
基于域适应学习的非侵入式负荷分解问题研究
2021-09-03 14:15苏海军侯坤福高敬更王治国
甘肃科技 2021年14期
苏海军,侯坤福,高敬更,王 琨,王治国
(1.国网甘肃省电力公司营销服务中心,甘肃 兰州 730300 ;2.兰州理工大学电气工程与信息工程学院,甘肃 兰州 730050)
1 概述
非侵入式负荷分解(Nonintrusive Load Monitoring,NILM) 是指通过安装智能电表获得居民一段时间内的总用电信息,然后在算法层面推算出该用户各用电器的用电情况[1],通常获得的设备用电信息用于用户制定较为经济的用电计划[2]以及电力服务商需求侧精细化管理配置[3]。
现有的非侵入式负荷分解问题研究集中于负荷分解精度的提高,代表性的研究包括利用隐马尔可夫模型、深度学习的方式进行非侵入式负荷分解。其中因子隐马尔可夫模型[4]在一定程度上改善了负荷分解精度,但较为复杂的用电情况下,模型的分解精度会下降。此外,伴随着人工智能发展的浪潮,利用深度神经网络进行负荷分解的方式也逐渐被研究者重视起来,此类方法的优势在于不需要进行其他方法所必须要完成的特征提取工作,同时这类方法也表现出了较好的效果,代表的研究如2014 年Jack 所提出的利用循环神经网络和降噪自编码器的seq2seq 方法[5]以及2018 年Zhong 所提出的基于卷积神经网络的seq2point 方法[6],都表现出了良好的负荷分解效果。
基于神经网络的负荷分解方法需要大量的先验数据对网络进行训练,通过大量先验数据训练的模型往往只能在某地区某家庭某种设备上表现出良好的效果,一旦将训练好的模型用于非训练数据下的设备时,模型的负荷分解精度迅速下降,极大的影响着非侵入式技术的大规模部署。因此如何提高模型的泛化能力,以此期望对任意家庭设备进行负荷分解达到最佳效果,是亟待解决的一个重要问题。
本文针对非侵入式负荷分解提出一种域适应学习神经网络模型(Domain Adaptation Neural Network,DANN)。与以往的普通神经网络模型不同,该模型将混合基准家庭数据(源域,有标签)和目标家庭数据(目标域,无标签)进行网络训练,极大的改善了模型的泛化能力,在目标域家庭中取得了较好的分解效果。同时在实验中进行了论证,对于运行特征较为简单的设备有着较高的分解精度,对于较为复杂的运行特征的设备,本文所提方法也表现出了较大的研究潜力。
2 非侵入式负荷分解问题
负荷分解的任务是利用入户智能电表信息恢复单个设备的功率信息。通常情况下,通过智能电表可以获得用户一段时间内总的用电信息,如有功功率,视在功率。设住户某段时间T 内的用电功率信息为:
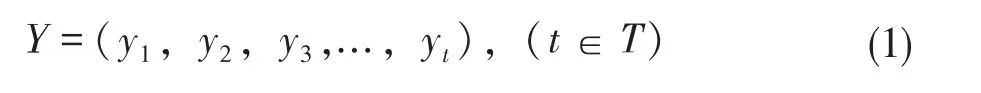
n 种用电设备,单个设备用电信息为:
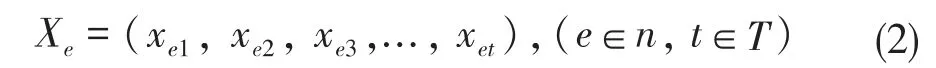
非侵入式负荷分解方法在算法层面构建分解模型,从主表功率序列Y 中恢复出用电设备功率序列Xe,目前该问题主要的研究集中于提高负荷分解的精度,本文将在前人的研究基础上重点关注模型的泛化性能研究。
2.1 跨地区设备负荷分解问题
目前各类国家之间关于非侵入式负荷分解问题的研究进度并不一致,关于数据集的制作,国外已经领先国内许多,国内还没有一个用于非侵入式负荷分解任务的标准数据集,所以存在跨地区的非侵入式负荷分解任务需求,但随着国内研究的推进,针对我国的居民用户用电行为研究加速,必然会发布用于我国本地的非侵入式负荷分解数据集,针对跨地域的设备负荷分解存在一定的实际意义。
2.2 跨用户及跨设备间负荷分解问题
相较于跨地区间的负荷分解任务而言,同地区不同家庭之间的同种设备或者不同设备的负荷分解任务更具有实际意义,首先,目前已经存在一定数量的用于非侵入式负荷分解任务的数据集,存在的实际问题是,利用同一个家庭的不同时间段设备运行作为训练数据和测试数据,以此在同一用户家庭中完成负荷分解,可以取得较高的负荷分解精度,但是一旦利用A 家庭的训练数据对模型展开训练,利用B 家庭去验证,负荷分解精度会立马大幅下降,模型的泛化性能备受考验,然而在未来实际应用当中,数据集一旦定制完成,将会是一个标准的用户用电数据,但是数据集所包含的用户毕竟是有限的,居民的用电行为及家用电器型号却是千差万别,利用标准数据集训练得到的模型不能完全匹配每个家庭的用电特征。
因此,本文提出模型域自适应学习,对于每一个家庭都会在基准的负荷分解模型上做一定量的域自适应训练,这样就可以利用标准数据集展开个性化的模型训练,以少量的数据集训练各类用户负荷分解模型,以此提高模型的泛化能力,助力非侵入式负荷分解的实际推广。
3 域适应学习
3.1 DANN 网络概述
深度学习的模型训练往往需要大量的带标签数据,这类训练所得模型在指定任务中能够取得较好的成绩,但是更多任务是无标签数据的,或者说大量的标签工作需要繁杂的标定工作,这极大的阻碍着该研究领域的发展[7]。
近年来,出现了一种新的深度学习模式:迁移学习。迁移学习是运用已存有的知识对不同但相关领域问题进行求解的一种新的机器学习方法。它放宽了传统机器学习中的两个基本假设:用于学习的训练样本与新的测试样本满足独立同分布的条件;必须有足够可利用的训练样本才能学习得到一个好的分类模型。而最终的目的则是迁移已有的知识来解决目标领域中仅有少量标签样本数据甚至没有标签的学习问题[8]。目前迁移学习的研究已经在文本分类[9]、情感分类[10]、图像分类[11]等相关领域展开。
域适应(Domain Adaption)是迁移学习中一个重要的分支,目的是把具有不同分布的源域(Source Domain)和目标域(Target Domain)中的数据,映射到同一个特征空间,寻找某一种度量准则,使其在这个空间上的“距离”尽可能近。然后,在源域(带标签)上训练好的分类器或者预测器,可以直接用于目标域数据的分类或预测。
本文利用域自适应学习,迁移数据集中已训练好的模型,用于未知数据标签的设备负荷分解。数据来源仍然是公开的数据集,在处理时,将一部分数据处理为有标签数据,一部分数据被处理为无标签数据,根据不同任务要求完成数据构造。图1 展示利用DANN 网络的非侵入式负荷分解过程。

图1 基于DANN 域适应学习的非侵入式负荷分解流程图
3.2 域适应学习原理
假设存在两个分布S(x,y)和T(x,y),将其称为源分布和目标分布,其中源分布数据有完整的数据标签,目标分布无数据标签,两种分布都是复杂且未知的,这两种分布相似却又存在差别,如何求同存异,利用源分布数据帮助目标分布数据展开任务(分类、预测)?
域适应学习或是一种解决方案,Yaroslav Ganin在其关于域适应学习的论文中指出:高性能的深度架构接受了大量标记数据的培训,在没有针对某项任务的标记数据的情况下,如果使用性质相似但来自不同域的标记数据(例如合成图像),则域自适应通常会提供一个有吸引力的选择[12]。该方法可以在源域中的大量标记数据和目标域中的大量未标记数据上进行训练(不需要标记的目标域数据)。随着训练的进行,该方法促进了“深度”功能的出现,这些特征区分源域上的主要学习任务,并且在目标域实现了自适应。
在域适应网络训练期间,可以访问大量来自源域和目标域的训练样本{x1,x2,x3,...,xn},其中源域数据带有标签{y1,y2,y3,...,yn},目标域不带有标签。对于第i 个示例,用di表示域标签,该二进制变量指示xi属于源域分布还是目标域分布,如果di=0,则xi~S(x),如果di=1,则xi~T(x)。对于源分布中di=0 的示例,在训练时已知相应的标签yi∈Y。对于目标域中的示例,在训练时不知道标签,且希望在测试时预测这些标签。
针对这种任务,定义一种深度前馈架构,该架构针对每个输入xi预测其标签yi和其域标签di∈{0,1}。将这种映射分解为三个部分,输入x 首先通过映射Gf(特征提取器)映射到D 维特征向量f∈RD,将所有层的参数向量表示为θf,即f=Gf(x;θf)。然后,特征向量f 通过映射Gf(标签预测变量)映射到标签y,用θy表示该预测器的参数。最后,相同的特征向量f 通过带有系数的θd映射Gd(域分类器)映射到域标签d。
在学习阶段,训练目标是使训练集(即源分布部分)上的标签预测损失最小化,因此,特征提取器和标签预测器的参数都得到了优化,以使损失最小化用于源域样本。这确保了特征的可辨别性以及特征提取器和标签预测器在源域上的组合的总体良好预测性能。另一方面,要使训练所得的特征是域不变的,则分布S(f)={Gf(x;θf)│x~S(x)}T(f)={Gf(x;θf)│x~T(x)}相似。
要使训练所得的特征是域不变的,假定学习的效果够好,则域分类将会无法判别数据来源,换个说法就是此时的域分类损失函数会比较大,因此,为了获得域不变特征,寻找特征映射的参数,该参数映射使域分类器的损失最大化,寻找域分类器的参数θd,在训练过程中,使域分类的尽可能无法区分开源域数据与目标域数据,所以它的梯度更新方向应当向域分类损失增大的方向更新。整个特征层的参数更新由两部分的损失函数决定,在不断的迭代训练过程中,一方面需要将预测器损失不断减小,一方面需要将域分类器损失向增大的方向更新,这种对抗性的训练促进了域不变特征的出现。
3.3 DANN 网络结构
DANN 网络(Domain Adaption Nerual Network)分为3 个模块,特征提取器,分类器或者预测器(根据不同任务而定)和域分类器。
特征提取器(feature extractor)用来将数据映射到特定的特征空间,供标签预测器和域判别器做进一步的数据处理。
标签预测器(label predictor)对来自源域的数据进行预测,尽可能预测出正确的标签。
域判别器(domain classifier)对特征空间的数据进行分类,尽可能分出数据来自哪个域。
其中,特征提取器和标签分类器构成了一个前馈神经网络。在特征提取器后面,加上一个域判别器,中间通过一个梯度反转层(Gradient reversal layer,GRL)连接,该层用于特征提取网络与域分类网络之间,反向传播过程中实现梯度取反。在训练的过程中,对来自源域的带标签数据,网络不断最小化标签预测器的损失(loss)。对来自源域和目标域的全部数据,网络不断最大化域判别器的损失。
非侵入式负荷分解任务在于学习主表数据与设备数据之间的映射关系,本文中采用序列到点的映射学习模式,5 层卷积层作为特征提取器,两层全连接层作为预测器,两层全连接层作为域分类器,网络选择Adam 优化器进行梯度更新,学习率0.001,在预测器中添加了Dropout 层[13]用于防止过拟合,具体网络结构图如图2 所示。

图2 DANN 域适应网络结构图
3.4 DANN 神经网络训练
从域适应网络的参数更新来看:定义整个网络目标损失函数为:

其中θf是特征提取层需要训练的网络参数,θy,θd是预测器和域分类器的所要训练的参数,整个、网络的损失函数分为两部分,前面部分为预测器损失Ly,也就是域标签di=0 时,数据为源域数据时的预测损失函数;后面部分为域分类器损失函数。
计算整个网络的前向传播过程完成后,接着进行网络的参λ 数更新,利用梯度下降法进行网络参数更新,由于这种对抗训练需要将域分类损失最大,故而整体利用梯度下降方法训练时,需要将域分类器损失取反。
利用优化器进行反向传播,训练过程参数的更新过程如下:

式中因子λ的大小决定了域分类器所能影响到特征提取器的参数更新的范围,μ 是学习率。图3 详细展示了DANN 神经网络的训练流程。
防治措施以药剂防治为主。对于炭疽病、斑点落叶病、锈病等真菌性病害,可用43%戊唑醇5 000倍液,或者其他三唑类药剂,或者用25%吡唑醚菌酯2 500~3 000倍液等甲氧基丙烯酸类药剂进行防治;对于绿盲蝽、桃小食心虫等,可用2.5%高效氯氟氰菊酯1 000~1 500倍液、2%甲维盐12 000倍液等进行防治;对于红蜘蛛、螨类等,可用20%螺螨酯2 500倍液等进行防治。

图3 DANN 神经网络算法流程图
(1)设定DANN 神经网络参数,训练轮次50,预测器及域分类器损失函数定义,分别为均方误差损失函数、负对数似然函数损失函数,训练数据批量大小:256,Adam 优化器学习率:0.001 等参数;
(2)加载已处理完成的源域训练数据(带预测标签),目标域数据(不带预测标签标签),定义域标签,源域数据标签为0,目标域数据标签为1;
(3)将源域与目标域数据训练数据送入卷积层特征提取器;
(4)将提取到的特征数据送入由全连接神经网络构成的预测器,计算预测损失函数;
(5)将提取到的特征数据送入梯度反转层,进行梯度反转;
(6)将梯度反转后的特征数据送入由全连接神经网络的构成的域判别器,计算源域域目标域域分类损失函数;
(7)损失函数求和,用于统一利用梯度下降法更新参数;
(9)判断迭代次数是否达到设定值,未达到转至步骤2)继续迭代训练,达到则训练结束。
4 数据处理
4.1 数据集
数据集采用UKERC 能源数据中心2015 年公开发布的UKdale 数据集[14]。
Ukdale 数据集记录了从2012 年11 月到2015年1 月份的5 个家庭的用电数据,每6 秒钟采集一次用电数据。数据集包含10 多种类型的电器的测量值。本文中,仅关注冰箱,洗衣机,这类电器均具有较为明显的运行特征,如冰箱的运行特征具有周期运行的特点,洗衣机的工作模式更为丰富,相比冰箱运行特征更为复杂。
4.2 数据预处理
数据预处理分为实验数据提取,处理异常值,划分实验数据。通过nilmtk工具包将原始数据转化为可用于科学计算的数据格式。同时,设置相应的实验数据时间段并进行重新采样,部分时间段存在数据缺失,会被直接删除。利用滑动窗口方法扩充数据,滑动窗口在给定的样本数据上进行步长为1的滑动,可以获得大量主表功率序列及对应设备运行值,最后采用零均值归一化方法归一化数据以便于神经网络训练。
在制作训练数据集时,将源域数据和目标域数据数据同时送入网络训练,预测器根据传入的源域数据计算预测损失,域分类器根据源域数据和目标域数据计算域分类损失,然后进行梯度更新,完成网络训练。
5 算例分析
5.1 实验环境
本文硬件环境为Intel(R)CoreTM i7-7700 CPU@3.6GHz,16G DDR4 内存及GeForce GTX 1070(8GB 显存)的64 位计算机。软件平台为WINDOWS-10 专业版操作系统,Python 3.6.2(64 位)及Pytorch 深度学习框架。在训练深度学习模型时使用GPU 进行硬件加速。
5.2 实验设计
本次所提网络主要针对非侵入式负荷分解模型泛化能力的提升展开研究,因此,会对模型的泛化能力做全面的比较,测试从2 个角度展开:
(1)UKdale 数据集同一家庭中的不同设备之间的分解精度对比;
(2)UKdale 数据集不同家庭之间的同一设备之间的分解精度对比。
其中:(1)代表的可能实际应用情况是某家庭新购置一种家电,利用家庭中已有设备分解模型对其进行负荷分解;(2)代表的是在某一地区下,存在标准分解模型,由于家庭之间的设备及用电行为差异,导致模型分解能力波动,也是最具有研究意义的一点。此外,在一定程度上跨地域设备负荷分解与跨家庭设备负荷分解属于同一类问题,均属于不同家庭之间的设备负荷分解问题,考量到问题的同质性及文章篇幅限制,本文测试了Ukdale 数据间的不同家庭同种设备的负荷分解效果,不再展开跨地域设备负荷分解。表1 所示为算例分析测试跨家庭负荷分解所用数据配置情况,表中“S”代表源域数据,“T”代表目标域数据,“H”代表家庭。

表1 数据分配表
由于不存在同类型域自适应研究方法和非侵入式负荷分解模型泛化能力的研究,故本次实验的对比,将在采用DANN 方法与其他仅对源域数据进行训练的模型中展开对比,分别为文献[5]所提DAE与LSTM 方法和文献[6]所提基于CNN 的Seq2point方法,以及组合优化法、FHMM 方法[15],所用对比算法的具体实现参考文献[15]。
5.3 评价指标
评价指标采用MAE,F1score。MAE 可以验证所提方法得出的分解预测值跟实际设备运行值的差距,F1score 更加侧重于评价设备运行状态(设备开启或关闭)而不是设备实际运行的功率值大小,分数越高代表性能越好。计算公式如(7)(8)所示。

其中PRE 与REC 的计算方式如(9)(10)所示,PRE 为准确率,REC 为召回率。TP 表示负荷在真实数据中打开而在预测中也是打开时的总数;FP 表示负荷在真实数据中关闭而在预测中打开时的总数;TN 表示负荷在真实数据中关闭而在预测中也是关闭时的总数;FN 表示负荷在真实数据中打开而在预测中关闭时的总数。
5.4 设备分解结果对比
5.4.1 跨家庭设备负荷分解结果对比
对比冰箱实验结果图4、图5,冰箱的运行特点较为简单,各类算法对于冰箱的功率变换时刻有着较好的预测效果,而其他5 种方法仅仅能够预测设备的启停状态,对设备的运行功率值预测较差,评价指标见表2。
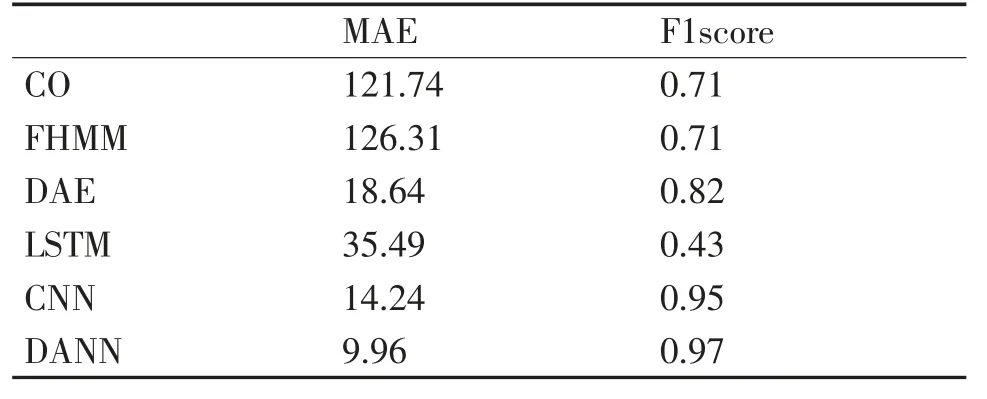
表2 冰箱跨家庭实验评价指标对比

图4 CNN 冰箱跨家庭实验结果

图5 DANN 冰箱跨家庭实验结果
对比洗衣机实验结果图6、图7,洗衣机作为一种工作方式复杂的设备,在5 种对比方法中,卷积神经网络类方法仅预测了一个功率波动时刻,反观本文所提方法,精准的预测了3 个设备运行功率有较大波动的时刻,对于设备功率值也相对更为接近,对于各类细节把握也比上述方法更为精准,如在小功率运行时刻,较为精细的预测了洗衣机运行的功率值,其他方法预测的结果较为粗糙,同时也不存在较大的误判情况,评价指标对比见表3。

表3 洗衣机跨家庭负荷分解评价指标对比
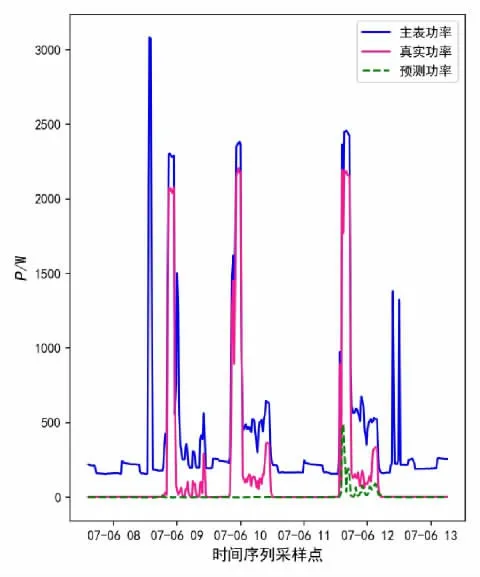
图6 CNN 洗衣机跨家庭负荷分解结果
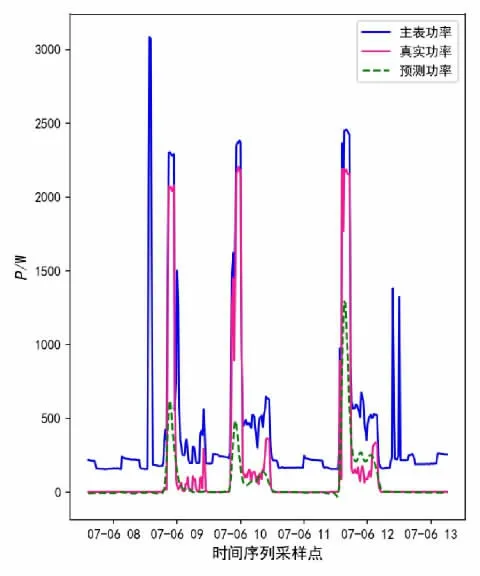
图7 DANN 洗衣机跨家庭负荷分解结果
5.4.2 跨设备负荷分解结果对比
图8 展示了源域水壶与目标域微波炉的负荷分解结果,表4 为评价指标对比。分别利用运行特点最为复杂的洗衣机和利用运行特点最为简单的水壶作为源域数据对网络进行训练,其他用电设备作为目标域数据,发现所有利用洗衣机作为源域数据进行训练的方法来分解其他设备负荷时效果非常差,相反利用水壶作为源域数据时,所有方法对设备的启停能够较好预测,但对于功率值的预测不是很准确;同时发现,利用水壶作为训练数据时,能够较好的完成微波炉的负荷分解效果,其中RNN方法效果最好,本文所提方法表现较好。该跨设备测试效果较好的可能原因是两者工作运行的模式比较接近,都是短时运行大功率与性能,功率值两者也比较接近。如何利用RNN 作为特征提取器,实现域适应学习,改善跨设备负荷分解效果,这也将是接下来的研究重点。

表4 微波炉跨家庭实验评价指标对比

图8 DANN 微波炉跨设备实验结果
6 结语
本文将迁移学习中的域适应学习方法引入非侵入式负荷分解问题,用以解决目前模型普遍存在的泛化能力不足问题以及适应未来无标签任务的需求,提出一种域适应负荷分解模型,该方法利用源域数据和目标域数据共同训练网络,使得特征提取网络所获得的的特征更具有代表性,考虑到不同家庭之间的用电行为差异,用于非侵入式负荷分解模型的网路必须拥有更好的网络泛化能力,所提方法从多个角度出发设计了验证试验。综合考量本文所提方法的性能,其在跨家庭同种设备负荷分解任务中,对于简单运行特征的设备,本文所提方法相较于其他未利用源域与目标域数据混合训练的方法而言,有着对设备运行功率值负荷分解精度较高的优势;对于有着复杂运行特点的设备,本文所提方法更能获取源域与目标域数据的共同特征。所以在不同家庭之间同种设备的负荷分解精度相较于其他未利用目标域数据的方法而言,对于设备的运行特征(开启或关闭)把握的更好,对于设备运行功率值的预测有一定的提升。
猜你喜欢
河北大学学报(自然科学版)(2022年3期)2022-06-16
计算机工程与科学(2021年2期)2021-03-01
计算机技术与发展(2020年11期)2020-12-04
辽宁工业大学学报(自然科学版)(2020年1期)2020-01-07
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
电子与信息学报(2015年12期)2015-08-17
中国惯性技术学报(2014年4期)2014-10-21
电测与仪表(2014年15期)2014-04-04
测绘科学与工程(2013年2期)2013-03-11
