
基于多卷积核DPCNN的维吾尔语文本分类联合模型
2021-08-13 07:43加米拉吾守尔吴迪王路路古丽尼格尔阿不都外力买合木提买买提吐尔根依布拉音
中文信息学报 2021年7期
加米拉·吾守尔,吴迪,王路路,古丽尼格尔·阿不都外力买合木提·买买提,吐尔根·依布拉音
(1.新疆大学信息科学与工程学院,新疆乌鲁木齐830046;2.新疆大学软件学院,新疆乌鲁木齐830046;3.新疆多语种信息技术实验室,新疆乌鲁木齐830046)
0 引言
文本分类,是自然语言处理(natural language processing,NLP)的一个经典问题。文本包含丰富的语义信息,但是由于其非结构化的性质,如何准确地从文本中提取关键语义信息并完成分类是一项极具挑战性的任务。可以按照文本的长度将文本划分为长文本分类和短文本分类,其中短文本语义稀疏,处理难度更大。
深度学习方法在文本分类中取得了巨大的成功,如Zhang H 等[1]在CNN 上引入了聚类控制的方法,有效缓解了英文短文本分类中存在的数据稀疏问题,Choi B J等[2]提出的自适应卷积方法在多个英文长文本分类任务中取得较好的效果。虽然深度学习方法在大语种文本分类任务中已经取得非常可观的结果,但对于维吾尔语而言,资源匮乏和语言形态复杂等难点导致各项自然语言处理任务发展较为缓慢。维吾尔语文本分类早期的研究多使用传统的机器学习方法,如陈洋[3]在贝叶斯算法中加入权重完成了维吾尔语文本分类任务,但该方法需要考虑多个特征权重的影响,若继续引入其他特征,该文提出的调整函数将不再适用。近年来,部分学者在深度学习的基础上考虑使用语言特性,如Parhat等[4]、沙尔旦尔·帕尔哈提等[5]和Li Z等[6]使用词素序列对维吾尔语短文本分类进行研究,即更小的词粒度,以此来克服语言形态复杂等问题,但是这种方法的不足之处是过于依赖词素切分工具,而切分精度会直接影响自然语言处理任务的精度。
为了克服维吾尔语复杂的语言形态对语义信息获取的不利影响,以及短文本长度较短而导致的语义稀疏特性,本文提出了一种结合多卷积核的深层金字塔网络(deep pyramid convolutional neural networks,DPCNN)、双向长短时记忆神经网络(bi-directional long short-term memory,Bi-LSTM)和组合池化方式的卷积神经网络(convolutional neural networks,CNN)的深度学习模型。该模型以双通道的方式学习语义表示知识,一方面,通过Bi-LSTM 获取全局语义依赖,并且应用CNN 模型加强其局部语义依赖学习;另一方面,以多卷积核DPCNN 的方式压缩文本的语义信息。通过以上方式可更好地学习文本中蕴含的语义信息,无论是语义特征较为丰富的长文本,还是语义特征不足的短文本,该模型都取得了较高的分类精度。
1 相关工作
以往的文本分类,按照其使用方法的不同可以归结为基于规则的方法、基于机器学习的方法和基于深度学习的方法。基于规则的方法是指使用一组预定义的规则将文本分为不同的类别。例如,任何带有“足球”“篮球”或“棒球”字样的文本可以被赋予“体育”标签。而后,学者们多采用机器学习及其改进模型完成文本分类任务,如朴素贝叶斯(naive Bayesian,NB)[7]、支持向量机(support vector machine,SVM)[8]、逻辑回归(logistic regression,LR)[9]等。如今,深度学习已经成为文本分类任务的主流方法。一般而言,获取文本局部语义信息的方式有两种,分别是CNN[10]和注意力机制(attention mechanism)[11]。其中,注意力机制最先被使用在计算机视觉上,后被应用到NLP任务中。其特点是能够在减小无用信息对结果影响的同时,相对放大有用信息对结果的正面作用,能有效筛选出对实验结果有积极作用的语义。其变体self-attention[12]和multi-head-attention[13]推动了NLP 的发展。但文献[14]验证了该机制对新闻文本分类任务的精度提升相对有限。CNN 模型利用语义信息的空间不变性,能够很好地捕捉局部的语义信息。Kalchbrenner等[15]最早提出了基于CNN 的文本分类模型,即动态卷积神经网络(dynamic convolutional neural networks,DCNN)。该模型使用动态最大池化(dynamic k-max pooling),能够显式地捕获单词和词组之间的长距离和短距离的依赖关系,可以根据句子长度和卷积层次结构来动态地选择池化参数。Kim[10]提出了更为精简的CNN 文本分类模型,在减少计算量的同时有效提升了模型的精度。循环神经网络(recurrent neural network,RNN)[16]多用于获取全局语义信息,该模型符合人们顺序阅读的习惯,但传统的RNN 无法解决长距离依赖问题。之后学者们提出了门控循环单元(gated recurrent unit,GRU)[17]、长短时记忆神经网络(long shortterm memory,LSTM)[18]等模型成功克服了该难点。
维吾尔语的文本分类发展趋势亦是如此。阿布都萨拉木·达吾提等[19]建立了情感词典用于维吾尔语的文本分类任务。此类基于规则的方法需要研究人员对各个标签领域有深入的了解,能准确筛查出可能出现的关键词、关键句,使得这类方法工作量巨大,并且当有不同领域的词汇出现在同一文本中时,该文本分类任务会变得非常困难。随后学者们采用机器学习的方法,如吐尔地·托合提等[20]采用NB、k近邻算法(k-nearest neighbor,KNN)和SVM等多种机器学习方法提取语义特征词完成了维吾尔语的文本分类任务,但是特征词提取的质量会直接影响模型的性能。近年来,学者们多采用深度学习的方法完成维吾尔语的文本分类任务,沙尔旦尔·帕尔哈提等[5]采用不同的语义单元表示单词,使用CNN 和LSTM 完成了维吾尔语文本分类任务。虽然上述两种模型都能提取语义信息,但是LSTM 无法加强学习文本局部语义信息,而CNN 对文本的时序信息不够敏感,所以单独的LSTM 模型或是CNN 模型均无法全面捕捉文本的语义信息。
2 模型说明及算法描述
文本分类任务定义:给定一个文本T,将其进行向量化表示为{w1,w2,w3,...,wn}作为模型输入,对该文本进行语义提取并判定其所属类别,从而达到分类的目的。本文用Word2Vec方法完成文本的向量化表示,通过Bi-LSTM 和CNN 串行的方式在考虑文本时序的同时加强模型对局部信息的提取。与此同时,融合多卷积核的DPCNN 模型获取到的文本语义依赖,通过双通道的方式可以有效避免随着模型的深度增加而导致的梯度消失问题。最后通过Softmax 完成文本分类。该模型简称为MDPLC模型,其结构示意图如图1所示。

图1 MDPLC 模型
2.1 Bi-LSTM+CNN
RNN 在处理具有时序性的数据时有着良好的性能,但传统的RNN 模型不能很好地解决长距离依赖问题。所以,学者多采用LSTM 解决该问题。该模型是一种基于RNN 的变体,通过引入存储单元记住每个时间间隔的值。具体地,其引入输入门(input gate)、输出门(output gate)、遗忘门(forget gate)三个门来调节信息流入和流出,从而解决了传统RNN 模型面临的梯度消失或爆炸问题。LSTM细胞图如图2所示。

图2 t时刻的LSTM 细胞图
LSTM 的计算如式(1)~式(6)所示。

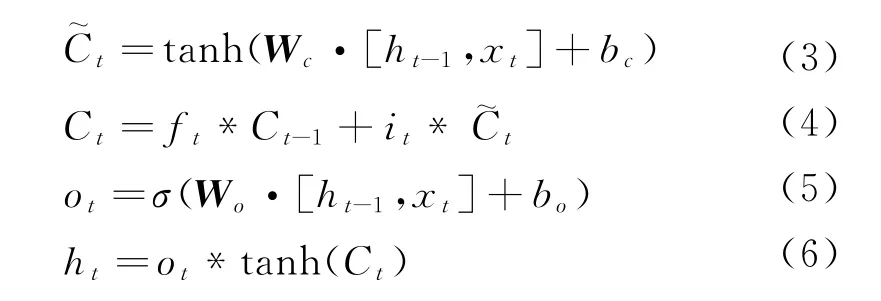
其中,xt表示当前的输入,ht-1表示上一个节点的输出,Wf、Wi、Wc、Wo表示权重矩阵,bf、bi、bc、bo表示偏置。式(1)的ft是一个0到1之间的值,用于决定上一时刻学到的信息有多少通过。式(2)~式(4)中it用于决定更新哪些值,其中,表示通过tanh层生成的候选值,Ct表示最后更新的值。式(5)中的ot表示保留的最终信息,ht为当前节点产生的最终输出。
为更好地获取语义信息,本文采用了Bi-LSTM从前向、后向分别捕捉文本的语义依赖,并且将Bi-LSTM 获取的语义信息和词向量进行拼接,其计算如式(7)~式(9)所示。

其中,H表示最终得到的语义信息,W表示词向量,表示前向LSTM 获得的语义信息,表示后向LSTM 获得的语义信息,操作⊕为向量拼接操作。
Kim[10]提出的TextCNN 模型首先在预先训练好的词向量上通过不同卷积核大小的卷积层提取语义特征,而后通过池化层进一步筛选上述操作提取的语义特征,有效减少了过拟合现象的发生。常见的池化方式有两种,最大池化(max-pooling)和平均池化(mean-pooling),其中最大池化能有效提取最显著的语义信息,而平均池化能够很好地兼顾邻域所有的语义信息。最后通过全连接层完成对文本的分类。该模型如图3所示。

图3 TextCNN 模型图
卷积操作如式(10)、式(11)所示。
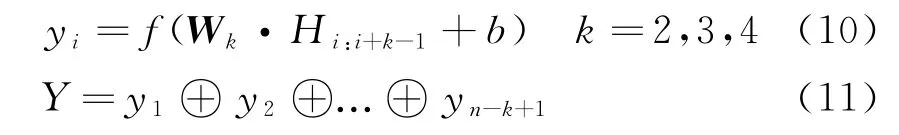
其中,b表示偏置,Wk表示不同卷积核所对应的权值矩阵,i为第i个特征值,k为卷积操作中卷积核的大小,f为激活函数,yi表示卷积后的输出结果,操作⊕为向量拼接操作,Y为得到的最终特征。
为了充分地获取卷积后的语义信息,本文采用基于最大池化和平均池化的组合池化方法,在捕获最显著的特征的基础上同时学习到其周围的语义,如式(12)~式(14)所示。
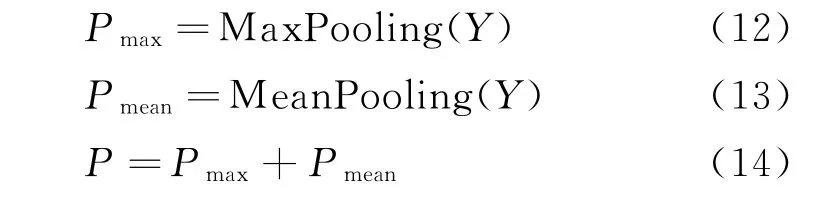
其中,Pmax表示最大池化的结果,Pmean表示平均池化的结果,P表示两种池化方式融合的结果。
2.2 多卷积核DPCNN
Johnson R 等[21]提出了深层金字塔卷积网络(deep pyramid convolutional neural networks,DPCNN),该模型通过等长卷积(equal-width convolution)的方式进行region embedding,可以将每个词及其左右相关词的语义信息压缩为中心词位的embedding,通过堆叠两层的方式有效地提高了中心词位表示的丰富度。为获取文本的长距离依赖,在不改变整个语义空间的前提下通过size=3,stride=2 的池化使得语义长度减半,简称1/2 池化,增大了模型感知长文本片段的能力。基于上述操作,DPCNN 利用固定大小的卷积核提取局部语义信息,这点与CNN 相异。该模型通过残差连接的方式多次重复等长卷积、1/2池化,有效减小梯度传播的难度。
大多数卷积神经网络初步提取语义信息是通过卷积核在词向量上平移提取的方式。可见,随机初始化的卷积核参数对模型的结果有着重要作用。为减少初始化DPCNN 模型中单个卷积核数值对实验结果的不确定性影响,本文提出一种多卷积核的DPCNN 模型,完成文本语义知识的学习,即随机初始化多个相同大小、参数不同的卷积核,用于提取预先训练的词向量的语义信息,并在最后融合,获取所有语义信息。
2.3 Softmax分类
MDPLC模型通过融合Bi-LSTM+CNN 和多卷积核DPCNN 学习到的语义信息,将获取的语义信息通过Softmax层,把输入值转换为概率值,输出概率最大的类别,从而完成维吾尔语文本分类任务,如式(15)所示。

其中,i为分类的标记,本文实验用到了8个标记类别,所以i∈{1,2,3,4,5,6,7,8},D为输入的文本,θ表示模型训练学习到的参数,模型最后输出概率值最大的类别。
2.4 算法描述
本文使用的Bi-LSTM+CNN 模型采用了组合池化而非单一池化的方法,该方法能够有效获取显著特征和周围语义的特征。而多卷积核DPCNN 能从多个角度对文本的语义信息进行学习,减少单一卷积核在学习语义信息时随机初始化导致的不确定性影响。MDPLC模型以双通道的方式融合上述两种模型捕捉到的文本语义信息,完成分类。该模型算法描述如算法1所示。

算法1 MDPLC文本分类模型__________________________输入:维吾尔语文本输出:类别标签1.Begin 2.对数据进行预处理操作;3.通过Word2Vec中的Skip-gram 方法训练词向量得到emb;4.#RCNN 5.将训练好的词向量输入到Bi-LSTM 中,获取其语义特征lstm_feature;

6.out_feature=Concate(axis=1)([emb,lstm_feature]);7.merge_p=[];8.For index,filter_size∈[2,3,4]9.Begin 10.conv_result=conv(out_feature,filter_size);11.p1=mean_pooling(conv_result);12.p2=max_pooling(conv_result);13.merge_pool=Add()([p1,p2]);14.merge_p.append(merge_pool);15.End 16.out_cnn=Concate(axis=1)([merge_p[0],merge_p[1],merge_p[2]);17.# 多卷积核DPCNN 18.conv2=[]19.for i in range(3):20.Begin 21.以等长卷积的方式得到region_embeding;22.使用kernal_size=(3,1)的二维卷积对region_embeding进行卷积,得到conv1;23.while x.size()[2]>2:24.Begin 25.通过size=3,stride=2的池化操作;26.使用kernal_size=(3,1)的卷积核进行两次卷积,得到conv;27.conv2.append(conv);28.End 29.End 30.out_mdpcnn=Concatenate(axis=1)([conv2[0],conv2[1],conv2[2]]);31.merge_pool=Add()([out_cnn,out_mdpcnn]);32.利用训练好的MDPLC模型进行预测,得到分类结果33.End_______________________________________________
3 实验结果及其分析
3.1 实验环境说明
实验硬件配置为:GPU 为RTX-2080Ti,CPU 为i7-9700。软件环境为:操作系统为Ubuntu 18.04,编程语言为Python 3.6,框架为Py Torch 1.1.0。
3.2 实验数据收集及语料处理
由于没有公开的维吾尔语文本分类数据集,本文在Nur网、昆仑网(新疆板块)、天山网等维吾尔语新闻网站爬取了14 723条语料,共计八个类别,分别是财经、彩票、科技、旅游、社会、时尚、体育和娱乐,并对该数据集进行基本的预处理操作,如去除网页标签、去除标点和拉丁化等操作。
为验证模型对短文本和长文本的分类效果,本文将维吾尔语新闻的标题(平均长度为9个单词)作为短文本数据集,新闻内容本身(平均长度为264个单词)作为长文本数据集。由于部分新闻是图片新闻,内容较短,仅从文本角度考虑并不足以反映该条语料的所属类别,本文将此类数据从数据集中剔除,所以长文本数据集共计14 541条。本文按照7:2:1的比例随机将两个数据集划分为训练集、验证集和测试集。短、长文本数据集分布如表1所示。

表1 文本数据集分布
3.3 评价指标
在本文的实验中,采用三个评价指标来评估模型,分别是精准率(Precision,P)、召回率(Recall,R)、F1值(F1-score),计算如式(16)~式(18)所示。


3.4 对比模型说明
FastText[22]:该模型与Word2Vec中的CBOW相似,不同的是CBOW 输出的是词向量,而Fast Text输出的是预测的标签。
TextCNN[10]:TextCNN 模型通过卷积、池化、全连接对维吾尔语进行分类。
Bi-LSTM[18]:由前向LSTM 和后向LSTM 组合而成,双向的LSTM 可以更好地捕捉其语义信息。
DPCNN[21]:该模型是由Rie Johnson提出的更深层级CNN 模型的一种变体。
多卷积核DPCNN:与文献[21]不同,初始化多个大小相同、参数不同的卷积核对文本语义信息进行提取完成分类。
Bi-LSTM+CNN:由Bi-LSTM 完成对文本语义信息的捕捉,再通过组合池化的CNN 对局部语义信息进行提取,从全局和局部两个层级提取语义依赖完成文本分类。
MDPLC:本文提出的模型,采用多卷积核DPCNN 和Bi-LSTM+CNN 双通道融合方式学习语义表示知识。
3.5 实验对比结果及分析
3.5.1 维吾尔语文本分类实验对比结果及分析
为验证MDPLC模型在维吾尔语短、长文本分类任务中的性能,本文进行了该模型与主流深度学习的对比实验,实验结果如表2所示。

表2 维吾尔语长短文本结果对比表 (单位:%)

续表
表2呈现了本文提出的MDPLC模型和现有模型的实验对比结果。无论在何种情况下,MDPLC模型在维吾尔语短、长文本的分类任务中,三个评价指标都取得了最高精度。由表2 可以看出:
(1)MDPLC 模型在维吾尔语短、长文本分类任务中的有效性都得到了验证,原因在于该模型应用Bi-LSTM 初步完成了文本语义信息的获取,并采用基于组合池化的CNN模型加强了对局部信息的学习。在此基础上,以双通道的方式进一步融合多卷积核DPCNN提取到的语义信息。并行的方式能有效避免在文本分类中过深的深度学习模型导致的梯度消失问题,从而提高维吾尔语文本分类器的性能。
(2)考虑到维吾尔语形态丰富的特性,本文借鉴了文献[5]基于词干序列的文本分类方法,采用NLP-Cube①https://github.com/adobe/NLP-Cube工具和Char-CRF[23]两种词干提取方法进行了以词干为语义单元的实验。MDPLC模型在以词和词干为表示的文本分类任务中取得的精度均优于文献[20]所提出模型的方法。证明了该模型的优越性。
(3)无论是哪种模型,在长文本分类任务上的性能表现均较好,而在短文本上较差。这是因为相对于短文本,长文本的文本长度更长,文本蕴含的语义信息更多,使得模型能够更容易地捕获语义信息,从而能够有效帮助模型完成分类任务。但是,在长文本分类任务中,以词为语义单元取得的精度较高,这是因为文本长度的增加导致了词干提取工具提取的错误词干增多,使得输入模型的语义信息表示出现偏差。
3.5.2 中、英文文本分类实验对比结果及分析
本文采用中文新闻数据集THUCNews[24](约74万)标题和英文新闻数据集AGNews[25](约32.8万)作为分类任务数据集。为验证该模型在不同训练集数量下的性能,本文在不改变测试集数量的前提条件下随机抽取THUCNews、AGNews训练集的1%、5%、25%、50%和100%进行了实验。实验结果(F1值)如图4和图5所示。

图4 多种模型在THUCNews上的分类结果

图5 多种模型在AGNews上的分类结果
由图4和图5还可以看出:在中、英文文本分类任务中,MDPLC模型取得的F1值优于其余的主流文本分类模型,并且该模型在使用1%、5%和25%的训练集时取得的精度明显优于其他模型,验证了该模型在不同语言文本分类任务中的性能。
3.6 消融实验
为了探究MDPLC中多卷积核DPCNN 卷积核的个数(nums)对实验结果的影响,本文分别使用nums=[2、3、4]的MDPLC模型在维吾尔语短、长文本上进行了验证实验。实验结果如图6、图7所示。
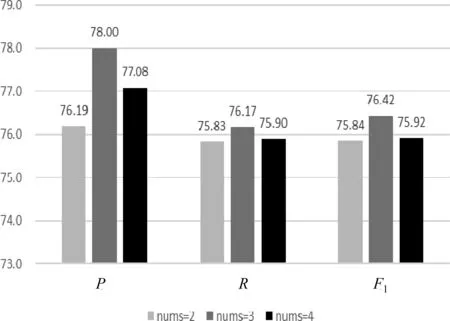
图6 nums取值对MDPLC 模型在维吾尔语短文本分类任务中的影响

图7 nums取值对MDPLC 模型在维吾尔语长文本分类任务中的影响
由图6、图7 可知,当nums 的取值为3 时,MDPLC 模型在维吾尔语短、长文本分类任务中均取得了最好的性能。当nums的取值为2时,该模型的分类性能有所下降,这是因为nums为2的模型不能全面地学习文本中蕴含的语义信息,语义学习的不充分导致了精度的下降;当nums的取值为4时,该模型的分类性能也在下降,这是因为nums为4的模型学习到了文本中过多的噪声信息,出现了过拟合的现象。所以,本文选用nums为3的MDPLC模型,该模型在维吾尔语长文本分类任务中取得的P、R和F1值分别为87.78%、87.22%和87.15%,在维吾尔语短文本分类任务中取得的P、R和F1值分别为78.00%、76.17%和76.42%。
4 结论及展望
针对维吾尔语形态丰富且资源匮乏的难点,本文提出了MDPLC深度学习模型,融合Bi-LSTM+CNN 与多卷积核DPCNN 并行获取的语义信息完成分类任务。实验结果表明,该模型在维吾尔语短、长文本分类的任务中都取得了较好的结果。为了进一步验证模型的有效性,本文在中文、英文文本中进行了实验比对,并且探究了模型中多卷积核DPCNN 中卷积核个数对实验结果的影响,为进一步的研究提供了参考。
从实验结果看,维吾尔语短、长文本分类的精度还有长足的提高空间,在将来的研究中,我们将引入除维吾尔语以外的低资源黏语,如哈萨克语、柯尔克孜语等。我们还会考虑引入时间指标进行实验探究,期望更快、更好地完成维吾尔语的文本分类任务。
猜你喜欢
科学技术与工程(2023年3期)2023-03-15
软件导刊(2022年3期)2022-03-25
新一代信息技术(2021年22期)2021-12-29
开放教育研究(2020年2期)2020-03-31
计算机技术与发展(2019年1期)2019-01-21
自动化学报(2017年4期)2017-06-15
现代语文(2016年21期)2016-05-25
新疆大学学报(哲学社会科学版)(2015年5期)2015-10-12
语言与翻译(2015年4期)2015-07-18
大连民族大学学报(2015年2期)2015-02-27
