
采用Transformer的行为及交互角色识别
2021-08-19 08:25邹婷
现代计算机 2021年21期
邹婷
(西南交通大学信息科学与技术学院,成都611756)
0 引言
图像分类作问题是计算机视觉领域的一个基础性课题,该问题伴随着深度学习技术的进步已取得巨大进展,包括目标分类、动作分类甚至场景分类等问题的研究都已经进行很长一段时间,其中部分任务已经接近人类的水准。而在真实应用场景下,如智能机器人,则需要对场景进行更为详细的理解,除了识别图片显然在发生的行为以外,我们还需要了解诸如“谁在进行活动”、“使用的工具”、“活动发生的场所”等信息用于更高层次的场景理解。
静态图像中的行为以及人物交互识别任务在过去的很长一段时间已经成为计算机视觉领域的研究热点之一[4],早期的数据集和方法主要集中在识别较少数量的动作[5],近年来的相关数据集则开始关注人与人、人与物之间的交互[6-7],而最新的研究已有更为详细的、结构化的数据集被提出,以便于解决更高层次的理解问题。Yatskar等人[8]利用自然语言资源提出的imSitu就是一个更大、信息更为全面的数据集,该数据集以一个三元组的形式描述静态图像的场景信息,与此同时,他们使用了一个CRF模型用于建模动作和交互角色-名词实体之间的依赖关系。在本文的工作中,实验使用Transformer模型来解决本任务,捕获动作-交互角色-名词实体之间的相关性关系。
Transformer[12]在自然语言处理中受到广泛的应用,已经证实其结构可捕获语法用于生成句子,近来也有部分工作将其用于图像领域并取得较为不错的效果[13-14],受启发于以上两点,本文将其运用于场景预测任务。场景预测包括预测一个动词和一组与之相关联的名词实体,故可将其视为一个特定动作拥有着固定语法框架的结构化标题生成任务。具体实现上参照一般的图像处理任务,首先通过CNN抽取图像特征,进一步将特征送入Transformer模型,在输出结点生成动作或名词实体。与其他模型相比,本文提出的模型在公开的数据集imSitu上取得了更好的效果。
本文首先对当前的场景识别研究以及视觉Trans⁃former的相关工作进行简要介绍,随后详细描述本文所使用的网络结构和算法细节,最后对实验结果进行对比分析。
1 相关工作
1.1 场景识别相关技术
Yatskar等人提出的imSitu数据集将场景识别的任务定义为预测一个结构化的三元组,具体而言,对于特定的行为,会涉及到特定的参与角色,如“参与主体”、“工具”以及“地点”等,任务需要为主体发生的行为所涉及到的交互角色分配对应的名词实体。与前文对应,参与主体可能是人、狗等,工具则可能是刀、绳子等,地点则可能是森林、厨房等。对于同一个动作,其参与的语义角色固定,但根据该动作所表示的语义不同而对应着不同的名词实体。我们从数据集里选取一组图片如图1所示。
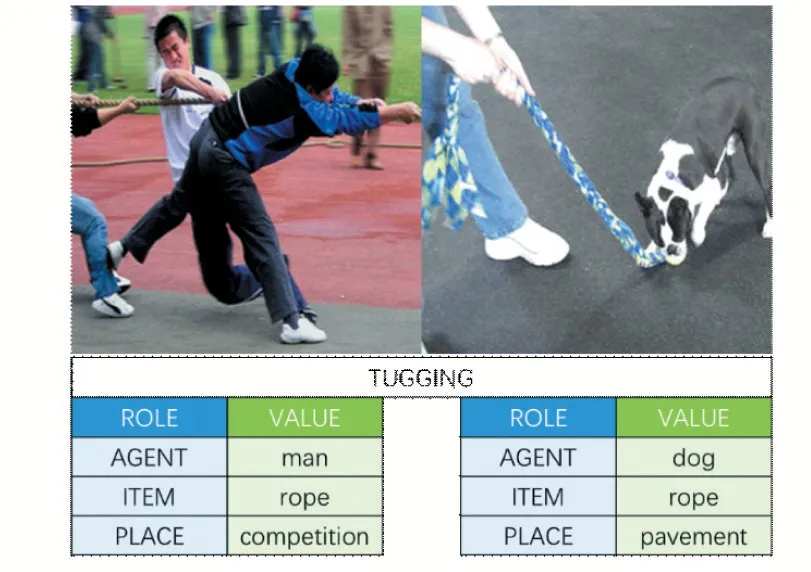
图1 数据集示例
可以看到,同样是拖拽的动作,场景可被泛化的定义为“某人正在某个地方拖拽某物”,涉及到的角色(表格中蓝色的一列)共有3个,agent指发生当前行为的主体,item则为被拖拽的物体,place即发生的地点。左右两张图像视觉上分别对应着拔河与遛狗两种场景,即使是相同的动作拖拽,参与动作的角色的取值(右侧绿色这一列)也不同,文中我们将其这些值称为名词实体,其取值更多的与当下的语义环境相关。我们的任务就是要在识别动作的同时,将参与的角色进行识别,以便于更高层次的理解当前画面的信息。
Yatskar等人在提出数据集的同时也提出了利用神经网络建模的CRF模型,利用CNN分别得到动词和动词-角色-名词实体组合输出的势函数,联合建模了动词以及动词-角色-名词实体元组的预测。在他们接下来的工作中,考虑到了输出空间的庞大(各种组合的可能性太多)以及训练数据中的稀疏性可能会带来的问题,进一步在其接下来的工作[9]中提出了一个张量合成函数来共享不同角色之间的名词。同时作者还通过根据结构化情景构建的查询短语搜索图像来增强训练数据以应对稀疏性问题。
不同于Yatskar等人的联合预测verb-role-noun,Mallya A等人[10]考虑到对于特定的动作,其所涉及的参与角色是隐含且固定的,在此基础上他们假定每个动作涉及到的角色有一个固定的顺序,进而将问题转变为先预测一个动词,在确定动词和角色之后,为每一个角色分配名词实体。在这样的定义下,考虑到大部分的行为都有人的参与,作者使用一个融合网络,将原画面与提前检测到的人物框进行叠加来预测动作,另外再使用RNN模型预测固定角色顺序的名词实体。具体而言,在RNN的每一个时间步输出一个名词实体分类的结果,这大大的减小了分类的域,减少了内存消耗。
RNN的工作建模了同一个动词的不同角色对应的名词实体之间的关系,而忽略了角色与名词实体以及动词之间的关系,Ruiyu Li等人[11]利用图结构,通过把动词和参与角色定义为图结构的结点,使用图像特征和角色、动词的词嵌入联合初始化这些结点,以图的边衡量其关系,利用图网络的结点聚合建模角色与角色,角色与动词之间的关系。在经过有限次聚合迭代后,在每个结点处输出名词实体的分类结果。
1.2 视觉Transformer
Transformer是由Vaswani等人基于注意力机制提出来的一个序列模型[12],用于机器翻译工作,注意力机制可选择性的聚合来自整个输入序列的信息,可捕获到句子中的关键部分。Transformer引入了自注意力层,该结构扫描整个序列的每一个元素,通过聚合整个序列的信息来更新当前结点。目前Transformer在自然语言处理领域的许多问题上正在取代RNN,受启发于此,已有许多工作将其结构应用到计算机视觉任务中[13-14],在不少视觉任务中,Transformer表现出比RNN甚至卷积神经网络更有力的性能[18]。
本文结合图网络建模结点的思路[11]和DETR[13]将Transformer用于目标检测的结构,通过CNN提取图像特征,将其转换为序列输入Transformer中,建模verb与nouns的依赖关系,实验证明本方法取得较之此前的工作更好的效果。
2 算法原理
对于任意一张静态图像,其场景所涉及到的动词和与参与动作的角色之间存在着依赖关系[11],以前文“拖拽”这一动作为例,参与行为的主体(agent)就与发生的地点(place)存在相关性,出现在运动场的实体更可能是人而非狗。而“携带”这一动作,agent就与被拿的物体(item)相关,小件的物体拿在手上,大件的物体更可能是在背上,那么根据场景的不同,行为对应的agent取值则不同。前文提到的方法使用CRF、RNN及图神经网络来模拟这些隐含的依赖关系,考虑到Trans⁃former的注意力机制在更新结点时会综合考量当前结点自身与其他结点的关系,本文使用Transformer结构来解决场景识别任务。具体地,实验将Transformer结构的encoder用于特征编码,decoder部分用于模拟verb结点与role结点,进一步计算动作与参与角色之间的重要程度。
Attention机制:Transformer的核心算法在于其自注意力机制,将输入序列映射到三个分别称为Q、K、V的矩阵,并进行如下公式所示的运算对结点与结点间的相关性建模,且这样的方式是动态衡量结点间信息相关性,符合本任务场景语义的不同会带来角色间依赖不同的特点。多头注意力则将序列拆分后运算再进行拼接,以便于以不同的维度观测序列的重要部分。
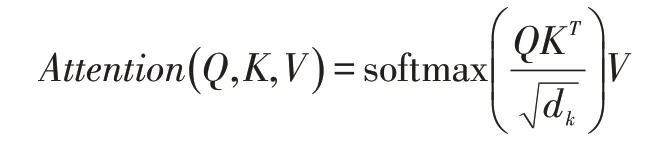
参考DETR的工作,本文使用CNN作为back⁃bone,提取图像特征后将其展开为序列,结合位置编码后作为Transformer的encoder部分的输入。而在Transformer的decoder部分,不同于DETR的设置,对于每一张图片,本文使用固定数量为7个的输出,对verb结点和noun结点进行模拟,使用输出序列的第一个结点作为动词结点,而后6个结点作为角色结点,将其称为role query。通过这样的方式,利用Transformer的attention机制来衡量结点间的相关性。模型的大致流程如图2所示。

图2 模型流程
在输出时,实验取消了DETR模型末端的MLP头,分别使用两个线性映射后接softmax用于动词和一组名词实体的预测。
在训练时,保留二分匹配的部分,用于名词实体结点的匹配,实验使用匈牙利匹配算法。定义当前图像所涉及到的每一个角色对应的名词实体为e,其真值的索引σ(e)以及softmax后对应的概率为pσ(e)(e),将这一组名词实体的匹配cost矩阵设计为,经过匹配后,使用动词verb和匹配后的noun联合优化模型,loss设计为:
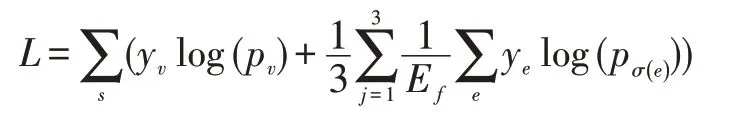
其中yv和ye分别为动词和当前图片s对应的一组角色的名词实体的真实值(在数据集中的索引),Ef即当前图片的所有角色,此外,imSitu数据集给每一组角色都提供了三组名词实体的标注,我们对三组结果取均值,也就是loss公式的右半部分。
3 实验设置与结果分析
3.1 数据集与评价指标
实验将基于公开数据集imSitu进行,该数据集包含504个动作,190种语义角色,取使用频率最高的2000种名词实体。数据集中的每一张图片对应着一个动词verb,三组角色-名词实体标注,这里的三组标注是源于不同的人对于画面的不同理解,其中的语义上的词定义来自FrameNet和WordNet。数据集的划分上,训练集、验证集和测试集大小分别为75k、25k和25k,在imSitu训练集的75k张图片上进行模型的训练,同时在验证集上进行验证并以此调整模型的训练情况,以最好的模型在测试集进行测试。
沿用先前工作的评估方式,本文评估以下三个指标:①verb:指动词识别正确的分类准确率。②value:每一个单独的名词实体分配正确的准确率。③valueall:当前动作所有名词实体均分配正确的准确率。
3.2 实验设置
实现上,训练参数做如下设置,batchsize为取64,epoch为40,使用Adamw训练策略,Transformer的初始学习率为10-4,backbone选取ResNet[15],加载torchvision在ImageNet上预训练的模型参数进行finetune,初始学习率为10-5,权重衰减为10-4,分别在25、30、36次ep⁃och时将学习率缩小1/10。DETR中将Transformer的layer norm去掉了,这里我们恢复encoder结尾的layer norm,采取gelu作为激活函数。
3.3 结果分析
本文将实验结果与本任务的其他方法分别在验证集和测试集上进行了对比,实验结果如表1所示,其中第5行(已加粗)是本文采用的方法的实验结果,评价指标如3.2所述,与其他工作类似,我们也选取了动词预测top-1和top-5的分类结果。可以看出,本文提出的方法在imSitu数据集上与其他方法相比均有所提升。
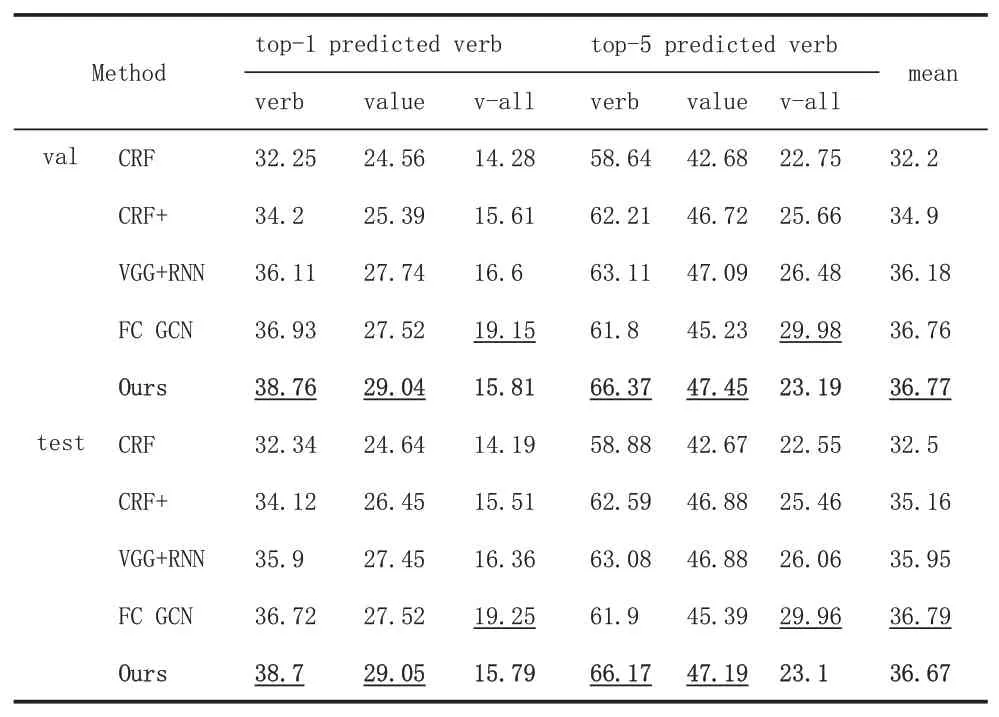
表1 本文方法与其他方法的实验结果对比
受益于Transformer的self-attention机制,模型捕捉到名词实体(即value/noun)之间的相关性,除此之外,相较图网络[11]和RNN[10]的方法都是基于角色建模依赖关系,我们在decoder处将动词和参与角色同时作为结点,不仅考虑参与角色之间的关系,也考虑每一个参与角色与动作之间的联系,故可以看到本文方法在verb预测上表现优越。同时attention机制使得模型更关注重要的角色,以及其重要程度,正如前文所讨论的,特定行为的特定角色对区分画面的贡献度更高。role query的存在使得每一个参与的角色都会与verb进行结点间的信息聚合,故在给角色分配对应的名词时也取得较好的效果。
此外,场景识别中,行为发生时的角色的相对位置理论上也对分类的结果有帮助,尽管此前的方法也用到了图像特征,但并没有显式的将位置信息加入结点进行编码,Transformer在其encoder与decoder部分均在每个结点上叠加位置编码,本文认为这部分内容也有助于结果的提升。
同时我们也看到,value-all这一指标的准确率尽管高于基准方法,但相比其他方法而言效果不是很好,这里推测可能是由模型末端的二分匹配的不准确性带来的误判。
4 结语
本文提出了一种新的用于静态图像情景识别的方法,可同时预测正确的动词以及参与当前行为的交互角色-名词实体组合。本文使用的视觉Transformer方法明确地建模了行为和交互角色之间的依赖关系,使得动作与角色之间、角色与角色之间可互相感知相关关系。在本问题的标准数据集imSitu上,我们在评估的三个指标上均取得了超出baseline方法的效果,在动词和value的识别上超出当前所有的其他方法,通过分析,表明了该方法对捕获动词与角色之间依赖关系的有效性。
猜你喜欢
电子制作(2022年1期)2022-01-28
计算机系统应用(2021年11期)2022-01-06
数理化解题研究·综合版(2021年11期)2021-12-22
小学教学研究(2021年5期)2021-09-29
课程教育研究(2021年27期)2021-04-13
初中生世界·九年级(2020年2期)2020-04-10
当代陕西(2019年5期)2019-03-21
21世纪商业评论(2018年3期)2018-03-02
现代出版(2014年6期)2014-03-20
