
融合词义信息的文本蕴涵识别方法
2021-08-13 07:43杜倩龙宗成庆苏克毅
中文信息学报 2021年7期
杜倩龙,宗成庆,苏克毅
(1.中国科学院自动化研究所模式识别国家重点实验室,北京100190;2.中国科学院大学人工智能学院,北京100049;3.台湾“中央研究院”资讯科学研究所,台湾台北11529)
0 引言
文本蕴涵识别(recognizing textual entailment,RTE)旨在利用各种分析手段有效理解文本的语义,然后推理出文本之间的语义蕴涵关系。如表1所示,该任务通常给定一个前提文本P(premise)和一个假设文本H(hypothesis),然后判定是否可以从前提文本P的语义中推理出假设文本H 的含义,从而推断出文本P 和文本H 之间的关系是蕴涵(entailment)、中立(neutral)还是矛盾(contradiction)。文本蕴涵识别有效解决了语言表达的多样性和歧义性问题,被广泛应用于自动问答[1]和文本摘要[2]等自然语言处理任务中。为了有效评估文本蕴涵识别系统的性能,在过去的十几年间学界组织了大量的文本蕴涵识别相关评测,例如,RTE[3]和Sem Eval-2014[4]等。早期的文本蕴涵识别相关研究都是在小规模的数据集之上,基于人工定义的规则和特征,利用传统的统计学方法、规则方法和逻辑推理方法等进行的文本间蕴涵关系的判定[5-6]。

表1 文本蕴涵识别样例
随着深度神经网络方法的快速发展和大规模文本蕴涵识别数据集SNLI[7]和MultiNLI[8]的出现,基于神经网络的文本蕴涵识别方法[7-17]开始大量涌现并取得了很好的效果。神经网络文本蕴涵识别方法主要采用神经网络结构对两个输入文本进行编码,从而生成文本的向量表示,然后对这两个输入文本的向量表示进行比较,最终判定文本之间的语义蕴涵关系。在上述方法中,为了更好地推理文本间的蕴涵关系,有学者提出了基于文本间信息交互的神经网络文本蕴涵识别方法,该类方法采用注意力机制对文本间不同粒度的语义信息进行对齐和比较,并将不同粒度间的比较信息进行融合,从而预测文本之间的语义蕴涵关系[11-14,17]。基于文本间信息交互的识别方法在文本蕴涵识别数据集上取得了最优的效果,并受到学者越来越多的关注。
然而,当前基于信息交互的神经网络文本蕴涵识别方法[11-14,17]主要关注采用大规模的无监督数据对模型和词向量进行预训练,或者构建更加复杂的网络结构对文本间的语义信息进行对齐和比较,而忽略了词义信息对文本蕴涵识别的作用。
下面以表1中的文本对(1)为例:
P:Tom will join the board of the film company as a nonexecutivedirector.
H:Tom is a filmdirector.
对于该文本对,在对文本P和文本H 之间的蕴涵关系进行判定时,现有基于文本间信息交互的识别方法[11-14,17]通常采用注意力机制对文本之间的词汇表示进行对齐,然后将文本中的词汇与其在另一个文本中的对齐信息进行比较,最终通过融合所有的比较信息预测文本之间的关系标签。在上述方法中,词汇“director”在文本P 和文本H 中具有相同的初始化向量。如果现有文本蕴涵识别模型无法有效地对词汇“director”在这两个文本中的词义表示进行建模,模型将错误地将假设文本H 和前提文本P之间的关系判定为“蕴涵”(假设文本H 中所有词汇的表示向量均可以在前提文本P 中找到其匹配项)。
针对上述问题分析之后发现,文本中词汇的词义信息可以有效改善词汇在文本中的语义表示,从而改进文本间语义关系的推理。例如,对于文本对(1)中的词汇“director”,其在文本P和文本H 中对应着不同的词义。对于该词义,其对应的语义分别为:
(a)member of a board of directors
译文:董事会成员
(b)the person who directs the making of a film
译文:导演
(a)和(b)分别为词汇“director”在文本P 和文本H 中的词义在Word Net[18]中对应的释义信息,该释义信息很好地描述了目标词汇在对应上下文中的语义。因此,为了有效构建词汇“director”在文本P和文本H 中的向量表示,本文首次提出了利用词义(a)和词义(b)对应的释义信息生成其表示向量,并将该表示向量作为词汇“director”在对应文本中的初始化向量。在此基础上,本文进一步提出了利用词义之间的关联信息(例如,上下位关系和蕴涵关系等)改善文本之间的语义关系推理。综上所述,本文提出了一个融合词义信息的文本蕴涵识别模型(incorporating word sense information for recognizing textual entailment,IWSI-RTE),该模型利用词汇的词义信息改善文本中词汇的语义表示和文本间语义关系的推理,从而有效提升了文本蕴涵识别的准确率。
1 相关工作
随着深度神经网络方法的快速发展和大规模文本蕴涵识别数据集SNLI[7]和MultiNLI[8]的出现,基于深度神经网络的文本蕴涵识别方法开始大量涌现,并显著提升了文本蕴涵识别系统的性能。依据是否对文本间的语义信息进行交互,可以将现有的神经网络文本蕴涵识别方法划分为两类:①基于句向量的文本蕴涵识别方法[7,10],该类方法首先利用神经网络模型分别生成前提文本和假设文本的句向量表示,然后对这两个文本的句向量表示进行比较;②基于文本间信息交互的识别方法[11-14],该类方法利用注意力机制对文本间不同粒度的语义信息进行对齐和比较,并将比较后的信息进行融合,从而推断出文本之间的蕴涵关系。
在基于句向量的文本蕴涵识别方法中,Bowman等人[7]提出了利用长短期记忆网络(long shortterm memory,LSTM)分别生成前提文本(P)和假设文本(H)的向量表示,然后利用一个三层的前向网络对文本P和文本H 的向量表示进行比较,从而预测最终的关系标签。此外,为了更好地抽取文本中词汇之间的依存信息,Mou等人[10]提出了基于树结构的神经网络识别方法,该方法利用树结构的卷积神经网络对输入文本进行编码,然后对编码后的向量表示进行比较。
在基于文本间信息交互的文本蕴涵识别方法中,Chen等人[12]于2017年提出了一个增强型序列推理模型(enhanced sequential inference model,ESIM)。在该模型中,Chen 等人利用双向LSTM网络结构对两个输入文本进行处理,从而生成文本中所有词汇的向量表示,然后利用注意力机制计算两个文本中所有词汇之间的对齐权重。对于任意词汇,利用对齐权重计算其在另一个文本中的相关语义向量,并将该词汇的向量与其相关语义向量进行比较,从而生成该词汇对应的比较信息。最终,通过融合所有词汇的比较信息预测文本对之间的关系标签。在此基础上,Chen等人[13]于2018年进一步提出了一个基于结构知识的推理模型(knowledgebased inference model,KIM),该模型利用人工构造的知识资源Word Net抽取词汇之间的关联信息,然后将其添加到ESIM 模型的词汇对齐、局部推理和推理信息融合的过程中,从而进一步提升了文本蕴涵识别的准确率。在利用Word Net抽取词汇之间的关联信息时,该模型不对词汇的词义进行判定,而是直接对词汇所有词义之间的关系进行比对。此外,在Transformer[19]结构出现以后,Devlin等人[20]提出了利用深度双向Transformer结构编码文本表示的模型,该模型在一个深层Transformer结构上利用大规模无监督数据对模型参数进行预训练,然后在文本蕴涵识别任务上对模型参数进行微调。
现有识别方法主要关注如何构造更加复杂的网络结构对文本中的语义信息进行对齐和比较,或者利用大规模的无监督数据对模型和词向量进行预训练,而忽视了传统语言学信息在判定文本间语义蕴涵关系时的作用。不同于上述方法,本文将探究传统语言学信息是否可以有效改善文本蕴涵识别的效果,以及如何在神经网络模型中有效融合词汇的语言学信息。基于此,本文提出了一种融合词义信息的文本蕴涵识别方法,该方法利用输入文本中词汇的词义信息改善文本的语义表示和文本间语义关系的推理,从而有效提升了文本蕴涵识别的准确率,且具有很好的可解释性。不同于KIM 模型中利用Word Net抽取词汇所有词义间的关联信息,然后利用该关联信息改善词汇对齐和关系推理的方法,本文提出了直接将输入文本转换为对应的词义序列,然后对词义序列中的词义进行对齐和比较。此外,为了更好地表示词义序列中的词义,本文提出了利用Word Net中词义的释义信息生成词义的向量表示,并利用词义间的关联信息改善词义间的关系推理。
2 融合词义信息的文本蕴涵识别方法
2.1 预处理
为了有效利用文本中词汇的词义信息推断文本间的语义蕴涵关系,对于输入的前提文本(P)和假设文本(H),本文首先利用词义消歧工具对文本中所有的词汇进行处理,从而推断出每个词汇对应的词义,并利用Word Net[18]中的词义标签表示该词义。特别地,对于在Word Net中不存在词义的词汇(例如,介词、冠词和情态动词等),本文直接利用词汇本身表示其词义。如图1所示,本文依据上述方法将原始的词汇序列转换为一个新的词义序列,该序列中的词义标签对应着目标词汇的词义。对于词义序列中标定的词义,本文进一步提出了利用Word Net中词义的释义信息对其进行表示。表2展示了文本蕴涵识别样例中部分词汇的词义及其在Word Net中对应的释义信息。

表2 输入文本中词汇的词义及其在WordNet中对应的释义

图1 原始词汇序列转换为词义序列
2.2 模型方法
对于输入的文本P和文本H,通过对其进行预处理分别生成对应的词义序列。为了有效推理文本间的语义蕴涵关系,本文将分别对输入文本的词汇序列和词义序列进行比较,并将比较信息进行融合,从而预测最终的关系标签。
图2 展示了本文提出的IWSI-RTE 模型的整体框架,该模型主要包含三层网络:①编码层,该层分别对文本的词汇序列和词义序列进行编码,从而分别生成词汇和词义的向量表示;②交互层,该层分别对两个文本的词汇序列和词义序列进行对齐和比较,从而分别生成对应的比较向量;③推理层,该层利用词汇及词义与另一个文本间的比较向量生成对应的局部蕴涵信息,然后将所有的局部蕴涵信息进行融合,从而预测文本间的蕴涵关系。

图2 IWSI-RTE模型的整体结构框架
2.2.1 编码层
对于文本P和文本H,该层分别对其词汇序列和词义序列进行编码,从而生成每个词汇和词义的向量表示。
(1)编码词汇序列
定义两个输入文本的词汇序列分别为P=(p1,p2,…,pm)和H=(h1,h2,…,hn)。pi表示词汇序列P中的第i个词汇,而hj则表示序列H中的第j个词汇。m和n为这两个序列对应的词汇数目。对于词汇序列P中的任意词汇pi,利用表示其对应的初始化向量,进而得到词汇序列P的初始化向量序列为。同理,得到序列H的初始化向量序列。
词向量:本文采用Glo Ve[21]词向量对所有词汇进行初始化。
词汇特征:受到Chen等人[22]工作的启发,本文在对词汇进行初始化时融合了一些语言学特征,包含了词性、命名实体和归一化的词频,并将其分别表示为one-hot向量。
词汇匹配特征:本文采用了三种文本间词汇的匹配特征,这些特征表示另一个文本中是否存在目标词汇的原始形式、小写形式和词干形式,并用一维的0或者1值表示这些特征。
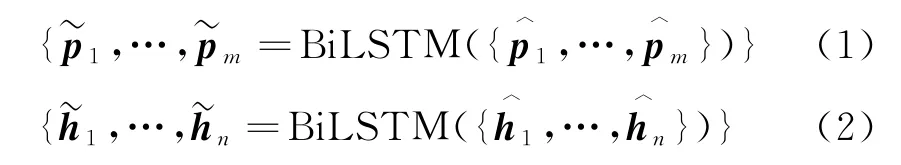
(2)编码词义序列
如2.1节所述,通过预处理过程本文分别得到文本P 和文本H 的词义序列。定义和分别表示文本P和文本H 的词义序列。和分别对应文本P和文本H 中第i个和第j个词汇的词义。此外,定义分别表示文本P和文本H 词义序列的初始化向量序列,和为词义和对应的初始化向量。
词义向量:对于词义序列中的每个词义,其在Word Net[18]中对应着一个释义,本文通过对该释义中所有词汇的词向量采用最大值池化操作生成词义的向量表示。此外,对于无法利用Word Net标注词义的词汇,本文采用Glo Ve[21]词向量对其进行初始化。
词义特征:本文采用了四种描述文本间词义关系的特征,这些特征表示另一个词义序列是否存在目标词义的相同词义、下位义(hypernym)、上位义(hyponym)和存在蕴涵关系的词义。这四类特征表示为一维的0或者1值。此外,本文还添加了词义在对应序列中的归一化频率,并将该特征表示为一个one-hot向量。

2.2.2 交互层
利用编码层分别生成词汇序列和词义序列的向量表示后,交互层将分别对文本P和文本H 的词汇序列和词义序列进行对齐和比较,从而生成每个词汇及词义与另一个文本之间的比较向量。特别地,在比较时本文对词汇序列和词义序列采用相同的对齐和比较策略。下面将对文本间语义信息对齐和比较的具体过程进行介绍。
对于词汇序列中的词汇pi和hj,首先利用向量的内积操作计算其对齐权重,具体计算如式(5)所示。

其中,ei,j表示词汇pi和词汇hj之间的对齐权重。和分别为词汇pi和hj编码后的向量表示,具体如式(1)和式(2)所示。
计算得到词汇序列P和词汇序列H间所有词汇的对齐权重后,对于词汇pi,模型将利用该对齐权重对词汇序列H中所有的词汇信息进行融合,从而计算词汇pi的相关语义向量ui。同理,利用对齐权重将词汇序列P中的所有词汇信息融合,从而计算词汇hj的相关语义向量vj。
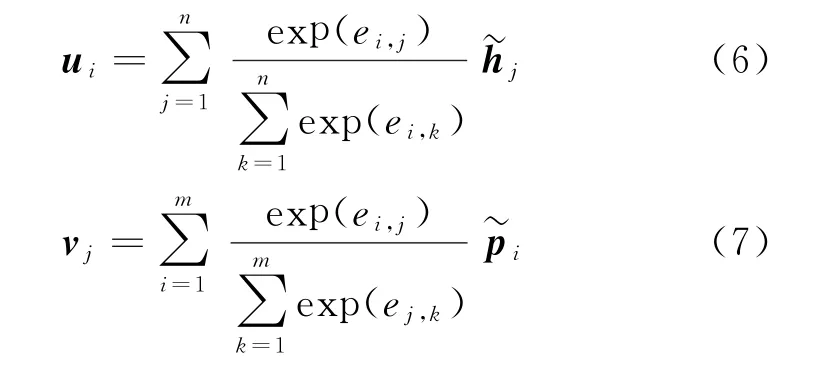
计算得到词汇的相关语义向量后,对于词汇pi,将其词汇向量与其相关语义向量ui进行比较,从而生成词汇pi和词汇序列H间的比较向量;同理,将hj的词汇向量和相关语义向量也进行比较,具体计算如式(8)、式(9)所示。

其中,G表示激活函数为relu 的单层前向网络。“;”表示向量的拼接操作,“-”表示向量的减法操作,而“⊙”则表示向量的点乘操作。表示词汇pi和词汇序列H间的比较向量;则表示词汇hj和词汇序列P之间的比较向量。
与词汇序列间的对齐和比较策略相同,对于词义序列Ps中的词义,将其与词义序列Hs中的所有词义进行对齐和比较,从而得到与词义序列Hs之间的比较向量;同理,计算得到词义和词义序列Ps之间的比较向量。
2.2.3 推理层
该层分别利用词汇和词义的比较向量生成对应的局部蕴涵信息,然后将所有的局部蕴涵信息进行融合,从而预测文本间的关系标签。
(1)序列间局部蕴涵信息推理及融合
为了有效利用词汇序列之间的比较向量生成对应的蕴涵信息,将词汇序列P和H对应的比较向量序列分别输入到双向LSTM 中进行处理,从而得到每个词汇所对应的局部蕴涵信息,具体计算如式(10)、式(11)所示。
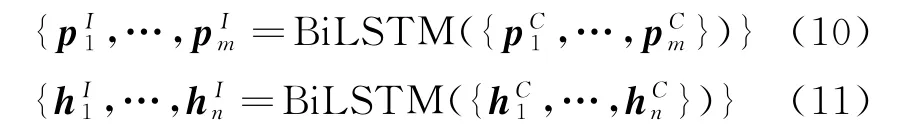

其中,OP和OH表示将词汇级别蕴涵信息融合后得到的序列P和序列H之间的推理向量,且分别代表着不同的比较方向。OP表示将词汇序列P中的词汇与序列H进行比较,OH则表示将词汇序列H中的词汇与序列P进行比较。
得到上述推理向量后,将这两个向量进行拼接并输入到一个前向网络中,从而计算词汇序列P和词汇序列H间的全局推理向量,具体计算如式(14)所示。

其中,F是一个激活函数为relu的单层前向网络。O表示词汇序列P和词汇序列H之间的全局推理向量。
同理,对于词义序列Ps和Hs中的词义和,本文利用与式(10)中相同的方法对其比较向量和进行处理,从而生成词义和所对应的推理向量。然后将所有词义对应的推理向量进行融合(如式(12)~式(14)所示),从而生成词义序列Ps和Hs之间的全局推理向量Os。
(2)结果预测
利用上述操作分别得到词汇序列和词义序列间的全局推理向量后,将这两种不同类型的全局推理向量进行融合,并输入到一个多层前向网络Q中,从而预测文本之间的语义蕴涵关系,具体计算如式(15)所示。

其中,Q表示一个两层的前向网络,其激活函数分别为relu和softmax。O和Os分别表示词汇序列和词义序列间的全局推理向量,max和avg表示向量间的最大值和均值操作。表示最终的预测向量,向量维度为3。
3 实验
3.1 实验数据
本文采用了两个数据集对模型性能进行测试,分别为:SNLI[7]和MultiNLI[8]。下面分别对其进行介绍。
SNLI该数据集是Bowman等人[7]于2015年公开的第一个大规模文本蕴涵识别数据集,包含了570 152个英文文本对。在该数据集中,文本间的关系标签被标注为蕴涵、矛盾或者中立。特别地,由于标注者在部分文本对的蕴涵关系上无法达成一致,这些文本对间的关系标签被标注为“-”。在实验时,本文将标注为“-”的文本对删除。因此在真实的训练过程中,训练集包含了549 367个文本对,而开发集和测试集则分别包含了9 842和9 824个文本对。
MultiNLI该数据集是由Williams等人[8]于2018年公开的大规模英文文本蕴涵数据集,一共包含了43.3万个文本对,且覆盖了多个领域的英文数据,包括书面语类、口语类和非正规书写类等。此外,为了更好地评估模型的性能,Williams等人依据是否与训练数据来自相同的领域,将开发集和测试集划分为领域内数据(matched)和领域外数据(mismatched)两种类型。
3.2 实验设置
在对模型进行训练时,本文采用Adam 算法对参数进行优化,并利用300维的Glo Ve[21]词向量对输入文本进行初始化。基于相应的开发集,本文将批大小设置为32,并采用大小为0.000 4的学习率,同时将SNLI、matched和mimatched数据集上网络结构的隐层维度分别设置为400、400和450。此外,为了避免过拟合,本文还采用了dropout策略,并将概率值设置为0.2。在预处理步骤对输入文本中词汇的词义进行标注时,本文采用了Du等人[23]的方法标注文本序列中词汇的词义。该方法利用词汇的局部上下文信息和词汇之间的结构依存信息推断目标词汇的词义,从而生成整个句子的词义序列。该方法采用词义消歧数据集Semcor对模型进行训练,然后对词汇的词义进行判定。
3.3 结果分析
表3展示了模型在SNLI数据集上的测试结果。在表3展示的模型中,Parikh等人[11]提出了一个可分解注意力模型[模型(2)],该模型将文本蕴涵识别划分为对齐、比较和融合三个子任务进行处理。在此基础上,模型(6)提出了ESIM 模型,该模型利用双向LSTM 网络对文本中的词汇进行编码从而生成词汇的向量表示,然后利用句间注意力(interattention)机制对文本之间的词汇表示进行对齐和比较,最终预测文本间的蕴涵关系。该模型成为文本蕴涵识别领域的代表性模型。此外,模型(9)在ESIM 模型的基础上进一步提出了一种利用Word Net中人工构造的结构知识改善文本间语义信息对齐和推理的方法,该方法不对文本中词汇的词义进行标注,而是直接利用词汇所有词义间的关联信息改善文本间词汇的对齐和关系推理。模型(10)则在ESIM 模型的基础上提出了利用大规模无标注数据改善词汇的向量表示,从而提升了文本蕴涵识别系统的推理性能。

表3 模型在SNLI测试集上的准确率
不同于上述方法,本文在ESIM 模型的基础上提出了融合词义信息的文本蕴涵识别模型IWSIRTE,该模型利用词汇的词义信息改善文本的语义表示和文本间语义关系的推理。从表3 中可以看出,IWSI-RTE模型在SNLI数据集上的准确率达到了88.6%,优于表中大多数模型。特别地,相比于基线模型ESIM,IWSI-RTE 模型的性能有明显提升。此外,相比于模型(9)中利用结构知识改善词汇对齐和词汇间关系推理的方法及模型(10)中采用大量无标注数据改善文本语义表示的方法,IWSIRTE模型在性能上也是可比的。相比于人工标注的准确率[模型(11)],IWSI-RTE 模型在SNLI数据集上也取得了更好的效果。
表4展示了不同模型在MultiNLI数据集上的测试结果。模型(1)和模型(2)为基于句向量的文本蕴涵识别模型。模型(3)为基于文本间信息交互的ESIM 模型,该结果为Williams等人[8]发布MultiNLI数据集时所公布的ESIM 模型在该数据集上的测试结果。模型(4)和模型(5)同样为基于句向量的文本蕴涵识别模型。在模型(4)中,Chen等人[29]采用了句内门注意力(intra-sentence gated-attention)机制生成文本的向量表示。模型(5)则利用堆LSTM 及一种跳跃式传递机制生成文本的向量表示。模型(6)为基于词汇依存三元组间独立比较的模型。模型(7)则在ESIM 模型的基础上利用大量无标注数据改善输入词汇的向量表示。此外,在模型(8)中,Chen等人[13]利用外部知识改善文本间语义信息的比较和推理。在模型(9)中,Tay等人[14]采用了一种因式分解网络对文本间的关系进行压缩,然后利用压缩后的信息预测文本间的关系标签。模型(10)则提出了利用卷积神经网络对文本间的语义信息进行交互和比较。
从表4中可以看出,本文提出的IWSI-RTE 模型在MultiNLI的领域内(matched)测试集上优于所有的相关模型。此外,在MultiNLI 的领域外(mismatched)测试集上,IWSI-RTE 模型的性能明显优于模型(1)~模型(8),且与模型(9)和模型(10)的性能也是可比的。特别地,相比于模型(7)中采用大量无标注数据改善词汇表示的方法,以及模型(8)中同样利用Word Net中的结构信息改善词汇对齐和关系推理的方法,IWSI-RTE 模型在这两个数据集上的性能具有明显的提升。

表4 模型在MultiNLI测试集上的准确率
3.4 模型分析
表5 展示了模型中不同策略对最终结果的影响。模型(1)为本文最终的IWSI-RTE 模型。模型(2)表示在对IWSI-RTE 模型中的词义表示进行初始化时,该模型仅采用了词义向量,而没有添加词义特征信息。相比于IWSI-RTE 模型,模型(2)的结果在这三个数据集上分别下降了0.3%,1.0%和0.4%。结果表明,本文所采用的词义特征信息可以改善文本间语义关系的推理。模型(3)表示在模型(2)的基础上继续去除词义向量间的比较信息,仅利用词汇信息对文本间的语义信息进行对齐和比较。从表中可以看出:相比于模型(2),当在模型(3)中仅利用词汇信息判定文本间的蕴涵关系时,模型的性能分别下降了0.1%,1.0%和1.0%。这表明本文所采用的词义向量信息也可以改善文本间语义关系的推理,且与词汇特征信息对推理性能的影响大致相当。模型(4)在模型(3)的基础上继续去除了词汇特征和词汇匹配特征信息。模型(4)为本文的基线系统,即ESIM 模型,所呈现的结果为本文在实现时对ESIM 模型部分参数进行调整后得到的结果。为了测试词义信息编码时不同网络结构对识别效果的影响,在模型(5)中本文展示了利用BiLSTM 网络对词义序列进行编码时模型的识别性能。从表中可以看出,相比于IWSI-RTE 模型,模型(5)的性能在所有数据集上均有所下降。这表明,采用前向网络结构能够更好地生成词义的向量表示,且具有更好的可解释性。

表5 消融分析
模型(6)~模型(8)展示了不同的词义信息融合策略对测试结果的影响。如式(15)所示,在对词汇序列以及词义序列间的全局推理向量进行融合时,IWSI-RTE模型首先对词汇序列间的全局推理向量和词义序列间的全局推理向量进行均值操作和最大值操作,从而生成两个全局推理向量间的均值向量和最大值向量。然后,模型将该均值向量和最大值向量与对应的全局推理向量进行拼接并输入到一个前向网络中,从而预测文本间的语义蕴涵关系。不同于上述方法,模型(6)直接将词汇序列间的全局推理向量与词义序列间的全局推理向量进行拼接,然后预测文本间的关系标签。模型(7)则在模型(6)的基础上添加了全局推理向量间的均值操作。同理,模型(8)在模型(6)的基础上添加了全局推理向量间的最大值操作。从表中可以看出,IWSI-RTE 模型中融合三类推理向量(原始推理向量、推理向量间均值和推理向量间最大值)的方法取得了最好的效果。
模型(9)和模型(10)则展示了词义向量的生成策略对测试结果的影响。在IWSI-RTE 模型中,本文利用最大值池化操作对词义释义信息中所有词汇的向量表示进行处理,从而生成词义的向量表示。不同于该方法,模型(9)采用求和池化操作对词义释义信息中所有词汇的向量表示进行融合,而模型(10)则采用均值池化操作对词义释义信息中所有词汇的向量表示进行融合。从表中可以看出,IWSIRTE模型中采用最大值池化操作的方法取得了最好的效果。
词汇的词义信息可以有效改善文本中多义词及同义词的向量表示,从而改善文本间语义信息的对齐和比较。为了分析词义信息对不同类型文本对间蕴涵关系判定的影响,本文在SNLI和MultiNLI领域内数据集①由于MultiNLI数据集未公开测试集中文本对之间的语义蕴涵关系,因此本文在开发集上对模型在不同类型文本对上的结果进行分析。不同类型文本对上对所提模型的性能进行了测试。如表6所示,本文展示了SNLI开发集中不同类型文本对的数目及模型的测试结果。表中的模型“baseline+additional features”表示未融合词义信息的识别模型。从表中可以看出,当融合词义信息时,IWSI-RTE 模型在不同类型文本对上的性能均有一定的提升。特别地,在语义关系为“蕴涵”的文本对上,模型IWSI-RTE 的性能提升要优于另外两种类型的文本对。
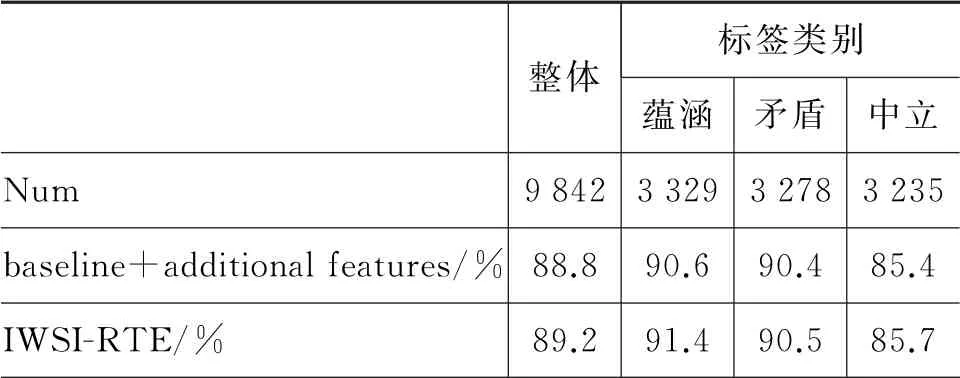
表6 SNLI开发集上不同标签类型的测试结果
此外,表7 展示了模型在MultiNLI领域内开发集上的测试结果。从表中可以看出,模型IWSIRTE的性能在开发集中不同类型文本对上的提升大致相当。整体来说,在该数据集中词义信息对不同类型文本对的性能提升没有明显的差异。综上所述,多义词或同义词问题与具体的文本对类型没有一定的关联性,而是与数据集中的样本分布相关。

表7 MultiNLI领域内开发集上不同标签类型的测试结果
3.5 词义作用分析
如表8所示,为了验证词义消歧准确率对文本蕴涵识别的影响,本文展示了采用不同词义消歧方法时文本蕴涵识别模型的性能。IWSI-RTE(MFS)表示采用最大频率词义(the most frequent sense,MFS)消歧方法对文本中词汇的词义进行判定。MFS 词义消歧方法在词义消歧标准数据集senseval-2和senseval-3 上分别达到了61.9%和62.4%的准确率,而IWSI-RTE 方法中采用的Du等人[23]的词义消歧方法则分别达到了66%和69%的词义消歧准确率。实验结果表明,当词义消歧的准确率提升时,文本蕴涵识别系统的推理性能也有明显提升。由于现有的词义消歧方法还无法取得很好的效果,这也成为制约本文所提出的文本蕴涵识别方法的瓶颈。然而,论文中的实验结果表明,在词义消歧结果不是很理想的情况下,文本蕴涵的识别性能仍然有所改进。该结果再次表明,词汇的词义对判定文本之间的语义关系有着重要作用。在未来的工作中,我们将继续探究如何改善词义的判定效果,从而进一步提升文本蕴涵识别系统的推理性能。
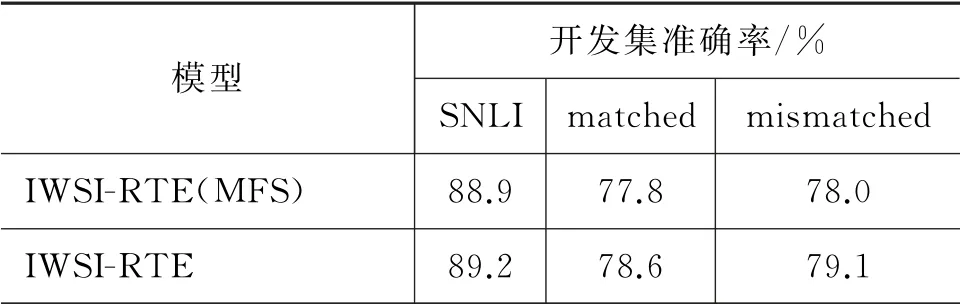
表8 词义作用分析
4 结束语
为了有效利用词汇的词义信息改善文本的语义表示和文本间语义关系的推理,本文提出了一种融合词义信息的文本蕴涵识别方法。通过对文本中词汇的词义进行标注,该方法将原始的词汇序列转化为新的词义序列进行对齐和比较。特别地,为了更好地表示词汇在对应文本中的词义,本文提出了从Word Net中抽取目标词义的释义信息并利用该释义信息生成词义的向量表示。此外,本文还提出了在词义表示中融合文本间的词义关系特征,从而提升了文本间语义关系的推理性能。实验表明,本文所提出的方法可以有效改善文本蕴涵识别系统的推理性能,且具有很好的可解释性。
猜你喜欢
当代陕西(2021年18期)2021-11-27
吉林大学学报(理学版)(2020年3期)2020-05-29
西夏研究(2020年1期)2020-04-01
开放教育研究(2020年2期)2020-03-31
作文大王·低年级(2019年4期)2019-05-13
新高考(英语进阶)(2018年3期)2018-05-14
高校应用数学学报A辑(2016年4期)2016-07-10
现代语文(2016年21期)2016-05-25
大连民族大学学报(2015年2期)2015-02-27
语言与翻译(2014年3期)2014-07-12
