通过电子商务网站的搜索功能获得商品信息,但要求用户使用关键字确切描述自己的需求,在不能准确描述所想购买商品的情况下,搜索功能无法发挥应有的作用。推荐系统不需要用户主动参与,就能根据用户以往的商品购买记录,推荐满足用户兴趣的商品。推荐系统不但增强了用户购物体验,而且通过发现潜在购买者,有针对性地推荐商品,使销售利润最大化,达到了双赢的效果。
目前,应用最广泛的是基于内容的推荐算法和协同过滤(Collaborative Filtering,CF)算法[1-3],协同过滤算法使用用户与商品的历史交互数据,并通过分析其他人的兴趣偏好,建立当前用户偏好模型,即体现了“协同”,该算法假设存在一组兴趣偏好相似的用户群。相比较基于内容的推荐算法,协同过滤算法对音频、图像等难以提取特征的非结构化对象有较好的推荐效果[4-5]。
1 基于用户的协调过滤算法
协同过滤推荐算法主要包括基于用户(Userbased CF,UCF)和基于项目(Item-based CF,ICF)两种协同过滤算法[6]。基于用户的协同过滤推荐算法包括以下3个阶段:
1)相似度计算:相似度计算的方法主要有Person相关系数、Jaccard相关系数以及余弦相似度[7]。计算余弦相似度时,需计算用户评分向量之间的余弦夹角,即为两向量的点积与其模的乘积之商,用来衡量两个用户之间的相似度,设两个用户u和v的评分向量分别为和,则两个用户之间的相似度如式(1)所示:
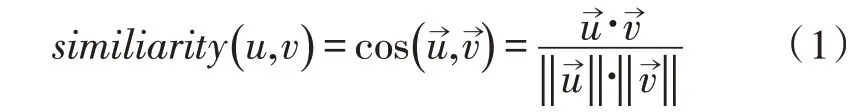
2)用户最近邻搜寻:通常用户最近邻搜寻的办法有两种,基于阈值设定和基于K最近邻搜寻。对于第一种方法,若相似度高于阈值即可进入最近邻集合,反之则剔除。而第二种方法中,根据相似度将目标用户的近邻用户进行排序后,选取前K个用户进入最近邻集合。两种方法都会面对如何设计阈值和选取K值的问题,K值过大会导致在最近邻集合中引入不相似或干扰用户,从而影响最终的推荐效果;K值过小则可能导致最近邻集合信息不全,同样不利于推荐效果。
3)预测评分并生成top-N推荐:完成最近邻搜寻后能够获得目标用户的近邻集,可用式(2)预测未评分项目的评分,将项目按照预测评分降序进行排序,把前N个项目推荐给目标用户。
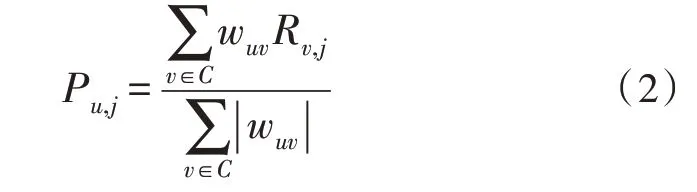
式中,用户u的最近邻集合为C,用户u与邻近用户v之间的相似度为wuv,邻近用户v对项目j的评分为Rv,j,Pu,j为目标用户u对未评分项目j的预测评分。
2 推荐算法的评价标准
推荐算法的准确度是衡量推荐算法优劣的关键,推荐算法评价指标包括对预测评分准确度和top-N推荐准确度两类评价指标,对top-N推荐准确度的评价指标主要有召回率(Recall)和准确率(Precision),对预测评分准确度的评价指标通常包括平均绝对误差(Mean Absolute Error,MAE)和均方根误差(Root Mean Square Error,RMSE)[8-9]。
平均绝对误差与均方根误差利用预测评分与真实评分间的误差大小来衡量系统的预测精度。MAE和RMSE值越小说明推荐质量越高,预测的评分与实际评分误差越小。MAE及RMSE的计算公式为:
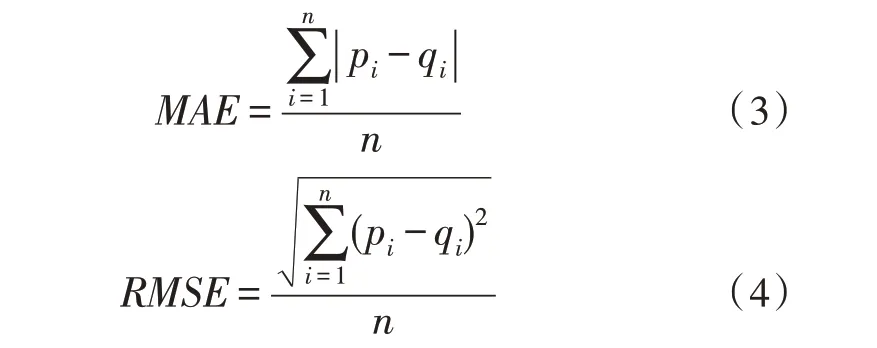
其中,{p1,p2,…,pn}为预测的用户评分集合,{q1,q2,…,qn}为实际的用户评分集合,n为用户评价的项目数量。
准确率(Precision)表示推荐列表中推荐的准确项目所占的比例,如式(5)所示:
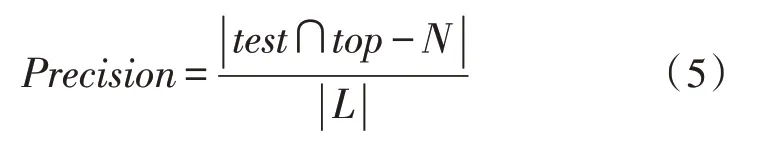
召回率(Recall)是用户推荐准确的项目在测试集中所占的比值,如式(6)所示:
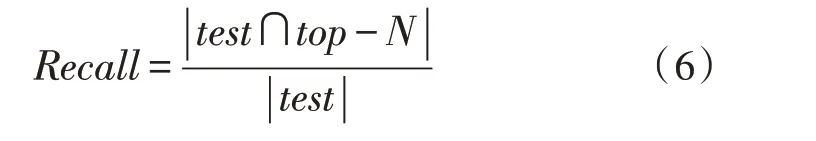
其中,test为测试集,top-N为预测评分的前N个项目,|L|表示设定的推荐列表长度。
3 数据稀疏性问题
协同过滤算法具有用户群体社会化的特点,且高度自动化、新兴趣发现等优势,能够推荐非结构化对象,因此在推荐系统中被广泛使用,但其存在稀疏性、冷启动和扩展性等问题[10-12]。
在电子商务系统中,由于用户和商品数量的急剧增加,加之用户缺乏对商品评分的主动性,使得用户评分的商品数量只占很少的一部分,用户与商品评分矩阵(表)非常稀疏,用户-商品矩阵的高度稀疏将造成相似计算出现很大误差,进而影响推荐系统的推荐质量和推荐性能。数据的稀疏性用稀疏度(Sparsity)表示,稀疏度是指评分矩阵中空值的数目与矩阵元素总数的比值,如式(7)所示:
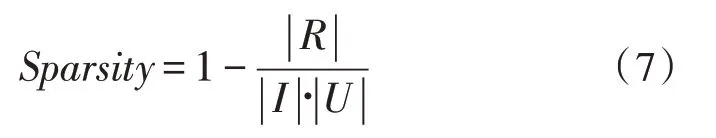
其中,|R|表示评分数,|I|表示项目数或商品数,|U|表示评分者数,Sparsity是所得的稀疏度[13]。
解决数据稀疏性问题的主要方法有降维技术、评分矩阵预填充、多种特征融合、数据聚类、以及相似度改进算法[14]。相似度计算作为协同过滤算法的重要部分,但由于评分矩阵的稀疏性,使两个用户之间的共同评分项数量很小,因此,传统计算相似度的方法会出现很大误差。文献[15]针对社交网络,提出了属性相似度及其构成与计算方法,有效地提高了推荐准确率。文献[16]在数据高度稀疏的情况,建立了梯形模糊的评分模型,并使用该模型计算用户之间的相似度。文献[17]针对评分矩阵的稀疏性,提出了一种加权相似度算法,以减小评分矩阵稀疏性导致的相似度误差。
4 改进用户相似度的推荐算法
在大多数推荐系统中,用户评过分的项目很少,计算用户之间的相似性会产生很大的误差,使得生成的用户近邻集合与实际的近邻集合有较大差异。同理,基于项目的协同过滤算法项目之间的共同评价也很少,使得计算的项目间的相似度误差较大,得到的项目近邻集合也有偏差[18-19]。文中提出了一种改进用户相似度的协同过滤推荐算法(Improved user similarity User-based CF,IUCF),该算法基于项目特征的稀疏数据预处理方法,结合用户的已评分信息及项目的特征,生成用户与项目特征兴趣矩阵,使用用户与项目特征兴趣矩阵计算用户的相似度,提升用户相似度的准确率,最终提高推荐的精度和准确度。
在一个推荐系统中,一般包含的项目数量十分巨大,而项目特征的个数要远远小于项目数,例如Movielens-100k数据集,电影的数目有1 682部,而电影的类型只有19种,一部电影可以属于一个或多个不同的类型。由用户与项目评分矩阵(表)生成的用户与项目特征兴趣矩阵,将大幅降低数据稀疏度,例如,在Movielens-100k数据集中,观众与电影评分矩阵(用户与项目评分矩阵)的数据稀疏度为0.937,生成的观众与电影类型兴趣矩阵(用户与项目特征兴趣矩阵)的数据稀疏度为0.205。由于观众与电影类型兴趣矩阵数据密度的提高,观众之间共同评分项数量增多,因此,使用观众与电影类型兴趣矩阵计算得到的观众相似度更加准确,更能反映观众对不同类型电影的偏好。
假设在一个包括N个用户和M个项目的推荐系统中,R为用户与项目评分矩阵,记作[Ru,i]N×M,其中,Ru,i表示用户u对项目i的评分。以Movielens-100k数据集为例,算法步骤描述如下:
1)数据读入和预处理:读入观众对电影的评分集合,把观众对电影的评分集合分成训练集train和测试集test两部分,使用训练集部分生成观众与电影评分矩阵R=[Ru,i]N×M,读入电影的类型描述集合,生成电影与电影类型矩阵(项目与项目特征矩阵)V=[Vi,f]M×Q。
2)由观众与电影评分矩阵R生成观众与电影兴趣矩阵R′:对于观众与电影评分矩阵R中的每个评分项Ru,i,当评分项Ru,i≧1时,设定Ru,i=1,生成的观众与电影兴趣矩阵为。
3)由观众与电影兴趣矩阵R′和电影与电影类型矩阵V生成观众与电影类型兴趣矩阵(用户与项目特征兴趣矩阵)T:观众与电影兴趣矩阵和电影与电影类型矩阵相乘得到中间结果矩阵,然后求出T′每行的和,计算得到矩阵T的每个元素,生成观众与电影类型兴趣矩阵T。
4)使用观众与电影类型兴趣矩阵T生成观众间相似性矩阵S=[Su,v]N×N:选择余弦相似度,计算每一个观众和其他观众的相似性,组成观众相似性矩阵S,通过式(1)计算可得到观众相似性矩阵S的元素Su,v,和是观众u和v在矩阵T中的观众与电影类型兴趣向量。
5)搜索最近邻:在不同数目的K最近邻情况下,对测试集中的每个观众,在观众相似性矩阵S中搜索与该观众相似度最大的前K个观众组成最近邻集合。
6)预测测试集中的观众对电影的评分:根据式(2)预测用户对1 682部电影的评分,例如测试集中的观众u,对电影的实际评分集合为{q1,q2,…,qn},对应电影的预测评分集合为{p1,p2,…,pn}{p1,p2,…,pn},根据式(3)计算MAE。
7)计算推荐准确率和召回率:依据给定top-N的N值生成推荐给观众的电影集合top-N,test为测试集,按照式(5)计算推荐准确率,按照式(6)计算推荐召回率。
5 实验描述及结果分析
实验使用的编程语言是python3.7,开发工具为Jupyter notebook,实验程序还使用了两个扩展程序库NumPy和Pandas。NumPy是一个基础性的python科学计算库,提供高维度数组与矩阵的计算能力,并提供大量方便用户调用的函数库[20]。Pandas是一个数据分析包,通过提供的标准数据结构以及快速、灵活的操作,成为了python环境下高效而强大的数据分析工具[21]。
实验所使用的数据集是Movielens-100k,由943名线上电影观众针对1 682部电影共10万条评分记录组成。该数据集包含电影的类型描述、观众信息和观众对电影的评分等3个数据集文件,电影类型有19种,观众对电影的评分是1~5的整数,每部电影至少被评价1次,每个观众至少给二十部电影评过分。原始数据随机分成5份,每次将其中4份数据作为训练数据,另一份作为测试数据,运行5次,并将5次实验结果的平均值作为最终的评测值。
实验选择了4个推荐算法评价指标包括推荐精度(MAE)、准确率(Precision)、召回率(Recall)以及预测耗时,使用这4个评价指标将IUCF算法与UCF进行比较。预测耗时是在同样的条件下比较两种推荐算法,计算推荐结果耗费的时间。该算法最主要的参数是用户最近邻的K值,选择用户不同的近邻数目对算法的结果有重要影响。
1)用户最近邻K值的取值范围为10~300,且为10的整数倍,UCF算法和IUCF算法的MAE值随K值的变化趋势如图1所示。当K小于140时,IUCF算法的MAE值小于UCF算法,K值越小,两种算法的MAE差值越大;随着K值的增大,当K大于140时,两种算法的MAE趋于相等。说明相比传统的UCF算法,其在用户最近邻K值越小时,预测的评分与观众实际评分更接近,推荐精度更高;当K大于140时,两种算法预测的评分基本相同,推荐精度也大致相等。
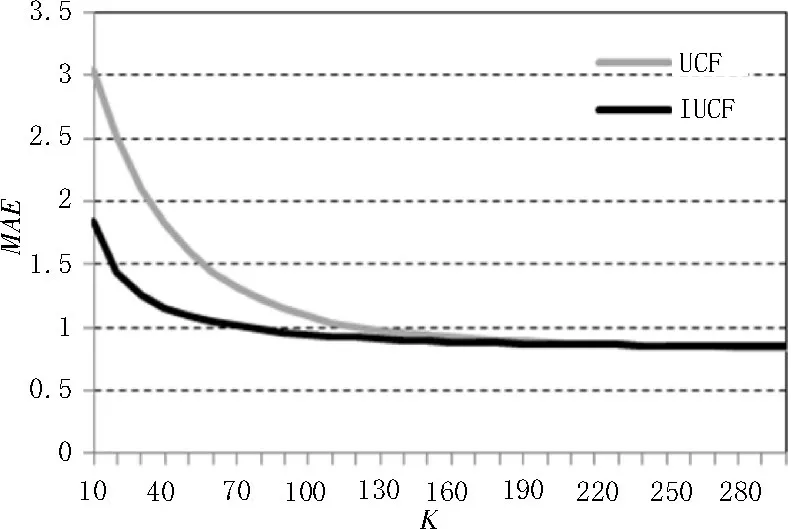
图1 算法MAE比较
2)K的取值方法与上面相同,取值范围为10~300,且为10的整数倍,两种算法预测耗时随K值的变化如图2所示。当K小于140时,IUCF算法的预测耗时小于UCF算法,当K大于140时,两种算法的预测耗时基本相等,并且随着K值的增大,两种算法预测耗时都趋于相同的值。从图2可知,当K小于140时,IUCF算法比UCF算法效率更高,当K大于140时,两种算法效率基本相同。
3)兼顾评分预测的准确率和算法执行效率,最近邻数目K值取为140,top-N推荐的N取值范围为10~500、且为10的整数倍,两种算法的准确率随N值的变化如图3所示。两种算法准确率曲线的基本趋势是随着N值的增加,准确率提高,当N等于360时,UCF算法的准确率最高;当N等于380时,IUCF算法的准确率最高。IUCF算法的准确率曲线始终位于UCF算法的准确率曲线上方,IUCF算法相比UCF算法准确率平均提高了0.45%,说明IUCF算法的准确率总体优于UCF算法。
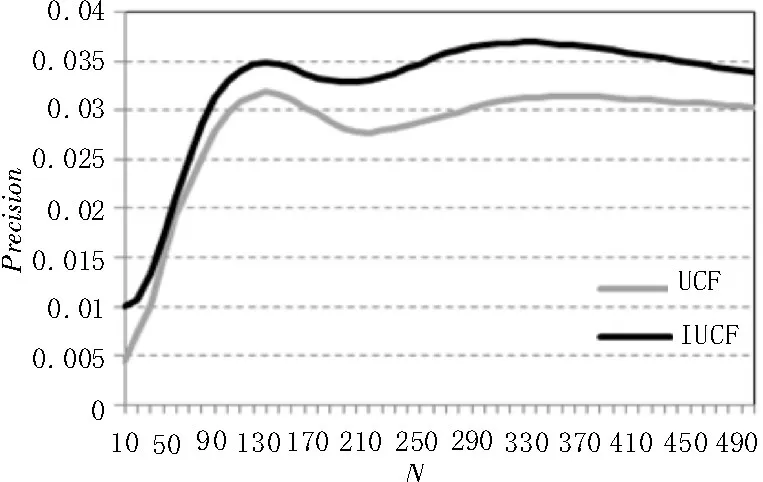
图3 算法准确率比较
4)同样取K为140,两种算法的召回率随top-N推荐的N值变化如图4所示。N值由10至500,且为10的整数倍,两种算法的召回率都随N值增大而提高,但IUCF算法召回率曲线始终位于UCF算法召回率上方,IUCF算法相比UCF算法召回率平均提高了5.2%,说明IUCF算法的召回率整体优于UCF算法。
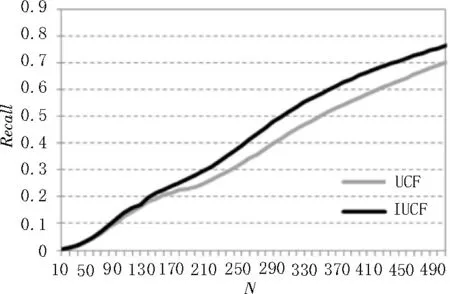
图4 算法召回率比较
6 结论
文中使用Movielens-100k数据集,选择了4个推荐算法评价指标,对比改进的用户相似度协同过滤推荐算法(IUCF)和传统的基于用户的协同过滤算法(UCF)。在用户最近邻数目K小于140时,改进的用户相似度协同过滤推荐算法推荐精度高,预测评分准确,推荐消耗的时间少,推荐效率高,而当用户最近邻数K大于140时,两种算法的推荐精度和推荐消耗时间趋于相等。在用户最近邻数K=140并且top-N推荐的N取值范围为10~500的条件下,IUCF算法的准确率及召回率从总体上看高于UCF算法。
猜你喜欢
黄河之声(2022年10期)2022-09-27
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
中国交通信息化(2018年5期)2018-08-21
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
中央民族大学学报(自然科学版)(2016年3期)2016-06-27
南都周刊(2015年4期)2015-09-10
