
融合词语统计特征和语义信息的文本分类方法研究
2021-08-06 05:42:16张丽,马静
计算机工程与科学 2021年7期
张 丽,马 静
(南京航空航天大学经济与管理学院,江苏 南京211106)
1 引言
文本分类是文本挖掘的关键技术之一,其最直观的作用是将文本进行归类,使得复杂错乱的海量文本能够分门别类地进行存储、查找,在此基础之上,通过对特定领域语料的分析,也能够获得更加深入的文本语义信息。因此,文本分类具有很大的研究价值。
向量空间模型VSM(Vector Space Model)[1]文本表示法是典型的基于统计的方法之一。基于VSM的分类方法,以特征项作为文本表示的基本单位,用特征项及相应权重来代表特征信息,通常利用TF-IDF(Term Frequency-Inverse Document Frequency)方法计算特征项权重,将特征项表示为向量,权值大小代表了这个特征项能在多大程度上将其表示的文本与其他文本区分开来,最终文本被表示为多维向量空间中的一个向量,通过计算向量夹角大小来衡量文本相似度,如KNN(K-Nearest Neighbor)、SVM (Support Vector Machine)等,进而对文本分类。该类方法操作性强,计算简单高效,但这种方法基于词袋法思想,假设特征词之间相互独立,从而忽略了词语之间的语义关系和词语在文本中的上下文结构信息[2]。并且,向量空间模型在处理海量数据时,特征维度会非常高,因此易产生向量空间高维性问题。因此,目前亟需解决的问题就是向量空间的维数灾难和语义缺失,从而进一步提高海量文本分类的效果。裴颂文等[3]针对TF-IDF中存在的不足,提出一种动态自适应特征权重计算方法,不仅考虑了特征项词频和逆文档频率,并且还考虑了文本动态变化情况下特征项的分散度和特征向量梯度差,对特征项权重进行动态调整,有效提高了文本分类的性能。路永和等[4]引入词性改进特征权重计算方法,采用粒子群优化算法迭代计算最优词性权重,与传统的TF-IDF方法相比分类准确率提高了2~6个百分点。
另外,基于文本复杂网络的分类方法,在实现特征提取之后,利用特征词网络的最大公共子图计算文本相似度,进而分类。该方法保留了较多的语义信息和文本结构信息,但该方法计算较为复杂,分类效率和准确率有进一步提升的空间。一些学者利用复杂网络节点信息改进特征权重计算。杜坤等[5]以维基百科知识库为数据源,考虑特征项之间的语义关联构造文本复杂网络,构造评估函数来评价网络节点重要程度,引入特征项在文本中的综合特征指数及类别区分度改进TF-IDF,提高了文本相似度计算的准确率。
针对TF-IDF方法的不足,本文首先利用文献[6]的方法,结合共现关系和依存句法关系构建文本复杂网络,在保留语义信息的同时降低节点冗余。在此基础上,基于文本复杂网络中网络节点统计特征改进TF-IDF方法,除词频外,保留特征词之间的句法关系、语义信息和结构信息。并将特征向量和通过LSTM(Long Short-Term Memory)算法得到的语义向量融合,使得文本表示向量特征信息更为丰富,文本向量化的结果更精确,进而达到提升文本分类准确率的目标。最终实验结果表明,本文提出的分类方法准确率更高。
2 相关研究理论
2.1 TF-IDF
传统的特征权重计算方法主要有二分类法、词频TF(Term Frequency)法、逆文档词频IDF(Inverse Document Frequency)法、TF-IDF法,其中,TF-IDF法被广泛应用于文本相似度的计算。利用VSM对一篇包含n个特征词的文本进行表示,文本dj(t1,t2,t3,…,ti,…,tn)最终可以被表示为一个n维向量dj=((t1,W1),(t2,W2),…,(ti,Wi),…,(tn,Wn)),其中ti表示文本的第i个特征词,Wi表示第i个特征词的权重,权值越大,其文本表示能力越强。
(1)二分类法。若某特征词在文本中出现,则其权重即为1;不出现,则其权重即为0。这种方法将所有特征词同等看待,既不突出也不抑制任何一个特征[7]。其权重计算公式如式(1)所示:
(1)
(2)词频TF法。TF反映特征词在文档内部的分布情况,是指特征词在文档中出现的次数与文档中所有词语数量的比例。这种方法认为特征词在文档中出现的次数越多,其表征文档的能力越强。其权重(特征词ti在文本dj中出现的频率)计算公式如式(2)所示:

(2)
其中,ni,j是特征词ti在文本dj中出现的次数,∑knk,j表示文档dj中的词语数量。
(3)逆文档频率IDF法。IDF反映特征词在文档集中的分布情况,这种方法认为只在小部分文本中出现的特征词比在大多数文本中都出现的特征词能更好地表征文本类别信息。其权重计算公式如式(3)所示:
(3)
其中,|D|表示语料库中的文件总数,|{j:ti∈dj}|表示包含特征词ti的文档数目。
(4)TF-IDF法。同时考虑TF与IDF,并将向量进行归一化,特征词的权重计算公式如式(4)所示:
TFIDFi,j=
(4)
TF-IDF通过TF来反映文本内部特征,单纯使用词频作为衡量词语重要性的依据,不够全面,因为有些重要词语出现的次数并不多,词语的位置信息、词性、词语间的语义联系、词语在局部及全局的影响力等都是词的重要特征,该方法无法利用这些信息,其权重计算结果很可能不准确。
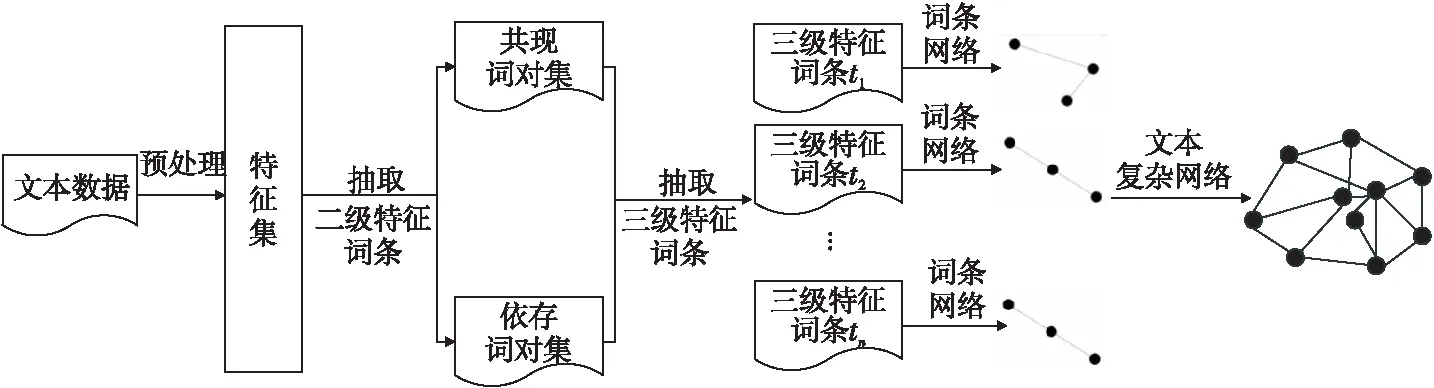
Figure 2 Construction method of text complex network图2 文本复杂网络构建方法
2.2 LSTM
长短期记忆LSTM神经网络模型[8,9]是循环神经网络RNN(Recurrent Neural Network)模型[10]的一个变种,是一种循环神经网络。LSTM学习的过程是对序列化输入的文本信息进行由左到右的学习,这也符合人类读取文本的过程。在文本分类研究中,一般会取RNN或者LSTM最后一个节点的输出作为文本表示,然后结合Softmax和交叉熵损失函数来进行文本分类模型的训练。然而,RNN在训练过程中会出现梯度弥散或者梯度爆炸等现象,并且当句子较长时,随着记忆单元的传递,对一开始的输入信息会有较多的遗忘。LSTM通过门控机制可以很好地避免记忆衰减,其隐藏层到隐藏层的权重是网络记忆的控制者,实现对文本的长期依赖进行学习,所以本文选择LSTM捕捉序列信息。LSTM通过“门”结构从细胞状态去除信息或向细胞状态增加信息,由记忆单元、输入门、遗忘门和输出门4个主要元素组成,如图1所示。
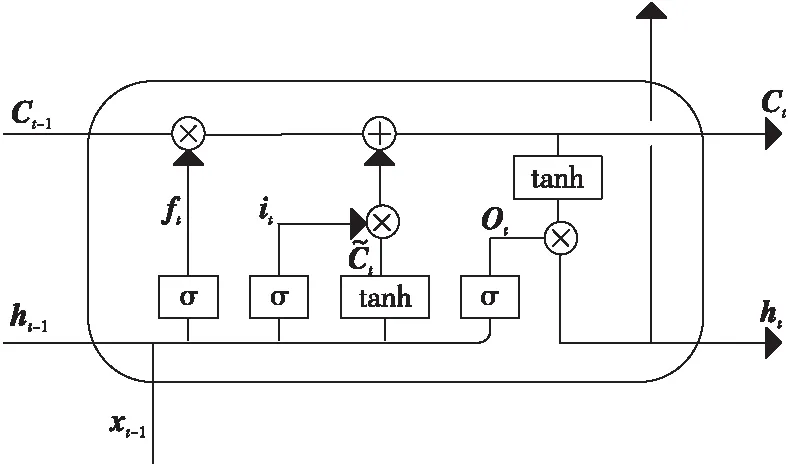
Figure 1 Structure of LSTM cell图1 LSTM单元结构
LSTM单元在t时刻更新的公式如式(5)~式(10)所示:
ft=σ(Wf[ht-1,xt]+bf)
(5)
it=σ[Wi[ht-1,xt]+bi]
(6)
(7)
(8)
Ot=σ(Wo[ht-1,xt]+bo)
(9)
ht=Ot⊙tanh(Ct)
(10)
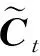
3 结合共现关系和句法关系的文本复杂网络构建及特征提取
3.1 文本复杂网络构建
本文构建的特征降维文本复杂网络采取文献[6]的方法,结合词语间共现关系和依存关系,文献[6]验证了该方法能在表达文本语义的同时实现降维,有助于提升文本分类效果。构建方法如图2所示,其中共现词对集依据共现关系抽取,出现在同一个句子中且跨度不大于2的词语之间存在共现关系。依存词对集依据句法依存关系抽取,词语之间的句法关系主要包括主谓关系(SBV)、动宾关系(VOB)、定中关系(ATT)、介宾关系(POB)等14种关系类型。分别抽取高于共现概率阈值Tm和依存概率阈值Tr的词对组成二级特征词条,以依存词对丰富共现词对的语义信息,获得三级特征词条,最后生成文本复杂网络。通过对所有包含其一条边的两端节点表示的词的词条的权重求和,计算出这一条边的权重。文本集中的文本dj就抽象为无向图G=(N,E,W),其中,N、E、W分别表示该文本中的节点、边和边的权重。
3.2 文本特征提取
特征提取分为特征选择和特征权重计算2个步骤,本文基于复杂网络利用主成分分析PCA(Principal Component Analysis)和TOPSIS(Technique for Order Preference by Similarity to an Ideal Solution)方法实现特征选择,结合复杂网络节点统计特征改进TF-IDF权重计算方法。
(1)PCA方法确定节点评价指标权重。
本文选取8个指标:度、聚类系数、加权度[11]、加权聚类系数[12]、介数中心度[13]、度中心性[14]、接近中心性[15]和PageRank值,较为全面地评价节点重要性。利用PCA方法进行降维,确定各个指标的权重。
PCA方法通过对数据进行降维,提高计算效率。以本文为例,用于节点重要性评价的p个指标组成指标集x1,x2,x3,…,xp,r个节点的指标构成了原始数据矩阵X=[xij]r×p,(i=1,2,…,r;j=1,2,…,p),其中xij表示第i个节点在第j项指标上的数据。主成分分析法将标准化后的原始数据矩阵进行线性计算,求得协方差矩阵,即原始数据的相关矩阵R。并求解得到特征值λ1≥λ2≥…≥λp≥0,以及特征向量u1,u2,u3,…,up。u1,u2,u3,…,up分别是x1,x2,x3,…,xp的第1,第2,…,第p个主成分。u1,u2,u3,…,up互不相关且方差递减。前i个主成分在总方差中的主成分贡献率为αi,累计贡献率为E。选取的主成分数量越多,使得对应的累计贡献率越高,丢失的数据信息就越少,但是后续处理的运算量也就越大,一般情况下选取累计贡献率E≥85%的最小整数,以达到对节点评价指标降维的目的。
(2)TOPSIS方法评价节点重要性。
本文拟采用TOPSIS方法[16],利用降维后网络统计的指标对各个节点重要性进行评价。TOPSIS的基本原理是通过计算评价对象与最优解、最劣解的相对距离来排序。基于TOPSIS方法利用m个统计指标对一个包含r个节点的网络评价节点重要性,具体步骤[16]如下所示:
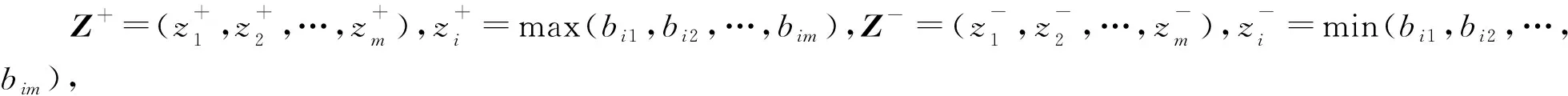
(3)特征权重计算。
为了准确计算文本间的相似度,在确定文本特征之后,需要对每个文本的所有特征项赋予一定的权重。本文基于前文构建的特征降维文本复杂网络,利用多个节点统计指标,考虑了词语在全文及局部的影响力、与其他词语的关联程度,综合考量了特征项的语义信息和统计信息提取特征词。因此,利用基于前文构建的特征降维文本复杂网络节点统计指标评价的节点重要性结果,改进IF公式,计算文本特征权重,能在文本转换为向量的过程中保留一定语义内容。本文的特征权重Wij计算公式如式(11)所示,其中,IDFi表示特征词ti的逆文档频率,计算方法如式(3)所示。IMDij表示特征词ti在文本dj中的重要度,计算方法如式(12)所示,其中,Cij是上文依据TOPSIS方法得到的文本ti在文本dj中的重要性系数。
Wij=IMDij*IDFi
(11)
(12)
4 融合词语统计特征和语义信息的文本分类方法
4.1 基于LSTM的文本向量表示
LSTM用来处理具有序列关系的数据。首先需要构建LSTM输入词向量矩阵,本文采用文本分析领域常用的word2vec方法[17],把文本中的每个词都表示成一定维度的词向量形式。本文采用自身语料集作为训练集,得到词向量,具体操作细节为:将word2vec训练出来的结果作为词向量矩阵的初始值,每条文本在输入到模型之前都会进行一个查表操作,查找出每个词语对应的词向量,而该词向量矩阵在训练模型的过程中会作为网络参数进行进一步微调,以达到更好的训练效果。通过将词向量矩阵输入LSTM模型,可以获得相应的用于表示文本的文本向量,代表的是整个文本的语义信息。
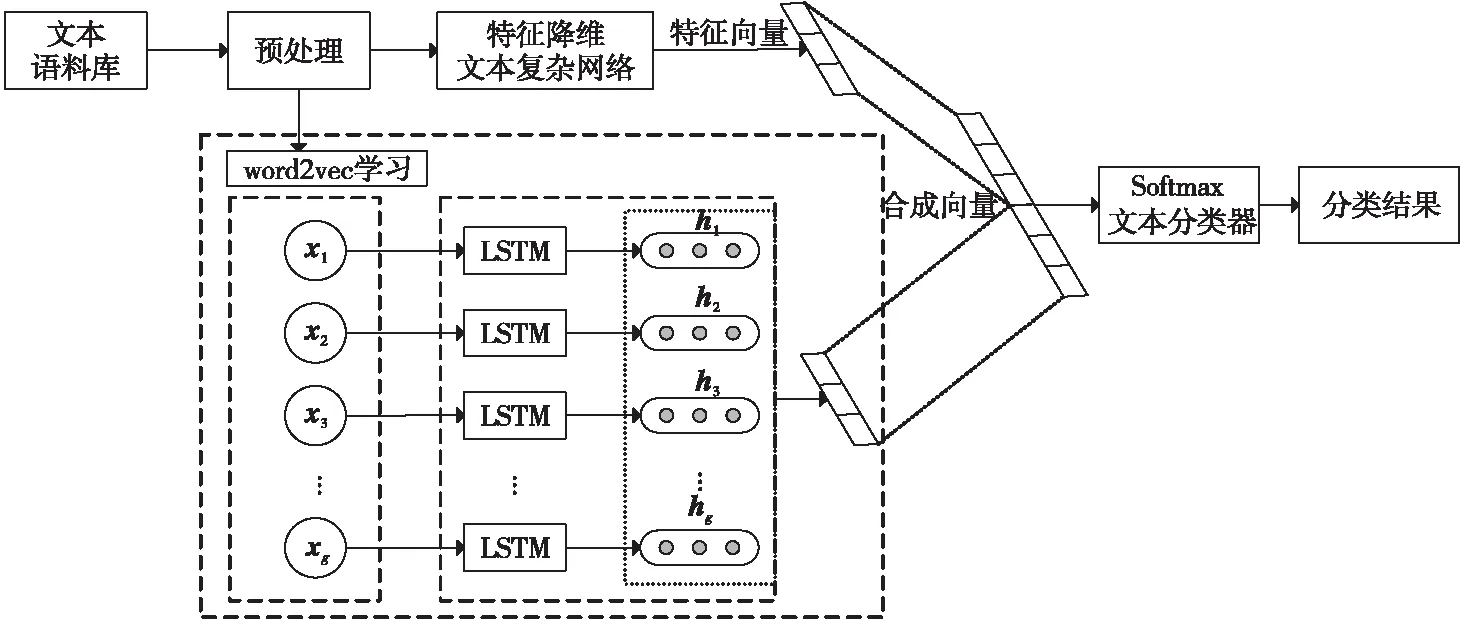
Figure 3 Flow chart of text classification method combining word statistical features and semantic information图3 融合词语统计特征和语义信息的文本分类方法整体流程示意图
4.2 融合特征向量和语义向量的文本表示向量
为了丰富文本表示向量包含的文本信息,本文将上文LSTM模型中提取的语义向量和基于特征降维文本复杂网络提取得到的特征向量相结合,从2个维度来表征文本信息,使新的文本表示向量信息量更丰富、区分度更高。对2种特征先分别进行归一化,然后再进行组合,从而构建出新的文本特征表示,最终文本表示向量如式(13)所示。
(13)
其中,zj为文本dj的LSTM文本向量表示,而θj则为基于特征降维文本复杂网络提取的文本dj的特征向量,vj为组合后的语义特征表示向量,T则表示对矩阵的转置操作,‖·‖2表示2-范数,用来对zj和θj进行归一化处理。
最后,将融合后的文本表示向量送入Softmax分类器,实现文本分类。
4.3 本文方法流程
本文首先构建一种特征降维文本复杂网络进行文本表示,然后基于文本复杂网络实现文本特征提取,将特征向量化,接着利用LSTM深度学习算法直接提取文本向量,然后将特征向量与LSTM提取的文本向量相融合,再送入Softmax分类器实现文本分类。方法整体流程示意图如图3所示。
该文本分类方法的整体步骤如下所示:
步骤1对原始文本语料进行清洗、分词和去停用词等预处理工作;
步骤2对预处理后的文本基于特征降维文本复杂网络进行表示;
步骤3依据网络节点统计指标实现文本特征提取,并计算特征权重,将文本特征向量化,得到文本的特征向量;
步骤4进行word2vec学习,将语料中的每条文本表示为词向量矩阵;
步骤5将步骤4得到的词向量矩阵作为输入,进行LSTM模型训练,最终得到代表原文本词向量层面信息的文本向量;
步骤6将步骤5得到的文本向量与步骤3得到的特征向量相结合来最终表示文本信息,并进行Softmax文本分类。
5 实验
5.1 实验数据
(1)数据存储。
本文的实验语料来源于搜狗实验室发布的2012年6月和7月期间,国内若干新闻站点中国际、体育、社会和娱乐等18个频道的新闻数据,数据内容包括URL、ID、新闻标题、新闻正文和作者等字段。人工筛选删去少量无关新闻、重复新闻和字数较少新闻,最终用于实验的文本数是8 000条,其中财经类、健康类、教育类、军事类、旅游类、汽车类、体育类和娱乐类各1 000条。本文根据实验需要将文本数据标识号、类别标识、分词后文本、二级特征词、依存词对、三级特征词和权重信息等存入MySQL数据库中。
(2)数据清洗。
网络新闻文本数据相较于微博、论坛和评论数据,更加规范,但是仍然存在着一些脏数据,例如:
①图片过多而字数过少的新闻文本:例如一些旅游类的新闻,其中大多是一些风景照,字数过少,包含的信息过少,本文将长度小于20个字符的新闻文本数据直接删除;
②重复出现的新闻文本:热点新闻文本可能出现多次;
③包含跳转链接的新闻文本:一些热点新闻,可能出现多家媒体进行转载的情况,这类新闻的末尾通常含有原网页链接,如一篇转载自光明网的新闻,在末尾可能包含URL字符串:“http://www.gmw.cn/…”,本文利用正则表达式直接将文本中所有URL字符去除;
④编辑名字、记者名字、杂志社名称:新闻文本经常在开头或者末尾出现编辑名字与记者名字,这不属于文本的语义信息,例如,作者:张三,编辑:李四,本文利用正则表达式直接将这些无用信息去除;
⑤去除新闻文本中的英文信息:本文研究不涉及双语文本的分类,只关注中文文本的分类方法,因此将过滤掉英文信息。
5.2 实验过程
本文实验主要参数设置如表1所示,特征词数量s将通过多次实验对比确定最优值。
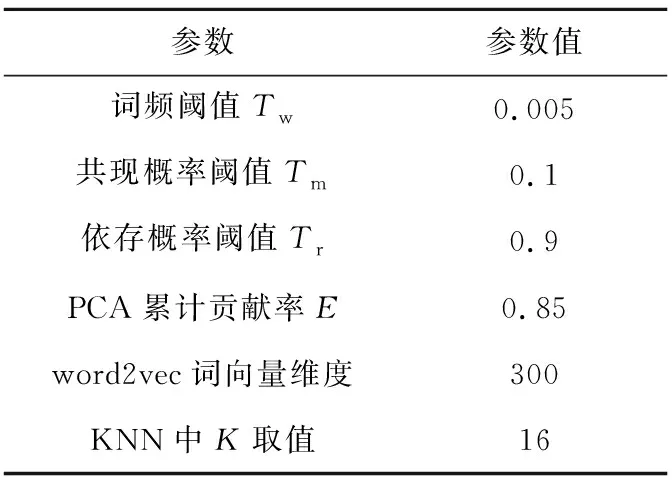
Table 1 Main parameter setting
为了与本文方法进行对比,本文设计了对比实验,求出各个分类方法在同一数据集中上分类表现,6个对比方法具体如下所示:
(1)方法1:使用传统的TF-IDF方法实现特征提取和权重计算,最终得到文本表示向量,再结合KNN算法实现文本分类。
(2)方法2:使用传统的TF-IDF方法实现特征提取和权重计算,最终得到文本表示向量,再结合SVM算法实现文本分类。
(3)方法3:利用本文设计的基于文本复杂网络的特征提取结果,并使用改进TF-IDF实现特征向量化,再结合KNN算法实现文本分类。
(4)方法4:利用本文设计的基于文本复杂网络的特征提取结果,并使用改进TF-IDF实现特征向量化,再结合SVM算法实现文本分类。
(5)方法5:使用LSTM模型提取文本向量,送入Softmax实现文本分类。
(6)方法6:使用本文提出的特征提取算法和特征权重计算方法提取特征向量,并使用LSTM模型提取文本向量,再将特征向量和文本向量相融合,最后送入Softmax分类器实现文本分类。
5.3 实验结果及分析
(1)特征词数量。
本文以评价指标准确率precision、召回率recall和F1-score值为依据,不断更改特征词数量s的取值进行多次实验,计算出了不同特征词数量取值下的准确率、召回率和F1值的变化,实验结果如图4所示。由图4可知,随着特征词数量的不断增加,准确率、召回率和F1值均在不断提高,反映出文本分类效果的提升。但是,由于随着特征词数量的增加,方法的运行时间会显著增加。当阈值设定为15时,分类效果提升最明显;当阈值设定为20时,准确率、召回率和F1值提升效果不明显,且此时特征词较多会增加方法运行时间,所以本文选择将文本特征提取中特征词数量s设置为15,此时文本分类效果较好且运行时间较短,便于后续实验的进行。
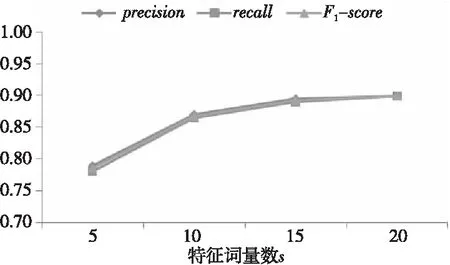
Figure 4 Influence of number of characteristic words on the evaluation index图4 特征词数量对评价指标的影响
(2)分类效果。
通过方法构建和实验验证能够获得各组实验结果,实验结果记录如表2所示,6组实验结果平均F1值对比如图5所示。从表2和图5可以看出,传统的分类器KNN的分类效果最差,本文提出的结合复杂网络统计特征的文本分类方法效果最好。具体分析如下:

Table 2 Evaluation index values of text classification of each method

Figure 5 F1-score of six methods 图5 6组方法的F1值
方法1与方法2相比、方法3与方法4相比,方法2和方法4效果较好,说明在该语料库中SVM分类器的表现好于KNN的。方法1与方法3相比、方法2与方法4相比,方法3和方法4效果更好,使用文本复杂网络进行特征提取结合KNN或SVM进行分类,分类效果有所提升,说明向量空间模型在进行文本表示时受限于独立性假设,不利于引入语义信息,本文设计的基于特征降维文本复杂网络的特征提取方法能够有效获取文本语义信息。基于LSTM的文本分类实验中,结合文本复杂网络和LSTM的方法,分类准确率达到92.02%,比基于LSTM的方法高了2.8%,比基于文本复杂网络和KNN的方法高了4%,比KNN高了14%,说明LSTM方法相比传统机器学习方法在文本分类上有明显的优势,并且在LSTM抽取出的语义信息中加入基于文本复杂网络的特征信息能够有效提高文本的分类效果。
实验验证了本文设计的融合词语统计特征和语义信息的文本分类方法确实进一步提升了文本分类的准确率。
6 结束语
为了解决处理海量文本语料时,传统方法带来的维数灾难和语义缺失,从而导致分类不准确的问题,本文首先基于文本复杂网络节点统计特征改进TF-IDF方法得到特征向量,在特征表示中融合了词语的句法关系、词性、结构信息和词频计算特征权重,弥补了“词袋”模型的缺点;接着基于LSTM提取的语义向量,将特征向量与语义向量相融合,使新的文本表示向量信息量更丰富、区分度更高,使最终的文本分类效果更好。本文方法仍存在巨大的探索空间,向量融合方式较为粗糙,仅将特征向量和文本向量分别归一化后相组合,在维度相差较大时,分类效果不稳定。下一步考虑将此分类方法运用到短文本分类和舆情分析中。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02 09:46:54
保定学院学报(2022年2期)2022-04-07 02:26:50
开放教育研究(2020年2期)2020-03-31 01:54:14
计算机技术与发展(2018年8期)2018-08-21 02:08:14
许昌学院学报(2018年4期)2018-05-02 12:27:37
中国机械工程(2017年22期)2017-12-02 01:52:34
中华建设(2017年1期)2017-06-07 02:56:14
现代语文(2016年21期)2016-05-25 13:13:44
中文信息学报(2015年4期)2015-04-21 08:29:12
大连民族大学学报(2015年2期)2015-02-27 08:28:11
