
基于上下文的跨语言知识图谱实体对齐方法
2021-08-31 06:10聂铁铮马新月申德荣寇月
山西大学学报(自然科学版) 2021年3期
聂铁铮,马新月,申德荣,寇月
(东北大学 计算机科学与工程学院,辽宁 沈阳 110169)
0 引言
移动互联网崛起以来,信息呈爆炸式增长,大规模知识图谱(KG)层出不穷,导致各类知识图谱之间存在知识重复、知识间的关联不明确等问题,影响知识图谱在语义级别的综合集成。典型的多语 言 知 识 图 谱 有DBpedia[1]、YAGO[2]和Freebase[3]等,各知识图谱中包含大量的知识描述,但由于数据来源存在差异,很难构造一个包含全面事实的知识图谱。
实体对齐(Entity Alignment)在机器翻译、问答系统和信息检索等领域也被描述为实体匹配或实体解析。实体对齐任务的目标是识别出不同知识图谱之间指代对象为现实世界中同一事物的实体对。例如,在YAGO[2]知识图谱中,英文数据集中的“Louise_Élisabeth _of_France”和中文数据集中的“路易丝-伊丽莎白”,这两个实体有不同的名称,但它们都指向现实世界中的同一对象,因此它们属于可对齐的实体对。
分数概念的演变经历了四种途径,随之相伴的是人们对于数系的认识由整数系扩充为了有理数系.通过对分数演变顺序的分析,本研究提出了其对分数概念教学的一些启示,如教学实施的过程应分为四个具体阶段,在教学内容中应渗透比例思想、等价类思想,可将“测量”、“除法”两种分数产生途径作为数系扩充的重要教学点.
面向知识图谱的实体对齐技术可以实现知识的连接,将同类知识图谱融合为规模更大、质量更权威的领域知识图谱,为下游应用提供知识保障。知识图谱的实体对齐任务需要进行复杂的计算,传统的实体对齐方法通常采用基于实体的标签信息和基于人工定义特征的方法,不仅需要消耗大量的人力,而且很难迁移到实际的应用场景。
基于翻译模型的表示学习方法能够在低维稠密空间中学习实体的向量表示,以TransE[4]为代表的表示学习方法最开始用于单一知识图谱中实体的结构嵌入,其扩展方法TransD[5]、TransH[6]等在学习实体的嵌入表示的基础上,在统一向量空间中进行实体对齐或者实体推理,实体对在嵌入空间中的距离越接近,那么两个实体的语义相似度越高,知识图谱间实体对的可对齐的可能性越大。在知识图谱实体对齐领域,最近的研究以基于嵌入的方法为代表,MTransE[7]以翻译模型为基础得到各个知识图谱的嵌入表示,然后通过学习两个知识图谱之间的映射关系进行实体对齐。ITransE[8]在MTransE 的基础上添加了种子集迭代策略,新的匹配对为模型提供了更好的学习效果。BootEA[9]在JAPE 的基础上进行了改进增加了自举策略,避免了迭代增加种子集中的错误堆积。使用翻译模型的嵌入方法能够捕捉实体间的线性关系,但存在无法处理多关系图中复杂的关系信息、精确度低的问题,在实体对齐的场景下仍有一定的局限性。
近些年来出现的另一类实体嵌入方法是基于图卷积神经网络的嵌入方法。这种方法在三元组的维度上结合节点的属性信息进行复杂信息建模。R-GCN[10]添加关系矩阵来度量邻居实体对中心实体的权重表示,但由于参数过多,训练十分缓慢。DPGCNN[11]充分利用图的结构信息,构建一个以边为顶点、实体为边的对偶图,与原始图不断进行交互以进行复杂的关系表示。SEA[12]通过改进现有的嵌入模型,利用生成对抗网进行对抗训练,削弱节点的度对嵌入位置的影响。但普通的图卷积神经网络是对无向图进行操作,忽略了知识图谱中关系的语义信息和关系的指向信息。
还有一些方法在图神经网络的基础上添加了图注意力机制(GAT)[13],MRAEA[14]聚合实体的邻居来计算每个实体的嵌入表示,同时利用图注意力机制GAT 进行权重度量。中心实体的嵌入表示结合了结构信息和关系、实体的语义信息,这种方法存在的问题是仅考虑了中心实体的下一层邻居信息,忽略了上一层邻居节点对中心实体的影响,当中心实体没有任何传出信息时,很难为其匹配到相似的实体。
混合料装车运输时需合理安排施工机械,从而形成连续工作链。为防止装料时发生混合料离析,需派专人指挥采用三次装料法放料:遵循车厢前、后、中装料顺序。为防止运料车在运输过程中热料热量流失过快,应布置毡布裹附,同时在运输过程中应尽量减少车辆制动次数[3]。
为了验证基于上下文的实体对齐方法的有效性,我们实现了以下几种实体对齐方法与之进行比较,具体如下:
(1)利用基于词的Bi-LSTM 特征提取方法,构建包含上下文信息的中心实体的特征向量表示。
(2)实体嵌入层。与之前仅考虑传出关系的实体嵌入方式不同,本文的实体嵌入过程在现有方法的基础上结合中心实体的传入邻居,即上一层邻居信息,丰富中心实体的特征向量表示,从而影响实体在低维空间嵌入的位置。为了对传入邻居与传出邻居进行划分,添加超参数β 来平衡邻居类别的重要程度,实体的初始化向量表示的计算方式如下:
(2)提出一种新的实体嵌入方法,该方法结合图注意力机制有效地对知识图谱内的中心实体的上下文建模,实体的嵌入表示结合了所有相关的邻居节点和关系信息。
情,但是面对大量不认识的词汇和短语,往往找不到有效的方法,寻找不到规律,显得有点束手无策。相对而言,大二年级的学生由于在大一期间,有了一定的积累,同时为着备考英语四、六级做准备,词汇量有了一定的增长,但是词汇混淆度比较高,如何准确区分词汇的差别,以及部分单词出现记了又遗忘的现象。大三大四的学生由于通过四级考试后,没有保持继续学习的状态,英语水平反而更加下降,在词汇和词汇丰富度上存在种种问题。词汇量少,词汇容易混淆始终是困扰大学生英语学习的通病问题。
(3)实现了仅使用少量的种子集作为训练数据,降低手动标记数据的成本,同时减少训练中需要手动调整的超参数的数量,提高模型对不同数据集的鲁棒性。
1 模型构建
1.1 基于上下文的实体嵌入表示方法
本文主要关注跨语言知识图谱的实体对齐方法,模型的总体框架如图1 所示,先根据词嵌入来分别对两个知识图谱中实体和关系信息进行语义编码,利用Bi-LSTM[15]得到节点和关系的初始化特征表示,接着利用图注意力机制进一步处理实体的嵌入表示,捕获每个三元组中的内部依赖性及邻居节点对中心实体的重要程度,最后利用基于距离的度量函数进行实体对齐。
由于是在固定区域内施加均布载荷,在传感装置中质量块的质量不变的条件下,可将施加的载荷等效为加速度的变化。因此通过施加不同大小的载荷,得到对应的在施加载荷方向上的位移量与加速度之间的关系,结果如表2所示,PDMS薄膜等效位移与所受到的激励呈线性变化关系。

图1 基于上下文的跨语言知识图谱实体对齐方法总体框架Fig. 1 Framework of the approach of entity alignment based on context for cross-lingual Knowledge Graph
(1)特征提取层。这一层的目标是通过基于词的Bi-LSTM 来学习三元组中的实体和关系的初始化嵌入表示。传统的长短期记忆网络可以捕获输入序列的长期依赖,Bi-LSTM 在LSTM 的基础上充分考虑词的上下文信息,从而得到更深层次的双向语义特征向量表示。
受以上内容的启发,本文提出了一种基于上下文的跨语言实体对齐方法,通过中心实体的上下文信息来解决前期工作的缺陷。本文的主要贡献如下:
下面来详细说明特征提取过程:
实验结果表明,均匀设计法实验得到的ITAE相较于工程整定法更小,稳态性能较好。输出波形图表明,均匀设计法得到的输出曲线与工程整定法相比,超调量、调节时间均有降低,系统的暂态性能有所提高。


其中ReLU 是激活函数,αij为注意力相关系数,N+i和Ni为实体ei的两类邻居节点。
利率市场化赋予商业银行自主定价权,加剧了市场竞争,提高了利率风险。利率定价关乎商业银行应对风险的能力,以及巩固甚至提升市场地位的水平,所以是至关重要的。有效预见未来利率趋势,精确计算利率定价,提出或确定方案不仅需要大量数据,建立数据库,还需要高素质的专业人才对数据进行筛选分析,构建模型。在风险控管方面,除了要牢牢把握市场动向,还要善于把控贷款业务风险,通过投资转移、分散风险,加强商业银行内部的管理。商业银行内部管理,往往能决定该行能否稳健经营。如何保持经营环境良好、工作人员廉洁、决策执行高效也是商业银行长期要面临的问题。
此前,中国家用电器研究院曾对FPA(斐雪派克)电机和普通电机作对比测试,在止逆阀半开,模拟公共烟道高风压状态,以用户常用的中、低速运行,测试后的数据显示,应用了FPA(斐雪派克)变频电机的海尔风幕8°油烟机,噪音相比普通油烟机低了5分贝左右,减轻用户头顶的噪音困扰。该项领先技术实力支撑了海尔厨电在市场上的主导地位。
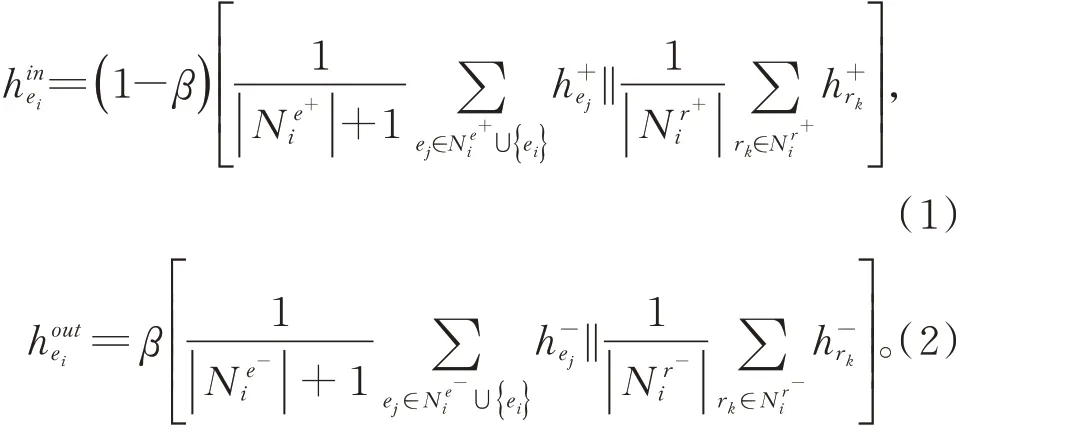
在上述公式中,将实体关联的关系向量和邻居实体向量的平均值作为新的节点表示,||和|分别表示实体ei关联的实体集和关系集的元素个数,表示中心实体ei的上一层邻居的节点嵌入表示,表示下一层邻居的节点嵌入表示,β是平衡邻居类别的超参数。
实体ei与邻居实体间的关系的注意力分值使用公式(3)、(4)来计算:
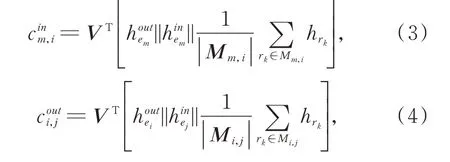
为了将注意力系数分配到节点ei的邻居节点中,引入逻辑回归模型对相邻的节点进行正则化,公式(5)和公式(6)分别为中心节点的上一层邻居和下一层邻居的注意力权重系数的计算公式:

在获得两个知识图谱中所有实体的最终特征向量表示后,计算向量空间中所有实体对之间的距离来进行实体对齐,将每一个实体嵌入向量与另一个知识图谱中所有的实体嵌入向量之间的距离做比较,利用公式(8)计算两个实体之间的距离。

3)根据关系的指向,将中心节点的邻居划分为传入邻居和传出邻居,传入邻居的初始特征用表示,传出邻居的初始特征用表示。
1.2 实体对齐
其中LeakyReLU 是泄露修正线性单元,利用节点间的注意力系数和非线性激活函数可以得到实体ei的输出特征:
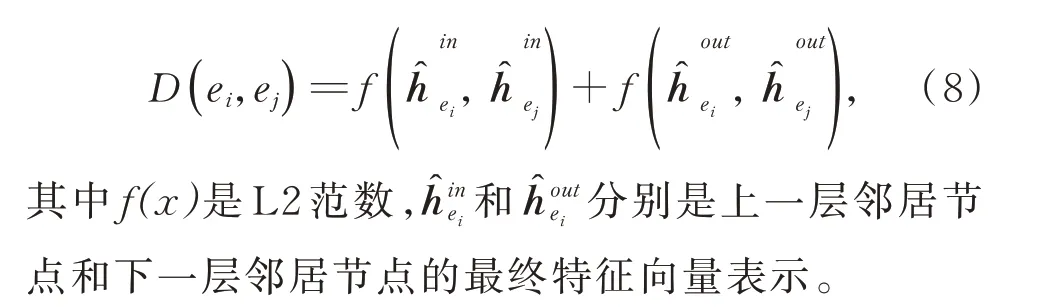
对于知识图谱KG1中的特定实体ei,分别计算ei与KG2中所有实体之间的距离,从距离排序列表中选择候选匹配实体,距离越近的实体越相似,在候选匹配列表中的排名越靠前。
1.3 模型训练
为了使两个知识图谱中相同的可对齐实体在向量空间中的距离尽可能地接近,本文利用基于距离排序的损失函数进行模型训练:

2 实验结果
2.1 数据集
为了验证本文方法的精确性和鲁棒性,使用常用的多语言的知识图谱数据集DBP-15K[17]和大规模 数 据 集DWY100K[18]。DBP-15K 数 据 集 由DB⁃pedia 构建,包含三种语言且涵盖丰富的关系信息和实体链接,其中,ZH-EN 数据集代表中文-英文数据集,JA-EN 数据集代表日文-英文数据集,FR-EN数据集代表法文-英文数据集。DWY100K 包含两个从DBpedia、Wikidata 和YAGO3 提取的大规模数据集。表1 给出了数据集详细的统计信息。在实验中,已知的等效实体对作为实体对齐方法执行过程中的种子集。
从前期各地的实践看,对PPP项目流程执行各不相同,存在许多不按照规范要求执行的情况。自2017年以来,相关部门相继出台各项政策,对PPP项目进一步规范,5大环节、19个节点仍为判断PPP项目是否合规的重要依据。
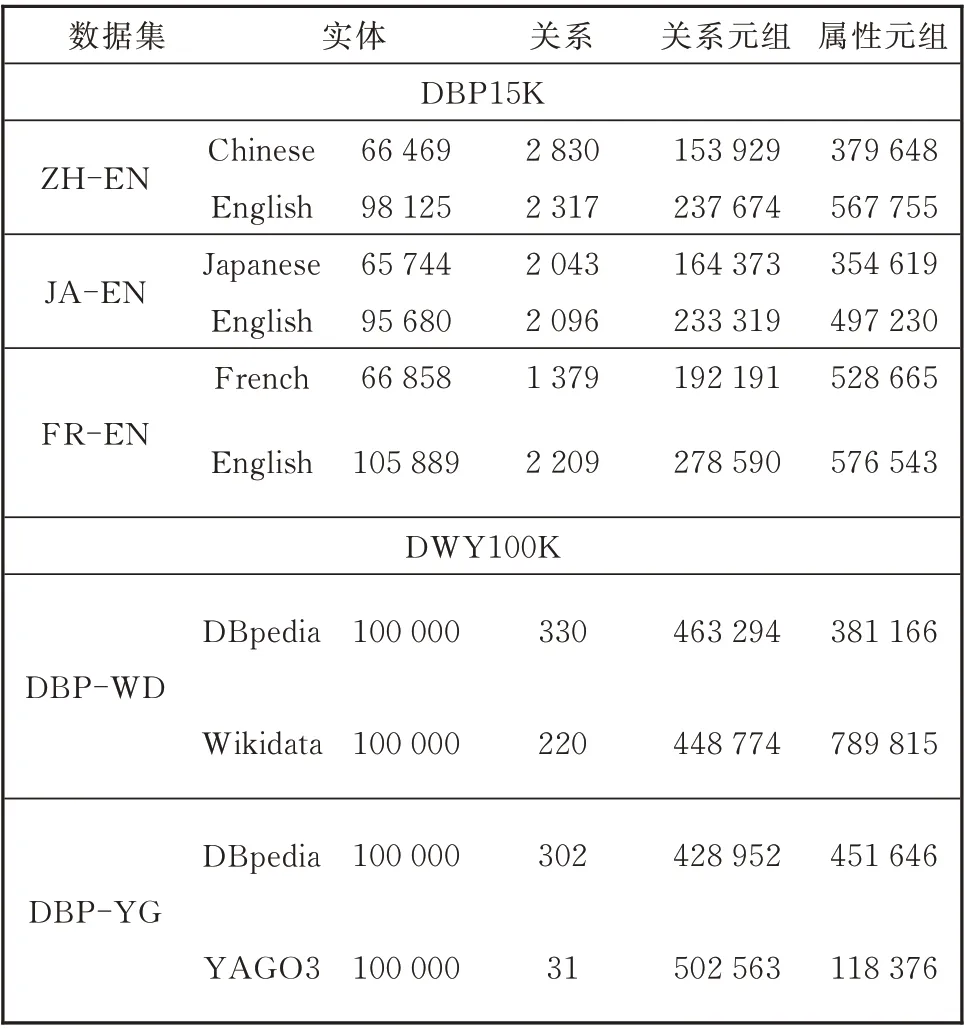
表1 DBP15K 和DWY100K 数据集的详细统计信息Table 1 Statistics of datasets DBP15K and DWY100K
2.2 对比方法
where Pais the power requirement to meet the actuator movement.
(1)基于翻译模型的方法。MTransE[10]将单个嵌入空间中的实体迁移至统一嵌入空间进行实体对齐。ITransE[8]添加了种子集迭代策略和参数共享策略。
(2)基于图卷积网络的方法。JAPE[17]对知识图谱中的结构信息进行建模,同时将属性信息合并到基于嵌入的实体对齐中。GCN-Align[19]为GCN的变体,使用关系矩阵对结构和属性建模,以发现不同的关联关系。
2.3 实验设置
为了与以前的工作进行公平的比较,采用相同的数据拆分方法和评估指标。将预对齐实体对中的70%随机分配为训练的种子数据,余下的30%用于测试。使用Hits@k 和平均排列等级(MRR)作为评估指标,Hits@k 衡量正确对齐的实体在前k个候选者排名中出现的比例,MRR 指的是查询结果平均排名的倒数。将模型的3 次独立运行的平均值作为最终效果。
实验的默认设置为:特征向量的嵌入维度为300,超 参 数β=0.6,==1.0,学 习 率 为0.001,负采样样本数K=125。
2.4 实验结果
表2、表3 为在DBP15K 和DWY100K 数据集上进行实体对齐实验的执行结果。

表2 KEGA 在DWY100K 数据集上的实体对齐对比实验结果Table 2 Entity alignment compare results of KEGA on the DWY100K dataset
3 分析与讨论
从表2、表3 中可以看出本文使用的基于Bi-LSTM 模型和图注意力机制的实体对齐方法对比之前的方法有一定的提升。这表明Bi-LSTM 可以获得三元组之间的关联特征,注意力机制可以利用邻接实体和关系加深对中心实体的嵌入表示,将两种方法结合起来可以挖掘出更多的实体间潜在的关联关系。

表3 KEGA 在DBP15K 数据集上的对比实验Table 3 Entity alignment results of KEGA on the DBP15K dataset
实验结果表明,在两类评估数据集上本文的方法KGEA 的性能优于以前的方法,结合图注意力机制对中心实体的上下文建模确实可以带来更好的改进效果,这充分说明在知识图谱实体对齐任务中利用丰富的结构信息和元语义信息的重要性。
爱思唯尔在提供服务的同时,在选稿、审稿方面有专家团队严格把关,坚持保证质量、可信度,每年向其投稿的稿件,只有不到三分之一被出版。
在DBP15K 数据集上使用不同比例的先验种子集进行实体对齐,以验证种子集数目对实体对齐结 果 的 影 响。图2(a-c)显 示 了GCN-Align 和KGEA 的实验对比结果。
图2(a-c)中x轴是用于对齐的种子集的比例,y轴是Hits@1 分数。从图中可以看出,在所有的数据集中,KGEA 的性能均优于GCN-Align,这表明KGEA 可以利用更加详细的实体关联信息进行嵌入表示。即使种子集比例较小,本文的方法也能取得良好的效果。例如在DBP15KJA-EN数据集中,当种子集比例为10%时,Hit@1 也可以达到53.4,且当种子集比例为50%时,KGEA 比GCN-Align 的Hit@1 得分高出13.5%,进一步证实了本文方法的鲁棒性。
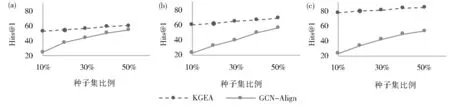
图2 不同种子集大小在DBP100K 数据集上对实体对齐方法KGEA 和GCN-Align 性能的影响(a~c)(a)ZH-EN;(b)JA-EN;(c)FR-ENFig. 2 (a),(b)and(c)show the performance of KGEA and GCN-Alignment using different proportions of prior entity alignment on the DBP15K datasets(a)ZH-EN;(b)JA-EN;(c)FR-EN
4 结论
本文提出了一种新的基于上下文的知识图谱实体对齐方法,通过探索中心实体周围的复杂关联信息来学习实体嵌入。利用Bi-LSTM 模型和图注意力机制构造相邻的关系信息和结构信息,更好地学习实体的向量表示来实现实体对齐。本文通过实验将所提出方法与现有相关方法进行对比,实验结果表明本文的方法在三个多语言知识图谱数据集和两个大规模数据集中均取得了最好的实体对齐效果。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
小雪花·成长指南(2022年1期)2022-04-09
当代陕西(2019年5期)2019-03-21
新城乡(2018年6期)2018-07-09
21世纪商业评论(2018年3期)2018-03-02
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
第二课堂(课外活动版)(2016年2期)2016-10-21
领导科学论坛(2016年9期)2016-06-05
中国报道(2009年12期)2009-01-15
