
数据流环境下的关键词轮廓查询算法
2021-08-24 03:06宋栿尧夏秀峰
小型微型计算机系统 2021年9期
宋栿尧,朱 睿,张 豪,邱 涛,夏秀峰
(沈阳航空航天大学 计算机学院,沈阳 110135)
1 引 言
轮廓查询是多维数据管理中的经典问题,它通过用户偏好帮助用户从大量信息中提取有用信息,在许多应用中发挥着重要作用.近年来,随着科技、互联网技术的不断发展,数据的来源和生成形势日益多样化,产生了大量文本数据.不同于传统的数值型数据,它们由标准属性和文本属性两部分构成.其中,标准属性包括结构化数据,如数值型数据,而文本属性包括非结构化数据,如标签、评论等.和结构化数据相比,非结构化数据能够提供更丰富的语义情感信息并且更好地表达用户的个人偏好,因此结合文本信息的轮廓查询,即关键词轮廓查询已经成为越来越流行的热点问题.
给定d维数据集合D中的两个对象o1,o2,如果o1在任意维度上的表现都不比o2差,且至少在一个维度上表现优于o2,则称o1支配o2(记为o1o2).D中所有不被其他对象所支配的对象组成的集合称为D所对应的轮廓集合,记为SK.而关键词轮廓查询和传统轮廓查询有所不同,对于d维数据集合D,其中每一条记录o均可以由二元组
下面举例来说明轮廓查询与关键词轮廓查询的区别.用户在社交网络平台上浏览评论信息时,通常更加关注发言用户等级较高且位置与自己更接近的评论信息.如图1(a)所示,图中x坐标表示发言用户的等级,y坐标表示发言用户与浏览用户之间的距离.给定数据集合D={o1,…,o8},o1~o8分别代表8条评论,由于o1、o2、o4和o5这4个对象在所有维度上的表现都不差于其他对象,且至少在一个维度上的表现比其他对象要好,即它们不被其他对象所支配,因此,这4条评论构成了轮廓集合SK.而当我们给定查询词kw时,得到的查询结果与SK不同.如图1(b)所示,当我们给定关键词kw=k4时,由于对象o2的文本属性中只包含关键词k2和k3,而不包含关键词k4,因此o2不是关键词轮廓对象.而对象o3虽然不是D所对应的轮廓对象,但它包含关键词k4,且不被其它包含关键词k4的对象所支配,因此它是D所对应的关键词轮廓对象.也就是说,当给定关键词k4时,数据集D所对应的关键词轮廓集合KSK={o1,o3,o4,o5}.通过观察,我们不难发现,关键词轮廓查询和传统的轮廓查询均是通过对各维度属性进行比较来选取最优点的集合,但由于关键词轮廓查询引入了文本属性,因此需要考虑对象与关键词之间的匹配关系,这导致了其在查询方法以及查询结果上均与传统的轮廓查询有所不同.

图1 传统轮廓查询与关键词轮廓查询
随着科技的不断发展,流数据逐渐成为当前的主流数据类型之一.和传统数据类型相比,它具有数据规模大、速度快、变化频繁等特点,这使得研究面向数据流环境下的关键词轮廓查询问题具有重要意义.例如,在社交网络平台上,随着用户不断评论、留言,评论信息实时更新,而用户在浏览这些评论信息时,通常只关注当前最新的评论信息.因此,算法可针对最新的评论信息进行分析,将包含用户给定关键词并且各项属性表现比较好的评论信息实时推荐给用户.
不失一般性地,本文基于滑动窗口模型展开研究.给定滑动窗口W
目前,许多学者[1-5]对于流数据环境下的轮廓查询展开了研究,而其中还没有算法引入关键词属性.其原因在于:关键词轮廓查询由两个独立的步骤构成,即首先使用给定关键词集合kw过滤出文本属性中包含kw的对象集合,再在此对象集合之上进行轮廓查询.由于中间结果与关键词相关,因此无法有效地构建索引来维护关键词对象.此外,随着大数据时代的到来,数据量急剧增长,如何对流数据中的关键词对象和轮廓对象进行有效维护也是一个需要解决的问题.
本文首次提出查询处理框架PCKSWI(Partition-based Continuous Keyword Skyline with Index)来支持数据流环境下的关键词轮廓查询.具体地,给定滑动窗口W0,PCKSWI将W0划分成m个不相交的子窗口{P0,P1,…,Pm-1},分别过滤出每个子窗口中包含关键词集合kw的对象集合LK={LK0,LK1,…,LKm-1}.随后,本文分别在每个分片中利用查询关键字集合过滤与之无关的对象,并针对剩余对象计算该分片中的轮廓对象,得到最终各分片的局部关键词轮廓对象集合LKS={LKS0,LKS1,…,LKSm-1}.分片的好处在于:对于任何一个分片Pi,Pi-LKSi中的对象在Pi成为窗口中的第一个分片前都不会成为查询结果.换句话说,算法只需维护{P1,…,Pm-1}中的局部关键词轮廓对象和P0中的候选关键词轮廓对象便可支持查询,这可有效避免维护所有候选关键词轮廓对象给算法性能带来的影响.当Pi成为窗口中的第一个分片时(此时窗口为Wi),算法可利用Wi-Pi中的关键词轮廓对象高效筛选Wi-Pi中的非关键词轮廓对象.因此,PCKSWI可有效降低候选轮廓集合规模,降低总体查询代价.
本文主要贡献如下:首先,提出了一种分片策略,其按照对象到达时间对窗口进行划分,根据划分后得到的性质过滤掉大部分不可能成为查询结果的对象,从而克服了数据间时序关系对算法性能带来的影响.其次,提出了一种基于多分辨率网格的关键词轮廓网格索引(Keyword Skyline Grid,KSG)用来维护各分片中的对象.该索引一方面利用网格来有效过滤出窗口中的关键词对象,另一方面可利用关键词对象中的轮廓对象和网格单元格的关系高效计算出窗口中的关键词轮廓对象.最后,分析了分片粒度的设置,通过对分片粒度进行合理设置,提高了PCKSWI的整体效率.
2 相关工作
轮廓查询是多维数据管理领域中的经典问题,轮廓查询及其变种已被大量学者深入研究.和本文相关的研究包含两类:1)滑动窗口模型下连续的轮廓查询;2)关键词轮廓查询.下面,本节对这两类研究进行介绍.
2.1 滑动窗口模型下连续轮廓查询.
Lin等人[1]最早提出了基于滑动窗口的轮廓查询的概念,并提出了n-of-N轮廓查询算法.该算法利用一个间隔树来维护窗口中的各个对象,记录对象成为轮廓查询结果的时间段,从而快速计算出任意时间段对应的轮廓集合,因此只需通过维护滑动窗口中少量数据即可完成滑动窗口上轮廓集合的计算.Tao等人[2]提出了两种算法框架Lazy和Eager用于持续监测滑动窗口中的轮廓对象,算法引入数据的时间属性,利用R-Tree索引管理流数据,并删除其中不可能成为查询结果的对象,从而降低了计算代价.Morse等人[3]提出了LookOut算法,它采用改进的四叉树索引来对数据进行维护,该索引具有比R-Tree索引更高效的维护效率.Tang等人[4]提出了kdStreamSky算法,它基于kd-Tree索引,采用事件链机制来处理数据点的状态变化,能够更快地响应用户的查询要求.Ren等人[5]针对不完整数据流展开研究,提出了算法Sky-iDS,从不完整数据流中检索具有高可信度的轮廓对象,通过差异依赖规则来填充不完整数据流中对象的缺失属性.
这些查询算法普遍存在的问题是没有考虑对象的时序关系对查询效率带来的影响.即一个对象是否会成为候选轮廓对象由其在各维度的表现情况以及其到达顺序共同决定.例如:对象o1能够支配对象o2,且o1的到达时间晚于o2,则o2不会成为候选轮廓对象.极端情况下:窗口中最后一个到达的对象无论其在各维度的表现如何,由于其到达顺序最晚,它仍为候选轮廓对象.因此,提出一种算法,通过利用对象的时序关系来对候选集合进行合理筛选,对解决上述问题具有重要的理论意义.
2.2 关键词轮廓查询
Choi等人[6]提出了基于倒排索引的关键字轮廓查询算法(INverted-index-based Keyword Skyline algorithm,INKS),其首先通过倒排索引得到包含关键词的数据集合,之后使用环算法[7](Block-Nested-Loop algorithm,BNL)计算出其对应的轮廓集合.另外,他们还提出了优化的关键词匹配轮廓算法(Keyword-Matched Skyline algorithm,KMS),该算法基于R-Tree索引和签名文档过滤,在维度较低的情况下,具有较高的计算效率.Regalado等人[8]通过计算用户输入的关键词与对象的关键词之间的相关性,并以此作为标准维度来进行轮廓计算.Chen等人[9]将社交关系应用到关键词轮廓查询中,提出了基于社交的空间文本轮廓查询算法(Social-based Spatial-textual Skylinealgorithm,SSTS),并引入了新型函数来计算SSTS的社交相关性;在此基础之上,他们通过有效的剪枝策略对SSTS进行扩展,并提出了了受限的基于社交的空间文本轮廓查询算法(Constrained Social-based Spatial-textual Skylinealgorithm,CSSTS).Li等人[10]提出了空间关键词轮廓查询算法(Spatial Keywords Skyline algorithm,SKS),引入了最小值过滤等策略,并提出了一种索引结构STR-Tree,将空间区域信息与对象文本信息相结合,快速过滤掉与查询无关的区域,进一步提升了查询效率.
目前被提出的这些查询算法都是针对于静态数据所展开的,在流数据环境下,它们均无法有效地解决关键词轮廓查询的问题.因此,提出一种增量算法,使得其能够在数据流环境下高效维护当前窗口中的关键词轮廓集合,具有重要的理论意义和应用价值.
3 问题分析及定义
在本章,我们首先介绍了轮廓集合和关键词轮廓集合的相关概念,之后,正式介绍问题定义.
定义1.(轮廓集合)给定d维数据集合D,∀o1,o2∈D,如果o1在任意维度上的表现都不比o2差,且至少在一个维度上表现优于o2,则称o1支配o2(记为o1o2).对于D中任意对象o,如果D中不存在其他对象支配o,则称o为轮廓对象.D中的所有轮廓对象组成了轮廓集合,记为SK.
如图1(a)中所示,给定数据集合D={o1,…,o8},其所对应的轮廓集合SK0={o1,o2,o4,o5}.
定义2.(关键词轮廓集合)给定d维数据集合D,D中每一条记录o可以由二元组
如图1(b)中所示,给定数据集合D={o1,…,o8},以及关键词kw=k4,其所对应的关键词轮廓集合KSK={o1,o3,o4,o5}.
定义3.(连续的关键词轮廓查询)设W为规模为N的查询窗口,查询q
如图1(b)中所示,给定当前窗口W0对应的对象集合O0={o1,…,o8},窗口流速s=2,以及关键词kw=k4,其所对应的关键词轮廓集合KSK0={o1,o3,o4,o5}.在窗口经过一次滑动之后,对象o1和o2离开窗口,o9和o10进入窗口.如图1(c)中所示,此时当前窗口W1所对应的关键词轮廓集合更新为KSK1={o3,o4,o5,o10}.
4 查询处理框架PCKSWI
本章提出一种带索引的基于分片技术的算法框架PCKSWI(Partition-based Continuous Keyword Skyline with Index)来支持连续的关键词轮廓查询.它根据窗口中对象的到达顺序将窗口划分为若干个子窗口,之后,之后计算出各子窗口中的局部关键词轮廓集合,并在此基础之上计算出全局关键词轮廓集合.根据分片的性质,该算法可以过滤掉大部分不会成为查询结果的对象,实现查询在数据流环境下的高效维护.为帮助PCKSWI高效计算各分片的关键词轮廓对象,本章提出了关键词轮廓网格索引(Keyword Skyline Grid,KSG)来管理各分片中的数据.此外,为了提高各分片的查询效率,我们通过分析找到了一个适合的划分粒度.
4.1 框架概览
4.1.1 PCKSWI框架的基本思想
给定窗口W,我们将其划分为m个分片{P0,P1,…,Pm-1}.对于每一个分片Pi,我们使用一个索引Ii来维护其中对象,并从中选择局部关键词轮廓对象来作为候选关键词轮廓对象.这里,索引Ii的构建将在4.2节中详细介绍.此外,令LKSi为分片Pi的局部关键词轮廓对象,其满足∀o∈LKSi,o的文本属性中包含给定关键词集合kw且o不被任意文本属性中包含kw的对象所支配.
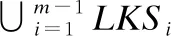
4.1.2 PCKSWI的增量维护算法
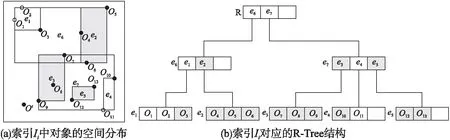
下面正式介绍基于分片技术的增量维护算法.给定窗口W,及其所对应分片{P0,P1,…,Pm-1},索引Is维护CL中的所有局部关键词轮廓对象.我们首先构建一个新的分片Pm来维护新到达的对象,并构建一个集合LKSm来维护Pm中的局部关键词轮廓对象.当一个新的对象o流入窗口时,算法首先将其插入集合Pm,并检测其关键词是否包含给定关键词kw,如果包含则将其插入集合LKSm,之后,对于任意流入窗口的对象oi(i>1),如果其包含关键词kw,算法将其插入Pm并访问LKSm,并通过索引Im判断其是否被LKSm中对象支配.如果不被支配,则将oi插入LKSm.特别地,如果oi能够支配LKSm中对象oj(j 除了维护新流入窗口的数据,算法还需要在关键词轮廓失效时,对候选关键词轮廓集合进行维护.具体地,算法首先逆序扫描LKS0中对象,将LK0-LKS0中的对象依次插入候选集.给定LK0-LKS0中对象o,如果其不被任何到达时间比它晚且包含关键词kw的对象支配,则将o插入候选集.反之,则说明o不是关键词轮廓对象,且在其离开窗口前不会成为查询结果,无需操作. 当窗口Pm变满时,算法首先构造索引Im,之后我们访问Im来更新集合LKSm,这里,索引Im的构造以及集合LKSm的更新将在4.2节中详细介绍.接下来,我们将LKS-LKSm中的对象全部插入到LKS中.在处理完分片Pm之后,我们判断是否需要对分片P1进行重扫描操作.如果集合LKS1为空,则无须进行该操作,反之需要对分片P1进行重扫描操作,将P1中的所有候选关键词轮廓对象插入集合LKS中.这里,重扫描操作将在4.2.4节中详细介绍.最后,我们构建一个新的分片Pm+1. 为了对各分片中的对象进行有效的关键词过滤,并且高效地计算出关键词轮廓集合,PCKSWI采用网格索引结构KSG管理窗口中对象.首先,我们利用多分辨率网格将整个空间划分为一组大小不等的单元格,之后,对于每一个非空单元格,我们使用R-Tree维护其中文本属性中包含给定关键词的对象.下面正式介绍网格索引KSG. 4.2.1 KSG的构建 观察1.给定网格G,对象o1、o2以及其所在单元格c1、c2,如果c1在c2的左下方,则对象o2一定被对象o1所支配. 图2 索引KSG的过滤步骤 算法1.关键词过滤算法 输入:数据集D,单元格集合C,关键词kw 输出:过滤之后的剩余对象集合D 1. fori=0;i<|C|-1;i++do; 2. ifkw∉C[i].keywordthen 3.D.delete(C[i]); 4. fori=0;i<|C|-1;i++do; 5. ifC[i].tag=unskylinethen 6.D.delete(C[i]); 7. returnD; 在重构过程中,我们使用R-Tree索引来维护所有轮廓单元格以及最小轮廓单元格中的对象,由于R-Tree索引已经在文献[11]中详细介绍,为节省空间,这里不再重复叙述. 4.2.2 局部关键词轮廓查询 4.2.3 网格索引更新算法 当分片Pm变满时,我们需要将集合LKSm中的对象合并到LKS中,并将LKS中的非关键词轮廓对象删除.我们可以根据观察2,降低索引更新所需代价. 观察2.给定对象o∈LKSi,o′∈LKSm,如果o被o′所支配,那么o的支配空间内的所有对象均被o′所支配. 另外,由于o′比这些对象的到达时间都要晚,因此它们在失效前不会成为关键词轮廓对象.具体地,假设对象o∈LKSi,o′∈LKSm,如果o被o′所支配,我们访问索引Ii的根节点,找到所有被对象o′所支配的对象.假设e为索引Ii的节点,e.m为e所对应的最小边界矩形(MBR),我们可以利用o′和e.m左下方(或右上方)坐标之间的位置关系来判断e中对象和o′之间的支配关系.如果e.m左下方坐标位于o′的右上方,则说明e中的所有对象均被o′所支配,我们可以将e从索引Ii中删除;如果e.m右上方坐标位于o′的左下方,则说明e中的所有对象均不被o′所支配.如果结点e与o′不存在支配关系,我们继续访问e的孩子节点.特别地,如果Ii成为了一棵空树,我们直接删除索引Ii. 以图3为例,索引Ii中对象以及LKSm中对象o′的分布情况如图3(a)中所示,其对应的R-Tree结构如图3(b)中所示.我们首先访问Ii的根节点R,由于其孩子节点e6和e7所对应的最小边界矩形与o′之间均不存在支配关系,因此我们继续访问e6的孩子节点e1、e2以及e7的孩子节点e3、e4和e5.由于e2.m、e3.m和e5.m的左下方均位于o′的右上方,因此e2、e3和e5中所有对象均被o′所支配,我们将其从Ii中删除.接下来,我们继续访问剩余的节点e1和e4,找到其中所有被o′所支配的对象.最终,我们得到更新之后的关键词轮廓集合{o1,o2,o11}. 图3 索引KSG的过滤步骤 4.2.4 基于KSG的重扫描算法 如4.1节所述,当LKS0中对象均被LKS-LKS0中对象支配时,LK0中对象在失效之前均不会成为轮廓对象.此时,算法无需访问LK0.反之,算法需要对LK0进行扫描以便找到其中所有可能成为查询结果的对象,并将它们加入候选集. 为实现高效扫描,我们提出一种基于索引KSG的重扫描算法.它包括两个步骤:非候选对象的过滤和候选对象的验证.在非候选对象的过滤步骤,我们根据集合LKS-LKS0中的对象来检测索引I0中的对象是否为候选关键词轮廓对象.具体地,对于LKS-LKS0中的每一个对象o,我们访问索引I0并找到所有被o所支配的对象,该扫描算法已经在4.1节中介绍过,这里为节省空间不再介绍.之后,我们利用LKS-LKS0中的其他对象来找到LK0中的所有非候选关键词轮廓对象并从LK0和索引I0中删除这些对象. 在候选对象的验证步骤,我们逆序扫描LK0中的剩余对象.由于这些剩余对象均不被LKS-LKS0中的对象所支配,因此LK0中最后到达的对象o一定是候选关键词轮廓对象,我们将其插入集合LKS中.另外,我们将o插入另一个R-Tree索引RI0中.之后,我们对LK0中的对象逆序扫描,判断其是否被RI0中的其他对象所支配.如果不被支配,则将其插入RI0和LKS中,否则,我们将其从LK0中删除.在访问过LK0中的所有对象后,重扫描算法结束. 在介绍了框架概览和网格索引KSG之后,我们需要解决如何进行分片的问题.如前文所述,我们需要监测LKS∪LK0中的对象来支持关键词轮廓查询.需要注意的是,在最坏的情况下,分片Pi中的所有对象均为关键词对象,因此,当分片粒度较大时,最坏情况下,各分片中的关键词轮廓对象候选集LKS的规模较小,维护代价较小,但重新扫描LK0后,会导致加入候选集的对象过多;反之,LKS的维护代价则会较大,但重扫描LK0后,加入候选集的对象则会相对减少.因此,选择一个合适的分片粒度是有必要的.下面,我们将对分片粒度的设置进行分析. (1) 本节采用C++语言实现了PCKSWI算法,实验环境为Intel i5-4210M~2.60GHz;8GB内存;1TB硬盘的PC机. 本节分别采用一个真实数据集和两组合成数据集来验证算法性能.真实数据集采用手机评论数据集,包含64MB条记录,每条记录包含3条数值型属性.合成数据集包括一组独立数据集和一组反相关数据集,其中每组包括4个数据集,分别包含2、3、4、6条数值型属性和10M条记录.本节在测试时,将窗口长度N从0.5MB变化到2MB,默认值为1MB;将关键词数量n从2个增加到10个,默认值为2个;将维度d从2增加到6,默认值为3. 本文的实验方法是按照数据产生的顺序将数据一次性读入内存.此后,对每条数据按照其到达时间添加ID属性.随后,将数据依次插入窗口并计算窗口中的关键词轮廓对象.当所有数据都处理完毕之后,统计运行时间.本文采用相同的方法处理各个数据集中的对象,为节省空间,这里不对它们的生成过程进行详细介绍.此外,本文将PCKSWI算法与基于文献[12]中的连续轮廓查询算法的baseline算法和不带索引的算法PCKS进行对比. 本节第1组实验测试窗口长度对算法性能的影响,分别在真实数据集、独立数据集和反相关数据集下测试算法性能,其他参数均使用默认参数,窗口长度从0.5MB扩大到2MB,记录算法的总运行时间.图4(a)-图4(c)分别为真实数据集、独立数据集和反相关数据集下3种算法的运行时间.我们发现PCKSWI算法的性能最好,并且,随着窗口长度的增加,3种算法性能均有下降,而PCKS和PCKSWI算法的性能下降更加缓慢.原因在于,PCKS和PCKSWI算法通过对滑动窗口进行分片,有效避免了对所有候选关键词轮廓对象的维护,因此其性能受窗口长度的影响不大. 图4 窗口长度N对算法效率的影响 本节第2组实验测试关键词数量对算法性能的影响,分别在真实数据集、独立数据集和反相关数据集下测试算法性能,其他参数均使用默认参数,关键词数量从2个增加到10个,记录算法的总运行时间.图5(a)-图5(c)分别为真实数据集、独立数据集和反相关数据集下3种算法的运行时间,我们发现PCKSWI算法的性能最好,并且,随着关键词数量的增加,3种算法性能均有下降,baseline算法下降最为明显,PCKS算法次之,PCKSWI算法的性能下降最为缓慢.原因在于,随着关键词数量的增加,虽然通过给定关键词可以过滤掉更多文本属性中不包含关键词的对象,但需要将对象的文本属性与给定关键词进行比对的次数也随之增加,因此整体效率会有所降低.PCKSWI算法通过网格索引批量过滤掉大部分文本属性中不包含关键词的对象,这使得其将对象的文本属性与给定关键词进行比对的次数相应的减少,因此其效率降低最为缓慢. 图5 关键词数量n对算法效率的影响 本节第3组实验测试数据维度对算法性能的影响,采用独立数据集和反相关数据集作为测试数据,其他参数均使用默认参数,数据维度d从2扩大到6,记录算法的总运行时间.图6(a)和图6(b)分别为独立数据集和反相关数据集下3种算法的运行时间,可以发现PCKSWI算法的效率最高,并且随着数据维度的增加,3种算法的效率都有明显降低,其中PCKS算法效率的降低最为缓慢.这是因为,对于baseline算法来说,随着维度的增加,R-Tree索引的有效性下降,因此效率大幅降低.然而,由于PCKS算法维护的候选对象少,所以和baseline算法相比,运行时间增加较慢.而对于PCKSWI算法来说,KSG索引的有效性也会随着维度的增加有所下降,因此其效率也会随着维度的增加而有所降低. 图6 数据维度d对算法效率的影响 本文研究了数据流上的关键词轮廓查询问题,为支持该查询,本文提出查询处理框架PCKSWI.它通过对窗口进行有效划分,过滤掉大部分不可能成为查询结果的对象,从而克服了数据间时序关系对算法性能带来的影响.随后,本文提出了基于多分辨率网格的索引KSG,该索引一方面利用网格来有效过滤窗口中的关键词对象,另一方面可利用关键词对象中的轮廓对象和单元格的关系高效计算出窗口中的关键词轮廓对象.另外,本文通过分析,根据流数据的规模对划分粒度进行调整,提高了PCKSWI整体效率.最后,本文基于真实数据集以及合成数据集进行实验,实验结果表明本文所提算法在数据流上能够有效处理关键词轮廓查询.4.2 网格索引KSG
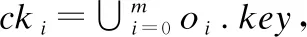


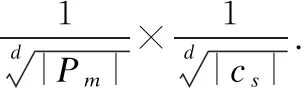

4.3 分片粒度的设置
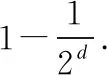
5 实验分析
5.1 实验准备
5.2 实验分析
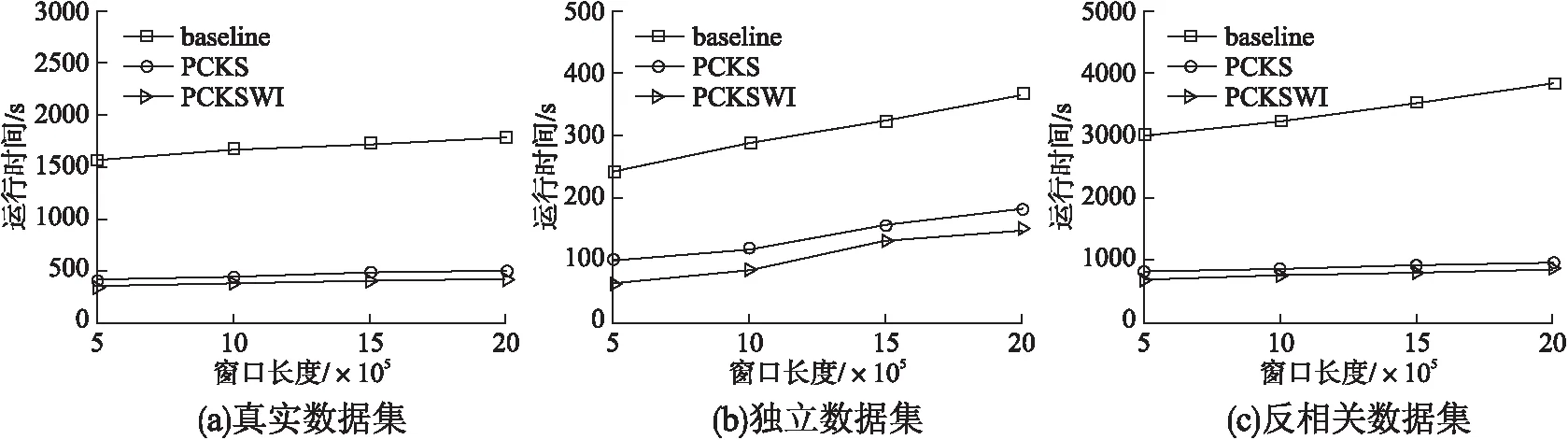
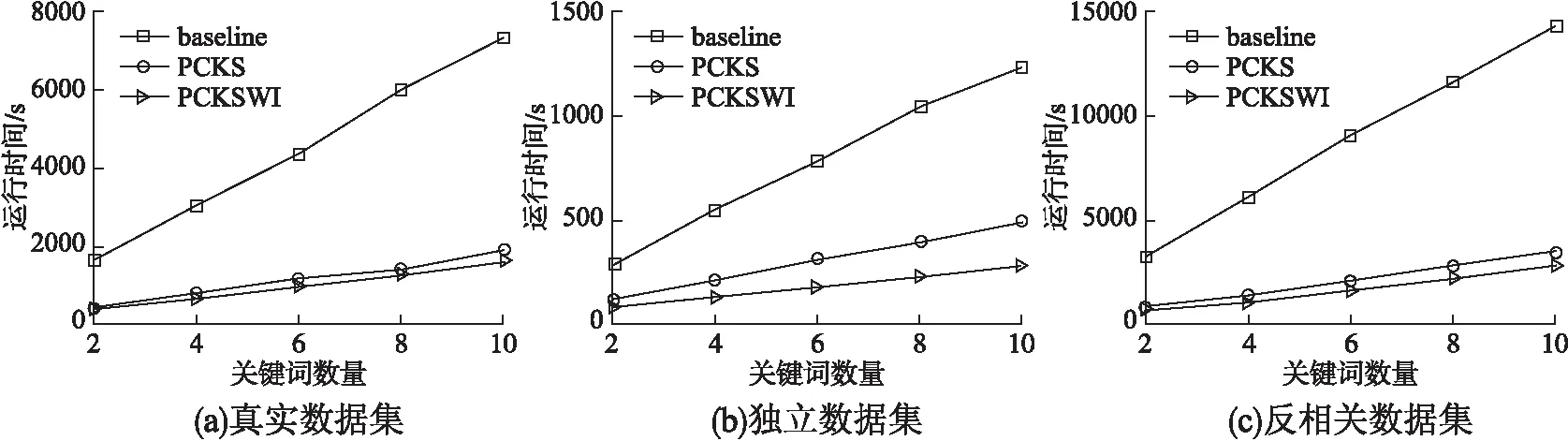
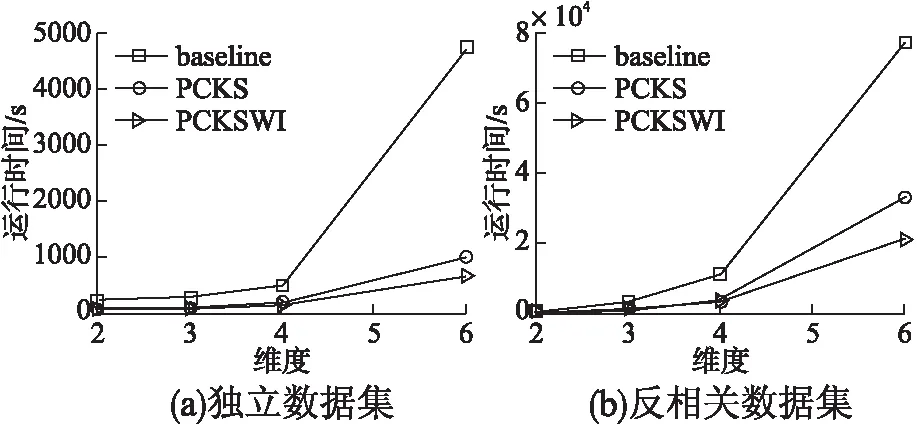
6 结束语
猜你喜欢
意林(2021年9期)2021-05-28
时代英语·高一(2019年5期)2019-09-03
时代英语·高一(2019年1期)2019-03-13
新城乡(2017年9期)2017-09-26
科技资讯(2016年18期)2016-11-15
Coco薇(2016年8期)2016-10-09
学生之友·最作文(2014年5期)2014-07-09
大灰狼(2009年7期)2009-08-26
舒适广告(2008年9期)2008-09-22
