
活塞杆抛光表面微细缺陷的快速筛查技术
2021-08-12 08:29姜庆胜李研彪计时鸣
计算机集成制造系统 2021年7期
姜庆胜,李研彪,计时鸣
(浙江工业大学 机械工程学院,浙江 杭州 310023)
1 问题的描述
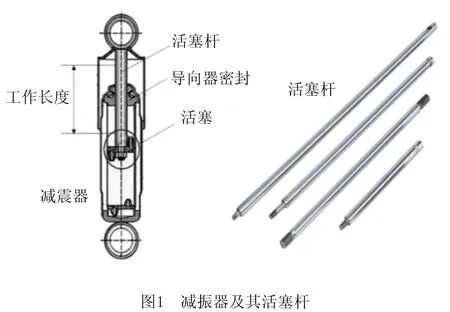
活塞总成是大多数减振器的主要构件之一,得到了普遍应用。如图1所示,活塞杆表面与导向器导向孔表面形成密封面,活塞杆表面品质直接影响减振器密封效果、减振性能和使用寿命。活塞杆是大批量的精密加工产品,在活塞杆交付使用前必须严格剔除存在表面缺陷的不合格产品。目前普遍采用人工肉眼筛查剔除,效率低下,准确率不稳定,且有损工人眼睛健康。
对于表面缺陷检测,李少波等[1]对传统检测方法、基于计算机视觉的检测方法、基于机器学习的检测方法等均作了比较全面的比较。活塞杆是经过抛光的金属圆轴,针对该特征,以往一些学者对表面缺陷的信息采集进行了研究和实验,比较典型的有苏俊宏等[2]采用多次曝光来将柱面合并成一张图片的方法来获取缺陷照片;郭皓然等[3]采用投影照射不断曝光的形式来得到曲面的缺陷照片;ALI等[4]提出对圆柱形表面采用摄像机和多平面镜的方法来获取被检测缺陷表面的信息。
相对于传统的缺陷检测,当今更多的研究是基于计算机视觉和深度学习的表面缺陷检测识别方法,大部分文献都是针对物体平面的缺陷识别。物体平面的缺陷信息获取一般都是通过照片一次或多次拍照得到缺陷图像,在这样的图片基础上采用数字图像的预处理技术去除噪声,然后采用某些算法识别出缺陷[5-9]。总之,采用不同方法获取的图像应根据相应的特征采取不同的图像处理技术来实现检测。
利用机器视觉自动识别表面缺陷是未来技术的发展趋势。罗菁等[10]、汤勃等[11]等对最近几年机器视觉检测方法作了总结;对于机械零件表面缺陷的检测,具有代表性的有RAVIKUMAR等[12]使用直方图统计特征法的研究;TSAI等[13]采用傅立叶特征法的研究;LI等[14]则对于细微缺陷的识别进行了研究。
对于微细缺陷的识别,需要高分辨率图像检测,从而导致图像处理计算量巨大,串行算法效率在许多场合难以满足在线实时检测要求。计算机统一设备架构(Compute Unified Device Architecture, CUDA)可利用中央处理器(Central Processing Unit, CPU)和图形处理器(Graphic Processing Unit, GPU)各自的优点实现计算问题的并行化,为大规模数据计算提供高效计算能力,因此已在图像处理、物理模拟等科学研究领域得到应用。例如,AYDIN等[15]基于CUDA实现了对圆柱形金属表面图像进行并行图像分割,计算速度提升了71倍;PIERRO等[16]将CUDA用于Josephson结的模拟计算,实现了相对i7-6700处理器的400倍加速;YAM-UICAB等[17]通过CUDA C实现了GPU对图像中直线的霍夫变换,较当前最好的串行方法速度提升了10倍;WANG等[18]将CUDA应用于NNP(nearest neighbor partitioning)分类器,实现了近70倍的计算加速;WANG等[19]通过CUDA实现了并行浮动图心算法,针对数据量巨大的航天飞机数据集计算,获得了近90倍的加速;闫钧华等[20]应用CUDA实现了对基于SIFT(scale invariant feature transform)图像配准算法的加速,较在CPU上提速100多倍;王玉亮等[21]基于CUDA实现了眼底图像的快速自动配准与拼接。
本文提出一种针对线扫描图像的基于CUDA并行计算体系的减振器活塞杆抛光表面微细缺陷的快速筛查方法,实现了对16 384×4 096大幅图像中极少微细局部缺陷的并行快速筛查,并应用于减振器活塞杆表面品质实时在线检测系统,解决了通过线扫描方式得到的抛光轴表面缺陷大幅图像中微细局部缺陷的高效筛查的技术瓶颈。
2 活塞杆表面缺陷特征及表面成像方法
活塞杆表面缺陷一般包括坑点、起泡、针孔、脱镀、裂纹、划伤、磕碰伤等,部分典型缺陷如图2所示。图2a、图2b、图2c和图2d分别是小凹坑、缺口、磨损和划伤缺陷。

活塞杆表面具有如下特征:①表面抛光后形成镜面,导致光源照射表面不可避免地形成高光反射区;②可能存在尺度非常小的缺陷,最小缺陷的长宽尺度为0.1 mm,为满足活塞杆表面微小缺陷的检测,图像必须有较高的分辨率。
针对活塞杆表面特征,本文提出一种采用线扫描原理的活塞杆表面成像方法:线扫描相机每次可以成像一个像素单位的一行图像,该行图像成像的空间位置固定,当采用漫反射型条形LED光源照射活塞杆表面时,只要将活塞杆表面的高光反射区避开成像空间位置,成像效果即可得到保障。获取图像时,使活塞杆匀速转动,每转动一个设定的角度单位,线扫描相机采集一行图像,直到活塞杆旋转一周,即可获得活塞杆表面的一幅完整的图像,该方法有效解决了活塞杆表面(轴类零件均有类似问题)难以清晰成像的困难,经线扫描相机获取的活塞杆表面图像,成像质量优良,缺陷与背景灰度差异明显,而且偶然出现的需要预处理的噪声干扰稀疏且独立,如图3所示。

针对小尺度缺陷的检测需求,本文采用1×16 384像素的黑白工业线扫描相机(每一行图像具有16 384个像素),对活塞杆圆周进行4 096等分,即完整的活塞杆表面图像像素尺寸为4 096×16 384,约6 700万像素。本文检测系统的设计适用于直径小于φ24 mm,待检工作区长度小于320 mm的活塞杆检测,周向分辨率为0.018 mm,轴向分辨率为0.02 mm,能可靠检测出尺度大于0.1 mm的缺陷。相机采样速度为48 kHz,完成整幅图像采集耗时约0.085 s。
3 活塞杆表面图像中缺陷的并行筛查算法
3.1 基于TDIIA的滤噪算法
对线扫相机获取的活塞杆表面图像统计分析表明,缺陷与正常表面及干扰噪声对比,具有明显差异:
(1)缺陷像素的灰度介于40~60之间,而正常表面介于90~110之间。
(2)对应缺陷的8连通域像素个数大于80,而偶然出现的图像干扰噪声像素团,8连通域像素个数一般少于16个像素,或呈现线宽为2个像素以下较长的线型噪声。
图像干扰噪声的灰度呈现低于或接近缺陷像素灰度和灰度高于正常表面灰度两种情况。对于后者,只要按正常表面对待,无需处理;对于前者,则需滤除,以免误判为缺陷。噪声像素团面积小于4×4像素,如图4所示为部分噪声像素团的实例,其中深色像素为噪声,浅色像素为正常表面。

对于缺陷的筛查,传统方法需经过4个步骤:①对图像进行滤波处理;②扫描所有像素,寻找出灰度符合缺陷特点的疑似缺陷像素;③通过对所有疑似缺陷像素进行8联通域分析,查找出符合8联通特征的疑似缺陷像素团;④对所有疑似缺陷像素团进行尺度判断,去除尺度小于最小缺陷尺度的疑似缺陷像素团后,留下的缺陷像素团则为筛查出的缺陷。该方法计算繁琐、耗时大,且不易实现并行计算。
本文根据第2章对活塞杆表面噪声像素团的尺度和形态特征的分析,提出一种基于5×5的二维间隔冲击阵列卷积核(Two Dimensional Interval impulse Array convolution kernel,TDIIA)的卷积滤波算法,在滤除噪声的同时,可以获得缺陷像素团。
TDIIA卷积核的定义如下:

(1)
式中:i=0,1,…,4;j=0,1,…,4。
基于TDIIA的卷积滤波计算方法如下:
(2)
式中:F(i,j)为TDIIA卷积核;A(y,x)为线扫描灰度图像;B(h,w)为滤波后的灰度图像。
线扫描相机获得图像的尺寸为4 096×16 384像素。为使卷积核在图像边缘卷积计算方便,调整线扫描相机有效视场为(4 096-4)×(16 384-4)。因此,式(2)中:
H=4 096,W=16 384;
h=0,1,…,H-5;
w=0,1,…,W-5;
x=w+j=0,1,…,W-1;
y=h+i=0,1,…,H-1。
A(y,x)矩阵由有效视场(4 096-4)×(16 384-4)扩展得到,相对有效视场矩阵,在四周各方向均向外扩展2个灰度为图像背景的平均灰度的像素,即做到图像四周各边缘区为正常背景图像,其中无噪声。
设灰度阈值gT=80,灰度小于gT的像素判定为缺陷或噪声,大于gT的像素判定为正常表面。
经TDIIA卷积核与原始图像卷积运算后,通过二维间隔冲击阵列的卷积发挥作用,得到具有如下特点的结果,即噪声像素团(如图4给出的典型噪声像素团)与背景的灰度均会大于gT,而真实缺陷的灰度一定会小于gT,从而可靠滤除噪声像素团,并识别出存在的缺陷。
3.2 缺陷筛查算法
经TDIIA卷积运算,若图像中无真实缺陷,则所有像素灰度均应大于阈值gT。因此,对于原始图像中是否存在真实缺陷,依据以下判据予以判断:
(3)
若矩阵C(h,w)中存在非零结果,则判定表面存在缺陷。采用基于CUDA的并行规约计算方法对C(h,w)所有像素求和以判断图像中是否存在缺陷,计算效率可以得到显著提高。
3.3 基于CUDA的并行滤波及缺陷筛查算法
为解决在线实时检测系统受制于6 700万像素活塞杆表面原始图像处理耗时大的技术瓶颈,本文提出一种基于CUDA的TDIIA卷积滤波及缺陷筛查算法,有效缩短了计算耗时。
CUDA的并行运算通过NVIDIA显卡中的GPU实现,软件采用CUDA的C语言编程并封装为kernel函数[22-23]。CPU通过设置kernel函数启动多个thread(线程)并行计算,而kernel函数则在GPU上运行。
完整的CUDA应用程序包括主机端(CPU)串行执行程序和设备端(GPU)并行运算程序。分别由_global_和_device_的kernel函数决定函数由主机调用或由设备调用,如图5所示。

该项目中完整的串行图像处理程序结构如图6所示,对应的CUDA并行处理程序结构如图7所示。


由图6和图7可知,同一个应用程序采用串行处理和并行处理的相同点和不同点。进行并行计算的前提必须是数据已经在GPU的全局内存中,并且已经按照一维顺序排列放置好了,在数据导入GPU全局内存之前的软件处理过程分别是“读图并赋值”、“动态地址分配”、“产生二维数组”、“二维数组转一维数组”、“CPU地址分配”、“GPU地址分配”“将一维数组拷贝到GPU全局内存”。
如果将图像直接读入GPU,图像本身数据结构中的数据是不能参与计算的,而且也没有这样的读入命令或函数来实现将图像直径读入CPU。在“读图并赋值”之后,要将数据转换成标准的数组形式,即“产生二维数组”,在实际中并行计算的数据存放都是一维排列存放,因此要将数据都转换成此种标准形式存放。GPU并行计算的本质是由无数个独立计算单元进行简单计算,这些互相独立的计算单元之间没有数据交换,每个计算单元的计算结果直接存放于内存中。前面所有处理过程是为并行计算做准备,均不符合并行计算要求,最后的“内存释放”也不具备并行计算条件。因此,并行计算部分只有滤波和筛查两个部分可以考虑。
由前所述,基于CUDA实现图像数据的并行计算,在滤波之前的一些必要的辅助工作不得不通过串行方式完成。但是这些辅助工作涉及CPU与GPU之间的大量数据传输,耗时不能忽略,因此GPU并行计算减少的运算耗时往往会被辅助工作的耗时所淹没。是否应采用并行计算,需要判定并行计算用时的减少能否明显抵消辅助工作用时的增加。
基于3.1和3.2的算法思路,可以转化为并行化运算,并可以通过以下两个方法,进一步提升计算效率。
(1)改进的TDIIA卷积滤噪算法
如图8所示,TDIIA卷积滤噪算法采用实线框范围内的5×5卷积核,以C为中心,进行卷积运算,结果即为C坐标下的滤波结果(若不作除9运算,则灰度被放大9倍)。TDIIA卷积核与原始图像的卷积运算即实现整个图像的滤波。卷积运算的大量时间消耗在数据读取方面,卷积核滑动到每一个位置时,需要对9个数据进行读数,并进行8次加法计算,注意到这些数据实际在后续卷积核滑动后的运算中还会用到,包括部分加法中间结果也需使用多次,从而严重影响卷积计算效率。
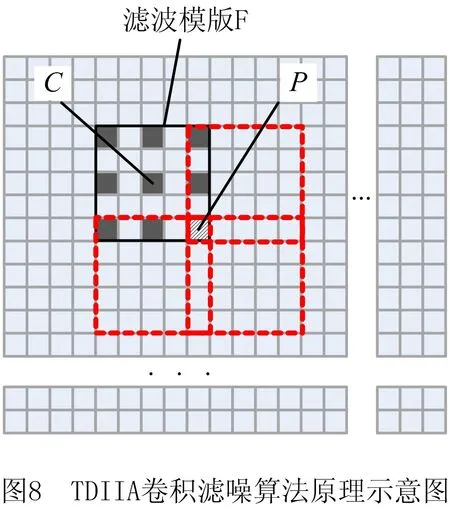
因此,更为有效地减少计算耗时的方法是减少原算法中的数据读取次数和加法运算次数。为此,本文提出一种基于卷积核分离计算的改进的TDIIA卷积滤噪算法,其基本原理如图9所示。

首先,对于图8所示卷积核,采用纵向滤波模板F1遍历整个原始图像进行3点数据(灰色)累加计算,得到中间结果矩阵,然后对中间结果矩阵采用横向滤波模板F2进行3点数据(灰色)累加计算,得到最终结果矩阵。对于P1位置的数据,在F2移动过程中,分别在位置0、位置1和位置2会被读取,共计3次;对于P2位置的数据,在F2移动过程中,分别在位置0、位置1和位置2共计被读取3次。因此,综合F1和F2滤波计算,一个数据仅会被读取3次,而其中加法计算仅需4次。算法的实现步骤为:
(4)
式中:i∈-2,0,2;h=2,3,…,H-3;w=0,1,…,W-1。
(5)
式中:j∈-2,0,2;h=2,3,…,H-3;w=2,3,…,W-3。
这里,A是由有效视场(4 096-4)×(16 384-4)的扩展得到的4 096×16 384图像,因此H=4 096,W=16 384。B1为中间结果矩阵,B2为最终结果矩阵(做除9运算即为滤波后的图像)。
与原始TDIIA卷积滤噪算法对比,最终结果矩阵(约6 700万个元素)中每一元素计算时的访问数据次数由9次减少到6次,加法运算的次数由8次减少到4次,分别降低至原方法的67%和50%,有效减少了总体滤波计算的时间。
(2)共享内存与全局内存混合规约求和算法
缺陷的筛查算法是通过对式(3)中C(h,w)求累加和实现,若累加和结果大于零,则表示图像中存在像素团大于规定面积的缺陷点,需要求和的元素个数为N=4 096×16 384=67 108 864。采用常规串行计算,则需时间为67 108 864×Δt,这里Δt为单次求和计算所需时间。
规约算法可以利用并行机制,可以实现对大数据的快速累加求和,对于N个数据的规约求和并行计算时间仅为:
t=log2(N)Δt。
(6)
式中Δt为单次求和计算所需时间。对式(3)中C(h,w)的所有元素求和,若完全采用规约求和并行计算,则求和时间仅为26Δt,较采用串行计算方法相比,计算时间几乎可以忽略不计。
考虑GPU运算时共享内存较全局内存具有更高的计算速度。同时减少线程(threads)空闲等待时间,本文进一步发挥共享内存快速数据读取优势,采用一种共享内存与全局内存混合规约求和方法。首先在一个线程中将每隔threadsPerBlock×blockPerGrid(即1 024×128个元素)的值累加求和,以减少线程空闲等待,每个线程累加次数为512次,将其结果存放进共享内存,每个线程产生一个元素,合计1 024×128个元素存入共享内存,然后对每个块(block)对应的1 024个线程采用规约求和算法得到一个结果存放在第一个共享内存缓存的第一个元素位置,共计会生成128个数据,最后将这个128个数据回传到CPU求出累加和。
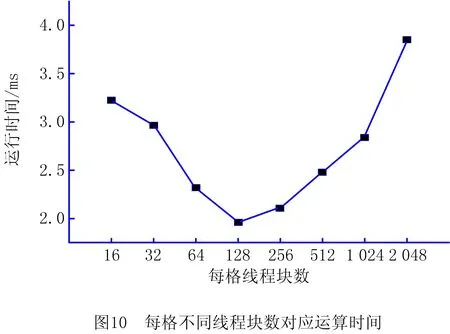
算法中每个块中线程数量threadsPerBlock为1 024,由GPU硬件确定,而blockPerGrid根据实验得到优化结果,如图10所示。实验结果表明,本文运算每格(grid)采用128个块(block)时,运算速度最快。
3.4 基于CUDA的并行滤波及缺陷筛查算法的编程实现
改进的TDIIA卷积滤噪算法和共享内存与全局内存混合规约求和算法采用C++、Opencv与CUDA C混合编程。为便于GPU核函数数据处理,滤波运算均将二维数据转变为一维数据进行计算,数据读取与加法计算量与二维计算相同。
参与并行计算的一维数组如何和图像的像素位置一一对应是编程实现的关键因素之一。Nvidia图像处理卡通过固定的位置索引函数在核函数中实现,如图11所示为其中的一种索引方法。

图11是一个32×256的图像,即一个二维的数组(32,256),线程表示列y,线程块表示行x,Dim表示线程块的大小,即线程的数量256,即一行有几个像素。(x,y)值就是某个像素的具体位置,这样就可以计算得到一个唯一的索引:将线程块索引与每个线程块中的线程数量相乘,然后加上线程在线程块中的索引,即pix=x+y×Dim,pix为某个像素在全局内存中的偏移量。Nvidia图像处理卡中的索引命令之一为:tid=threadIdx.x+blockIdx.x×blockDim.x,一旦知道某个索引tid,就相当于知道了这个tid值对应的线程索引和线程块的索引,即知道了(x,y)值。这是在全局内存中的索引方式,当数据被读入共享内存中时,也有固定的索引命令:cacheIndex=threadIdx.x,cacheIdex为共享内存中的位置偏移量。
项目中并行计算部分分为两部分:①滤波的卷积计算,这部分是基于全局内存的计算,因此采用的是全局内存位置索引;②像素筛选部分,这部分是将数据拷贝到共享内存中去计算,采用的是共享内存的位置索引。
该项目中,并行计算通过纵向滤波模板核函数、横向滤波模板核函数和缺陷像素统计核函数完成。其中纵向滤波模板核函数和横向滤波模板核函数的并行计算线程与图像像素对应,按以下方式进行索引:
unsignedintx=threadIdx.x+blockIdx.x×blockDim.x;
unsignedinty=threadIdx.y+blockIdx.y×blockDim.y;
unsignedintpix=y×W+x;
其中:x为图像宽度方向像素索引;y为图像高度方向像素索引;pix为二维图像转变为一维向量后的像素索引;W=16 384为图像宽度。
考虑滤波模板运算时图像边缘与运算模板中心重叠时的情况,以图像平均灰度替代图像边沿无法实现卷积运算的像素的灰度。以条件语句控制模板避开这些像素运算。
纵向滤波模板并行计算线程须满足如下条件:
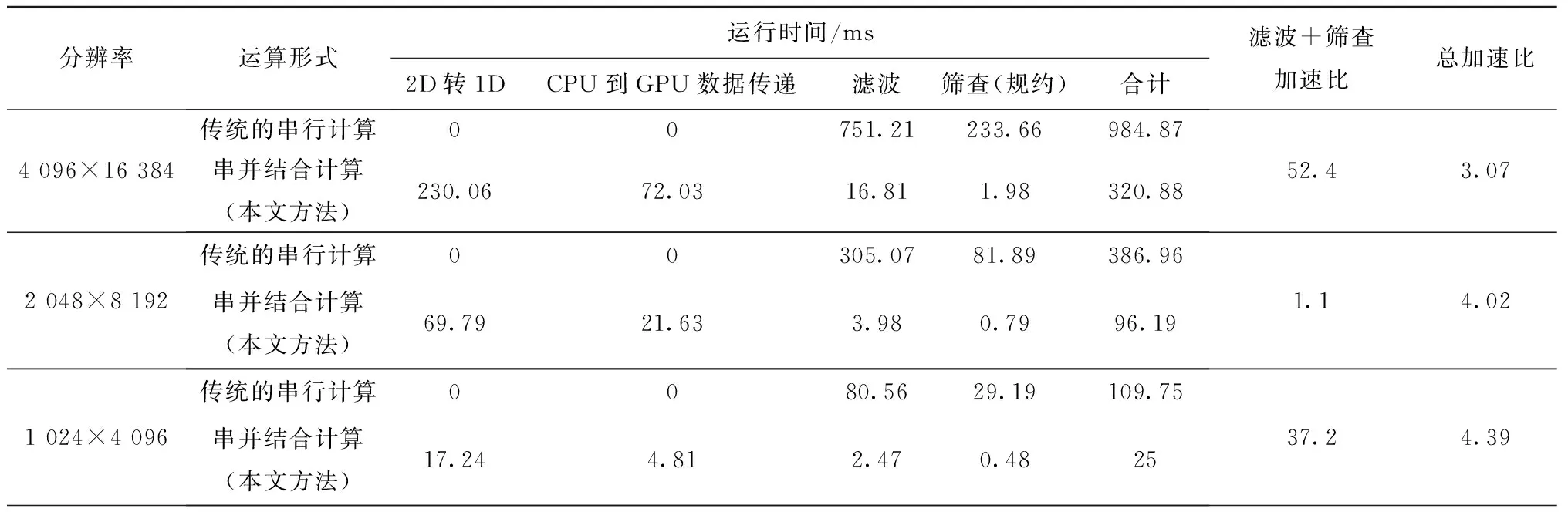
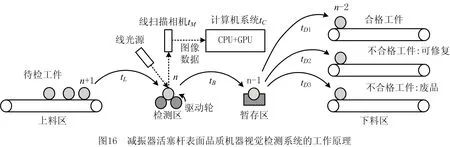
(pix>W2-1&&pix 横向滤波模板并行计算线程须满足如下条件: (pix>W2+1&&pix 其中:W2=16384×2为图像上边缘及下边缘所占像素数,N=4 096×16 384为图像对应的一维数组的长度。 缺陷像素统计核函数为各线程块声明共享内存变量数组,每一个线程块各有一个cache副本,针对4 092×16 380个像素,共设置具有1 024个线程的线程块128个,以及对应的128个共享内存副本。其中,线程索引为inttid=threadIdx.x+blockIdx.x×blockDim.x;共享内存索引为intcacheIndex=threadIdx.x。通过对所有线程块cache副本内元素规约运算求和以提高并行计算速度。 程序运算速度与硬件配置有关,本文系统配置的CPU为Intel(R)CPU E5-2620 v3 @2.40 GHz(2 core)内存32 GB,GPU为Nvidia的GTK1080Ti。操作系统是Windows Servers 2012 R2 64位操作系统。 本文采用的活塞杆表面线扫描成像方法的原理如第2章所述,图12a给出了活塞杆、线扫描相机、光源的空间布局形式,图12b给出了实际的活塞杆表面图像采集单元。 (1)改进的TDIIA卷积滤噪算法效果 实验表明,本文算法结果可靠,对于纵横向尺度均大于0.1 mm的缺陷(灰度一般低于70)可以准确识别,而对于噪声像素团(8连通域少于16个像素,或呈现线宽为2个像素以下较长的线型)则能可靠滤除。滤波算法后通过规约并行计算可快速判断图像中是否存在缺陷对应像素。 图13给出了改进的TDIIA卷积滤噪算法效果,其中图13a为原始图像的局部放大图,图13b为滤波后的结果。对于8联通域16像素点及以下的斑块,滤波后100%灰度大于规定的灰度(与低灰度噪声点的灰度有明显区别),而16像素点以上的斑块,滤波计算后,100%至少保留1个像素的灰度低于所设置的灰度阈值,因此被认为该斑块尺度大于噪声,可以判定为缺陷。同理,对于线宽为2像素以下的线条,也会被认为是噪声被滤除。 本文采用CUDA核函数进行并行计算,设定每个block为16×64=1 024个线程,共有256×256个block,即共计有67 108 864个线程参与并行运算,使得并行运算耗时较串行大为缩减。虽然,存在辅助数据传递工作用时开销,但CUDA并行计算仍得到了较好的总体速度提升。 (2)粒度与计算效率实验对比 通过实验,考察了粒度选择对于并行计算效率的影响。如图14所示,优化选择格(grid)、块(block)和线程(thread)的数量,可以得到较快的并行计算速度。在每格128个块时,每块256个线程时计算速度最快。GPU硬件决定每块最多可设置1 024个线程,但实验结果表明,每块线程数为512或1 024的情况,计算速度均低于每块线程数256的速度。 (3)加速比分析 加速比计算公式如式(7): (7) 式中:S为加速比;TS为串行计算运行时间;TP为并行计算运行时间。 将图7本文方法(在本文给出的硬件配置条件下)与图6的传统CPU串行运算进行对比,软件构成的前面3个阶段“读图并赋值”、“地址分配”和“产生二维数组”以及最后的“内存释放”串并行是一样的,不参与耗时对比,而不同部分“GPU拷贝数据到CPU”阶段的时间可以忽略不计,因为该项目中只有几个数据被拷贝,时间几乎为零。同样,“CPU地址分配”和“GPU地址分配”是一次分配多次使用,即在GPU上开辟存储空间的操作仅在初始化时进行一次,耗时约1 s,在后续反复的运算时不再需要,因此不计算在时间消耗比较中。这样就得到了如表1所示的加速比。 从表1看出,针对6 700万像素的减振器活塞杆表面图像的滤噪和缺陷筛查,本文方法在耗时方面具有明显优势,本文方法总体运算耗时节省了67.4%,总加速比为3.07。若仅考虑滤波和筛查运算环节,则并行计算较传统的串行计算方法速度提升了52.4倍。 传统的CPU串行运算,不需要2D转1D、CPU到GPU数据传递等辅助环节,但由于CPU串行运算部分相比GPU多线程运算部分要慢很多,并行运算仍体现出运算优势。如果是计算密集型的计算,串行运算时耗时越多,则并行运算节省时间越明显,加速比就越大。 本文还针对8 192×2 048、4 096×1 024、2 048×512的图像,做了串、并计算对比试验,运行对比情况如表1所示。在不同分辨率的图像下,总体运行加速比稳定,均在3~5倍左右。但是,从滤波和筛查计算来看,16 384×4 096图像的滤波加速比是44.7倍,筛查是118倍,滤波与筛查综合加速比为52.4倍。相对而言,较低分辨率图像的处理,滤波加速基本恒定在数十倍,而筛查则是处理像素越多,加速比越高。 表1 传统串行计算和串并结合的程序运行时间对比 续表1 (4)并行平台压力测试实验 单幅图像的处理并不能说明并行平台具有GPU计算的稳定性,需要对大量数据的处理性能对比,这里采用分辨率16 384×4 096为测试图像,大量测试并行计算的时间、滤波时间和筛选时间的变化情况,如图15所示。 由图15可知,数据量较大时,GPU并行计算平台仍然具有稳定的性能。 (5)筛选正确率的实验 通过1 000幅实际拍摄的含有如图2所示4种缺陷的图像进行了缺陷筛查实验,在图像含有高斯、均匀、椒盐噪声干扰情况下,采用本文提出的方法均可以正确判断出图像中是否含有缺陷,缺陷筛查正确率为100%,达到规定尺寸的缺陷没有漏检情况发生。 基于CUDA并行运算的滤波及缺陷筛查算法由改进的TDIIA卷积滤噪算法和共享内存与全局内存混合规约求和算法组合构成。本文将该算法应用于减振器活塞杆表面品质机器视觉检测系统,系统工作原理如图16所示。待检活塞杆通过夹持机构由上料区开始以步进方法逐步移动至下料区,在检测区匀速旋转,由线扫描相机摄取圆周完整表面图像,待计算机系统对摄取图像分析分类后,根据活塞杆表面的品质,按合格、不合格可修复和废品3类情况分别移动至不同的下料区。 图16中:n为工件编号,tL为上料时间;tB为工件移至缓存区时间;tC为图像处理的计算时间;tM为图像采集时间;tD为工件移至下料区时间,tD1、tD2和tD3分别表示移至对应合格、不合格可修复和废品的下料区所需时间(由于移动距离的差异,所需时间也有差异)。其中tL、tB、tD(tD1、tD2或tD3取其一)时间统一为0.5 s,同步进行,同时完成。tM为图像采集时间,线扫描相机完成整幅图像采集耗时约0.085 s,为保证成像质量,待检活塞杆旋转稳定时开始采样,总体时间0.5 s。由工件移动和相机采样构成一个完整节拍,耗时1 s,周而复始。由于机械运动与相机采样均不占用CPU和GPU时间,滤波及缺陷筛查运算也同步在上述节拍中完成,耗时为tC,若tC>1 s,则需要放慢机械动作,以满足运算耗时需求。本文方法有效减少了运算耗时,确保在小于1 s时间内完成缺陷筛查运算,对于提高机器视觉检测系统工作效率具有重要意义。 本文方法提高了基于机器视觉的产品品质在线检测的工作效率,可广泛应用于计算机集成制造系统中,在多供应商跨企业协同生产系统[24]、云制造加工服务物联网体系[25]中也可以发挥重要的作用。 本文提出一种减振器活塞杆表面品质检测系统实现方案,采用线扫描相机有效避免高光反射,清晰获取了活塞杆表面4 096×16 384的2D灰度图像,满足了活塞杆表面缺陷筛查自动化的需求。提出一种改进的TDIIA卷积滤噪算法,用于对图像噪声像素团与活塞杆表面缺陷识别,与混合规约求和算法组合,实现了CPU与GPU的串并混合编程方法,提升了缺陷筛查运算速度,较串行算法总体运算耗时节省了67.4%,可以确保检测系统以高效率工作。 本文提出的算法可准确滤除噪声像素团,并对属于活塞杆表面缺陷的像素进行计数。实验检测系统的实验结果表明,所提算法对缺陷筛查效果良好,缺陷判断正确率达到了100%,达到规定尺寸的缺陷没有漏检情况发生。 本文主要研究高反光金属轴表面缺陷的快速检测,在高光表面的轴加工过程中,轴表面会滞留一些油渍,或者经过油渍清洗工艺后滞留有水渍,这些油渍和水渍会影响高光表面微细缺陷的检测准确率,下一步将研究如何快速的识别油渍和水渍的干扰,以及缺陷的分类。4 实验及结果分析
4.1 计算机配置
4.2 图像采集单元

4.3 实验结果分析




5 串并混合算法与生产工艺流程结合减少筛选时间
6 结束语
猜你喜欢
沈阳理工大学学报(2022年3期)2022-08-11北京航空航天大学学报(2022年6期)2022-07-02网络安全技术与应用(2020年1期)2020-01-07自动化学报(2017年5期)2017-05-14环球市场(2017年36期)2017-03-09流体机械(2017年9期)2017-02-06光学精密工程(2016年1期)2016-11-07中国新技术新产品(2014年21期)2014-03-28中国设备工程(2014年2期)2014-02-28电视技术(2012年21期)2012-06-07
