
基于改进YOLOv5的叉车能效优化方法研究
2021-08-19 08:23李青青李陈斌李镇宇陆可
现代计算机 2021年21期
李青青,李陈斌,李镇宇,陆可
(1.安徽工业大学管理科学与工程学院,马鞍山243000;2.哈尔滨工业大学计算学部,哈尔滨150013;3.上海应用技术大学经济与管理学院,上海200235)
0 引言
机器视觉被越来越广泛的应用于无人工厂、智能控制等场景中。在工业物流系统中,叉车在搬运和存储环节中扮演着重要角色。然而,大部分工厂内部叉车数量大、运送路线复杂,并且对搬运的货物采用人工统计、纸质保存等传统方式进行管理,难以对叉车的工作效率进行有效评估。因此,本文提出一种基于机器视觉统计装卸货物次数的方法,对叉车工作效率进行分析和记录。
近年来,许多学者在不同领域对机器视觉进行深入研究。物体检测是机器视觉领域的基础性研究,对后续能效管理、自动识别等任务起着至关重要的作用。传统的检测是通过传感器判断托盘货物的状态。文献[1]使用传感器与激光雷达结合,通过联合标定和配准来实现对叉车托盘的检测,但是价格昂贵,无法普及使用。文献[2-3]基于颜色和几何要素生成特征信息,应用具有针对性,但是易受光照与噪声的影响。随着深度学习的发展以及硬件水平的提高,基于深度学习的目标检测技术,取得了划时代的发展。从最初的R-CNN[4]、OverFeat[5]、到后来的Fast R-CNN[6]、进阶版的Faster R-CNN[7]、SSD[8]以及YOLO系列,网络架构实现从双阶段到单阶段的革新。从面向PC端R-CNN到手机端MobileNet[10],目标检测技术在不同终端上展现了出色的检测效果和性能。文献[11]利用托盘孔位置的焦点特征进行托盘识别,要求存在托盘孔,限制因素较高。文献[12]利用改进的DenseNet算法对实际场景下的托盘进行检测,实验场景环境单一,检测效果一般。所以将机器视觉应用于实际场景中,存在网络模型较大、参数多、嵌入性差的问题,导致计算量大、硬件要求高的问题。
为了解决上述问题,适应作业环境的复杂多样性,首先在通用数据集的基础上增加了符合实地应用场景的数据。其次,对于现场硬件的限制性,难以嵌入大规模的应用程序,改进了YOLOv5的主干网络结构,使用更轻量级的特征提取网络减少网络的冗余特征。为保证减少网络运算量的前提下,不降低网络检测的准确度,故增加了注意力机制,更具针对性地提取图像的目标特征信息,提高网络的准确度。实验结果表明,在不同复杂度场景下,与原始的YOLOv5算法比较,改进后的网络在鲁棒性和准确度显著提高。
1 检测场景流程
1.1 网络结构框架
首先,本文将单目2D相机部署在叉车驾驶室的顶端,检测到叉车前向托盘立面局部货物。在获取实际场景下视频流的基础上,对视频进行分帧操作,截取间隔若干帧的不同时段的图片。然后对图像进行聚类分析,建立所有图像之间的相似度函数。利用相似度函数分析截取到的图片之间的相似程度,设定一定阈值对相似程度高的图片进行重复筛选,避免人工挑选的时间成本和主观判断的差异。最终图片作为自建数据集的源文件,通过标注后得到不同场景下的类别数据。选取YOLOv5算法作为机器视觉的检测算法,实现对叉车运输状态的实时准确获取。对现实场景进行目标检测的流程设计如图1所示。

图1 检测场景系统框架
1.2 实验数据集
本文围绕VOC数据集和自建数据集进行算法效果的对比实验。VOC数据集是拥有多项功能的数据集,包含20类目标,数量超过5万张,以XML数据结构存储。VOC数据集虽然包含着大量标注数据,但是适用于实际工业应用场景比较少。
本文仿照VOC数据集制作了一个专门用于检测叉车货物的数据集,用于提高网络性能。该数据集从实地车间驾驶员行车过程中跟拍获取视频,采集到不同天气、不同时间段(夜景也在内)、不同地点的复杂样本数据。通过后续对视频的分帧、聚类,挑选出叉车托盘货物中含有满盘、半盘、空载、上下料过程的四种不同复杂场景。最后使用labelImg软件对采集图片进行矩形框标定,生成对应的XML文件,用于训练和测试。自建叉车货物数据集更贴合工厂场景,同时复杂多变,对于目标检测网络的性能具有更大的挑战性。
1.3 数据聚类分析
本文应用的场景中,数据以视频的形式存储,而实际使用的数据集是以图像的格式作为输入,所以要对原始的数据进行预处理操作。数据预处理流程如图2所示。首先对视频数据处理,对输入的视频进行采集和编号,并将编号后的视频输入存储模块。然后对视频进行预处理操作,在利用高斯滤波滤除编号视频噪声的基础上,再进行分帧处理。在预设时间间隔下保证帧长有效性,得到若干独立的预处理图像。视频通过预处理模块首先对视频间隔为60帧频率取一张图片,并进行存储操作。在保证图像清晰的前提下,每个视频约提取5000张图片,所有视频数据共计生成90739张图片。

图2 数据分帧聚类处理
由于分帧后处理的数据量较大,图片与图片之间的差异性较小,通过聚类过后易于对图片进行删减。我们首先将原始图像看作是一个高维向量,将数据由高维向低维投影,进行坐标的线性转换。常见的数据降维方法包括主成分分析,奇异值分解等。我们采用PCA(Principal Component Analysis)算法进行降维,便于有效信息的提取和剔除无用信息。降维公式如下:

进行降维后,提取图片本身具有的特征,从而判断两两图片之间的相似程度。通过计算相邻图片特征的相似性,设定合理阈值解决自建数据集冗余的问题。

v1是图像1降维后的向量形式,v2是图像2的向量形式,也可以理解为概率论上的样本点。conv(v1,v2)为v1与v2的协方差,var(v1)为v1的方差,var(v2)为v2的方差。
针对相似度高无法识别的图片,提取图片更深层的语义信息,利用图片多层次特征预防删除过度情况。为了平衡聚类效果以及运算时间成本,将本实验聚类数目设置为9,通过每个类簇的协方差来决定簇类分布的形状。经反复迭代训练后,处理速度可达28bit/s,最终获得贴合数据集的模型。聚类效果如图3所示,不同散点群组间距离越远,相似度越低。

图3 聚类效果
2 基于机器视觉的叉车能效检测
YOLOv5网络框架主要由三个模块组成,框架如图4所示。首先是提取特征的主干网络CSPNet[13],在不同图片上提取细粒度级特征,提取丰富的语义信息和位置信息。模型的head模块包括PANet[14]和head检测部分,路径联合网络PANet网络可以对主干提取的特征进行特征融合。对于不同尺度目标的检测,特征金字塔结构会强化训练好的模型,有利于对不同大小的同一目标识别问题。Head检测层将预测出的目标框映射到对应的特征图上,最终输出包含目标所属类别概率、对象得分和包围框的坐标的向量。

图4 YOLOv5网络结构
在实际工业场景中,一方面现有数据集类似于PASCAL VOC(以下简称VOC)、COCO等公共数据集与实际场景的耦合性较差,模型适配性较低。另一方面,原始算法对现场设备性能要求过高,难以嵌入。对于以上问题,首先,自建了符合现实场景的数据集,在公共数据集的基础上满足实地检测要求。其次,对YO⁃LOv5网络结构进行了改进,通过GhostBottleneck(以下简称GB层)层代替BottleneckCSP网络层,缩减网络参数。同时新增了Squeeze-and-Excitation注意力机制模块(以下简称SE模块),对主干网络的提取特征重新组合,更好拟合网路通道之间复杂的相关性,提取更具针对性的特征。
2.1 GhostBottleneck模块
在实际场景下,由于现场设备空间布局的设计,硬件算力有限,限制了深度学习的应用。针对此问题,我们采用为移动设备设计的GhostNet[15]网络结构,其核心是利用线性操作来生成丰富的特征图。原始的Bottle⁃neck网络中,在提取特征的过程中生成过多冗余特征图,占用硬件内存时还影响网络的运行速度。本文使用GB网络结构代替YOLO中的BottleneckCSP结构。我们将网络拆分成shortcut和conv堆叠两个部分,使用一部分普通卷积获取特征图,其他特征图使用5×5的线性卷积操作,从而在减少一半计算量的同时,依旧能获取相同数量的特征图。框架绘制如图5所示。

图5 GhostBottleNeck框架
特征图经过一个Ghostconv卷积过后,判断传入的stride参数是否为1。当判断stride不等于1时,则执行DWconv层,实现对输入特征层的下采样,减少网络的运算参数,特征图会缩小为原来的一半,网络层的深度加深。当stride等于1时,网络会经过Ghostconv层进行特征提取,实现通道数的扩展。最终对前几层的输出进行整合操作。这样我们设置网络步长大小的同时,使得网络结构更富有灵活性和选择性。
与此同时,由于梯度发散,单纯增加网络深度难以简单地提高网络的效果,反而可能损害模型的效果。本文使用shortcut模块,对上一层的网络进行DWconv层的操作,与Conv堆叠块相似,选择传入的stride参数来进行控制是否进行卷积操作。增加的shortcut模块就是为了保证加深网络深度的同时,自适应地调节网络的输出通道数,便于维持模型的效果。
为了实现网络的轻量化,因此本文采用了Ghost⁃Conv卷积模块,绘制如图6所示。首先使用1×1大小的普通卷积层CV1实现更深层的特征提取。并且为了保证特征图细节信息的获取,分离出多尺度的局部特征信息。对前层输出数据分组成组特征,每个特征使用5×5大小的卷积核经过线性变换,提取更深层次的特征。最终将网络每一个模块可执行一组转换,在一个低维嵌入上执行每组转换,通过求和合并输出。网络通过分组卷积的方式来达到分组效果和卷积数量两个方式的平衡,最终可以在减少网络参数的同时还降低模型的复杂度。
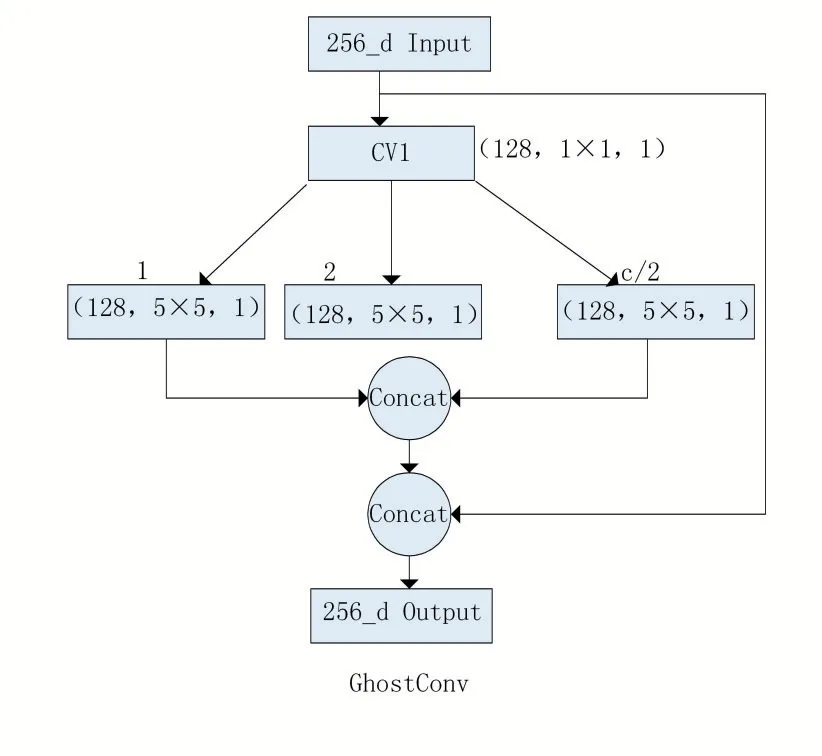
图6 GhostConv网络
使用了GhostConv过后,本文又结合了DWconv对网络进行优化。DWconv层使用1×1的卷积神经网络,设置网络输入输出的最大公约数作为划分群的个数,采用分组数量等于输入通道数量,即每个通道作为一个小组分别进行卷积,最终将每组结果联结作为输出。
2.2 SE(Squeeze-and-Excitation)模块
考虑到本文的检测目标物体面积较大,小目标物体较少,而在卷积池化的过程中,不同通道特征所占的重要性相同,造成信息损失问题。SE模块[16]是HU等人提出来的通过关注通道之间的关系,解决不同通道特征信息影响因子不同的问题。
SE模块包括Squeeze(压缩)和Excitation(激发)两个操作。在改进后GB层不断进行通道堆叠过后,会产生参数量大,模型容易过拟合的问题。我们首先利用Squeeze通过在Feature Map层上执行Global Average Pooling,输出1×1×channel的特征图对整个网路做正则化以防止过拟合。其公式如下:

H表示输入特征图的高度,W表示输入特征图的宽度。Excitation操作通过两层全连接结构获取通道间联系。然后接一个sigmoid激活函数层来保证输出的权重在[0,1]区间内。此时sigmoid函数的门机制,选择更加重要的特征交互传递到更深层。公式如下:
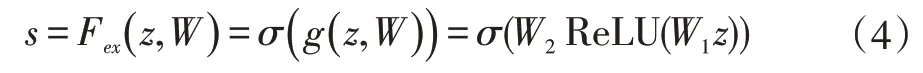
其中r为升降维比率,为降维层参数,为升维层参数,ReLU是其激活函数。最后一步是Scale层,将学习sigmoid层各通道归一化权重加权到原始特征上。
我们自建数据集中的图片,在特征表现上有很强的指向性,特征较少的位置信息对整体网络检测和识别的影响有限。我们使用SE模块控制scale的大小,对不同层的特征图提取的特征指向性更强。虽然增加SE模块层会相应增加网络模型的参数和计算量,对于模型参数增加量为:

其中r为降维系数,S为stage数量,Cs表示第s个stage的通道数,Ns是第s个stage的block重复次数。SE模块不可避免地增加了一些参数和计算量,但是在改进后的网络结构中表现出更好的性能效果。
2.3 改进后的YOLOv5网络结构
改进后的YOLOv5算法主干网络如图7所示,通过使用GB层对输入进行特征提取,不影响网络特征提取效果的基础上,使用步长为1的GB层代替原有的提取特征层。步长为2的GB层代替普通卷积层。再增加SE模块动态自适应完成在GB层通道维度上对原始特征进行双重验证,关注了模型通道层面的依赖关系。一方面,我们使用GB层的线性变换降低模型的大小,减少模型的运算成本。另一方面,结合使用SE模块针对性提取不同重要性的特征,使得网络剪枝的效果更加明显,对GB层提取的特征更具有鲁棒性和精确度。
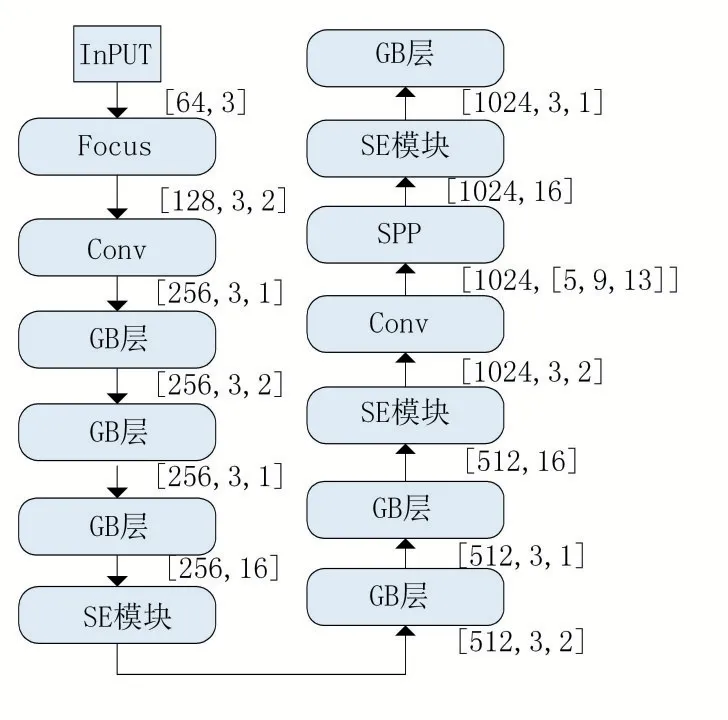
图7 改进的YOLOv5主干网络结构
增加的SE模块中,经过前面一系列的卷积操作和注意力机制层,会输出丰富的全局语义信息,但对局部的特征信息较少。我们在网络的后端增加空间金字塔池化层(Spatial Pyramid Pooling,SPP),对网络的前向卷积进行特征融合,从而获取更加丰富的局部特征信息。
3 实验设计
3.1 网络训练
本次实验所用到的软硬件配置如表1所示,实验框架基于PyTorch开发。

表1 实验配置
经过网络中的Neck模块过后得到挑选的候选框,训练过程中会得到每一个框的属性。其中一个指标是准确率(Precision,P),即遍历过的预测框中,属于正确预测边框的比值。其中若正确地检测出来托盘货物则为真正类(True Positive),若对于未装载货物的托盘检测为有货物则为假正类(False Positive)。检测准确率为:

3.2 检测的准确度
将实验的1172张样本集分成10份,将其中的9份作为训练集,剩下的1份作为交叉验证集,最终取所有类别平均误差,得到以下评估模型性能数据。本实验从mAP准确度的指标来衡量,对原始的YOLOv5算法和改进后的进行比较分析。
为了验证算法的鲁棒性对两种算法两个尺度各进行测试分析。结果如图8所示,原始的YOLOv5用细线条表示,改进后的网络用粗线条表示。从图中可看出,改进后的YOLOv5网络在保持较高准确度的基础上,波动水平较低,说明模型更加鲁棒。

图8 不同网络下的准确率测试
为了验证本文算法的有效性,将算法与更轻量级YOLO-fastest的性能进行比较。由表2结果表明,在自建的仓储托盘数据集上改进后的YOLOv5 mAP达到了99.1%,相对于原始网络mAP可提高0.9%,相对于更加轻量级的YOLO-fastest提高了2.31%。保证原有检测效果下,模型大小仅有5.4MB,模型的大小降低了67%。因此,本文算法在保证托盘货物叉车预测精准度下,模型占用内存小,更适用于树莓派、嵌入式电子设备等低端设备。

表2 不同网络的准确率测试值
经实验可发现,改进后的YOLOv5-SE与其他算法评估其网络性能,在相同数据集下表现效果如表3所示,在增加网络层数的同时,模型参数虽然有所增加,处理图像的速度比改进前的慢0.005s,但是依旧能满足现实场景实时检测的需求。

表3 不同网络的参数比较
3.3 实际检测结果
算法从实际工厂情景下出发,将训练好的模型应用于实地工业场景,算法能够完备地嵌入到工业应用现场。在叉车运行过程中,实现了实时检测的基础上,准确度维持较高水平。实验评估测试的结果如图9所示,表明在很大程度遮掩、工厂背景嘈杂、不同姿态的托盘情况下,网络模型依然取得了很好的检测精度。

图9 改进后的YOLOv5叉车托盘预测图
4 结语
本文提出了一种改进的YOLOv5算法用于统计叉车不同状态下装卸货物的次数,自建了基于实际工厂仓储叉车运输的数据集用于训练,修改了主干网络以降低算法的运算量,并引入注意力机制提取有效特征信息。改进后的YOLOv5模型小、更轻量级,易于进行嵌入式的开发。在叉车运行时面对复杂的场景鲁棒性强,能保持较好的检测性能。但在测试的过程中也发现存在预测框的边沿并不理想的情况,与检测托盘当前所属状态存在偏差,接下来我们将会这项工作进行重点改进,设计更好性能的YOLOv5模型。
猜你喜欢
中国特种设备安全(2022年7期)2022-10-09
农业工程学报(2022年12期)2022-09-09
大众文艺(2022年16期)2022-09-07
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01
计算技术与自动化(2022年1期)2022-04-15
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
时代英语·高二(2021年4期)2021-07-29
中学生数理化·高一版(2016年6期)2016-05-14
中国质量万里行(2014年11期)2014-11-13
