
基于改进KNN算法的汽轮机通流故障诊断方法及应用
2021-08-03 08:27陈时熠华心果向文国
热力发电 2021年7期
闾 城,陈时熠,华心果,向文国
(东南大学能源热转换及过程测控教育部重点实验室,江苏 南京 210096)
众所周知,能源是人类生活中必不可少的一部分[1]。传统的火力发电由于污染重、效率低等缺点开始逐渐被其他发电方式所替代。燃气轮机联合循环发电由于其高效率、低排放、分布式等特性,已经逐渐成为能源领域重要的发展和研究方向之一[2]。联合循环用汽轮机是燃气-蒸汽联合循环装置中重要的设备之一,其技术水平也直接影响到联合循环机组的循环效率、设备可用率及单位造价[3]。因此,联合循环汽轮机的经济性能、运行灵活性和安全可靠性将影响联合循环的总体性能。
作为发电的主要设备,汽轮机长期处于高温、高压、高速的工作环境中,极易发生性能退化[4],一旦发生退化对汽轮机的安全和经济运行将产生巨大的影响,因而对汽轮机退化诊断具有重要意义[5]。目前美国通用电气(GE)、日本东芝电气、日立电气、富士和三菱等企业均已拥有完善的汽轮机故障诊断技术和体系。
我国在汽轮机故障诊断研究方面起步较晚,与西方发达国家有一定的差距[6]。董晓峰基于RCM分析,采用主元分析提取通流部分故障征兆,再进行聚类分析,归纳了通流部分的故障模式类[7-8];忻建华等根据通流故障与热力参数的关系,提出了高压缸通流部分故障的热参数模糊诊断法[9];上海交通大学郝志莉、叶春总结了汽轮机通流部分故障的特性并进行了分类[10]。
目前的故障诊断方法一般都只能发现汽轮机的性能发生变化,但并不能准确地判断出故障的具体位置及类型。
因此本文提出了基于特征通流面积建立汽轮机系统性能退化模型,模拟汽轮机系统的故障样本与测试样本,建立设备故障样本库。基于汽轮机系统热力参数变化规律,计算当前机组运行数据样本相对于设备故障样本的相似度,判定当前机组各设备已发生故障的概率,实现对汽轮机系统设备故障的快速诊断。
1 汽轮机系统
本文以某S109FA联合循环机组汽轮机为研究对象,该机组由1台F级燃气轮机、1台余热锅炉,1台蒸汽轮机组成。汽轮机为三压、再热、抽汽凝汽式、双缸双排式汽轮机,部分设计参数见表1。
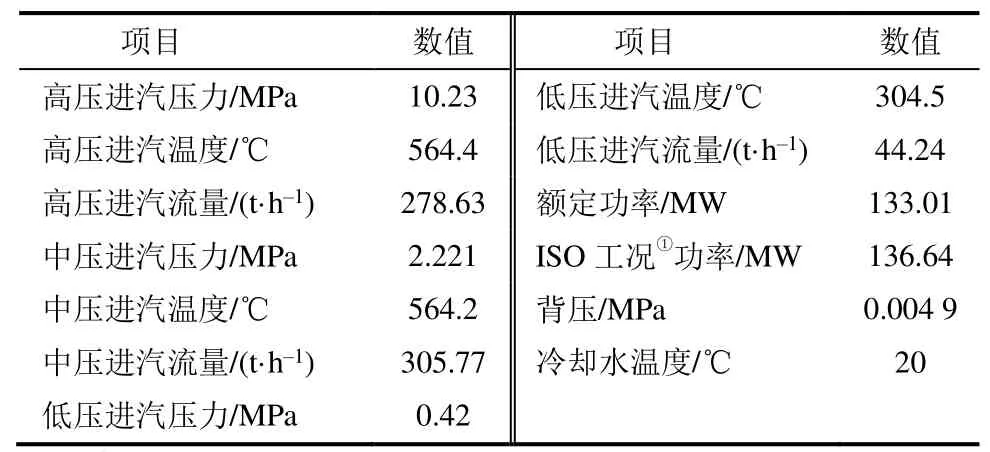
表1 汽轮机设计参数Tab.1 Design parameters of the steam turbine
1.1 通流部分故障类型及原因
汽轮机通流部分的故障按照发生、发展的进程分类可以分为突发性故障与渐发性故障[11]。突发性故障主要包括叶片断裂、阀门杆脱落等。此类故障会让汽轮机系统瞬间发生巨变,产生重大事故。
渐发性故障主要包括流道的结垢与磨损。此类故障属于日积月累型的,前期并不会影响汽轮机的运行,只要积累到一定程度时才会引发故障。本文主要研究此类故障。
1.2 汽轮机特征通流面积计算方法
特征通流面积是徐大懋院士提出的无量纲量。其特点为:对于给定的级组,特征通流面积只与几何因素相关而与工况无关;在几何尺寸未发生改变时,无论工况如何的变化,特征通流面积值都不会发生改变[12-13]。
特征通流面积可由弗留格尔公式变形得到,对于某一级组,设有2个工况(工况1、工况2),各参数应满足弗留格尔公式:

式中,G1、G2为变工况前后级组流量,T1、T2为变工况前后级组前温度,p01、p02为变工况前后级组前初压,pZ1、pZ2为变工况前后级组后背压。
等式左右两边变形可得特征通流面积F:

式中,П1=pZ1/p01,П2=pZ2/p02。
由于弗留格尔公式在推导过程用到了理想气体假设,由公式pV=nRT,可以将F中的T以p和V来替代,得到特征通流面积Fv:
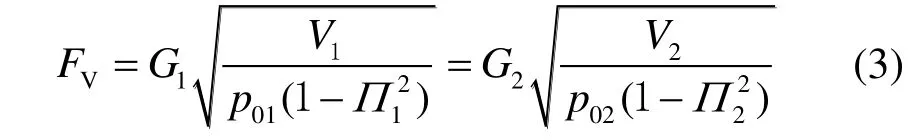
根据文献[14]中的研究可以发现,公式(2)的精度较低。因此本文采用公式(3)进行计算。
定义特征通流面积退化系数D:

式中,F为汽轮机实际特征通流面积,F0为汽轮机初始特征通流面积。
特征通流面积退化系数表征了汽轮机级组通流部分截面积的变化程度。特征通流面积变化系数为1代表特征通流面积未发生变化;特征通流面积退化系数小于1代表特征通流面积变小,对应的级组部分动静叶片结垢、变形和流道受阻等故障形式;特征通流面积退化系数大于1代表特征通流面积变大,对应级组动静叶片断裂、磨损或腐蚀等故障形式。
1.3 模型验证
分别选取ISO 100%、75%、60%、50%、40%、30%工况,根据电厂提供的热平衡图,对高中低压缸的特征通流面积进行定量计算,并建立机组的热力档案,见表2。

表2 不同工况下各级组的特征通流面积Tab.2 The characteristic flow area of each group under different working conditions
由表2可以计算得出,对于高压缸的特征通流面积,最大误差不过0.29%,中压缸最大误差2.8%,低压缸最大误差4.8%,均小于5%,判定此计算模型可用。
2 KNN算法原理
KNN(K-nearest neighbor)算法[15]是一种简单高效的分类算法。其核心思想是:每个数据样本都对应特征空间的1个点,如果在样本空间内1个距离当前未知类别数据样本最相邻的K个已知类别样本大多数属于某一个类别,则当前样本也属于这个类别。与其他分类算法不同的是,KNN算法并不通过判别类域确定样本所属类别,故KNN算法没有传统分类算法的学习过程。其算法简单、计算速度快,对样本数据集的异常值不敏感[16-20],特别适用故障诊断这种多分类问题[21]。
2.1 传统KNN算法
KNN算法计算方法如式(5)—式(7)所示。首先,获取已有故障类别标签的性能退化样本数据集:

式中:X为故障样本向量的特征值;y为故障样本标签;c为故障类别;上标n为故障样本特征数,即特征向量维度;下标i为故障样本序号,N为故障样本个数,k为故障类别数。
通常,机组采集的蒸汽系统的运行数据种类多样,各数据点采集的数据数量级相差较大。直接通过采集的数据样本计算样本之间距离时,计算结果将会被数量级较大的特征主导,而数量级较小的特征几乎影响不到计算结果,故需要通过归一化方法将所有数据映射到同一尺度。
对故障样本特征归一化:

式中,X'为归一化后的特征值,Xmax为特征在故障样本集中的最大值,Xmin为特征在故障样本集中的最小值。
将故障数据样本映射到同一尺度后,计算未知类别数据样本到故障样本数据集中各样本的距离。样本距离越远,表示2个样本间的差异越大。根据所研究的分类问题不同,可以选用不同类型的样本距离度量方式。不同距离度量方式反映了不同意义上的样本差异,常见的距离度量方式有:
欧式距离(Euclidean),表征了空间两点间的真实距离,计算式为

曼哈顿距离(Manhattan),表征了空间中两点之间的直角边距离,是对多个维度上的距离求和的结果,计算式为

切比雪夫距离(Chebyshev),表征了空间中两点各坐标数值差的最大值,计算式为

余弦距离(Cosine),表征了空间中两向量夹角余弦值,反映了数据样本特征向量在方向上的差异,计算式为
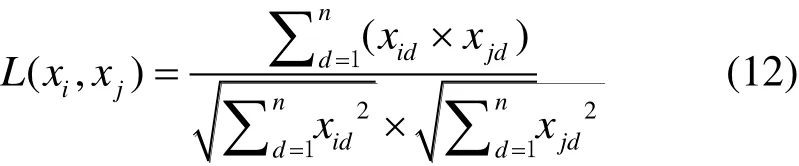
式中:L为样本间的距离;d为故障样本的第n个特征;i为未知类别数据样本;j为故障样本集中的样本。
对当前数据样本到故障样本距离排序,选取K个距离最小的样本。即这K个近邻与当前数据样本最为相似,而当前数据样本的特征值可能具有不同类别的数据样本特征,导致这K个近邻并不全部属于同一个类别。此时,通过K个近邻的投票来解决这个问题,即K个近邻大多数所属的类别,判定为当前数据样本所属类别,故在KNN算法中,K取值通常为奇数,来避免2个类别投票结果相同。
2.2 改进KNN算法
KNN算法如图1所示。图1中,绿色圆形表示当前需要判断类别的数据样本,黑色实线围成的圆圈表示当K=5时,当前数据样本的近邻空间。近邻空间内,包含红色方形和橙色三角形2个类别的数据样本,其中红色方形有3个,橙色三角形有2个。按照前述的传统KNN算法,根据投票原则,绿色数据样本应当判定为红色方形的类别。而根据图1,红色方形均处于近邻空间的边缘位置,而橙色三角形距离当前数据样本距离较小,显然,绿色数据样本与橙色三角形数据样本具有更大的相似度,绿色数据样本隶属于橙色三角形类别概率更大。在此种情形下,传统KNN算法对数据样本的类别判断失误,究其原因在于传统KNN算法投票决策方式认为K个近邻在决策过程中具有同等权重,而未考虑到K近邻样本距离的大小对决策过程的影响。本文通过样本距离计算K近邻样本在决策过程中的权重,评估当前数据样本与K近邻样本隶属于同类别的概率,以此对传统KNN算法决策过程进行改进。

图1 KNN算法示意Fig.1 Schematic diagram of the KNN algorithm
数据样本间距离越小,则认为2个样本相似程度越大,故K近邻中样本距离小的近邻,在决策过程中占有更大权重,可以认为权重是样本距离的倒数,K近邻权重计算方式为

定义K近邻样本距离占K近邻样本距离和的比值为当前样本与K近邻样本隶属于同一类别的概率。计算当前样本与各K近邻样本同故障类型的概率,并对同类别K近邻样本概率求和,即

式中,W(Xi,Xj)为j样本在i样本分类问题中的权重,P(Xi,Xj)为i样本和j样本隶属于同一故障类别的概率,P(Xi,cm)为i样本隶属于第m个故障类别的概率。
此时可以实现当前样本相对于各故障类型的不确定度估计,当前样本隶属于各类别的概率表征了当前数据样本隶属于各故障类型的可能性,故隶属概率最大的故障类别即为当前样本所属类别。
2.3 典型设备故障样本建立
本文考虑高中低压缸流道受阻与流道腐蚀6种故障型式,具体描述见表3。

表3 汽轮机系统典型故障型式Tab.3 Typical failure modes of steam turbine system
通过汽水系统性能退化模型模拟故障样本,设定汽水系统环境参数为ISO工况,余热锅炉入口烟气参数分别设置为ISO工况下100%、75%、50%负荷时燃机排烟参数,各类故障的设备性能退化系数分别在表3预设范围内选取。每种排烟参数下计算6种不同性能退化程度数据样本,则每类故障包含18个性能退化样本,故障样本总计108个。对每类故障,在故障样本参数预设范围内,随机生成1个检测样本,其参数设置见表4。

表4 故障测试样本参数设置Tab.4 Parameters setting for the failure test sample
根据上文特征通流面积的计算公式选取高中低压缸的进口蒸汽的温度,压力和流量作为样本特征。为消除特征参数数量级对样本距离的影响,通过式(8)对故障样本特征参数归一化。
3 汽轮机故障测试样本验证
3.1 KNN算法寻优
KNN算法分类准确性依赖于K值和距离度量方式的选取。根据2.3节生成的故障样本集对KNN算法超参数寻优。对于包含108个样本的故障样本集,随机选取其中75%样本作为训练集,25%作为测试集,分别计算KNN算法在K∈[0,10]且K∈N,度量方式分别为欧氏距离、曼哈顿距离、切比雪夫距离和余弦距离的设定下,通过训练集判断测试集类别的分类正确率。分类正确率计算公式为

式中,AAccuracy为分类正确率,Pc为分类正确的样本个数,P为分类的样本总数。
由于不同训练集划分方式影响测试集上的分类正确率,故随机多次划分数据样本取分类正确率均值。重复上述过程1 000次,计算分类正确率平均值,结果如图2所示。由图2可见:不同K值下,KNN算法选用余弦距离作为距离度量方式,正确率均最高;在选用余弦距离作为距离度量方式时,K=1, 2, 3分类正确率均高于0.95,分类准确性都较为理想;由于K值过小时,算法分类结果易受数据噪声干扰,故取K=3,余弦距离作为距离度量方式。

图2 KNN算法分类正确率随超参数变化关系Fig.2 Changes of classification accuracy of the KNN algorithm with hyperparameter
随机森林算法及XGBoost算法是2种在复杂分类问题上取得优秀效果的集成算法,通过建立基于相同故障样本集的随机森林和XGBoost算法模型,与KNN算法做对比。随机划分训练集,通过2种算法的最优超参数训练分类算法模型,并重复1 000次,将2种算法平均分类正确率及平均分类时间与KNN算法作比较,结果如图3所示。由图3可见,相较于复杂的集成分类算法,KNN算法对于本文所述的汽水系统异常设备定位问题具有分类正确率高和分类时间短的优势。

图3 分类算法平均分类正确率与平均分类时间比较Fig.3 Comparison of average classification accuracy rate and average classification time of classification algorithms
设定KNN算法K=3,余弦距离作为距离度量方式,前述的包含108个样本的故障样本集作为训练集,对表3对应的6个故障测试样本的故障类别进行预测。
3.2 传统KNN算法的验证结果
首先计算各故障测试样本相对于训练集样本的余弦距离,找出各故障测试样本余弦距离最小的3个近邻,各故障测试样本的3个近邻和余弦距离见表5。由表5可见,各测试样本距离最小的近邻1所属类别均与测试样本的故障类别相符,近邻2中只有1个样本所属类别与测试样本故障类别不符,近邻3中有5个样本所属类别与测试样本故障类别不符。

表5 故障测试样本近邻与样本距离Tab.5 The nearest neighbor and distance of fault test sample
通过传统KNN算法对故障测试样本所属故障类别进行判别的结果见表6。由表6可见,6个测试样本中,只有测试样本5故障类别判断错误,因为测试样本6的近邻2和近邻3都属于故障类别3,虽然样本距离最小的近邻1属于故障类别5,但根据投票原则,测试样本6仍被判定为故障类别3。故传统KNN算法的投票决策方式在特定情况下并不能准确利用样本近邻判别当前样本类别。

表6 传统KNN算法对故障测试样本的判别结果Tab.6 The discrimination result of the failure test sample using the conventional KNN algorithm
3.3 改进KNN算法的验证结果
通过改进的KNN算法决策方式对测试样本故障类型进行判别,首先通过式(14)计算测试样本各近邻在分类过程中的权重,根据式(15)计算测试样本与近邻隶属于同一类别概率,计算结果见表7。

表7 故障测试样本近邻权重和同类别概率Tab.7 The nearest neighbor weight and the same-class probability of failure test sample
样本距离更近的近邻,在决策过程中被赋予了更大权重,权重越大,测试样本与近邻隶属于同一类别的概率越大。测试样本隶属概率最大的故障类别判定为测试样本所属类别,通过改进型KNN算法决策方法判定的测试样本故障类别结果见表8。

表8 改进KNN算法对故障测试样本的判别结果Tab.8 The discrimination result of the failure test sample using the improved KNN algorithm
改进KNN算法对测试样本集所有样本故障类型均做出了准确判断,并给出了测试样本隶属于各故障类型的概率。由表7可见:对传统KNN算法判断错误的测试样本5,改进KNN算法计算了此样本3个近邻在决策过程中的权重,分别为2.964、1.547和0.585,表明近邻1在决策过程中起到了主导地位;通过权重计算样本5与各近邻同类别概率,分别为0.582、0.304和0.114;而近邻2和近邻3属于同一类别,故样本5隶属于故障5的概率为0.582,隶属于故障1的概率为0.418,最终判断样本5隶属于故障5。
可见改进KNN算法通过样本评估近邻在决策过程中的权重,取得了比传统KNN算法更高的分类正确率。并且改进KNN算法在本文所讨论的汽轮机系统故障诊断问题上,取得了良好的效果。
4 结 论
1)K=3时,余弦距离作为距离度量方式的KNN算法更适用于汽轮机系统故障诊断问题,其平均分类正确率为0.955 6。
2)对测试样本故障诊断结果表明,改进KNN算法比传统KNN诊断准确率更高,对测试样本诊断准确率为100%,采用改进KNN算法汽轮机系统故障诊断具有可行性。
猜你喜欢
吉林电力(2022年1期)2022-11-10
医学食疗与健康(2022年3期)2022-04-23
能源工程(2021年6期)2022-01-06
健康体检与管理(2021年6期)2021-11-17
少儿画王(3-6岁)(2020年4期)2020-09-13
科技与创新(2018年2期)2018-11-30
东方教育(2018年20期)2018-08-22
家教世界·创新阅读(2016年11期)2016-12-27
故事会(2016年15期)2016-08-23
中国化工贸易(2012年9期)2012-11-29
