
一种改进型TAGE分支预测器的实现
2020-01-07 01:09:48李正平
辽宁工业大学学报(自然科学版) 2020年1期
李正平,高 杨
一种改进型TAGE分支预测器的实现
李正平,高 杨
(安徽大学 电子信息工程学院,安徽 合肥 230031)
针对传统的TAGE分支预测器存在分支别名冲突以及对与历史不相关的分支预测准确率较低两个问题,提出了基于PC特征提取和提升基础预测表优先级的方式对预测器进行改进。将传统的TAGE分支预测器与本文改进的预测器共同使用SPEC2000的测试程序进行验证。实验结果表明,改进之后的分支预测器能够有效地解决这两个问题,预测准确率有着明显的提升。
分支预测;处理器性能;特征提取;卷积核
现代处理器大都采用超流水、超标量的设计结构,分支预测技术是两者的关键支撑技术[1]。为了提升处理器的主频,设计者不得不增加流水线的级数,细化处理器的工作。然而,随着流水线的级数增加,如果分支预测失败使得清空流水线的代价就会越大[2]。处理器超标量的设计使得指令并行性执行成为了可能,极大地提高了处理器的性能。研究表明,在一般程序中平均8~10条汇编指令就有一条转移指令,也就是说在8发射结构当中每一拍都会出现1条分支指令。如果没有分支预测,处理器每取一次指令,就会阻塞,直到分支指令执行完毕。多发射结构越复杂,阻塞的周期就会越长,导致处理器的性能降低。因此,分支预测技术对于减少清空流水线代价,挖掘处理器多发射结构的潜在能力,进而提升处理器性能发挥着至关重要的作用。
TAGE分支预测器和之前的预测器相比做了很大的改进,之前的预测器将所有的分支共同使用同一个表进行预测[3]。TAGE分支预测器将分支分成两类,与历史相关的分支和与历史不相关的分支,分别使用基础预测表和标记预测表进行预测,这使得分支预测准确率有着显著的提高。
近些年来,人们对TAGE分支预测器进行不断的改进。改进的角度主要从预测准确率、面积、功耗3个方向出发。文献[4]通过对历史寄存器位进行排列,降低了索引值和标记值的运算次数,节省了硬件资源,功耗和面积分别降低了90%和85%。文献[5]使用单端口存储器组件减少预测器的访问次数,在文献[4]的基础上进一步降低功耗。关于提升分支预测器的准确率,人们大都是将TAGE预测器与其他的专用预测器联合使用。例如文献[6]通过将TAGE预测器与循环分支预测器联合使用,文献[7]将TAGE预测器与统计校正预测器联合使用,都取得了很好的效果。文献[8]对历史寄存器进行压缩,使得可以记录更久的历史信息,提高与历史相关分支的预测准确率。
TAGE预测器标记预测表优先级比基础预测表更高,导致与历史不相关的分支预测准确率较低;并且使用程序计数器(PC)的部分位索引预测表,分支别名问题比较突出。针对TAGE分支预测器存在的这两个问题,对分支预测器的结构进行改进,改进之后的方法使得预测器的预测准确率明显提高。
1 传统型TAGE分支预测器
1.1 传统型TAGE分支预测器算法原理
TAGE分支预测器结构图如图1所示。分支预测器共包含5张预测表和1个历史寄存器,分别用T0、T1、T2、T3、T4、h表示。当分支指令进入预测器之后,就会得到5张表的预测结果,然后根据5张表的优先级选取优先级最高的结果值作为本次的最终预测结果。其中,T0称为基础预测表,作用是预测与历史不相关的分支,T1~T4称为标记预测表,作用是预测与历史相关的分支。基础预测表的每一行是由2位饱和计数器组成,如图2(a)所示。当计数器的最高位是1时,预测分支指令发生,当最高位是0时,预测指令不发生。标记预测表的每一行由3个部分组成,分别是标志位(tag)、饱和计数器(ctr)、置信度(u),如图2(b)所示。
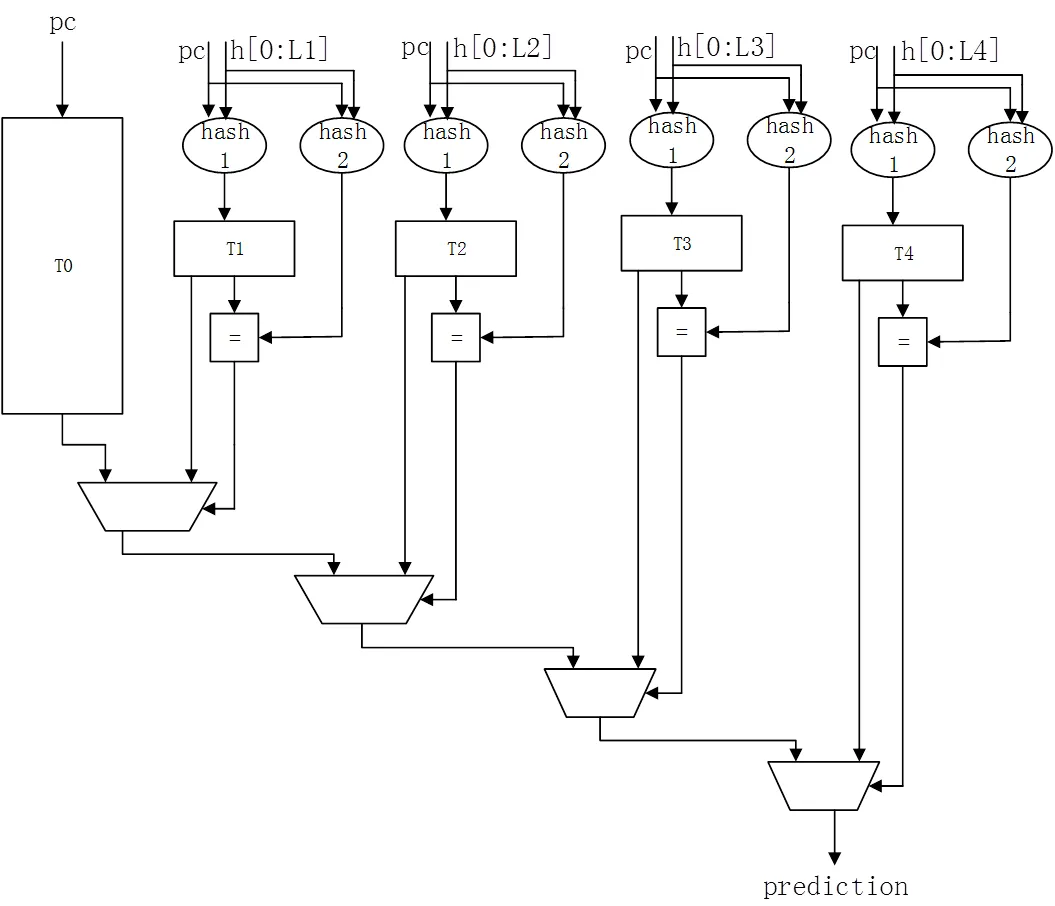
图1 TAGE分支预测器
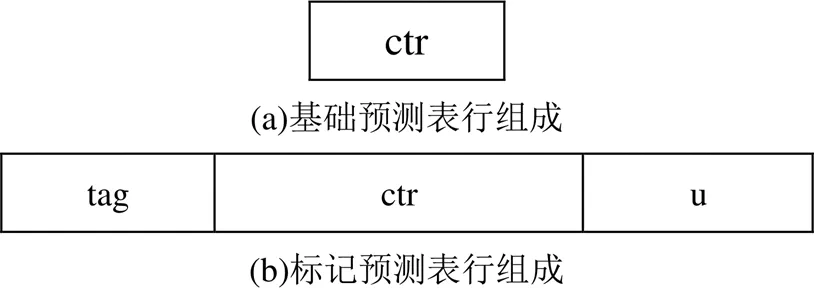
图2 预测表行组成
分支预测步骤:
(1)每一条分支指令对应一个程序计数器值。首先将程序计数器(PC)的部分位索引T0表,得到两位饱和计数器的值。
(2)将历史寄存器h分成4等分。将程序计数器(PC)部分位分别与历史寄存器的1/4长度位宽、2/4长度位宽、3/4长度位宽、4/4长度位宽进行两次不同的哈希计算,得到8个结果值,作为4张表的索引值和标记值。
(3)利用索引值选取T1、T2、T3、T4 4张表对应的行,取出对应行的tag位与步骤(2)标记值进行比较。如果相等,则取出对应行的ctr。否则,忽略该表的预测值。
(4)根据步骤(2)和(3)得到不止一个预测值。预测值优先级次序为T4>T3>T2>T1>T0,根据优先级选出最终的预测值。
1.2 算法缺陷
TAGE分支预测器将历史寄存器进行折叠,能够区分不同历史长度的分支;并且预测器增加了标志位,能够在一定程度上降低分支别名的干扰。但是存在两个较为明显的缺陷:
(1)使用程序计数器(PC)的部分位运算得到预测表的索引值和标记值,这使得不同的分支索引到同一项的概率依然很大,分支别名的问题并没有从根本上得到解决。
(2)基础预测表优先级最低,分支预测器预测的最终值大多来自于标记预测表,这使得对与历史不相关的分支预测准确率不高。
针对第一个缺陷,对程序计数器(PC)进行特征提取,使用特征提取值代替程序计数器(PC)的部分位,这样一来,特征值能够充分反映整个程序计数器(PC)的信息,能够和其他的程序计数器(PC)值区分开来。针对第二个缺陷,可以提升基础预测表的优先级,使得基础预测表与标记预测表有着相同的优先级。
2 改进型TAGE分支预测器
2.1 PC特征提取
本文以64位处理器为例,PC的地址可以使用16个十六进制数表示,将这16个数组成4*4的正方形,如下图3(a)所示。PC的特征提取采用经典的sobel算法使用的两个卷积核。使用Sobel算法[9-11]的两个卷积核可以提取每一个点在水平方向和垂直方向的一阶倒数,然后使用移位的方式将两个方向的倒数合并在一起组成PC的特征值。垂直方向的卷积核如图3(b)所示,水平方向的卷积核如图3(c)所示。
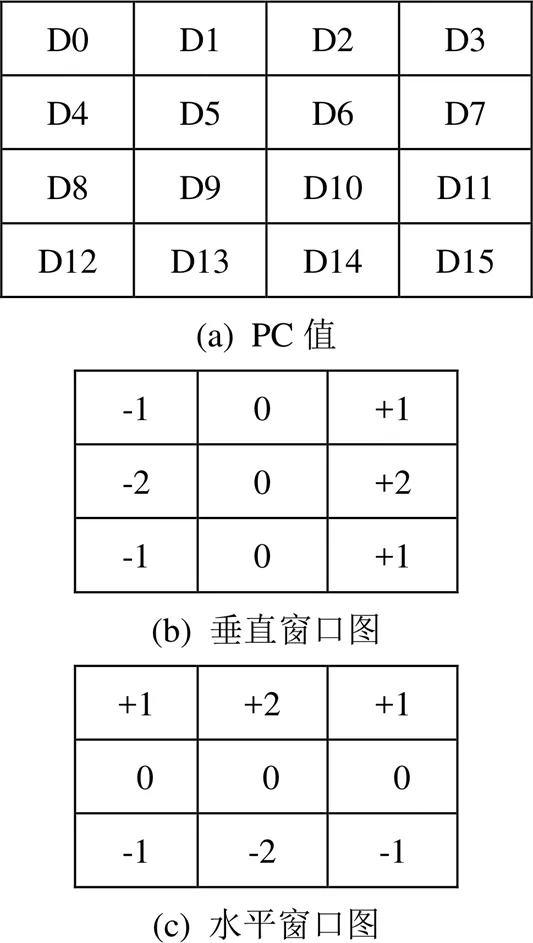
图3 特征提取图
具体的计算步骤:
(1)使用垂直窗口在图1(a)上进行滑动,得到4个值,分别用0、1、2、3表示。这4个值都是4位的二进制。
其中:
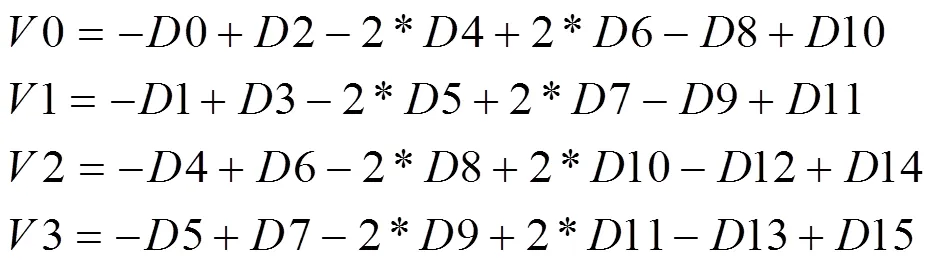
(2)使用水平窗口在图1(a)上进行滑动,得到4个值,分别用0、1、2、3表示。这4个值也是4位的二进制数。
其中:
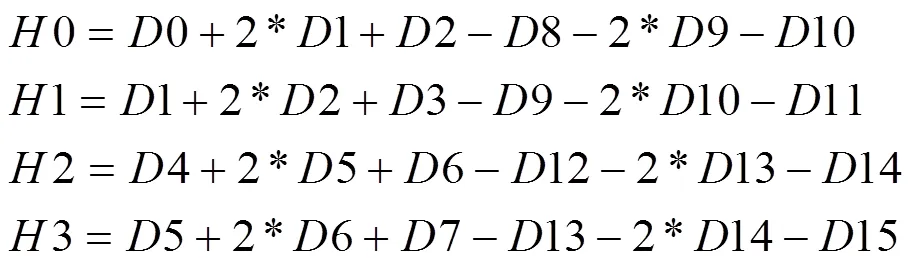
(3)特征提取的最终结果用字母表示,是8位的。其中,的高4位由垂直方向得到的4个值进行异或得到,低4位由水平方向得到的4个值进行异或得到。
2.2 改进型TAGE分支预测器结构
改进型TAGE分支预测器的结构如图4所示。为了解决第一个缺陷,增加了fe模块,该模块的作用是对程序计数器进行特征提取,用特征值参与运算,得到索引值和标记值。为了解决第二个缺陷,将基础预测表每一个行增加3个部分,分别是历史发生统计值(taken cnt),历史不发生统计值(n_taken cnt),置信度(u),如图5所示。其中,历史发生统计值用于计数该分支历史发生的次数,历史不发生统计值用于计数该分支历史不发生的次数,置信度用于统计发生次数的百分比。置信度是一个很重要的因素,它将决定分支预测器的最终预测值是来自于标记预测器还是基础预测器。为了增加基础预测表优先级,需要添加三态门,用于筛选标记预测表T1的预测值。
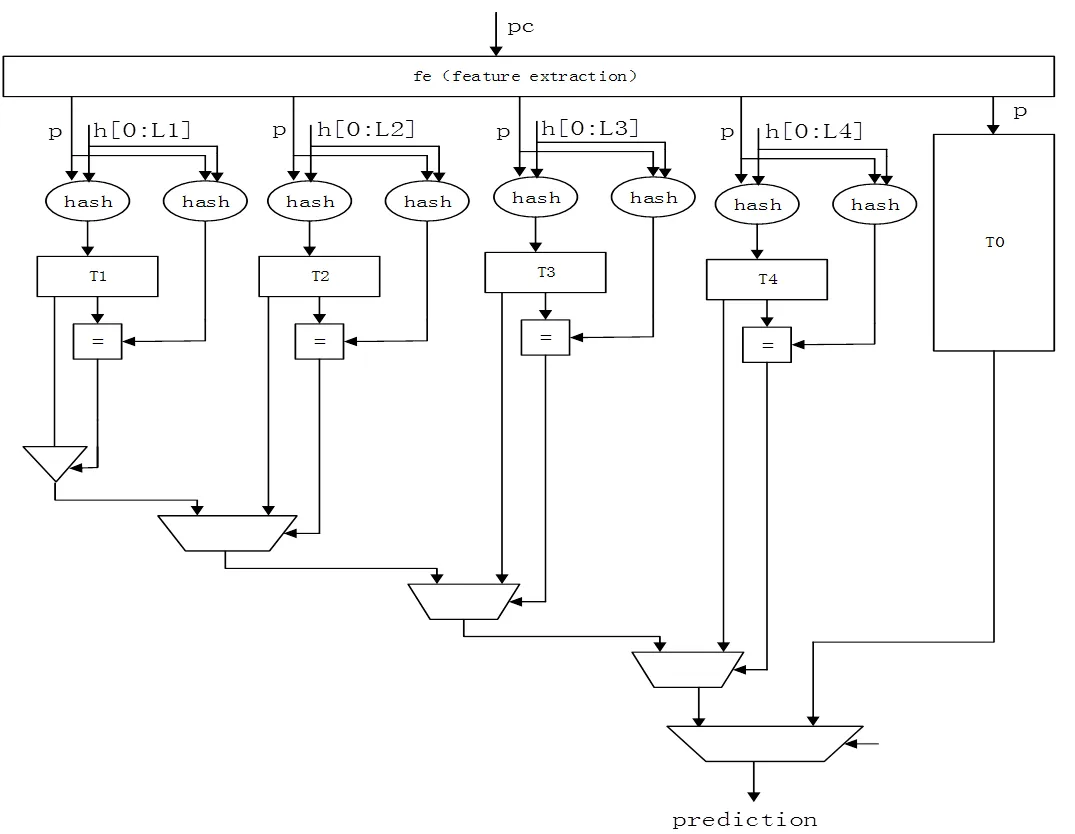
图4 改进型TAGE分支预测器

ctrtake_cntn_taken_cntu
改进型预测器预测步骤:
(1)对程序计数器进行特征提取,得到特征值。
(2)将历史寄存器h分成4等分。将特征值分别与历史寄存器的1/4长度位宽、2/4长度位宽、3/4长度位宽、4/4长度位宽进行2次不同的哈希计算,得到8个结果值,作为4张表的索引值和标记值。
(3)利用索引值选取T1、T2、T3、T44张表对应的行,取出对应行的tag位与步骤2标记值进行比较。如果相等,则取出对应行的ctr和u。否则,忽略该表的预测值。
(4)根据预测表的优先级T4>T3>T2>T1,从标记预测表选择优先级最高的ctr和u。
(5)从基础预测表T0得到ctr和u。
(6)比较置信度。如果基础预测表的置信度(u)大于标记预测表的置信度,则取基础预测表的预测值(ctr)作为最终的预测值,否则取标记预测表的预测值(ctr)作为最终的预测值。
3 性能评估
本文对TAGE预测器结构进行优化。为了测试改进型TAGE分支预测器的效果,使用spec2000的部分子程序进行测试,将测试结果与文献[12]进行对比,对比的结果如图6所示。由表中的数据可知,改进型的分支预测器预测准确度有着明显的上升。其中,编号为175.1的子测试程序主要用来测试与历史不相关的分支,准确度从之前的88.5%上升到现在的92.45%,准确率足足提升了3.95%。编号为164, 181, 252.3, 300的4个子测试程序准确度也有着相应的提升。使用PC特征提取的值索引预测表能够降低分支别名干扰的问题,提升基础预测表的优先级能够提高预测与历史不相关分支的准确率。
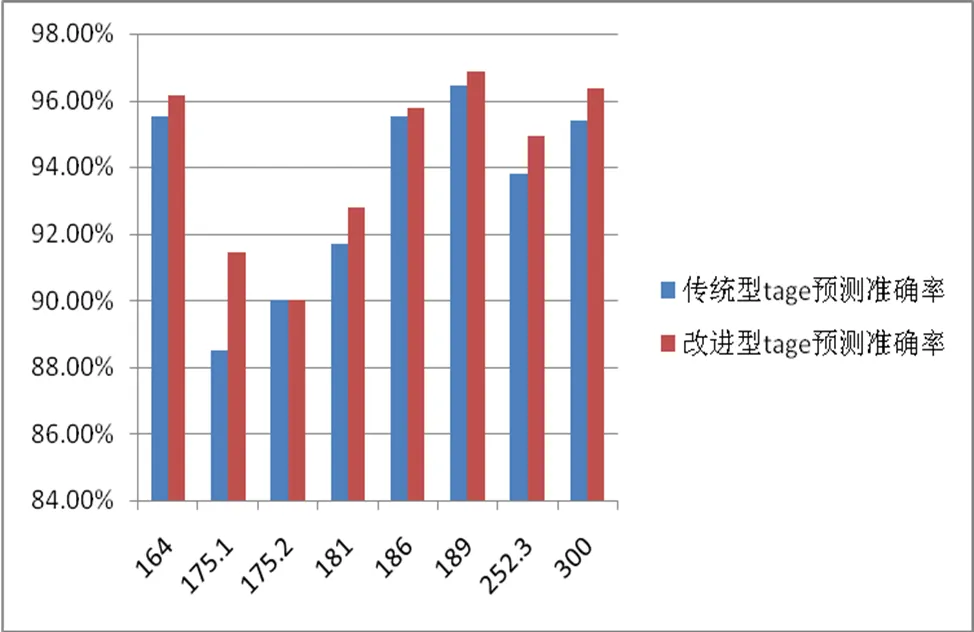
图6 使用spec2000部分子程序测试对比图

表1 资源消耗以及功耗对比
由表1可知,芯片的资源仅仅增加了4.8%,功耗增加了不足1%。以增加较小的芯片面积和功耗换取分支器的准确率是非常值得的。
4 结束语
通过对TAGE分支预测器的结构进行探究,发现预测器存在两个缺陷,并对预测器结构进行针对性改进,提出PC特征提取和提升基础预测表的优先级的方式。和传统的TAGE分支预测器相比,改进型的预测器准确率有着显著的提高。分支预测器的预测准确率是影响处理器性能的关键因素,是处理器设计的重中之重,因此,这种提升预测器准确率的方式显得尤为重要。
[1] 肖建青, 沈绪榜, 李伟, 等. 一种组合延迟槽和预译码技术的新型分支预测器[J]. 小型微型计算机系统, 2015, 36(4): 820-825.
[2]苟鹏飞, 喻明艳, 杨兵, 等. 基于类型预测的甚块预测器[J]. 计算机学报, 2012, 35(7): 1539-1552.
[3]Sprangle E, Chappell R S, Alsup M, et al. The agree predictor: a mechanism for reducing negative branch history interference[J]. Acm Sigarch Computer Architecture News, 1997, 25(2): 284-291.
[4] Schlais D J, Lipasti M H. BADGR: A practical GHR implementation for TAGE branch predictors[C]. 2016 IEEE 34th International Conference on Computer Design (ICCD), Scottsdale, AZ, 2016:. 536-543.
[5]Chatzidimitriou A, Papadimitriou G, Gizopoulos D, et al. Analysis and Characterization of Ultra Low Power Branch Predictors[C]. 2018 IEEE 36th International Conference on Computer Design (ICCD). IEEE, 2018.
[6]Seznec A, Miguel J S, Albericio J. The Inner Most Loop Iteration counter: a New Dimension in Branch History[J]. IEEE Micro, 2016, 36(3): 1.
[7]Seznec. A new case for the TAGE branch predictor[C]. 2011 44th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Porto Alegre, 2011: 117-127.
[8]Gope D, Lipasti M H. Bias-Free Branch Predictor[C]. IEEE/ACM International Symposium on Microarchitecture, 2015.
[9] Xiangxi Z, Yonghui Z, Shuaiyan Z, et al. FPGA implementation of edge detection for Sobel operator in eight directions[C].Chengdu, 2018: 520-523.
[10] Yusoff N M, Abdul Halim I S, Abdullah N E, et al. Real-time Hevea Leaves Diseases Identification using Sobel Edge Algorithm on FPGA: A Preliminary Study[C].Shah Alam, Malaysia, 2018: 168-171.
[11] Israni S, Jain S. Edge detection of license plate using Sobel operator,[C].Chennai, 2016: 3561-3563.
[12] Maa Y C, Yen M H, Wang Y T. Evaluating and improving variable length history branch predictors[C]. Computer Symposium. IEEE, 2010.
Implementation of Improved TAGE Branch Predictor
LI Zheng-ping, GAO Yang
(School of Electronics and Information Engineering, Anhui University, hefei 230031, China)
In this paper, the traditional TAGE branch predictor has two problems of branch alias conflict and low prediction accuracy for branches that are not related to history. The proposed method is improved based on PC feature extraction and the priority of the basic prediction table. The traditional TAGE branch predictor is used in conjunction with the improved predictor to verify the SPEC2000 test procedure. The experimental results show that the improved prediction accuracy of the branch predictor is obviously improved.
branch prediction; processor performance; feature extraction; convolution kernel
TP302.1
A
1674-3261(2020)01-0001-04
10.15916/j.issn1674-3261.2020.01.001
2019-11-01
国家自然科学基金项目(61474001)
李正平(1979-),男,安徽宣城人,教授,博士。
优先出版地址:http://kns.cnki.net/kcms/detail/21.1567.T.20191230.0916.002.html
责任编校:孙 林
猜你喜欢
河北大学学报(自然科学版)(2022年3期)2022-06-16 01:30:10
煤气与热力(2022年2期)2022-03-09 06:29:30
计算机工程与科学(2021年2期)2021-03-01 03:33:38
学生天地(2019年28期)2019-08-25 08:50:54
数学物理学报(2018年1期)2018-03-26 08:16:36
湖北师范大学学报(自然科学版)(2015年1期)2016-01-10 08:41:20
河南科技(2014年10期)2014-02-27 14:09:30
电子设计工程(2014年18期)2014-02-27 12:00:24
山西大同大学学报(自然科学版)(2014年3期)2014-01-23 01:56:30
疯狂英语·口语版(2013年1期)2013-01-31 09:23:26
