
融合知识的旅游景点及属性的情感分类方法
2021-08-31 06:10李德玉郝思青王素格廖健王敏
山西大学学报(自然科学版) 2021年3期
李德玉,郝思青,王素格,廖健,王敏
(1. 山西大学 计算机与信息技术学院,山西 太原030006;2. 山西大学 计算智能与中文信息处理教育部重点实验室,山西 太原030006)
0 引言
山西作为我国的旅游大省之一,其旅游业已成为山西经济发展的支柱产业之一。旅游作为一种体验性产品,游客对景点的评论带有强烈的个人主观态度,对这些景点评论数据进行情感分析,将对潜在游客具有重要的参考价值,同时,对于旅游景点公司的发展也会起到支持作用[1]。文本情感分析是自然语言处理和文本挖掘领域中的一个热点问题,其任务是分析人们对产品、组织、个人以及事件及其属性的意见、情绪、评价和态度[2]。传统的粗粒度情感分析主要是判断篇章或句子整体的情感倾向,而在旅游评论中,由于职业、性格、生活习惯、出行计划等不同,人们所关心的重点也各不相同。例如,“五台山的景色很美,值得一去,而门票有点贵。”该条评论涉及景点“五台山”的“景色”和“门票”两个属性,说明该条评论的作者比较关心“五台山”的“景色”属性以及“门票”价格。因此,对于旅游评论文本的情感分析,不仅需要粗粒度的情感分析,还需要细粒度的属性级情感分析。
属性级情感分析ABSA(aspect based sentiment analysis)分为两类任务[3]:属性项情感分析ATSA(aspect-term sentiment analysis)和属性类情感分析ACSA(aspect-category sentiment analysis)。ATSA任务主要是针对给定句子中标记的具体属性项进行情感极性判别,而ACSA 任务是针对给定句子中某个属性类别进行情感极性判别。例如,景点的景色、门票、趣味性、性价比等均属于景点的某个属性类别。通过对旅游评论数据的属性级情感分析,可以获得这些属性的相关情感极性,即“景色”和“性价比”属性为正面情感,“门票”属性为负面情感。
本文将旅游评论的情感分类任务分为两个子任务,分别为景点情感分类和景点属性情感分类。对于景点情感分类,由于旅游领域中一条评论大部分是围绕一个特定的景点进行评价,因此本文假定这条评论的整体情感就是该景点的情感,其情感极性可以为正面、负面和中性三类情感之一。对于景点属性情感分类,属性通常是抽象的类别,有时不直接出现在评论文本中,但某些名词或形容词蕴含着评价的属性,例如,评论文本中出现“风景”可以认为是描述“景色”的属性,而出现“便利”则是描述“交通”的属性。为此,通过分析旅游评论数据,我们定义了六个属性,如表1 所示。其中,每个属性的情感极性为正面、负面和中性三类情感之一。

表1 属性及对应属性词Table 1 Aspect classes and corresponding aspect words
需要说明的是本文仅围绕景点的旅游评论进行情感分类,并不考虑景点的相关产业,例如,餐馆和特产等。山西的景点有八大文化品牌:“华夏之根、黄河之魂、佛教圣地、晋商家园、边塞风情、关圣故里、古建瑰宝、太行神韵”。因此,景点描述本身蕴含着多种信息,例如,“五台山现在也是有点落入凡尘了,佛教徒去看看很正常,若是纯旅游就不要去了。”该例子既考虑到景点“五台山”自身蕴含的信息,还需要对景点前后状态进行对比。对于人类来说,景点本身蕴含的信息属于常识知识,提到“五台山”的第一印象就是“佛门净地”,这些信息好像景点的潜台词,不需要具体地描述,但是却对景点评价起到补充作用。
杨亮等的研究[4]说明了知识对于挖掘评论观点的重要性,但他们仅仅关注通用的情感常识。为了让机器拥有人类旅游的常识知识,对于给定的景点或者旅游评论,本文提出了基于景点知识的多任务联合学习的分类模型KB-MJLCM(Knowledge-Based Multi-task Joint Learning Classification Mod⁃el),该模型结合景点描述的知识信息,并使用BiL⁃STM 和注意力机制对景点及其属性进行情感分类。本文的主要贡献如下:
(1)建立面向景点评论的情感分类模型,该模型融合了旅游知识库中的景点描述信息,增强了景点的情感语义表示。
(2)对旅游评论进行情感分类时,同时对粗粒度和细粒度的情感类别判断两个子任务进行联合学习。
(3)在建立的山西旅游评论数据及山西旅游知识库上进行了实验,本文的方法取得了较好的结果。
1 相关工作
在文本情感分析中,通常使用传统的文本分类方法判断给定的篇章、段落、句子或短语的情感倾向[5]。伴随着深度学习模型的发展,神经网络模型被广泛地应用于文本分类任务中。2014 年,Kim[6]首次将卷积神经网络模型应用到NLP 领域,使用CNN (Convolutional Neural Network)建 立 了TextCNN 神经网络模型,并通过实验验证了CNN模型在文本分类的性能,此后,CNN 被应用于微博情感倾向性分析等任务中[7]。但CNN 无法对更长的序列信息进行建模,导致一些重要信息的丢失。因此,Qiu[8]提出了TextRNN,使其更好地表达上下文信息。Lai 等[9]利用RNN 和CNN 的优点,提出了RCNN 方 法(Recurrent Convolutional Neural Net⁃work)。Facebook 于2017 年发布了文本分类模型FastText[10],该 模 型 使 用 字 符 级 别 的n-gram 表 示 一个单词或句子,使得一些生僻词或未出现的单词可以从形态相近的单词中得到较好的词向量表示。2019 年,谷 歌 提 出 了Bert(Bidirectional Encoder Representations from Transformers)[11],在11 项NLP 任务中表现出卓越的性能,此后提出了Bert⁃CNN[12],该模型利用Bert 进行语义向量化表达,然后输入到CNN 中得到分类结果。
属性级情感分析ABSA(aspect based sentiment analysis)是自然语言处理中的一个重要任务。针对一条评论中可能出现多个评价对象或评价属性这一问题,Hu 等[13]提出了基于特征的情感分析。在ABSA 中,循环神经网络[14]和标准注意力机制[15]被较多地使用,以自动的方式学习上下文和属性词的语义特征。现有许多模型使用LSTM 层[16]从嵌入向量中提取情感信息,并应用注意力机制[17]使模型注意到与给定属性/实体相关的文本范围。TDLSTM[18]和 门 控 神 经 网 络[19]使 用 两 个 或 三 个LSTM 网络分别建模给定目标的左右上下文。具有多跳注意力的记忆网络[20]试图明确只关注信息最丰富的背景区域,以推断出对目标词的情感极性。Chen 等[21]利用双向LSTM 的记忆功能和门控循环单元网络,通过组合多个注意力的情感向量方式增强记忆网络,实现长距离句子的记忆功能。Song 等[22]通过在多头注意力基础上,设计基于注意力的语义编码网络,摒弃了存在长距离依赖问题的RNNs 网络。Wang 等[23]提出的ATAE 模型,使用LSTM 网络和注意力机制来解决属性级情感分析问题。Xue 等[24]将CNN 与门控机制相结合,提出了GCAE 模型,并将其应用于属性级情感分析任务中。曾锋等[25]通过双层注意力机制分别对单词层和句子层进行建模,捕获不同单词和不同句子的重要性。由于旅游评论文本中通常没有出现明显的属性项词,故本文主要关注ACSA 任务。现有的方法在一些通用领域的数据集上可以达到较好的效果,但在旅游领域的属性级情感分类问题上还需要考虑旅游数据的特殊性。何雪琴等[26]提出融合句法规则和卷积神经网络的旅游评论情感分析算法,在新疆旅游数据集上进行了实验。目前景点评论的情感分类方法都是粗粒度的,并没有充分考虑到景点评论的特征,将其用于旅游领域的景点及其属性的情感分类方法研究。
2 融合景点知识的多任务联合学习分类模型
为了增强旅游评论文本的情感表达,我们在表示层使用了知识库中景点的描述信息,结合BiL⁃STM 和注意力机制,建立KB-MJLCM 模型。具体来说,我们首先使用Bert 获得评论文本的嵌入,然后通过给定景点名称,挖掘知识库中对应的景点描述,再将Bert 得到的景点描述句子表示作为此景点的外部知识表示,将其与原景点表示进行拼接,获得景点的新表示,最后,使用多任务联合学习,同时得到景点情感倾向和景点属性的情感倾向。对于景点的情感分类任务,我们把它看作一个三分类任务,而对于景点属性的情感分类任务,使用多标签文本分类方法。模型整体框架如图1 所示。
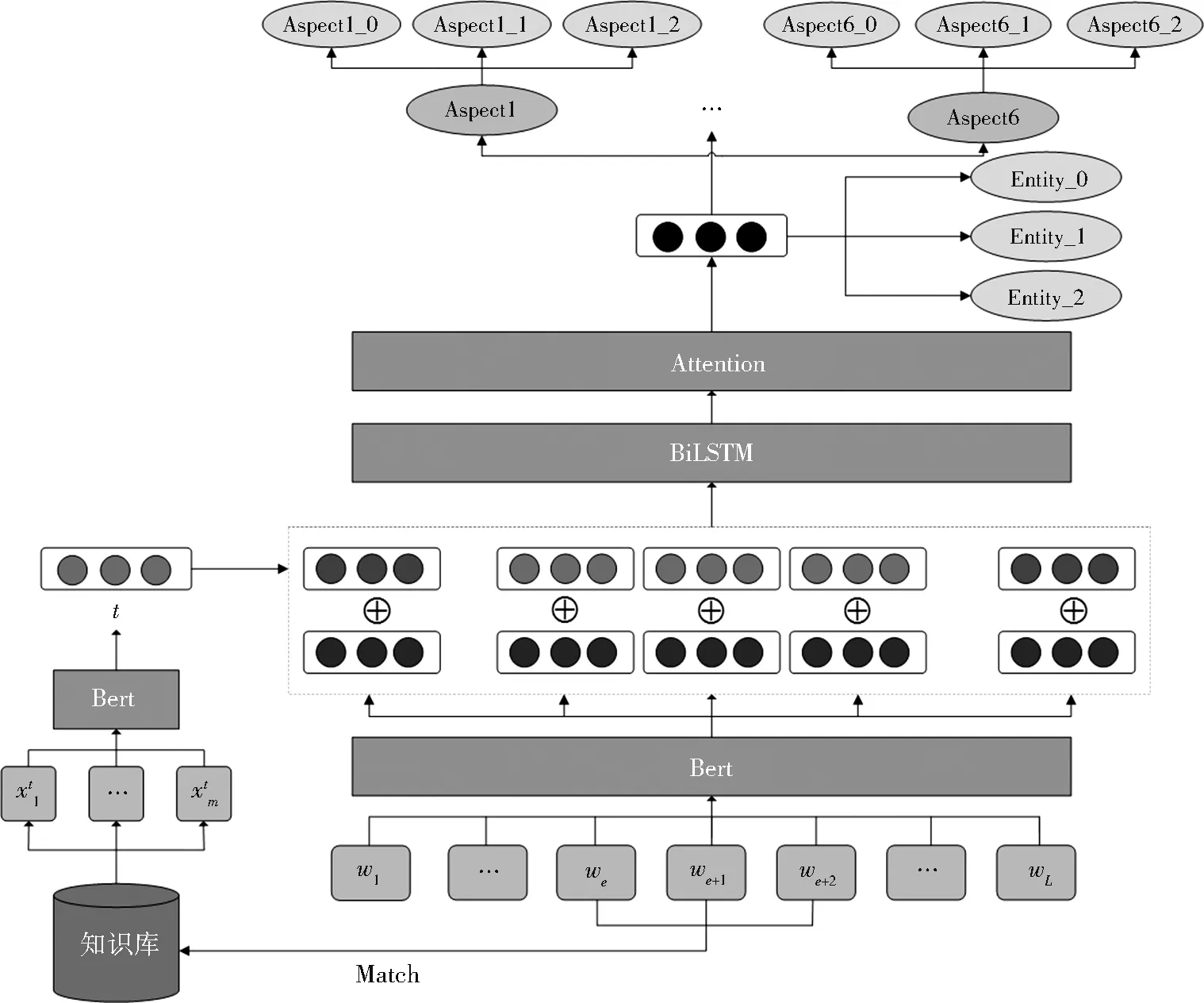
图1 模型整体框架Fig. 1 Overall framework of the model
(1) 基于Bert 的评论和景点的嵌入表示

(2) 基于景点描述知识的评论表示
传统的句子向量表示方法是对一句话中每个词的嵌入表示进行加权平均,但由于不同语境下词语的含义不同,简单的平均无法刻画其上下文的语义,我们使用Bert 得到整个句子的唯一向量表示。
给出一条旅游知识三元组<头实体,关系,尾实体>,头实体为景点,关系为“简介”,尾实体为景点描述,将其表示为(h,r,t)。对于给定的景点,将景点和知识库中的头实体进行匹配,将匹配到的三元 组 的 尾 实 体t输 入 到Bert 中,Bert 在 每 个input 之前添加一个特殊的记号[CLS],通过Transformer编码,使用CLS 位置的输出作为景点描述的向量表示t→∈Rd,d是向量维度,如图2 所示。
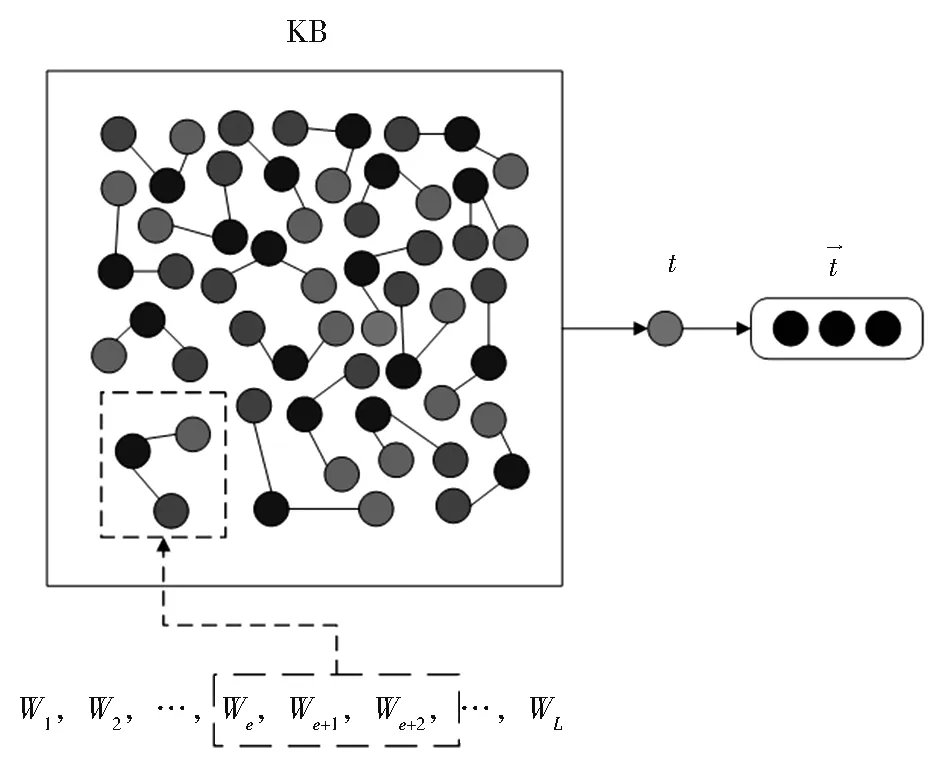
图2 景点描述知识表示Fig. 2 Knowledge representation of a scenic spot description
利用景点描述的句向量t→与评论中的景点表示进行拼接,作为景点新的嵌入表示ê。

(3) BiLSTM 层
对旅游评论文本分析时,不仅需要学习句子正向序列信息,还需要学习反向序列信息。因此,使用双向的BiLSTM 模型捕捉两个方向完整的信息。结合本文任务,将旅游评论中第i个词在t时刻通过前向LSTM 单元得到隐藏状态的表示为,通过后向LSTM 单元得到隐藏状态的表示为,其计算公式表示如下:
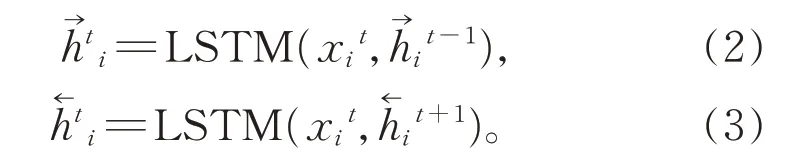
利用第i个词的前向隐藏状态和后向隐藏状态拼接的结果,可以得到旅游评论在t时刻最终的隐藏状态表示hti:
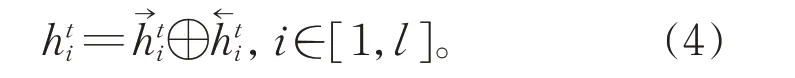
(4) Attention 层
本文使用注意力机制增强重要信息的权重系数,使模型关注到旅游评论中比较重要的部分,从而提高分类的准确率。注意力层的输入是BiL⁃STM 层的最终隐藏状态hi,计算公式如下:
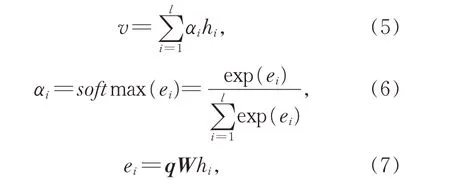
其中,v是注意力层的输出,αi是归一化的注意力系数,q为随机初始化的Query 向量,W为参数矩阵。
(5) 输出层
将注意力层的输出作为全连接层的输入进行分类,对于景点的情感分类任务,评论文本共包含三种情感类别,使用归一化的softmax 函数来得到情感判别结果;
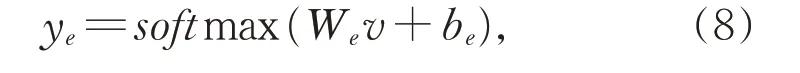
其中,ye为旅游评论的景点情感类别输出概率,We为权重,be为偏置项。
景点情感分类任务的目标函数为交叉熵损失函数,如式(9)所示。
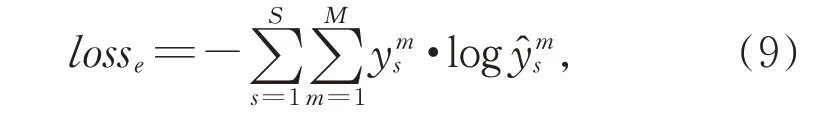
其中,S表示训练样本的数量,M表示所有的景点情感类别数量,ys表示第s个样本真实的类别标签,ŷs表示第s个样本的预测类别标签。
对于景点属性的情感分类任务,评论文本共包含六个属性类,其中,每个属性类包含三种情感类别。对于每个属性类,可以使用softmax 函数得到其判别结果如下:
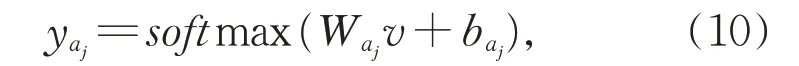
其中,yaj为景点属性,aj的情感类别输出概率,Waj为权重,baj为偏置项。
景点属性情感分类任务的训练阶段,采用交叉熵损失函数。
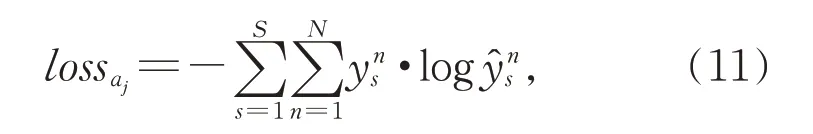
其中,S表示训练样本的数量,N表示所有的景点情感 类 别 数,ys表 示 第s个 样 本 真 实 的 类 别 标 签,ŷs表示第s个样本的预测类别标签。
将景点情感分类任务和景点属性情感分类任务通过联合学习同时更新参数,整个联合模型的目标函数如式(12)所示。
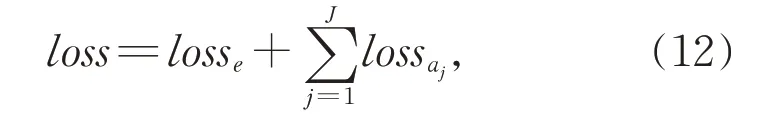
其中,J是景点属性类的个数。
3 实验
为了验证本文方法在旅游评论中的有效性,在山西旅游评论数据上进行了实验,以评估KB-MJL⁃CM 模型的性能。
3.1 数据集与参数设计
数据集:我们在携程上爬取山西旅游评论数据9 082 条作为数据集,标签均由人工标注。对于景点属性的情感分类任务,共定义了6 个属性类,其中,景色:2 843 条;性价比:2 354 条;交通:1 481 条;管理:1 232 条;门票:604 条;趣味性:568 条。每个属性类又分为正面、负面和中性3 种不同的情感极性。对于一条评论包含多个属性类的情况,参照Semeval-2014 任务4 的属性级情感分析数据标注方法。假设一条旅游评论中包含景点的p个属性类,则将该条评论在数据集中复制p次,为每条评论标注一个属性类。
使用课题组建立的山西旅游知识库作为外部知识信息来源,共1 732 条三元组知识,每条三元组的头实体为景点实体,尾实体为对应的景点描述。
超参数设计:为了实现模型测试,模型中的超参数设置如表2 所示。

表2 模型超参数设置Table 2 Hyperparameter setting for the model
3.2 实验结果及分析
为了验证本文提出的景点情感分类方法的性能,与其他的情感分类方法进行了比较实验,同时,为了验证知识库的作用,也对知识加入前后的实验进行了比较。
3.2.1 景点情感分类方法比较实验
将景点的情感判别看作文本分类任务,相应的对比实验也选用文本分类方法,具体如下:
TextCNN[6]:经典的CNN 文本分类算法,使用卷积神经网络模型进行文本分类任务。
TextRNN[8]:使用循环神经网络模型进行文本分类任务。
FastText[10]:Facebook 在2016 年提出的一 种快速文本分类算法,在保持性能的同时更加高效。
BertCNN[12]:使用Bert 对评论文本编码,然后通过卷积神经网络学习文本特征。
BertBiLSTM[27]:使用Bert 对评论文本编码,然后通过BiLSTM 学习文本特征。
ERNIE[28]:使 用 百 度 提 出 的ERNIE 进 行 文 本分类任务。
将上述文本分类方法与本文的KB-MJLCM 方法对景点情感判别任务进行实验,对比实验结果如
ATAE[23]:在输入层将词向量和属性词向量进行拼接,在隐藏层将隐藏状态词向量和属性词向量进行拼接,然后使用注意力机制得到最终的特征向量。
GCAE[24]:使用Glove 词向量表示句子,然后通过CNN 和门控机制得到最终的特征向量。
使用准确率(acc)作为评价指标,实验结果情况如表4 所示。表3 所示,其中,准确率(acc)和F1 值(macroF1)作为评价指标。
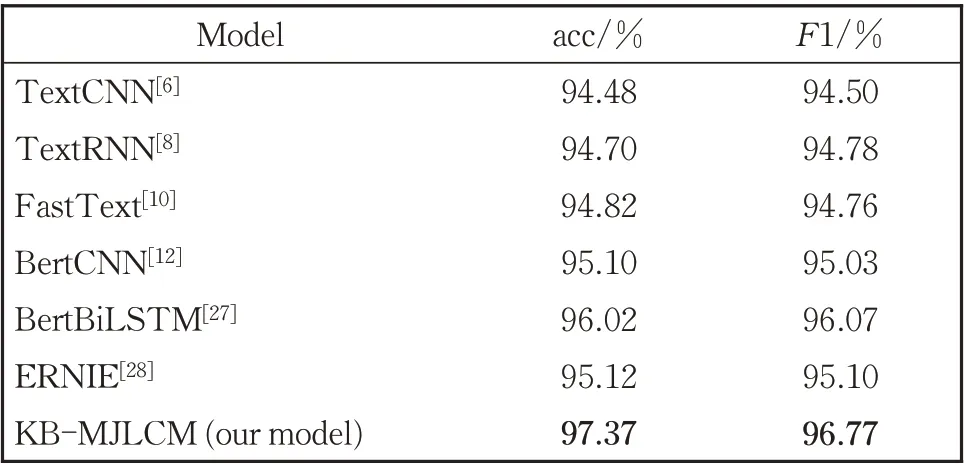
表3 景点情感分类方法的对比实验结果Table 3 Comparative experiment results of emotion classification methods of scenic spots

表4 景点属性情感分类方法对比实验结果Table 4 Experimental results of comparison of emotion classification methods in scenic spots
由表3 中的景点情感判别结果可以看出:
(1)本文的KB-MJLCM 方法是融合了景点描述知识,然后使用BiLSTM 和注意力机制挖掘文本特征,使景点情感判别的准确率达到97.37%,比TextCNN,TextRNN 和FastText 三 种 方 法 分 别 提高2.89%、2.67%、2.55%,F1 值 分 别 提 高 了2.27%、1.99%和2.01%。TextCNN 和TextRNN是经典的文本分类方法,分别使用卷积神经网络和循环神经网络捕获语义特征,在景点情感分类任务上的性能相近;FastText 在输入时加入n-gram 向量作为额外的特征,在输出时使用层次softmax 缩小模型预测目标的数量,相比基于神经网络的分类算法加快了训练和测试速度,但在分类准确率上并没有显著提升。
(2)本文的KB-MJLCM 方法相较于BertCNN、BertBiLSTM 和ERNIE 取得了更好的分类性能,准确率及F1 值都有明显提升。利用了Bert 的Bert⁃CNN 和BertBiLSTM 两种方法,在景点情感分类任务上的准确率分别达到了95.10%和96.02%,明显优于基于神经网络的TextCNN 和TextRNN。其主要原因是TextCNN 和TextRNN 的embedding 层是随机初始化的,而BertCNN 和BertBiLSTM 则使用Bert 作 为embedding 层,也 证 明 了 使 用Bert 获 得word embedding 可以有效提高分类准确率。ER⁃NIE 是百度提出的预训练模型,能够利用先验知识学习丰富的特征,在景点情感分类任务上达到了95.12%的准确率,与基于Bert 的文本分类模型性能相当。
3.2.2 景点属性情感分类方法的比较实验
在景点属性的情感判别任务上,本文仅与性能比较好的两种模型进行对比。
由表4 的实验结果可以看出:本文方法KBMJLCM 在景点属性情感分类任务上达到了96.30%的准确率,相比于ATAE 和GCAE 的实验结果均有显著提高。主要原因是一条景点评论可能包含多个属性及其对应的情感倾向,本文的KBMJLCM 可将景点属性的情感判别看作多标签文本分类任务,先将Bert 获得的评论向量表示与景点描述的知识表示相融合,然后使用BiLSTM 和注意力机制学习语义特征,最后通过6 个softmax 函数得到分类结果。而ATAE 的注意力层仅学习特定的as⁃pect 和context 词之间的关系而不是学习上下文词之间的语义关系,GCAE 使用门控机制控制情感特征的输出,然后通过最大池化层后输出情感类别,不能很好地提取文本特征。
3.2.3 景点知识库作用的验证实验
为了验证知识库在景点及其属性的情感分类中的重要性,本实验主要验证拼接知识表示前后的情感判别性能。具体的对比方法如下:
Bert[11]:使用Bert 对评论文本编码,对景点或景点属性进行情感分类。
Bert+KG:使用Bert 对评论文本编码,然后在表示层使用本文拼接知识表示的方法来融合知识信息,进而获得景点情感或景点属性情感的分类结果。
Bert+BiLSTM+ATT:使用Bert 对评论文本进行编码,通过BiLSTM 和注意力机制建模语义信息,然后对景点的情感或景点属性情感分别分类。
Bert+BiLSTM+ATT+KG:使用Bert 对评论文本编码,然后在表示层使用本文拼接知识表示的方法融合知识信息,通过BiLSTM 和注意力机制建模语义信息,对景点的情感或景点属性的情感进行分类。
KB-MJLCM(our model):在Bert+BiLSTM+ATT+KG 的基础上,将景点情感分类任务和景点属性情感分类任务联合起来,同时得到两个任务的分类结果。
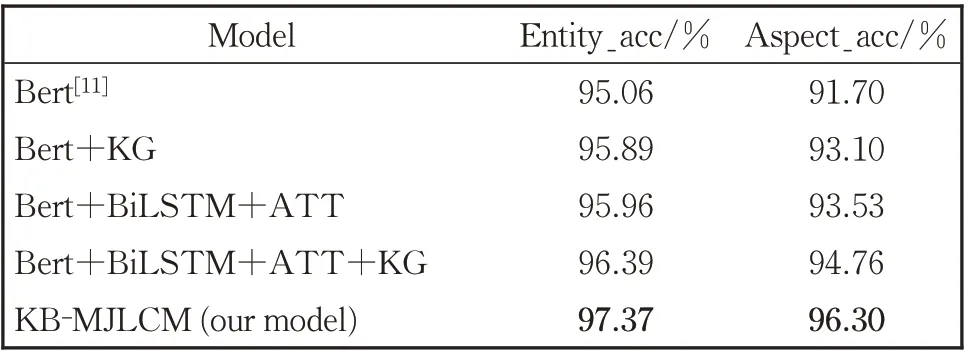
表5 景点知识库的作用验证实验结果Table 5 Experimental results to verify the function of scenic spot knowledge base
上述五种方法的对比实验结果可以看出:
(1)相比Bert,融合了知识表示的Bert+KG,在景点情感分类和景点属性情感分类的结果分别提高了0.83%和1.4%,说明Bert+KG 融合知识后丰富了景点实体的语义表示,有助于提升分类任务的性能。
(2)Bert+BiLSTM+ATT 把Bert 作 为em⁃bedding 层,使用BiLSTM 双向地捕捉较长距离的依赖关系,然后使用注意力机制来动态学习特征,可将注意力集中在重点词语上。由于旅游评论文本通常较长,而且通常包含着重要的情感词,因此,在Bert 基础上使用BiLSTM 和注意力机制可以学习到更加丰富的语义信息,在景点情感分类任务和景点属性情感分类任务上的准确率均有明显提高,分别提高了0.9%和1.83%。
(3)在Bert+BiLSTM+ATT 的基础上,使用本文的方法融合景点知识,整体性能略有提高,表明BiLSTM 和注意力机制能够有效挖掘文本特征,但加入知识信息仍能补充语义信息,对分类结果的准确率有一定的提升。
(4)本文提出的方法KB-MJLCM 不仅使用Bert 获得文本的向量表示,而且融合了景点知识表示,在此基础上,使用BiLSTM 和注意力机制学习文本特征,最后将景点情感分类和景点属性情感分类两个任务进行联合学习,在两个分类任务上分别达到了97.37%和96.30%的准确率,相较于Bert+BiLSTM+ATT+KG 性能均有显著提升,表明了在评论中表达的景点情感倾向和景点属性情感倾向有一定的关联,在联合学习过程中两个任务可以相互促进。
3.2.4 实例分析
为了更好地说明本文方法的有效性,选取以下山西旅游评论数据集中的真实景点评论。
例1,广仁王庙真正的古迹,国家级文物保护单位,但是地处郊区,宣传力度不够,游人稀少,而且不收门票,很厚道,守门的大姐人很友善。
例2,历史久远之名刹,古色古香之建筑,探古追幽法华寺。
从上述实例来看,例1 中提到景点“广仁王庙”是“真正的古迹”,通过融合其在知识库中对应的景点描述了解到该景点的历史意义,加强了景点实体的语义表示,对理解评论语义及判断情感倾向都有正面的意义。例2 中针对景点“法华寺”进行了评价,没有出现明确的情感词,但“法华寺”的景点描述详尽地介绍了其起源及建筑特点,融合这些外部知识信息可以有效地帮助机器理解评论的语义。
此外,我们列举了两组受到强烈主观影响的真实评论文本,如下所示。
例3-1,山里泉太远了,而且全程基本山路,开车比较费劲,但是山路里的景色还是非常美的,大自然的鬼斧神工。
例3-2,山里泉景区非常漂亮,有山有水,有风有云,特别漂亮。蓝天白云坐着船游玩,贴近自然,下火车不远就到了,交通非常方便。
例4-1,神秘有趣的3D 魔幻艺术展,立体逼真的效果很是吸引人,有搞怪版本,有幽默版本,有大自然清新版本。身临其境,趣味无穷!!适合休闲放松,带你进入一个新的世界!!推荐观赏!
例4-2,成年人就别去3D 魔幻艺术展了,骗钱的玩意儿,小孩儿看多了也觉得没意思了。所谓画展都是打印出来的。
从上述实例来看,例3-1 和例3-2 均为针对景点“山里泉”的评论,由于交通工具的差异导致对“交通”属性表达出截然相反的情感倾向,对景点的分析以及后续的问答系统、个性化推荐、舆情分析等任务造成了干扰,通过融合客观的景点描述信息,可以丰富景点实体的语义信息,更好地理解评论。例4-1 和例4-2 中对景点“3D 魔幻艺术展”的评价都带有强烈的主观性,表达的观点较为片面,融合知识库中客观的知识可以有效地减少过度主观因素的干扰,有助于真实地分析景点。
4 结论
由于知识库中包含了丰富的信息,尤其对于旅游领域的评论数据,景点本身蕴含着重要的信息,但机器无法自动学习这些潜在信息,可能会导致无法正确理解评论语义。本文通过在表示层引入景点描述知识,提出了基于BiLSTM 和注意力机制的旅游领域评论文本情感分类方法(KB-MJLCM 模型)。相比于传统的评论情感分类模型,本文使用外部知识信息来加强表示,在山西旅游评论数据上提高了准确率;而相比于其他的旅游领域的情感分类方法,本文考虑到了旅游评论的特点和难点,并将粗粒度的景点情感分类和细粒度的景点属性情感分类联合起来,在两个子任务上的都取得了较好的性能。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
意林·全彩Color(2018年7期)2018-08-13
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
海外星云(2016年7期)2016-12-01
第二课堂(课外活动版)(2016年2期)2016-10-21
Coco薇(2015年11期)2015-11-09
股市动态分析(2015年12期)2015-09-10
少儿科学周刊·少年版(2015年3期)2015-07-07
