
基于深度学习的甜味剂分类模型
2021-09-04 12:01:48肖凌俊陈爱斌周国雄易积政
农业工程学报 2021年11期
肖凌俊,陈爱斌,周国雄,易积政
(1.中南林业科技大学计算机与信息工程学院,长沙 410004;2.中南林业科技大学人工智能应用研究所,长沙 410004)
0 引 言
甜味天生就有吸引力,强烈影响着人们的饮食习惯[1]。由于摄入糖类可以产生愉悦心情,全球食用高热量食物的人越来越多。但食用过量的高糖类甜食会带来很多健康问题,如体型过胖,更容易患上心血管疾病和 2型糖尿病[2]。因此,筛选或合成低热量甚至零热量而又不失甜味的甜味剂可以预防这些风险,寻找新颖的非营养性甜味剂是一个全世界范围内都值得研究的课题[3]。计算机技术和虚拟筛选方法在很大程度上推动了药物研究的进展[4-5],甜味剂的开发过程和药物相似,因此甜味剂的研究也可以借鉴药物发展的经验。目前寻找新型甜味剂主要是基于结构和配体的方法[6]:基于结构是以分子结构为研究对象,探究候选分子与甜味受体结合位点的结合能力[7-8];基于配体的方法主要是利用已知活性和试验数据的甜味剂、甜性物质,依靠形状相似性或药效团等性质,从分子库中搜索潜在甜味分子[9]。尽管人们在解码甜味感觉与受体的原理方面取得了进展[10-11],但基于结构去筛选数量众多的天然和合成的甜味化合物仍然是一项繁琐而艰巨的任务。
为了显著减少试验所需的时间和研究费用,快速识别潜在的甜味分子并降低成本非常有必要。Zhong等[12]采用多元线性回归(Multi-Linear Regression, MLR)和支持向量机(Support Vector Machine, SVM)基于320个化合物的数据集构建回归模型;Rojas等[13]使用偏最小二乘判别分析(Partial Least Squares Discriminant Analysis,PLSDA)和k近邻(k-Nearest Neighbor,KNN)方法建构定量构效关系(Quantitative Structure-Activity Relationship,QSAR)模型来预测分子结构与其甜味的关系,并表示该方法可以设计新型甜味剂。定量构效关系理论使用数学模型来描述分子结构和分子的某种生物活性之间的关系[14]。用于甜味剂和甜味化合物的机器学习预测方法主要有随机森林(Random Forest, RF)[15-16],遗传函数近似算法(Genetic Function Approximation,GFA)[17],PLSDA[18]以及结合多种机器学习算法[19-20]。其中PLSDA模型的决定系数R2只有0.748,GFA模型的R2达到了0.83,使用多种机器学习算法的模型R2更是达到了0.91。
虽然上述研究已经取得了一些成果,但他们的模型也存在一些共同的问题,如数据集普遍偏小,局限于特定的化学家族,模型的适用范围有限,并不能从分子库中有效地筛选。因此,本研究的主要目的是构建一种基于配体和深度学习方法的模型,可以从大量分子中准确筛选目标分子,为后续检验提供参考。
1 材料与方法
1.1 问题分析
目前甜味剂的作用机理主要以 Shallenberger等[21]AH-B理论和 Kier等[22]甜味三角理论为基础,但它同时也存在一些缺陷,甜味剂可能还与疏水基团的性质、分子内氢键、空间要求等有关。不同的甜味剂可能有相同的药效团或一类特性基团,但不是决定性的,例如爱德万甜和新橙皮苷二氢查耳酮(图1),而具有相同结构的黄腐酚作为啤酒花中特有的物质却呈现苦味,其他常用的甜味剂如阿力甜则没有该结构。
甜味苦味的感觉是由分子与 G蛋白偶联受体的关键结合位点相互作用而产生的,但甜味分子的结合部位通常超过3个,如国内常用的甜味剂阿斯巴甜有9个与受体的结合位点(图2),因此分子3D结构的繁多以及编译分子3D结构的巨大工作量也是甜味剂的开发难点之一。
设计并合成新型人工甜味剂依赖完整有效的甜味理论体系,但近百年来甜味剂的重要发现出自偶然机遇的较多。而想要编译数据库中所有分子的三维结构是很难做到的事情,因此无法在大数据集中快速筛选目标分子,不能直接探索未知的甜味分子。但相关研究人员需要一种不明确所筛选分子三维结构下的受体信息也能预测未知分子甜味的方法,因此可以采用深度学习的方法来预测,用已知的试验数据集建立预测模型继而从大量的未知分子中筛选出可能性最大的潜在甜味剂并分类。
1.2 基于深度学习的甜味剂分类模型
对于大数据集的快速筛选,二维数据是最合适的选择,但使用二维数据的同时也会“失真”,即很多关键因素图片难以表现,例如分子的可旋转键数、极性比表面积、折射率、极化率、氢键受体、氢键个数、水溶性、疏水基团、膜通透性、手性中心数、重原子数、总电荷和芳香环个数等等,因此还需采用分子描述符将结构与各种生物活性联系起来,以弥补预测方法的不足。试验中使用一些描述符的模型比使用所有描述符的模型产生了更好结果,仅仅增加描述符的数量并不能提高预测模型的性能,不是所有描述符都与期望的属性具有潜在关系,本文最终选择效果最好的扩展连接性指纹[23](Extended-Connectivity Fingerprints,ECFP)。
基于深度学习的甜味剂分类流程如图3所示,除了区分有相同受体原理的甜味和苦味化合物,主要包括数据集的获取与汇编、模型的建立与训练、模型性能评价和甜味剂的分类。模型还增加了无味和甜味强度的分类,不仅仅是筛选出潜在甜味分子根据甜度强弱进行分类,还对筛选出的非甜味类物质通过相同的理论依据分类为苦味和无味。
1.3 数据汇编和整理
为解决以往文献中甜味化合物的相对甜味数值有较大出入的问题,购买了20种市面上的甜味剂用甜度计进行相对甜度的测定,并参照GB/T 2760-2014《食品添加剂使用标准》的要求以5%蔗糖溶液为标准甜度值。相对甜度较大的测定结果波动较大,以等甜度质量浓度(Mass Concentration of Same Sweetness, MCSS)为参考测定不同甜味化合物的相对甜度值(Relative Sweetness, RS)进行分类(表1)。
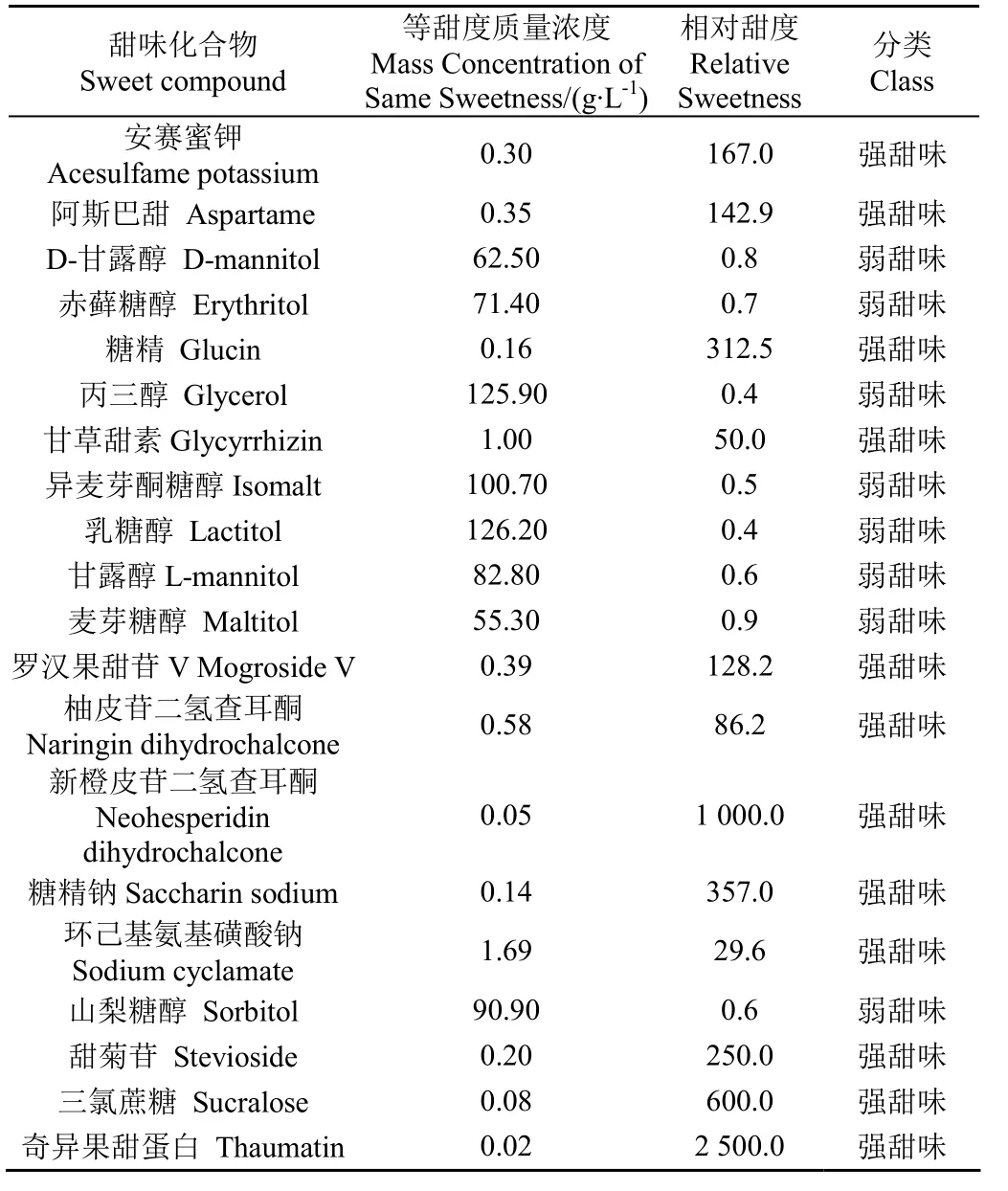
表1 不同甜类化合物的相对甜值Table 1 Relative sweetness value of different sweet compounds
除了试验测量的甜味剂,独立测试集中共包含 114种强甜度分子和 118种弱甜度分子,从其他文献中收集169种无味分子和115种苦味分子作为独立测试集中的无味和苦味分类[24-25],共 516种化合物。训练和验证模型的数据集是基于以下公共数据库的:FooDB(https://www.foodb.ca)和 SuperSweet[26]作为数据集中甜味分类来源,BitterDB[27]和Super Natural II数据库[28]作为苦味和无味分类来源。
1.4 数据预处理
考虑到分子结构的复杂性和可变性以及生成二维数据的不一致性,本文扩增了数据集,以提升化合物的多样性。之前的研究只选取目前使用的甜味剂或试验室测定数据作为数据集,导致数据集偏小,因此本文整合了公共数据库和相关文献的甜味、苦味以及部分无味化合物,最终数据集包含了20 029种化合物,同时将所有数据集图片调整成 224×224(像素)大小(图4)。数据预处理可以实现准确和稳定的分类[29],因此对25%的随机数据进行随机亮度变换,对25%的随机数据进行旋转处理(角度为随机的90°、180°和270°),对25%的随机数据进行水平翻转或垂直翻转处理。亮度变化范围一般从减少 50%到增强50%[30],因此本文使用了随机比例系数k(0.75~1.50)。处理好的数据读取后通过深度学习框架 Pytorch的Normalize函数进行归一化操作,随机抽取70%作为训练集来训练模型,30%作为验证集对模型的分类效果进行验证。
2 基于深度学习的甜味剂分类模型
2.1 网络框架
本文在基于大数据集的情况下采用机器学习方法去分类化合物时效果不好,认为输入特征大大影响使用机器学习方法模型的准确性,深度学习具有自动提取特征和选择最佳特征的独特特点,根据反向传播算法更新参数,有效避免了正确选择这些特征需要大量领域知识与经验的问题。密集连接卷积网络(Densely Connected Convolutional Networks,DenseNet)作为基于深度学习的一种网络,除了具有上述优点,它还以省参数、省计算、抗过拟合以及强大的泛化性能著称[31]。
DenseNet是在残差网络(Residual Network,ResNet)的基础上改进得来的,通过建立前层与后层之间的密集连接训练出更深的卷积神经网络(Convolutional Neural Network,CNN)。密集块(Dense Block)作为DenseNet的基本模块,是密集连接机制的核心。DenseNet由密集块和过渡模块(Transition)组成,密集块中后一层是由前面所有的层在通道维度上连接得来的,并作为下一层的输入,第l层可表示为
式中x0,x1,… ,xl表示每一层的特征图,Hl(·)表示非线性转化函数,代表一个组合操作,包括批归一化(Batch Normalization,BN)、ReLU 函数激活、卷积(Convolution,Conv)和池化(Pooling)操作,DenseNet采用的是BN+ReLU+ 1×1 Conv和BN+ReLU+3x3 Conv组合操作。
2.2 注意力机制
在本文的试验中,DenseNet的正确率并没有达到预期,因此需要选择性地提取信息特征,忽视不太有用的特征。卷积块注意模块(Convolutional Block Attention Module,CBAM)是一种结合了通道和空间的注意力机制模块,使不符合注意力模型的内容弱化或者遗忘,可以使得神经网络具备专注于选择特定的输入[32]。
CBAM分为2部分,第一部分是通道注意力机制模块。一个特征图经过一系列卷积池化得到的特征图,通常认为这个得到的特征图每个通道都是同样重要的,但实际每个通道的重要程度还不一样的,每个通道应该有一个重要性权值来控制该通道的重要程度。具体操作为将输入的特征图先分别全局最大池化和平均池化,输入到 2个神经元数量不一样的全连接层中,以增加拟合通道间复杂的相关性,具有更多的非线性,减少了参数量和计算量,然后2个输出相加进入下一个Sigmoid层,得到每个通道的重要性权值,再将原特征图的每个通道原来的值乘上该权值。第二部分是空间注意力机制模块,考虑了同一通道不同位置像素的重要性。该模块先将前一部分的输出特征图进行基于通道方向的全局最大池化和平均池化,形成的特征图用 7×7的卷积核进行卷积,得到一个新的特征图,经过激活函数sigmoid再与原特征图相乘:
式中F为原特征图,Mc(F)为原特征图经过通道注意力机制得到的新特征图,MS(Mc(F))为经过空间注意力机制最终得到的特征图,f7×7为卷积操作,多次试验后确定卷积核大小为 7×7,MLP是多层感知器,除了输入输出层,它中间可以有多个隐层,为了减少参数一般选2层,σ代表Sigmoid激活函数。
2.3 分类模型
分类模型的结构如图5所示。本文将卷积块注意模块插入每个密集块后面,与原先的过渡层形成一个新层。首先,输入的224×224×3图片通过7×7的卷积层后,由密集块进行组合操作和 concat操作,特征图的通道数量增加。得到的特征图通过应用的通道和空间注意力模块逐元素求和合并输出特征向量,随后进入过渡层。过渡层由1×1的卷积层和2×2的平均池化层组成的,即下采样,它的作用是压缩模型。最后一个密集块的输出进行7×7的全局平均池化后再进行全连接操作得到的矩阵和扩展连接性指纹矩阵通过卷积进行特征融合,随后建立2个神经元数量不同的全接连层,第一个全连接层将特征维度降低到输入的一半,第二个全连接层增维回到了原来的特征维度,降维可以更简单地计算权重部分,也具有更多的非线性,最终通过 Softmax分类器输出分类结果。试验模型的batch size设置为64,初始学习率设置为0.005,每7个周期衰减0.1倍。
通过注意力机制和特征融合的作用,使模型尽可能保留重要参数,达到更好的学习效果。采用精度Presision、灵敏度Sensitivity和F1分数来评价模型性能:
式中 TP,FP,FN分别代表被正确分类的正例、错误分类的反例和错误分类的正例。
3 结果与分析
大多数基于深度学习方法的模型都需要进行改进才能得到良好的结果,本文在试验中对前人提出的机器学习方法模型进行了评估,发现大多数机器学习方法不再适用,例如经常用来分类的SVM对化合物的分类仅达到了0.47的平均精度,只适用于小批量样本的任务,不能适应大数据的任务,KNN则达到了0.55的平均精度,只有RF较高达到了0.75的平均精度,但远不如它们在小数据集情况下的性能。表2中选取了试验效果较好的深度学习网络模型 VGG16、ResNet50和DenseNet与改进后的模型作对比,可以看出改进后的模型每一类的分类精度均能达到 0.91。由于没有加注意力机制的网络损失(由损失函数得出)波动较大,取最后 20个训练周期的平均算出每一类的精度、灵敏度和F1分数。图6可以看出,本文的模型各项指标均远优于目前常用的卷积神经网络模型,准确率稳定在0.934左右,损失稳定在0.017左右,准确率的波动幅度小于0.005,损失值的波动幅度小于0.001,没有过拟合的现象存在,而验证集准确率曲线和训练集准确率曲线的结果相差较大是由于扩充的数据集中含有疑难分类的化合物,如最常见的甜味剂糖精就有苦味和金属味的后调。通过模型新发现的甜味化合物可以进一步试验测定。
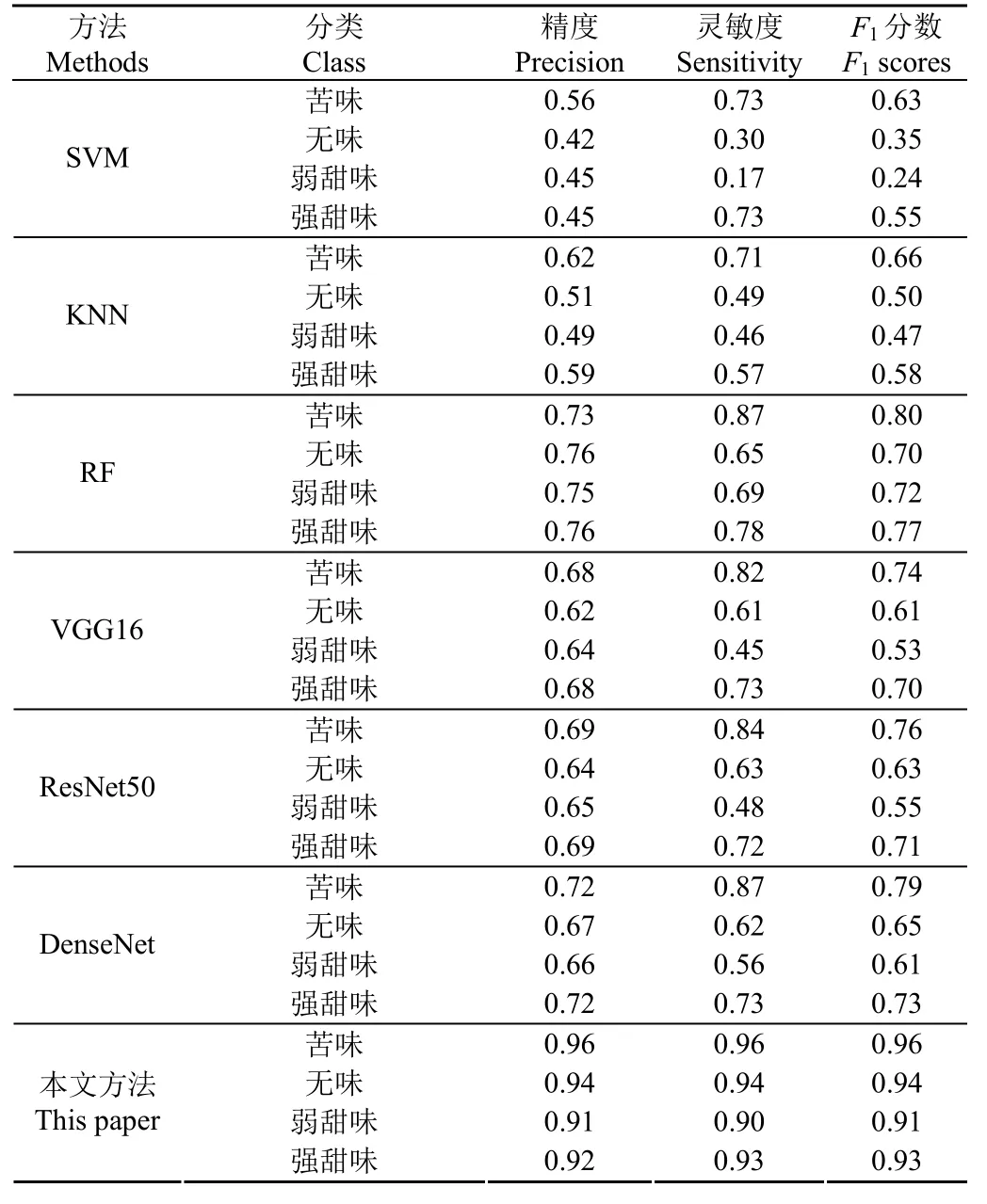
表2 不同方法的模型性能比较Table 2 Comparison of model performance of different methods
本文模型的混淆矩阵如图7a所示。可以看出苦味分类效果较好,这是由于单独区分苦味相对于区分甜度强弱的化合物来说简单的多。模型可以保存,也可以只保存参数,之后的使用只需要载入训练好的模型,随后传入需要筛选的分子图片以及该分子的扩展连接性指纹,模型即可预测并分类,方便研究人员从大量分子库中筛选感兴趣的分子。本文模拟了一个实际的独立测试集,并在训练好的模型上进行分类并测评,混淆矩阵(图7b)显示,苦味分子被正确分类的程度最高,甜度强弱方面的分类还不够完美。相比较前人的二分类,模型增加到了四分类,且各项指标较优,总体还是获得了很高的精度。
通过模型新发现的甜味分子可以使用虚拟筛选技术或生物试验进一步检验,以方便相关人员寻找理想的低热量甚至是无热量的甜味剂,该方法省去了大量建模的任务,可以显著减少开发甜味剂所需的时间和资金。
4 结 论
甜味剂的开发是一个漫长的过程,本文提出了一种可以筛选潜在甜味剂或苦味剂的深度学习模型,得出以下结论:
1)传统机器学习方法在前人对甜味剂的二分类中是有效的,但对大量未知分子的分类效果不尽人意,与机器学习不同,深度学习能够学习丰富的特征,根据反向传播算法更新参数,找到影响化合物甜味的关键结构,因此本文选取了深度学习模型并对其网络结构进行改进。
2)忽略某些特定的三维结构在理论上难以与真实甜味的感觉强度契合,因此有必要使用特征融合的方法弥补预测方法的不足。
3)注意力机制和余弦退火的改进大大提高了模型的性能。结果表明该模型每一类的分类精度均达到 0.91,可以解决筛选分子时构建三维模型的困难、没办法处理海量数据、预测模型有特异性和局限性等问题,在大数据集上能准确地分类以节省昂贵的试验。因此,对于分子研究和行业中的甜味剂开发来说,本文模型是一种新型的有效方法,为相关人员合理设计和筛选甜味分子提供了一个有用的工具。
猜你喜欢
学苑创造·A版(2021年10期)2021-10-30 10:34:43
科教新报(2020年40期)2020-12-03 05:56:56
作文评点报·作文素材小学版(2017年28期)2017-08-22 17:35:37
科学大众(中学)(2016年10期)2016-12-29 18:08:36
科学种养(2016年6期)2016-06-21 10:40:15
少年科学(2015年10期)2015-10-31 04:19:47
女友·花园(2015年4期)2015-05-30 21:25:47
江苏调味副食品(2015年1期)2015-02-28 01:56:34
天然产物研究与开发(2014年8期)2014-04-27 14:16:23
中国质量与标准导报(2014年6期)2014-02-28 22:24:10
