
基于SURF特征的汽车轮毂型号识别
2021-08-26 10:51侯永涛黎良臣顾寄南冒文彦
机械设计与制造 2021年8期
侯永涛,黎良臣,顾寄南,冒文彦
(1.江苏大学机械工程学院,江苏 镇江 212000;2.江苏大学机械工程学院,江苏 镇江 212000)
1 引言
随着工业4.0和中国制造2025的相继提出,智能制造成为了制造业领域的热门话题。如何将近年来涌现出的一大批智能算法运用到传统的制造业中,并使其发挥出超越常规方法的能力,成为了越来越多学者的研究课题。机器视觉技术作为自动化、智能化生产的一项关键技术,是未来实现无人化工厂的重要基础。
物体识别,在传统机器视觉技术中都是通过模板匹配的方法来实现的。而模板匹配又大致可分为:基于灰度值的模板匹配,基于边缘的模板匹配,基于形状的模板匹配以及基于角点、特征点的匹配[1]。这些方法共同的特点就是对图像的质量要求高,易受环境噪声的影响。
轮毂是汽车的重要零配件,随着汽车产量的扩大,轮毂的需求量也日益增加。在自动化生产线上要实现多品种轮毂的混流生产,首先要完成的就是轮毂型号的识别[2]。文献[2]通过检测轮毂的三个物理量并构造了四个位置、旋转不变量,以此作为图像识别的特征,最后利用投票分类器来识别轮毂型号。文献[3]选取了轮毂七个旋转不变的物理量,以此作为图像识别的特征。以上两种方法相似,都需要严格的应用环境来保证图像质量,以便于图像处理获得特征。另外,当两种轮毂物理量相似时,会对识别产生干扰。文献[4]利用轮辐的边缘作为模板进行匹配,并增加了轮毂图像纹理对比的步骤,从而减少了误识别的几率。但是边缘匹配只能适应小范围的光照变化,此外,该方法的实时性也是一个问题。文献[5]提出一种在遮挡、杂波和不同光照下具有不变性的通用匹配算法。该算法对应用环境有很强的适应性,但是面对体型较大、形状各异的轮毂时,制作模板、处理图像都会变得十分复杂。
综上所述,用传统的方法来识别轮毂型号是十分复杂的,且易受环境影响,可靠性不佳。针对轮毂自身的特点,这里的将采用轮毂图像的SURF特征与神经网络相结合的方式来识别轮毂型号。该方法既具有SURF算法的优良特性,又具有神经网络容错能力和学习能力强的特点。
2 图像SURF特征的提取
文献[6]提出了一种提取图像尺度不变特征点的算法即SIFT(Scale Invariant Features Transform)算法。SIFT特征对旋转、尺度缩放具有不变性,对光照变化也不敏感。文献[7]进一步改进了SIFT算法,形成了SURF算法。SURF特征(Speeded-Up Robust Features)在保持了SIFT特征优良特性的基础上,解决了SIFT算法计算复杂度高、耗时长的缺点。这就为实时识别提供了有力的支撑。
SURF特征是一种典型的局部特征,提取图像的SURF特征主要分为五个步骤。
(1)计算图像中每个像素的Hessian矩阵行列式的近似值。公式为:

其中,D xx、D yy、D x y是将高斯二阶导数模板用盒子滤波器代替后与原图像卷积得到的结果。以9×9模板为例,如图1所示。图中灰色像素代表0,上图是y方向高斯二阶求导的近似表示,下图是高斯二阶混合偏导的近似表示。另外,Bay H还引入了积分图像的概念,进一步提高了计算效率。
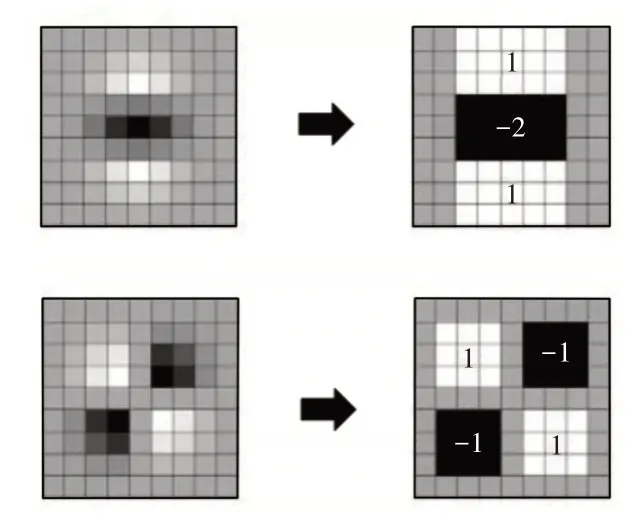
图1 将高斯二阶导数模板用盒子滤波器代替Fig.1 Replaces Gaussian Second Derivative Template with A Box Filter
(2)构造尺度金字塔。相比于SIFT算法,SURF算法没有降采样过程,图像的大小保持不变,改变的是高斯模糊模板的尺寸和尺度。
(3)定位特征点。如图2所示,将经过式(1)处理过的每个像素点与其3维邻域的26个点进行比较,如果该点为极值点,则作为初步的特征点。然后,采用3维线性插值法得到精确的特征点。

图2 特征点的初定位Fig.2 Initial Positioning of Feature Points
(4)确定特征点的主方向。特征点主方向的确定是使SURF特征具有旋转不变性的关键。以特征点为中心,半径6S(S为特征点所在的尺度值)划定一个圆形区域,每60°统计扇形内所有点在x和y方向上的Haar小波响应值(Haar小波边长取4S),再给这些响应值乘以高斯权重系数,使得越靠近特征点的权重越大,然后将这些响应值相加得到一个矢量,最后取所有扇形区域得到的矢量长度最长的作为该特征点的主方向。
(5)构造特征描述子。在特征点的周围划定一个边长为20S的正方形区域,该正方形的一边与特征点的主方向垂直。如图3所示,将正方形区域划分为16个子区域,然后计算每个子区域中所有像素点在x和y方向的Haar小波响应,再将x、y方向的响应值以及响应值的绝对值分别相加获得4个值,公式为:

图3 特征描述子的构造Fig.3 Structure of Feature Descriptor
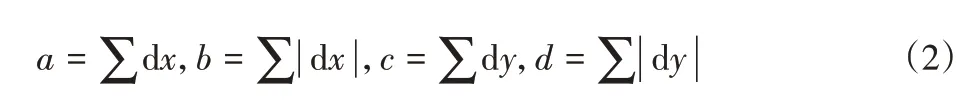
因此,特征点即可用一个4×16=64维的向量来表示。
3 搭建神经网络
由于轮毂型号有多种,采用的分类算法必须具备多类别的分类能力。而神经网络作为常用的分类算法,具有容错能力、学习能力强的特点,适合多类别分类的问题。神经网络的本质是使用大量的基本非线性计算单元(称为神经元),这些单元以网络的形式进行组织,就像大脑中神经元的互连那样[8]。神经网络一般分为输入层、隐含层和输出层。一般情况下,一个三层的神经网络就能训练出一个合适的分类器来解决分类问题。如图4所示,这里的将提取出的轮毂图像的SURF特征作为神经网络的输入,将轮毂型号作为输出,经过一定量样本图像的训练,从而训练出一个合适的分类模型。

图4 神经网络的搭建Fig.4 Construction of Neural Network
针对如何用提取出的轮毂图像的SURF特征作为图像的表征,从而用于神经网络的训练。这里的将提取出的SURF特征点按照每个特征点的强度值即由式(1)得到的值,从大到小进行排序。假设每张图像提取m个SURF特征点,则每张图像可表示为:

因为每个特征点是由一个64维的向量来表示的,所以将每个特征点的描述向量按照式(3)的顺序连接成一个向量,就可以以此来表征图像。因此,输入层的神经元数就是64m个;输出层的神经元数就是所需分类的类别数n;而隐含层的神经元数由经验式(4)确定。

4 实验与分析
这里的以三种型号的轮毂为例,采集了强光、正常光、弱光下轮毂在传送带上的图像。A、B、C三种型号轮毂的灰度图,如图5所示。图像大小为756×756。实验方案,如图6所示。识别算法基于MATLAB R2016a平台实现。实验所用的计算机配置:In⁃tel Core i3-2310M处理器,频率:2.1GHz;NVIDIA GeForce GT 520M显卡;4G运行内存。

图5 三种型号轮毂的灰度图像Fig.5 Gray Image of Three Types of Hub

图6 实验方案流程图Fig.6 Experimental Scheme Flow Chart
实验中,每种型号轮毂各采集了90张图像。根据文献[9]提取SIFT特征点来识别汽车标识时,每张图像所提取的特征点数,对每张轮毂图像提取了100个SURF特征点,这些特征点也基本能够覆盖轮毂的关键部位,能够充分表达各型号轮毂图像的特点。因此,神经网络输入层的神经元数即为:6400;输出层的神经元数即为:3;由式(4)可知隐含层的神经元数即为:85(β取5)。另外,A型轮毂在输出层以[1 0 0]表示,B型轮毂以[0 1 0]表示,C型轮毂以[0 0 1]表示。
实验中,将所有样本分成了训练集、验证集和测试集,每个集合依次占70%、15%、15%,结合总的图像数即训练集:188张、验证集:41张、测试集:41张,且都是随机抽取。其中验证集是用来衡量网络的泛化能力,在泛化能力无法继续改善时停止训练,防止过拟合。神经网络采用量化共轭梯度反向传播法[10]来更新网络的权值和偏差值;采用交叉熵来衡量网络的性能。
经过训练、验证和测试,得到了一个最佳的识别模型,该模型的性能随训练过程的变化,如图7所示。模型在第47代时获得最佳验证性能,交叉熵值约为:0.0044。利用该识别模型对更多A、B、C三种型号的轮毂图像进行了识别,得到了三种型号轮毂的平均识别准确率和一次识别所需要的时间,并与其它方法进行了比较结果,如表1所示。其中,多参数匹配方法和形状匹配及纹理筛选方法的识别准确率和识别时间分别由文献[2]和文献[4]得到。

图7 模型的性能随训练过程的变化Fig.7 Model Performance Changes with Training Process

表1 识别的准确率和时间消耗Tab.1 Identification Accuracy and Time Consumption
5 结论
(1)这里的利用SURF特征对光照不敏感、抗干扰性强以及神经网络容错能力、多类别分类能力强的特点,实现了对多种型号汽车轮毂的识别。(2)工业环境中,比如在传送带、辊道等这些单一背景下,这里的的识别方法具有很高的准确率;并且能够容忍轮毂表面的金属反光和背景中的噪声;另外,从每次识别所需的时间来看,完全能满足实时性的要求。(3)但是这里的的识别方法十分依赖神经网络对数据信息的学习,即没有经过训练的型号是无法识别的。这与传统模板匹配必须事先制作某一型号轮毂的模板才能识别该型号轮毂一样。
猜你喜欢
上海涂料(2021年5期)2022-01-15
机械工业标准化与质量(2021年10期)2021-11-19
科教导刊·电子版(2021年1期)2021-03-28
航天工业管理(2020年11期)2021-01-04
航天工业管理(2020年9期)2020-12-28
环境与发展(2019年11期)2019-02-12
山东化工(2019年1期)2019-01-24
制造技术与机床(2017年10期)2017-11-28
制造业自动化(2017年2期)2017-03-20
铁道通信信号(2016年8期)2016-06-01
