
基于XGBoost的土壤含水量传感器温度补偿模型研究
2021-09-02 01:28孟范玉于景鑫史凯丽
节水灌溉 2021年8期
沈 欣,吴 勇,孟范玉,张 赓,于景鑫,史凯丽
(1.全国农业技术推广服务中心,北京100125;2.北京市农业技术推广站,北京100129;3.农业信息软硬件产品质量检测重点实验室,北京100097;4.北京派得伟业科技发展有限公司,北京100097)
0 引言
精准灌溉是提高农业水资源利用效率,缓解我国水资源短缺的有效途径[1]。精准农业灌溉技术是以大田耕作为基础,按照作物生长需求,采用精确的灌溉设施对作物进行严格有效的施肥灌水[2]。因此,土壤含水量信息的准确采集决定了精准灌溉的准确性和可靠性。
传统的土壤含水量测量方法是烘干法——通过人工取土的方式获取土壤样本,在105 ℃高温烘干超过48 h后根据重量的变化计算土壤含水量。然而烘干法操作复杂且取土过程会对原状土体造成破坏,此外,该方法测定的数据有较大的时间延迟难以满足连续监测的要求[3]。随着传感器测量技术的进步,通过传感器测量土壤含水量可定时连续监测并通过无线通讯网络回传至数据中心,实现高效便捷的土壤多深度含水量的连续监测[4]。在农业生产和科研应用中,介电法是常用的测定方法,该方法以土壤的介电特性为基础,通过监测土壤的介电特性来计算土壤的含水量,而根据其监测方式的不同又可以分为电容法、同轴探头法、传输线法、自由空间法和谐振腔法[5]。在同轴探头法的基础上又研究出了驻波比法(SWR)、时域反射法(TDR)和频域反射法(FDR)等方法,其中FDR 测定方法目前最为常用[6]。然而,研究发现外界环境等因素尤其是土壤温度对土壤水分传感器的监测精度、稳定性、监测范围、监测速率等传感器性能指标有不同程度的影响[7],所以评估土壤温度对土壤传感器测量准确性的影响并构建校正模型至关重要。
国内外的相关学者针对温度对土壤传感器的影响及校正模型作了大量的研究。例如,孙道宪等采用数据融合技术建立补偿模型对TDR-3 土壤湿度传感器进行补偿,降低了传感器受土壤硬度的影响程度,使测量精度提高[8]。高磊等对FDR土壤湿度传感器进行了温度的影响因素试验,得出了FDR 土壤湿度传感器受温度影响的规律并绘制了相关曲线[9]。张荣标等研究了EC-5 土壤水分传感器受温度的影响,并使用最小二乘法建立了EC-5 土壤湿度传感器受温度影响的补偿曲线,减少了传感器受温度的影响程度,降低监测误差[10]。H R Bogena等研究了TE 型土壤湿度传感器受温度变化和电导率的影响并得出了对TE 传感器进行补偿的数学模型[11]。Seyfried 等研究了温度变化对EC-5 土壤含水量传感器的影响并建立了温度和土壤介电常数的拟合曲线[12]。然而,温度对传感器测量土壤含水量的影响机制复杂,呈现出复杂的非线性关系,现有的研究通常采用线性回归构建温度校正补偿模型,难以实现高精度温度补偿。
目前,AI 算法相比于传统模型具有更强大的数据拟合能力,而集成学习是其热门发展趋势[13],集成模型将独立模型组合成更强的学习器,相比于单独的模型能够获得更好的稳定性和预测效果[14]。在集成学习模型中,XGBoost (eXtreme Gradient Boosting)是2016年提出的一种基于树的集成学习模型[15],该模型在很多机器学习比赛中获胜并在工业界和学术界有着广泛的应用[16]。然而,目前鲜有研究利用XGBoost 算法构建针对传感器土壤含水量温度补偿的模型。
本研究以小汤山精准农业与生态环境重点野外科学观测试验站土壤样本为依托,分别配置12 组不同含水量湿土土样基准,测定了传感器在0~45 ℃的温度变化过程中传感器读数数据,来构建基于AI 算法的温度补偿模型。本研究的主要目的是:①分析温度对土壤含水量传感器测量精度的影响效应;②提出基于XGBoost的土壤含水量温度校正模型构建方法;③评估XGBoost土壤含水量温度校正效果。
1 材料与方法
1.1 试验材料
本论文试验材料选自设在北京市小汤山的精准农业与生态环境重点野外科学观测试验站(东经116°34′-117°00′,北纬40°00′-40°21′)。试验区为平原地貌,属温带半湿润季风性气候,在田块内选取0~20 cm 耕作层土壤样本。表1 展示了土壤背景值的测试结果。

表1 土壤背景值测试结果Tab.1 Test results of soil background values
本试验选用传感器为FDR原理的探针式传感器(见图1),其量程为0%~100%,在非饱和范围内传感器的监测偏差值为±3%,重复性为±1%,响应时间小于1 s,工作电压为5~12 VDC,输出信号为0~1.5 VDC 或4~20 mA。95%的测量区域为围绕中央探针直径5 cm、长8 cm的圆柱体内。

图1 土壤含水量传感器的外观图Fig.1 Exterior view of soil water content sensor
1.2 试验方法
本研究在室温22 ℃左右条件下使用传感器测定土样湿度。选取土壤表层0~20 cm 耕作层的土壤样本,将土样晒干后使用2 mm 筛网过筛。为了方便表述,下文所述的土壤含水量如无特殊注明则均代表体积含水量。使用拌土法分别配置体积含水量为10%、15%、20%、25%、35%的湿土土样,每个梯度设置3个重复,并将制备好的土壤样本密封静置48 h以便土壤均匀混合,将放置后的土样按照原状土壤容重(1.4 g/cm3)定容填装到高20 cm、直径20 cm的土柱。
试验过程中,将被测试传感器安置于土样后放入控温箱内,将箱内温度降为0 ℃。使用传感器的温度探头观察土壤样本的温度,在土壤样本稳定至0 ℃后,记录传感器的读数。分别测试传感器在0 ℃、5 ℃、10 ℃、15 ℃、20 ℃、25 ℃、30 ℃、35 ℃、40 ℃、45 ℃的土壤温度条件下的读数数值变化。试验中使用薄膜覆盖密封土样,避免放置过程中水分蒸发而影响试验结果。在使用传感器读数后,使用烘干法将所测部分土样在105 ℃的烘箱内烘干48 h,测定土壤真实含水量。
1.3 评价方法
本研究中所构建的温度对土壤含水量影响的校正模型属于回归问题,因此,我们选取了4个关键精度评定误差指标来评价模型的预测精度和拟合情况。
平均绝对误差(MAE):
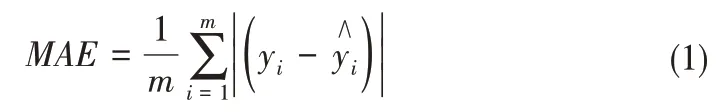
均方误差(MSE):
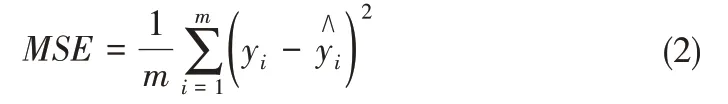
均方根误差(RMSE):
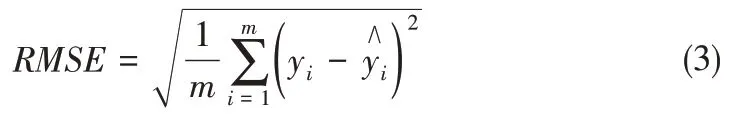
决定系数(R2):
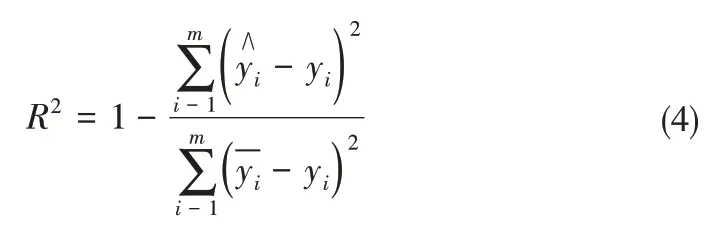
MAE指标可以反映预测值误差的真实情况。MSE是模型估算值和真实值之差的平方期望值,反映了误差数据的变化程度,MSE值越小表明模型预测精度越高。RMSE是MSE指标的算术平方根。R2可以消除数据维度对评价指标的影响,反映模型对数据的拟合程度。
2 模型构建
2.1 XGBoost算法
XGBoost 是借助梯度提升技术得以实现的机器学习算法,是一种增强的GBDT 算法,其基分类器是分类与回归树(CART),XGBoost 将多个CART 进行组合,即XGBoost 为树集成模型[15]。XGBoost 模型以迭代添加树的方式建立,第t次迭代时第i个样本的预测值可以表示为:
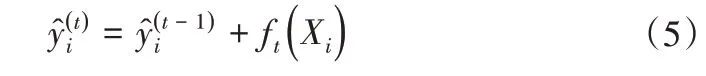
迭代添加树以最小化目标函数,目标函数式可以表示为:
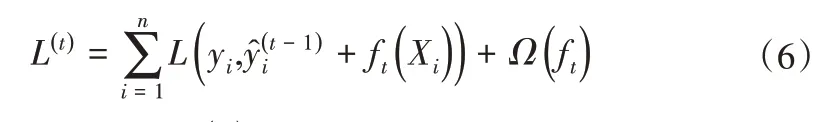
式中:L为损失函数;Ω(ft)表示模型复杂度。
为了快速优化目标,对式(6)使用二阶泰勒展开:
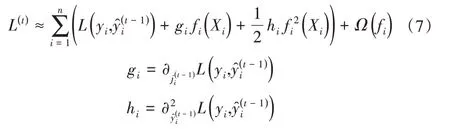
式中:gi和hi分别为损失函数项的一阶和二阶导数。
在添加第t棵树时,前面t- 1 棵树已经完成训练,即为常数项,移除该项获得第t步的简化目标函数:
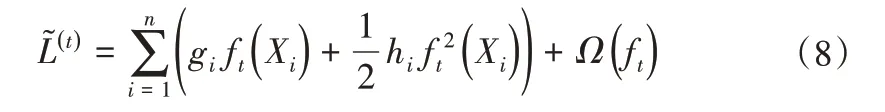
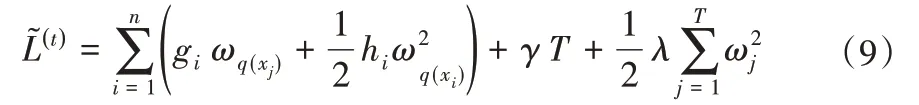
式中:ωj为叶结点j的权重;γ和λ为复杂度变量。
最终,目标函数得以优化,最优解可以表示为:
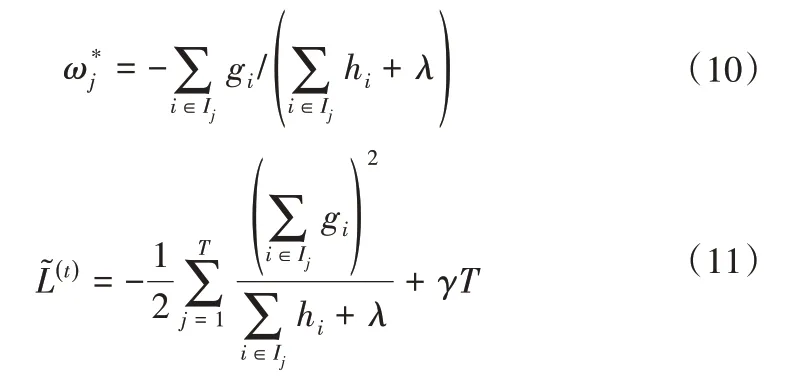
叶结点的分裂是基于模型的输入变量来进行的,通过输入变量被应用于叶结点分裂的次数来计算该输入变量的重要性得分,重要性得分反映了该输入变量与模型输出结果之间的相关性,进而根据各输入项的重要性总和计算相对重要性,因此可以根据输入变量相对重要性得分来筛选XGBoost 的输入。
2.2 XGBoost土壤含水量温度校正模型
采用XGBoost作为核心拟合算法构建传感器读数、土壤温度和真实土壤含水量之间的复杂非线性关系。模型的输入项为2×1 矩阵,输出项为1×1 矩阵。参考相关文献对XGBoost 模型的研究结果[15],本研究中XGBoost 的主要参数、参数设置、可选区间和参数释义见表2。

表2 XGBoost模型主要参数设置Tab.2 XGBoost model main parameter settings
为了充分利用数据价值,采用“K折交叉验证”用于模型调优,通过使用无重复抽样技术,每次迭代过程中每个样本点只有一次被划入训练集或测试集的机会,使得模型获得泛化性能最优的超参输出值。本研究采用5折交叉验证,训练集全部用于模型训练,而测试集用于对训练好的模型进行误差检验。
XGBoost 土壤含水量校正模型的温度校正过程见图2,包含以下几个步骤:①获取试验数据,对数据进行归一化处理,进而将数据集划分为训练集和测试集2 部分;②采用5 折交叉验证法对训练集进行处理,分别生成5份用于训练和验证的数据组;③针对交叉验证的每份数据,XGBoost 模型分别建立树模型、寻找最优分裂点、构建XGBoost和计算目标函数;④本研究采用MSE指标对模型进行误差评定,选取最佳预测精度的模型权重参数作为最终的模型参数;⑤将测试集代入最终模型以评估模型对未参与建模数据的预测精度。
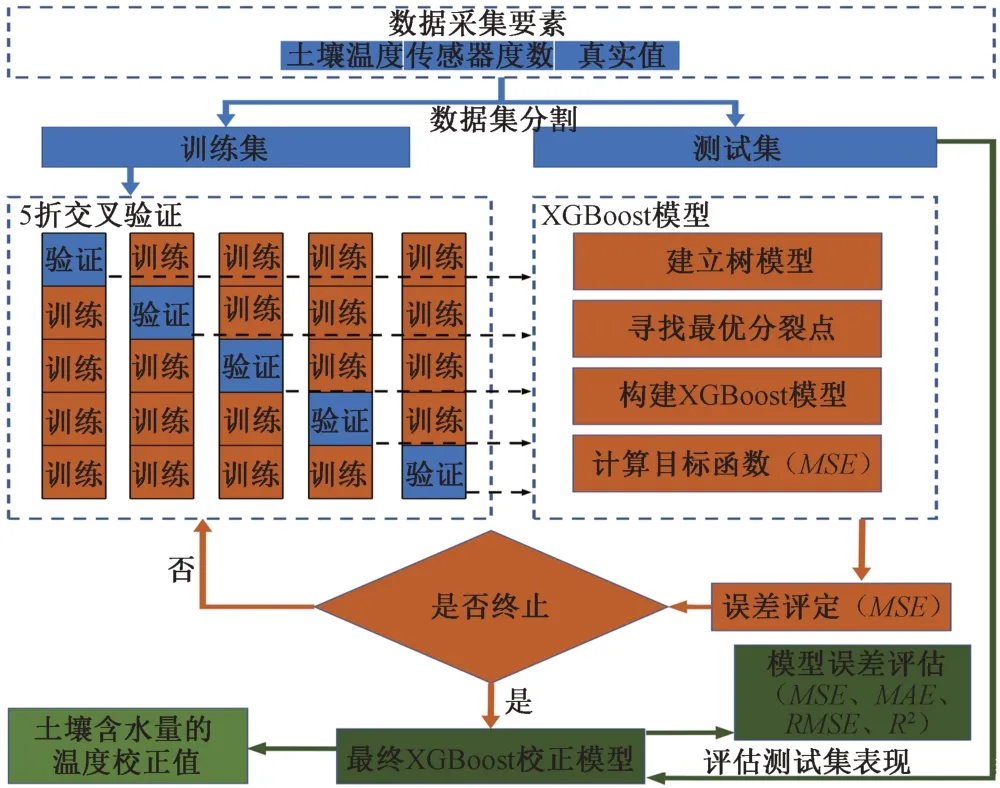
图2 基于XGBoost的土壤含水量校正模型结构Fig.2 XGBoost-based soil moisture content correction model and training process
2.3 数据集划分
为了能够更好地验证XGBoost模型的模型构建能力且充分利用有限的数据资源,将数据集分成训练集和测试集2 部分。随机选取总数据中的80%作为训练集,总数据集中剩余的20%数据用于测试模型的预测精度评定。
2.4 归一化方法
为了提升模型训练的精度和拟合速度,将数据进行归一化处理,本研究使用“Min-Max”归一化方法来对各特征值进行处理。
2.5 模型训练环境
本研究试验的训练环境为一台图形工作站,配置为CPU:Intel(R)Xeon(R)CPU E5-1620 v4 @ 3.50GHz、GPU:NVIDIA Quadro K2200 和RAM:32 GB。模型训练采用Ananconda 平台作为模型训练基础平台,采用XGBoost 1.1.0 作为模型框架,底层Python版本为3.7。
3 结果与分析
3.1 温度对传感器测量精度的影响
表3显示了不同温度下,传感器在不同样本中的度数与基准值的差值。可以看出,传感器的读数均高于实际的土壤含水量值,整体偏差为[3.52%,14.93%]。此外,随着温度的升高,传感器在各样本的读数均出现了升高趋势。这是因为随着温度的升高土壤的极化作用会变强,土壤中水分子的运动也随着温度的升高而变得活跃,从而导致土壤的介电常数增大。
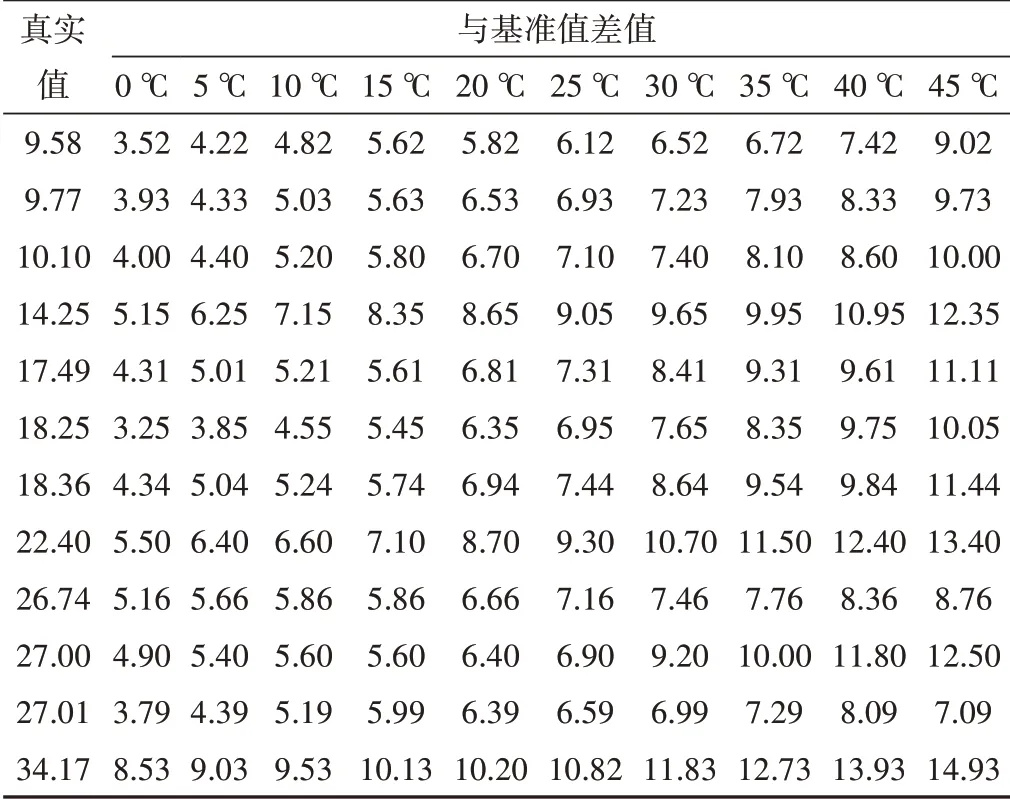
表3 不同温度下土壤含水量传感器读数值与基准值的差值 %Tab.3 Difference between soil moisture sensor measurements and reference values at different temperatures
图3 展示了传感器在0~45 ℃温度基准下对各样本读数的最大值、最小值和差值。土壤温度在0~45 ℃的变化过程中,土壤含水量样本由低至高的12 组类别,传感器读数数值范围分别为[13.1%,18.6%],[13.7%,19.5%],[14.1%,20.1%],
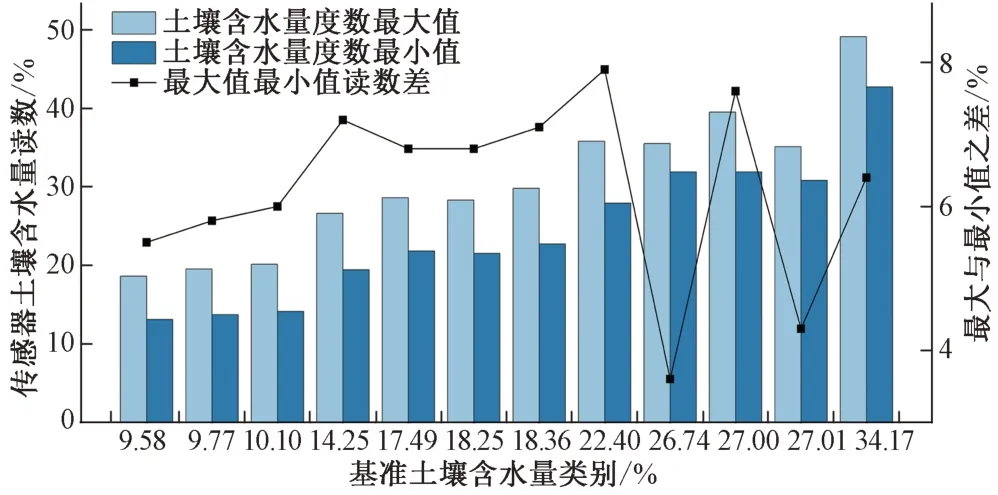
图3 0~45 ℃温度下传感器对各基准度数的最大值、最小值和差值Fig.3 Maximum,minimum and difference of sensor for each reference degree at 0~45 ℃
[19.4%,26.6%],[21.8%,28.6%],[21.5%,28.3%],[22.7%,29.8%],[27.9%,35.8%],[31.9%,35.5%],[31.9%,39.5%],[30.8%,35.1%],[42.7%,49.1%]。0~45 ℃温度下各基准类别读数最大值与最小值之差为[3.6%,7.9%],平均读数变幅为6.25%,读数变幅较为接近且与基准土壤含水量并无明显的趋势关系。
从表3的结果可以看出,温度对传感器测量结果的影响明显,温度与传感器读数呈正相关,温度升高会导致传感器读数的变大,这是因为随着温度的升高土壤的极化作用会变强,土壤中的水分子的运动也随着温度的升高而变得活跃,从而导致土壤的介电常数增大。这与文献[9,10,18]的研究结论相同。此外,赛音朝格图等[19]在温室环境中的研究也有相似的结论。
3.2 XGBoost 模型土壤含水量温度补偿估算精度对比
为了验证本研究所提出的XGBoost模型的土壤含水量温度校正效果,以本次试验0~45 ℃温度下和传感器在不同基准的读数为模型验证数据,对XGBoost 模型的预测效果进行评估。此外,为了进一步展示所提出的XGBoost模型在土壤含水量温度校正的精度优势,对比了其他的集成学习方法,比如Bagging[20]、Random Forest[21]和Adaboost[22],此外,还对比了经典的传统机器学习方法,比如Decision Trees[23]和K-Nearest Neighbor[24]方法。
表4 显示了XGBoost 模型与其他机器学习模型对训练集数据的5 折交叉验证预测误差和对测试集的预测误差结果。除SVR 和KNN 外,其余模型的训练集和测试集的预测R2均超过了0.90,说明其均能够实现对整体数据集的较好拟合。
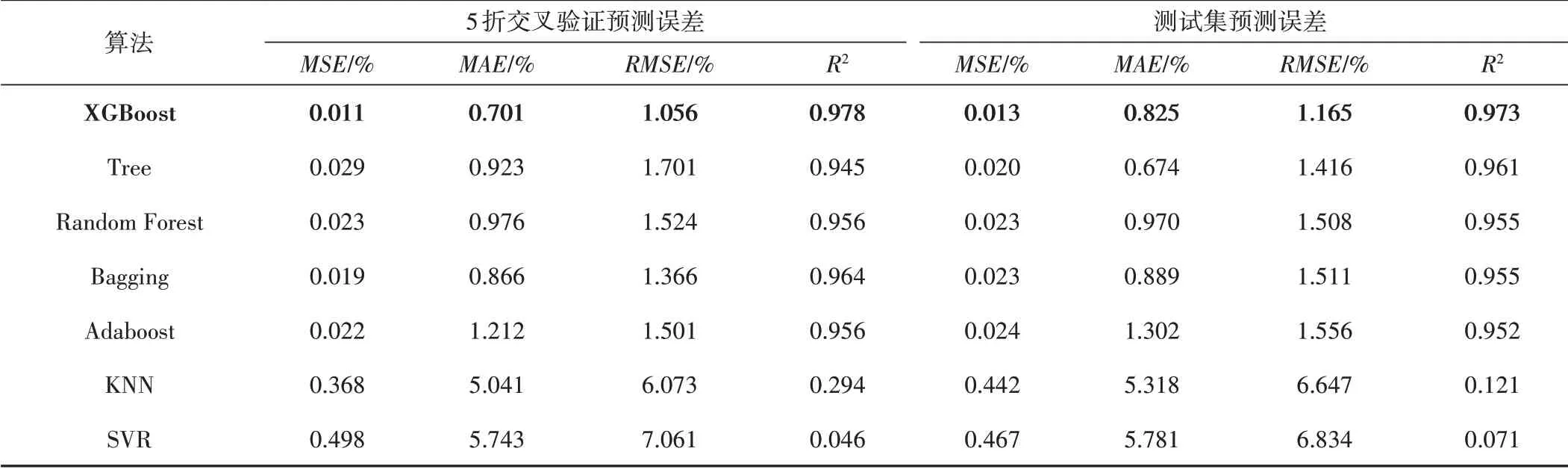
表4 XGBoost及不同机器学习模型的土壤含水量校正精度对比Tab.4 Comparison of the accuracy of soil moisture content correction for XGBoost and different machine learning models
从测试集的预测误差看,本研究所提出的XGBoost模型获得了最佳的预测精度,MSE、MAE和RMSE分别为0.013%、0.825%和1.165%,取得了所有对比模型中的最佳预测表现。这是由于XGBoost算法具备并行计算、近似建树、对稀疏数据的有效处理以及内存使用优化等功能,使得XGBoost不仅运算高效且拟合精度更高。文献[25,26]的研究同样证明了XGBoost模型预测能力优于其他基于树的集成学习模型。
在未来的研究中,希望能够在不同的土壤类型上进行数据采集以分析空气温度、土壤温度等因素对模型估算的影响,进一步提升用于模型训练的数据量来平衡训练集与测试集的统计学指标,实现更好的模型泛化性能和应用能力。
4 结论
针对土壤温度对传感器土壤含水量测定的影响,本研究提出采用基于树的集成学习算法XGBoost 结合“5 折交叉验证法”构建土壤含水量温度校正模型。以小汤山精准农业与生态环境重点野外科学观测试验站土壤样本为依托,分别配置含水量为10%、15%、20%、25%、35%的湿土土样,测定了12 组土壤含水量基准环境,记录了传感器在0~45 ℃的温度变化过程中传感器读数。
(1)土壤含水量传感器读数随着温度的升高而增加,0~45 ℃温度下各基准类别读数最大值与最小值变幅为[3.6%,7.9%],平均读数变幅为6.25%。
(2)XGBoost 土壤含水量温度校正模型能够实现对传感器土壤含水量温度影响的补偿,对测试集的MSE、MAE、RMSE和R2分别为0.013%、0.825%、1.165%和0.973。此外,对比Tree、Random Froest、Bagging、Adaboost、KNN 和SVR 模型,本研究提出的XGBoost 温度校正模型取得了最佳的预测精度。本研究对土壤含水量传感器温度校正和基于树的集成学习模型构建具有一定的意义。
猜你喜欢
恋爱婚姻家庭·养生版(2021年10期)2021-10-28
小学生学习指导·低年级(2021年6期)2021-09-10
少儿科学周刊·少年版(2021年20期)2021-01-17
国学(2020年1期)2020-06-29
农家科技(2020年3期)2020-05-11
中学生数理化(高中版.高考理化)(2020年2期)2020-04-21
雷达学报(2018年3期)2018-07-18
航天返回与遥感(2018年2期)2018-05-17
佛山陶瓷(2017年8期)2017-09-06
哈尔滨理工大学学报(2016年2期)2016-09-12
