
一种基于深度学习的高速无人艇视觉检测 实时算法
2021-08-11 05:14周治国刘开元郑翼鹏屈崇王黎明
北京理工大学学报 2021年7期
周治国,刘开元,郑翼鹏,屈崇,2,王黎明
(1. 北京理工大学 信息与电子学院,北京 100081;2. 中国船舶重工集团公司第七一一研究所, 上海 201108;3. 中国人民解放军海军工程大学,湖北,武汉 430032)
提 要:针对高速无人艇自主航行时对视觉检测的实时性以及由于水面场景变化和波浪反射等干扰的鲁棒性需求,提出一种基于深度学习的高速无人艇视觉检测实时算法. 采用基于MobileNet的神经网络快速提取全图特征,设计SSD结构的检测网络融合各层特征图的结果以完成快速多尺度检测,并在嵌入式GPU NVIDIA Jetson TX2硬件平台上将算法实现并验证. 结果表明,该算法能够实时检测多类水上特定目标,具有鲁棒性强、多尺度的特点,单帧视频的检测时间可以控制在50 ms以内.
水面无人艇是一种具备自主路径规划和自主导航能力的水上平台,在军事和民用领域有着广泛的应用前景. 实际应用中,无人艇在高动态环境中自主航行并完成任务,要求具备感知环境、发现潜在威胁以及执行合理路径的能力[1],一般需配备超声探头、视觉传感器、毫米波雷达、X波段雷达、激光测距仪等传感器获取环境和障碍物信息,其各自的感知范围如表1所示.

表1 常见传感器及其感知范围Tab.1 Common sensors and sensing range
由表1中所列数据可知超声探头与毫米波雷达覆盖范围较小,激光测距仪检测覆盖范围广,但条件较苛刻,X波段雷达近距离检测效果不好,而视觉传感器的感知范围较为合适. 另外雷达等传感器获取的信息量较少,能够进行障碍物探测但无法分类,而障碍物分类对于危险情况分级、局势判断有着重要作用. 视觉传感器具有高分辨率、低成本、易安装以及视野广的优势,采集的图像在稳像和去雾处理后图像质量较高,所以目前采用视觉算法进行无人艇障碍物检测最为普遍.
水面无人艇摄像头采集的图像中场景复杂,往往有多个障碍物,也经常遇到高光照、海面反射、浪花干扰等情况,因此实现障碍物检测非常困难. Fefilatyev等[2]首先检测海天线,然后在海天线下的区域内搜索潜在的障碍物目标,通过连续帧的检测结果确定障碍物. Wang等[3]和Mou等[4]也采用了类似的思路,先检测海天线,然后通过显著性或全局稀疏等方法检测潜在障碍物. Matej Kristan等[5]假设海洋环境图片可以被分为天空、陆地和海雾或停泊在海天线附近的船、水体3个平行且截然不同的语义区域,通过施加弱结构约束,采用马尔科夫随机场框架,推导出模型参数、分段掩模估计和优化算法. 随着机器学习算法的广泛应用,有研究者将机器学习的方法引入到水面无人艇障碍物目标检测领域. Li等[6]通过objectness方法获取潜在目标,并通过与显著性方法融合获取最终的结果,达到较好的检测精度.
目前国际上大部分的水面无人艇的设计速度均超过40节[7],且多用于战场侦察、岛礁巡逻等复杂水域环境中,因此对障碍物检测识别有较高的要求:①鲁棒性强,在海天背景、近岸情况、光照变化、多目标场景等情况下均能有较好的检测效果;②多尺度检测,无人艇工作环境复杂,可能遇到多种大小不同的船舶目标;③实时性强,无人艇航速较高的情况下要求算法能够快速检测;④识别分类,算法能够识别不同的目标并分类,为后续的危险分级和态势判断提供信息. 现有算法或是鲁棒性不足,或是实时性较差,或是应用条件苛刻,均无法很好地适用于高速无人艇的应用场景. 而近年来飞速发展的深度学习算法具有鲁棒性强、多尺度检测识别的优点,但也有一些限制:①网络本身结构的计算成本较高;②缺乏高性能的嵌入式GPU板卡支持.
本文针对高速水面无人艇障碍物检测识别这一问题,结合实际情况分析并建立算法模型,提出基于深度学习算法的高速水面无人艇视觉检测方法. 采用轻量级的MobileNet[8]作为基础网络提取图像特征,并添加多卷积层输出不同尺度的特征图,结合SSD思想设计快速多尺度检测网络实现多尺度检测. 并创建了一个新的水上目标数据集,用训练集对该网络在NVIDIA GeForce 1080TI上完成了整个检测系统的训练,在NVIDIA Jetson TX2上用测试集进行了验证,结果表明本文的方法可以在对多场景下不同大小的船舶以及摩托艇等障碍物目标保持82.1%平均检测精度的同时,单帧视频的检测时间小于50 ms.
1 视觉检测算法
1.1 算法架构
整体算法模型可分为两部分,第一部分基于MobileNet设计特征提取网络以生成多个不同尺度的特征图,第二部分基于SSD思想搭建了快速多尺度检测网络,融合各层特征图并最终输出结果. 整体的算法模型如图1所示.
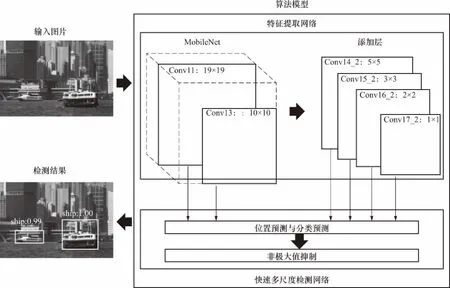
图1 基于深度学习的视觉检测实时算法模型Fig.1 Real-time visual detection algorithm model based on deep learning
1.2 特征提取网络
特征提取网络基于轻量级网络MobileNet设计,参考分离卷积[9]的概念设计深度可分离卷积层,将标准卷积层分解成一个深度卷积和一个点卷积,深度卷积将每个卷积核应用到每一个通道,而点卷积用来组合通道卷积的输出,大大减少了网络模型的参数量和计算成本. 深度可分离卷积层相比标准卷积层的计算开销比例为[8]
(1)
式中:DF为输入特征图的宽度和高度;M为输入通道的数量;DK为标准卷积层和深度卷积的卷积核尺寸;N为卷积核的数量.
深度可分离卷积层的引入也大大减少了网络模型的参数量,如表2所示.
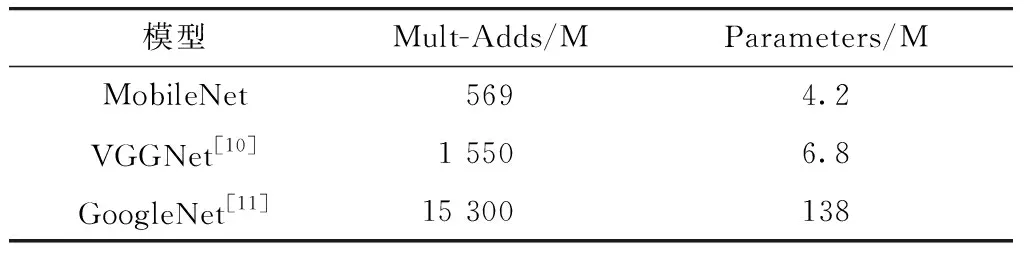
表2 网络参数量比较Tab.2 Comparison of network parameter quantities
特征提取网络去掉MobileNet最后的平均池化层、全连接层和Softmax层,并在网络后面添加8个卷积层以提高特征提取能力,特征提取网络的各层数据如表3所示.

表3 添加层结构Tab.3 Structure of add layers
1.3 快速多尺度检测网络
本文基于SSD算法设计了快速多尺度检测网络,抽取不同尺寸的特征图作为输入以实现多尺度,这6个特征图的大小分别为19×19、10×10、5×5、3×3、2×2、1×1. 算法对输入特征图的每个特征区域生成一系列不同大小、不同比例的默认框,其大小和比例与对应的特征层有关,假设模型检测时采用m层特征图,则第k个特征图的默认框比例计算公式如下:
(2)
式中k∈[1,m],其中Smax和Smin代表默认框在对应特征图中所占的最小和最大比例,分别设置为0.2和0.9.

(3)
(4)
特别的,当r=1时,规定默认框参数为
(5)
特征图与对应边框大小的不同使得其在图片的感受也会相应的不同,形成多尺度的检测.
检测网络训练时同时对目标分类和位置进行回归,整体对象损失函数是置信损失和位置损失之和,其表达式如下:
(6)
式中:Lconf为置信损失;Lloc为位置损失,这里采用的是Smooth L1Loss[12];N为与预先标注框匹配的默认框个数;α为平衡置信损失和位置损失的权重,通常设置为1;z为默认框与不同类别的预先标注框的匹配结果;c为预测物体框的置信度;l为预测物体框的位置信息;g为预先标注框的位置信息.
在算法的训练阶段,将这些默认框和预先标注框匹配,结果输入损失函数以训练匹配策略. 在预测阶段,则直接预测默认框的偏移以及对每个类别相应的得分,最后通过非极大值抑制去除冗余项得到最终的结果.
2 算法实时实现及验证
2.1 数据集构建
无人艇在工作过程中可能遇到多种多样的障碍物,包括大小船舶、浮木、浮球、礁石等等,其中会遇情形较为复杂,容易造成碰撞风险的主要为运动中的大小船舶. 并且当无人艇在进行战场侦察、岛礁巡逻、多船协同对抗等任务时,对船型的检测有着较高的需求. 船舶包括货船、大型集装箱船、各型军舰、冲锋舟、快艇、摩托艇等,本文根据军用检测场景中的碰撞危险度大小将潜在检测目标分为3类,如表4所示.
目前深度学习领域有很多著名的数据集,如COCO[13],ImageNet[14],Pascal VOC[15]等,但这些数据集中水面船舶的数据较少,且目标类型较少,场景单一,无法用于训练. 本文针对水面检测的实际场景,自行构建了水上目标数据集,以表4中列出的3类潜在目标为训练和测试数据,并包含了多尺度目标场景、浪花干扰场景、海天背景、建筑物背景,以及高光照和图片变色场景等多种实际检测场景. 该数据集由1 550张尺寸为300 ×300左右的图片构成,其中1 350张作为训练集,200张作为测试集.

表4 潜在检测目标分类Tab.4 Classification of potential objects
2.2 网络训练
在完成MobileNet的实现后,去掉最后的池化层和全连接层,添加了8层卷积神经网络,并从整个检测网络中分别提取了大小分别为19×19、10×10、5×5、3×3、2×2、1×1的6层输出特征图进行检测.
考虑到搜集的数据集较小,为了提高算法的检测精度,先在COCO数据集上对MobileNet网络进行了预训练,再用Pascal VOC数据集预训练整个系统,最后使用本文自己收集的水上目标数据集进行训练. 由于经过了两次预训练,所以整个网络的基本权重已经相对合适,只需进行微小的调整,而且MobileNet网络本身是一个轻量级的网络,不容易产生过拟合. 因此,为了保护基本权重,采用RMSProp算法优化参数,并将权重递减比例设置为0.000 05. 出于同样的原因,初始学习率设置为0.000 1,并在200 00步和400 00步分别调整为0.000 05和0.000 025.
本文提出的无人艇障碍物检测识别算法在深度学习框架Caffe上实现,并在配置有NVIDIA GeForce GTX 1080TI的工作站上进行了训练.
2.3 验证结果
本文在与训练数据集同分布的测试数据集上对算法进行了测试,算法对各类水上障碍物目标的检测精度如表5所示.

表5 检测精度Tab.5 Detection accuracy
由表5数据可见,将各类型的障碍物目标分为大型船、小型船、摩托艇3类,且对3类目标的检测精度均超过了80%. 测试集中各类场景图片的检测识别结果如图2~4所示.

图2 多尺度障碍物检测结果Fig.2 Results of multi-scale obstacle detection

图3 复杂场景检测结果Fig.3 Results of complex scene detection

图4 高光照场景检测结果Fig.4 Results of high light scene detection
目前算法由于其原理的限制,对于高光照噪声场景往往没有较好的解决办法,如文献[5]中通过忽略表示为闪光区域的区域中的任何检测来解决高光照噪声的干扰. 这种解决办法在某些场景下可以起到一定的效果,但是这种解决思路明显无法应对障碍物出现于闪光区域内的情况,会出现漏检的情况. 而由图2~4可见,本文算法能够较好的实现多尺度目标检测,并能在浪花干扰、多种背景的复杂场景下以及高光照场景下仍然保持较好的检测性能,优于现有算法.
2.4 算法实时性测试
由于深度学习算法的运行过程中具有大量的并行计算,计算成本较高,常见的CPU板卡并行计算效率较低,而一般采用的高性能GPU计算性能好,功耗却很大,不适合作为本文的无人艇障碍物检测算法的测试硬件. 本文选取了NVIDIA Jetson TX2作为本文的视觉算法硬件,其配置及运算性能如表6所示.

表6 硬件参数Tab.6 Hardware parameter
算法模型基于Caffe框架实现,并采用CUDA加速,测得单帧视频的平均检测速度在50 ms以内,与同类型方案比较如表7所示.

表7 本文算法与文献[6]统计结果
由表7数据可见,本文方案的硬件功耗仅为文献[6]的11.5%,单帧检测时间仅为文献[6]的18.6%,检测精度保持得很高,综合性能优于文献[6].
3 结 论
本文针对高速无人艇在战场侦察、岛礁巡逻等复杂水域环境下障碍物检测的相关指标进行分析,引入深度学习方法,并结合领域特点提出基于深度学习的无人艇障碍物检测算法. 实验结果显示,本算法对大型船、小型船和摩托艇3类目标的平均检测精度达到了82.1%,而且可以实现多尺度、复杂场景及高光照场景的检测,并能在嵌入式GPU NVIDIA Jetson TX2上实时运行,单帧视频的检测时间小于50 ms,优于现有的同类型方案.
致谢
本研究受到中船重工预研项目《水面无人艇关键技术研究》和海军工程大学军内项目《军港水域无人化勤务保障技术研究及验证》支持,特此感谢!
猜你喜欢
农业工程学报(2022年12期)2022-09-09
社会科学战线(2022年7期)2022-08-26
计算技术与自动化(2022年1期)2022-04-15
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
动漫界·幼教365(中班)(2020年3期)2020-04-20
创新作文(1-2年级)(2019年4期)2019-10-15
好孩子画报(2019年10期)2019-01-10
中国信息化周报(2015年1期)2015-04-09
时代英语·高三(2014年5期)2014-08-26
