
基于知识表示学习的协同矩阵分解方法
2021-08-11 05:14刘琼昕覃明帅
北京理工大学学报 2021年7期
刘琼昕, 覃明帅
(1.北京市海量语言信息处理与云计算应用工程技术研究中心,北京 100081; 2.北京理工大学 计算机学院,北京 100081; 3.中国科学技术信息研究所 富媒体数字出版内容组织与知识服务重点实验室,北京 100038)
提 要:针对协同过滤算法中用户反馈数据的稀疏性问题,提出一种基于知识库的协同矩阵分解方法.该方法从物品的知识图谱中学习其向量表示,并在此基础上联合地分解反馈矩阵和物品关联度矩阵,两种矩阵共享物品向量,利用物品的语义信息弥补反馈数据的缺失.实验结果表明,该方法显著地提升了矩阵分解模型的推荐效果,在一定程度上解决了协同过滤的冷启动问题.
在推荐系统中,基于协同过滤[1](collaborative filtering)的算法是应用最广泛的一类方法.协同过滤算法简单且高效,只需要用户对物品的反馈信息即可推测用户可能感兴趣的物品.反馈信息包括显式反馈(如用户对物品的评分)和隐式反馈(如用户是否点击过物品).协同过滤算法存在冷启动问题,它仅考虑了用户对物品的反馈信息,如果反馈数据太稀疏,推荐的效果通常不理想.另外,新加入的物品没有任何反馈信息,协同过滤算法无法对其进行推荐.
为解决冷启动问题,研究人员在协同过滤的基础上结合用户或物品的附加信息提出了一些混合推荐算法.SINGH等[2]提出了一种协同矩阵分解(collective matrix factorization,CMF)框架,首先将用户、物品或者其他实体之间存在的关系转化为关系矩阵,然后联合分解反馈矩阵和多个关系矩阵.LIANG等[3]利用用户的消费记录生成一个物品共现矩阵,基于CMF的思想对共现矩阵和反馈矩阵进行联合分解,但是该方法本质上还是只用到了用户反馈信息,没有利用物品的客观信息.
目前知识图谱在推荐系统中的应用受到越来越多的关注.知识图谱本质上就是一些相互关联的语义数据所构成的知识库,它们将不同主题领域(如电影、书籍和音乐等)的信息连接起来,形成结构化的实体语义信息.要将这些信息与推荐系统结合,通常先要将实体进行向量化,近年来有许多知识表示学习方法被提出.BORDES等[4]将实体和关系映射到同一个低维向量空间,对于知识图谱中的每一个三元组(h,r,t),TransE希望其对应的向量满足vh+vr≈vt.TransE生成的向量能够体现实体与实体间的关系,但是在处理多对多的关系时效果不理想.LIN等[5]对此进行了改进,将实体和关系映射到两个不同的向量空间中.知识图谱中的实体之间通过关系相互连接构成了一个图,因此还可以用PEROZZI等[6]和GROVER等[7]等图表示学习算法生成实体向量.DeepWalk通过随机游走选取图中的节点,生成固定长度的节点序列,将此序列类比为自然语言中的文本,节点则对应文本中的词,然后应用skip-gram模型来生成节点的向量.DeepWalk等概率地从与当前节点相连的所有节点中选择下一个节点,node2vec在此基础上改进了随机游走的策略,使用两个参数来控制节点跳转的概率,使得游走策略介于广度优先搜索和深度优先搜索之间.
基于知识图谱的混合推荐模型通常用上述的表示学习方法将实体向量化,然后与协同过滤模型结合.ZHANG等[8]利用LIN等[5]学习物品的结构向量,用自编码器学习物品的文本向量和图像向量,同时用RENDLE等[9]分解隐式反馈矩阵,最终的物品向量由矩阵分解生成的向量与结构、文本和图像向量相加得到.PALUMBO等[10]在电影知识图谱的基础上,将用户当做实体节点加入到图中,将用户对电影的反馈当做边也加入到图中,利用GROVER等[7]生成用户和电影的向量,并基于生成的向量计算用户和电影之间的相关度,达到推荐的目的.
在矩阵分解模型中向量的内积体现了两个实体间的相关度,而基于TransE的一系列方法会使得头实体向量加上关系向量尽可能接近尾实体向量,向量的内积不能够直接反映实体的相关度,因此不太适合与矩阵分解模型结合.node2vec不存在上述问题,但是该方法没有考虑边的类型,而知识图谱有明确的关系类型,忽略关系的类型可能会丢失重要的语义信息.
围绕以上背景,本文提出了一种协同矩阵分解方法,基于skip-gram模型和一种随机游走策略从物品的知识图谱中生成一个物品关联度矩阵,联合地分解用户反馈矩阵和物品关联度矩阵,有效地将知识图谱与协同过滤结合起来.实验表明,该方法相较于普通的矩阵分解方法,在各种评价指标上都表现得更好,对于反馈较少的用户和物品,效果提升更加显著.
1 理论基础
1.1 隐式反馈矩阵分解

在实际应用中,显式的评分数据通常较难获取,更为常见的是诸如用户的点击记录和消费记录之类的隐式反馈数据.HU等[12]针对隐式反馈提出了一种加权矩阵分解(WMF)模型,本文的协同矩阵分解模型建立在此基础之上.
WMF训练的目标是最小化代价函数式:
(1)
其中超参数cu i用于衡量反馈的置信度,通常地,当yu i=0时,为cu i设定一个较小的值c0,当yu i≠0时,为cu i设定一个较大的值c1.超参数λ控制L2正则化项的权重.
1.2 Skip-gram模型
本文以LE等[13]的skip-gram模型为基础从物品的知识图谱中提取信息.Word2vec词向量模型将文本中的词转换成分布式的向量表示,训练得到的向量能很好地体现词与词之间的相关性.Skip-gram模型并不局限于自然语言处理,DeepWalk和node2vec等方法将其拓展到了图表示学习领域中.
Skip-gram的目标是预测给定词wt的上下文wt-2,wt-1,wt+1,wt+2,通常可使用负采样和随机梯度下降算法来训练得到每个词的向量,本文没有直接通过skip-gram生成向量,而是根据词的共现频率生成一个矩阵.LEVY等[14]证明了在负采样数量为k的条件下用skip-gram训练词向量等价于分解一个点互信息(pointwise mutual information,PMI)矩阵,矩阵的元素为PMI(i,j)-logk,PMI可按式(2)进行估算:
(2)
其中#(i,j)表示词i作为上下文时,词j出现的次数,即(i,j)对出现的次数,#(i)=∑j#(i,j),#(j)=∑i#(i,j),D表示所有(i,j)对的总数.
2 基于知识表示学习的协同矩阵分解方法的介绍
本文提出一种基于知识表示学习的协同矩阵分解方法(knowledge embedding collective matrix factorization,KE-CMF),包括物品知识表示学习和协同矩阵分解两个部分,首先从物品知识图谱中提取信息,然后用协同矩阵分解模型将这些信息与用户反馈信息结合起来.下面先详细介绍这两个部分,然后说明算法的总体流程.
2.1 物品知识表示
本文提出一种改进的方法对图中的节点进行采样.给定一个图G=(V,E),V为节点的集合,E为边的集合,对于每一个节点u∈V,以u为起始节点进行一次随机游走得到一个长度为l的节点序列.用ci表示节点序列中的第i个节点,其中c0=u,假设当前已经从节点t游走到节点v,下一个节点ci基于概率P来选择,概率P按式(3)和式(4)计算:
(3)
(4)
s表示随机游走的状态(包含0和1两种状态),其初始状态为0,状态转换如图1所示.当s=0时,所有与v相连的节点被选中的概率相同,当s=1时,节点x被选中的概率取决于πvx,πvx为未归一化的转移概率,Z为归一化常量,d(·)表示节点的度.πvx的计算如图2所示,从节点t游走到节点v后,下一次游走返回节点t的概率由节点t的度d(t)和超参数p共同决定.节点t所连接的节点越多,则返回节点t的概率越大,这样可以充分地挖掘其局部结构信息.

图1 s的状态转换图Fig.1 The state transition diagram of s

图2 未归一化的转移概率πFig.2 Unnormalized transition probability π
得到节点序列c0,c1,…,cl-1后,设定一个窗口大小值m,对于每个cx,cy(x+1≤y≤x+m)构成其上下文.每个(cx,cy)分别为#(cx,cy)和#(cy,cx)贡献一个计数,遍历并所有的(cx,cy),统计得到每两个节点i和j的共现频次#(i,j).
考虑到不同的关系对于计算实体间相关度的影响程度不同,本文依次处理每一种关系,每次仅保留该关系所对应的边,得到一个子图Gr,并在Gr上进行相同次数的随机游走采样,计算相应的#r(i,j).对所有的#r(i,j)加权求和得到了#(i,j)=∑rar#r(i,j),其中ar为关系r的权重.最后根据式(2)计算得到PMI(i,j).定义物品的关联度矩阵M∈RI×J,M的元素mij=max{PMI(i,j)-logk,0}.
2.2 协同矩阵分解
协同矩阵分解模型在分解反馈矩阵Y的同时,将关联度矩阵M分解为物品向量βi和上下文向量γj,Y和M共享同样的物品向量,其代价函数为
(5)
式(5)在式(1)的基础上加入了分解矩阵M的平方误差损失项,以及γj的L2正则化项.协同矩阵分解利用物品的关联度信息来影响物品向量βi的取值,相当于引入了一个特殊的正则化项.与WMF[12]类似,对式(5)采用交替最小二乘法进行迭代即可得到θu、βi和γj的值.式(5)分别对θu、βi和γj求偏导,并令偏导等于0可求得θu、βi和γj的更新公式,分别为
(6)
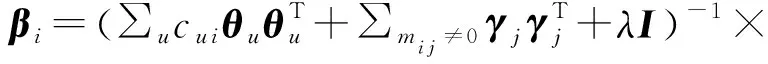
(7)
(8)
2.3 算法流程
本文方法(KE-CMF)的基本流程如算法1所示.
算法1 KE-CMF
输入:关系集合R,实体集合E,实体关系图集合{Gr|r∈R},随机游走长度l,窗口大小m,概率参数p,反馈矩阵Y
向量维度K,置信度c0和c1,正则化向权重λ,迭代次数N.
输出:用户向量θ,物品向量β,上下文向量γ
初始化:随机初始化θ,β和γ
1.forr∈Rdo
2.fore∈Edo
3.按照2.1节描述的随机游走策略以e为初始节点采样一条长度为l的序列s
4.在s上以m为窗口大小累计共现频次#r
5.endfor
6.endfor
7.根据式(2)计算PMI,得到关联度矩阵M
8.foriter=1 toNdo
9.根据式(6),式(7)和式(8)更新θ,β和γ
10.endfor
3 实验
3.1 数据集和评价指标
本文在两个不同领域的数据集上进行实验.第一个数据集为MovieLens-20 M,包含138 000个用户对27 000部电影的评分,评分记录总共有2千万条.第二个数据集为goodbooks-10 k,包含53 424个用户对10 000本书的评分,评分记录总共有6百万条.本文对数据集进行了多次筛选,首先去除未包含在知识库中的电影和书籍,然后去除评分在4以下的反馈项,将评分数据转换成隐式反馈数据,最后去除反馈数低于10的用户.按1:2:7的比例随机地将筛选后的数据集划分为验证集、测试集和训练集.
本文和文献[3]一样采用召回率Recall@K,归一化折损累积增益NDCG@K以及平均精度均值MAP@K评价算法的topK推荐效果.Recall表示用户感兴趣物品被推荐的概率,不考虑推荐的顺序.NDCG和MAP都对排序位置敏感,其值越大表明用户偏好的物品排序越靠前,它们的区别在于,MAP只考虑用户是否对推荐的物品有偏好,NDCG还考虑了用户对物品偏好的程度.
3.2 实验结果分析
实验对比的方法包括本文的KE-CMF,单一的隐式反馈矩阵分解方法WMF,联合分解反馈矩阵和物品共现矩阵的方法CoFactor以及KE-CMF+CoFactor,KE-CMF+CoFactor将KE-CMF和CoFactor中的关联度矩阵进行叠加生成一个新的关联度矩阵,然后按照同样的方法进行分解.
图3、图4和图5分别为以上几种方法在MovieLens-20M和goodbooks-10k上的Recall、NDCG以及MAP测试结果,从中可以看出CoFactor相较于WMF在各项指标上都有显著的提升,KE-CMF略优于CoFactor,KE-CMF与CoFactor结合后又有所提升.CoFactor利用用户的消费记录来计算物品的共现率,属于用户主观产生的信息,而本文利用电影本身相关的信息来计算物品的共现率,属于客观存在的信息,两者相加可以起到互补的作用,从而进一步提升算法的效果.
图6进一步说明,对于不活跃的用户,即看过的电影或书籍较少的用户,KE-CMF的召回率相比WMF有较大的提升,对于活跃的用户,KE-CMF和WMF的效果差别较小.随着用户活跃度的增加,两种方法的推荐效果大体上都呈上升趋势.

图3 本文的方法与其他方法在两个数据集上的Recall@ K对比结果Fig.3 Recall@K results comparison among different methods on 2 datasets
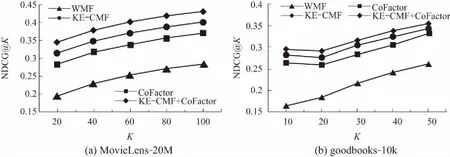
图4 本文的方法与其他方法在两个数据集上的NDCG@K 对比结果Fig.4 NDGG@K results comparison among different methods on 2 datasets

图5 本文的方法与其他方法在两个数据集上的MAP@K 对比结果Fig.5 MAP@K results comparison among different methods on 2 datasets
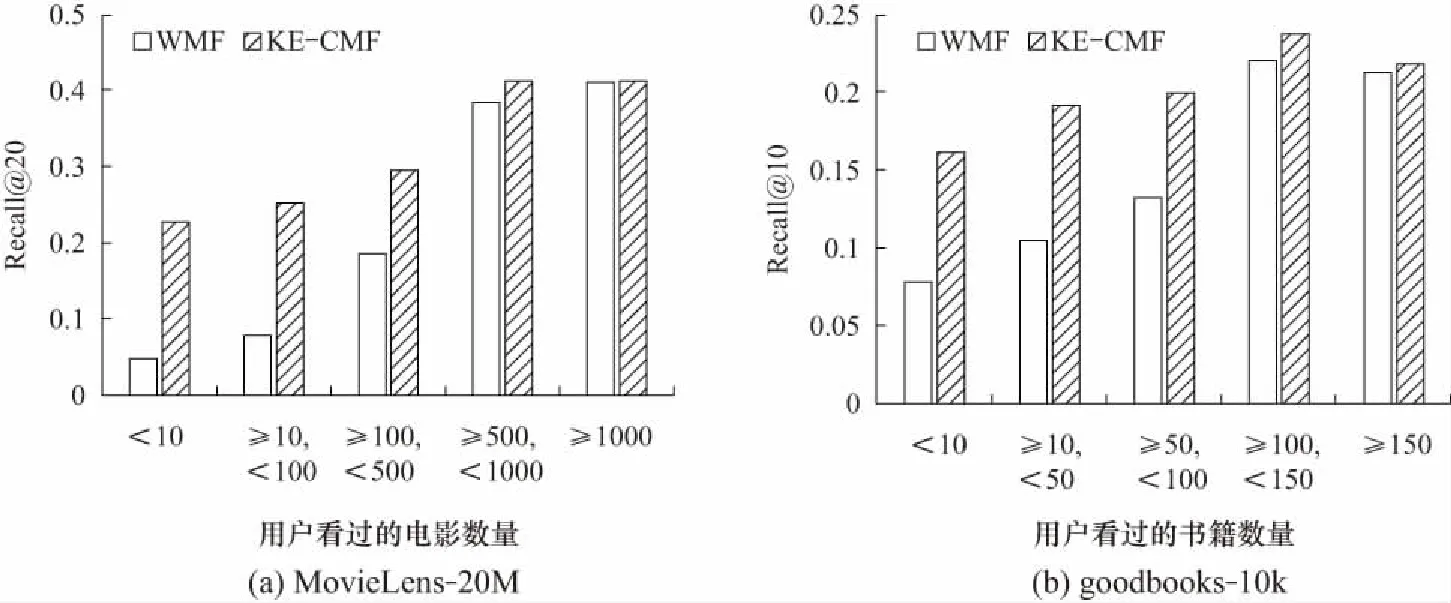
图6 不同的用户集在两个数据集上的平均召回率Fig.6 Average Recall@ of different users on 2 datasets
4 结束语
本文提出了一种基于知识表示学习的协同矩阵分解方法,用一种改进的随机游走策略从物品的知识图谱中生成物品的关联度矩阵,然后联合地分解该矩阵和用户反馈矩阵.本文的基本思想是利用物品本身的信息来对单一的矩阵分解进行正则化,从而得到更好的物品隐向量.实验表明该方法在召回率等指标上优于WMF和CoFactor,并且易于扩展,通过叠加用不同方法生成的物品关联度矩阵,可以进一步提升效果.未来将尝试改进知识表示的方法以及结合物品的文本信息.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
军事文摘(2022年16期)2022-08-24
新高考·高一数学(2022年3期)2022-04-28
新城乡(2018年6期)2018-07-09
读与写·教育教学版(2017年10期)2017-11-10
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
南都周刊(2015年1期)2015-09-10
