
基于SystemC参考模型的UVM验证平台设计
2021-08-02 03:35汪永峰
计算机技术与发展 2021年7期
汪永峰,卜 刚
(南京航空航天大学 电子信息工程学院,江苏 南京 211106)
0 引 言
当下芯片验证技术已经逐渐跟不上芯片设计的步伐,在完整的芯片研发过程中,芯片验证往往要占据整个芯片研发周期的70%以上[1]。可见,在不降低验证要求的情况下,缩短验证时间可以有效地缩短芯片研发周期,加快芯片上市时间。
该文旨在以超高频(ultra high frequency,UHF)射频识别(radio frequency identification,RFID)数字基带处理单元中读写器发送链路为例,设计一款可复用的验证平台。由于SystemC语言可以用来搭建事务级、高抽象级的虚拟原型,并且其与SystemVerilog语言均支持事务级建模(transaction level models,TLM)通信机制,这为SystemC和UVM之间的通信提供了可能[2]。这里选用SystemC建模作为参考模型接入UVM验证平台,将参考模型的输出和寄存器传输级(register transformation level,RTL)设计的输出进行比对。SystemC语言更注重算法级的设计,与更偏向于物理级的RTL相比拥有更快的仿真速度。并且将具有可重用、激励随机化等优点的UVM与SystemC语言结合起来,不仅提高了验证的全面性,还缩短了验证所需要花费的时间。
1 UVM的优势
通用验证方法学(university verification methodology,UVM)是一个以SystemVerilog类库为主体的验证平台开发框架,为验证人员提供了一系列通用验证组件(university verification component,UVC),例如uvm_driver、uvm_monitor、uvm_agent等[3]。总的来说,UVM之所以能够得到广大验证人员的青睐,是由于UVM验证方法学相比于其他的验证方法包含以下几点优势:
(1)UVM拥有自己的基类库,验证工程师可以利用继承功能复用这些通用验证组件来构建需要的验证环境,为验证平台的搭建提供了便利,缩短了搭建验证平台所需要的时间[4]。
(2)UVM搭建出来的验证平台具有特有的结构,使得整个平台层次清晰,代码可读性大大增加,也省去了工程师自己构建验证结构的时间[5]。
(3)UVM拥用属于自己的运行机制,通过phase机制使得仿真阶段也变得层次化,不仅仅指的是不同phase之间的层次顺序,也包含了不同组件中相同phase的层次化关系[6]。
(4)UVM拥有独特的传输机制。TLM通信机制增强了UVM各个组件之间的独立性,其端口种类繁多,为满足不同的通信需求提供了基础。同时由于SystemC同样支持TLM通信,这为UVM与System C之间的通信提供了基础[7]。
(5)UVM拥有自己独特的重载和覆盖机制,极大地提高了代码的可重用性。
2 待测设计介绍
本次待测设计采用由Verilog编写的UHF_RFID数字基带处理单元中的读写器发送链路。该设计从ISO/IEC 18000-6C协议标准出发,实现了读写器处理并发送,标签接收并处理的功能。如图1所示,阅读器发送侧主要由七个模块构成,分别为时钟模块、计数模块、并串转换模块、CRC校验码生成模块、异步FIFO模块、PIE编码模块以及同步码添加模块。发送数据时,首先需要通过计数模块计算发送数据位数并判断数据类型,为并串转换及数据编码做准备,接着将并行数据转换成串行数据,传递到CRC校验码生成模块,生成数据的循环冗余校验(cyclic redundancy check,CRC)码添加在数据尾部。根据数据类型的不同,阅读器发送模块的CRC校验分为CRC5和CRC16两种类型,当发送数据为Query命令类型时,进行CRC5校验,其他类型则进行CRC16校验。之后再将数据送入异步FIFO进行缓存,接着对FIFO读出的数据进行PIE编码,最后为其添加同步码发送给标签[8]。

图1 待测设计电路模型
而标签接收侧主要由四个模块构成,分别为同步码检测模块、PIE解码模块、CRC检验码检测模块以及串并转换模块。标签接收侧完成的功能则和读写器发送侧功能相反,数据首先通过同步码检测模块,确定数据的位置并提取紧接在同步码之后的正确数据,随后将接收到的数据传递到PIE解码模块进行PIE解码操作,将解码后的数据按照接收数据命令类型的不同,分别进行CRC5和CRC16校验,校验成功后将串行数据恢复成并行数据。
2.1 编码模块设计
协议规定读写器发送链路的编码方式为脉冲宽度编码(pulse interval encoding,PIE)。通过定义数据-0和数据-1编码后不同的码元长度来实现,PIE编码方式如图2所示,编码后0或1码元的长度主要取决于Tari和PW两个参数。读写器对标签发信的基准时间间隔为Tari,为一个0码元持续的时间。这个值可以根据实际情况适当修改,最佳读写器对标签Tari值如表1所示。PW的参数可以在0到Tari之间选取。从图上可以看出码元1的长度为Tari+x,x的取值范围为0.5tari到tari。

图2 PIE编码

表1 最佳读写器对标签Tari值
为方便编码,在下面的设计和验证中,取x的值为Tari。因此,在PIE编码中,0码元被编码为“10”序列,而1码元被编码为“1110”序列。
在PIE编码模块开始工作之前,首先要判断CRC校验模块是否已经开始工作并将校验后的数据写入FIFO进行数据缓冲,根据FIFO中有效数据的状态决定是否进行编码操作,若FIFO已经写入超过一半数据,则PIE编码模块开始工作,从异步FIFO中读取数据并进行编码直到FIFO为空,表示已对全部数据进行编码。PIE编码算法流程如图3(1)所示。

图3 PIE编解码算法流程
2.2 解码模块设计
根据协议可知,在解码时,最重要的参数是RTcal,其值为一个数据-0与一个数据-1的长度之和。由于数据-0和数据-1均由高电平和低电平两个部分构成,当接收到的数据为有效数据时,采用频率高于码元速率的时钟分别对接收到数据的高低电平进行采样,得到数据a和数据b,并取RTcal值的一半为常量pivot,与a和b之和进行对比,若a与b的和小于pivot,则接收到的数据为数据-0,反之接收到的数据为数据-1[9]。PIE解码流程如图3(2)所示。
根据协议标准,在解码时,若接收到比4*RTcal长的符号为不良数据,因此在解码时,a与b还需满足下列两个条件:
(1)a+b<4*RTcal,即a+b<8*pivot
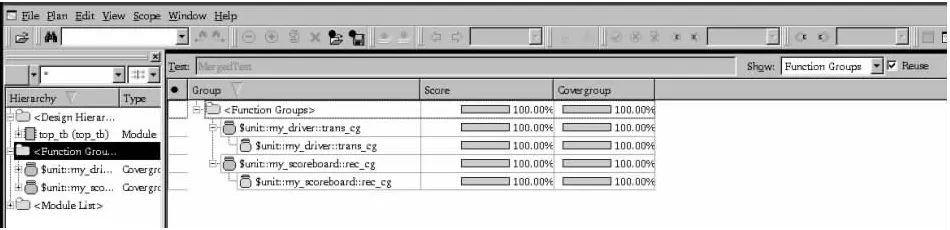
(2)0.625*Tari SystemC和UVM验证平台的搭建,其实现基础是UVM Connect(UVMC)通信包,这个包集成了已有的SystemC和UVM的TLM通信标准,使得UVM和SystemC之间TLM模型可以方便地实现通信并且不需要修改原本已有的代码,降低了SC和UVM的TLM模型复用的难度。原有的TLM模型不再需要继承其他的基类,而是通过外部代理的模式解决了这一问题,同时UVM一侧的transaction类并不要求在factory中注册,减少了对factory机制的依赖。SV和SC两侧的transaction类并不要求完全一致,数据在SV和SC之间可以由各自的converter函数完成数据转换,这样的方式进一步提高了原有TLM模型的复用性。 UVMC库不仅提供了SystemC和SystemVerilog模型与组件之间的TLM1.0和TLM2.0连接方法,它还将UVM命令API方法输出到SystemC一侧,用于从SystemC(C或C++)控制和访问UVM仿真[10],这些API主要有以下几个方面: (1)等待UVM到一个特定的仿真阶段。 (2)挂起或放下objection来控制UVM测试进程。 (3)通过UVM config_db设置或得到配置的对象。 (4)通过config_db覆盖类或实例的类型。 (5)打印UVM环境组件的拓扑结构。 对于SV和SC,在代码中分别利用UVMC库提供的类似的函数来完成相应的TLM port的注册,在本设计中的注册代码如下: SV TLM2: uvmc_tlm#(my_transaction)::connect(mdl.out,“reader2tag”); SC TLM2: uvmc_connect(cons.in,“reader2tag”); reader2tag是用来注册该端口的字符串,在使用这些函数时,UVMC会在SV和SC两侧都注册端口的句柄和名字(reader2tag),而在后期连接阶段,只要注册端口的名字匹配,UVMC就会将这两个端口连接起来,而并不关心它们是什么语言。 验证平台的结构框架如图4所示,该验证平台主要包含的组件及其对应的功能如下所示: 图4 验证平台结构 (1)interface:接口声明,主要包含读写器需要发送的数据和命令接口,用于实现待测设计(design under test,DUT)和testbench之间的通信[11]。 (2)transaction:产生组件之间通信最基本的数据包,本设计中包含读写器需要发送的命令和数据,由于需要预留8 bit用于储存data_size,因此在transaction内需要限制发送数据位宽不能超过120 bit,因此在transaction添加如下约束: constraint data_cons{ data_in[127:120]== 8'h0; } (3)sequence:用于产生transaction,可以控制transaction的数量,以及对transaction进行约束从而产生符合预期的激励等[12]。 (4)sequencer:用于将sequence产生的数据包传递给driver。 (5)driver:负责驱动transaction,将激励分别通过virtual interface和seq_item_port送到DUT和reference model,本设计在driver中定义了一个覆盖组,用于功能覆盖率的统计,主要包含对随机输入数据可能存在情况的覆盖,由于传输数据位宽较大,用随机的方法全部遍历不太方便,因此对数据范围进行了划分,设置各个范围的最低覆盖次数为1,并且对一些特殊情况、边界情况进行了覆盖,确保DUT在所有情况下都能完成正常的功能[13]。覆盖组定义代码如下: covergroup trans_cg; data_cov: coverpoint req.data_in{ bins all1={18'h3ffff}; bins special1={18'h15555}; bins special2={18'h2aaaa}; bins data_0={[0:18'h03fff]}; bins data_1={[18'h04000:18'h07fff]}; bins data_2={[18'h08000:18'h0bfff]}; …… } endgroup (6)monitor:本设计中包含两个monitor,一个从输入虚接口获取数据包,用于监测driver发送给DUT的数据包,确保读写器接收到的数据包正确无误,另一个从输出虚接口获取数据包,用于监测标签最终输出的数据包,并将其通过uvm_analysis_port传递给scoreboard进行数据比对。monitor关键代码如下: task my_monitor::main_phase(uvm_phase phase); while(1) begin tr=new("tr"); collect_one_pkt(tr); ap.write(tr); end endtask task my_monitor::collect_one_pkt(my_transaction tr); while(1) begin @(posedge vif.clk); if(vif.valid) break; end … while(vif.valid) begin tr.data_in=vif.data_in; @(posedge vif.clk); end … endtask (7)agent:将driver和monitor以及sequencer封装在一起,可以通过配置is_active和is_passive参数来选择是否使用driver和sequencer[14],并在connect_phase中建立driver和sequencer之间的连接。 (8)scoreboard:分别接收out_agent和reference model传递来的数据作为期望结果和实际结果,并在scoreboard中将期望结果和实际结果进行自动比对,若两者一致,则数据传输正确,打印“Compare SUCCESSFULLY”表示数据对比成功,若两者不一致,则数据传输错误,打印“Compare FAILED”表示数据对比失败,并分别打印出期望的结果和实际的结果以作对比。和driver类似,在scoreboard中也定义了一个覆盖组,用于对接收到的数据统计功能覆盖率。 (9)reference_model:该类在本设计中自身不对数据进行任何操作,仅用于和SystemC语言编写的真正参考模型进行数据通信以及控制与SystemC参考模型间的事务数量。UVM侧实现通信的关键代码如下: my_transaction pkt=new(); delay.set_abstime(3,1e-4); port.get(pkt); pkt.print(); out.b_transport(pkt,delay); pkt.print(); ap.write(pkt); (10)env:封装in_agent、out_agent、scoreboard、reference_model并将它们在connect_phase中进行连接,实现组件之间的数据通信。 (11)testbench:例化env,启动sequence。 (12)top:连接testbench和DUT,运用config机制配置顶层接口连接,启动testcase。 (13)DUT:由Verilog语言编写的UHF_RFID数字基带处理单元读写器发送链路设计,根据testbench送来的激励产生相应的输出结果,并送往scoreboard做比对[15]。 (14)SC Ref Model:由SystemC编写的UHF_RFID数字基带处理单元读写器发送链路模型,由UVM Connect包将其接入testbench,根据testbench送来的激励产生标准的输出结果,并送往scoreboard做比对。SC侧实现数据通信的关键代码如下: virtual void b_transport(T& t, sc_core::sc_time& delay) { cout << sc_time_stamp() << " SC consumer executing packet:" << endl << " " << t << endl; data_in=t.data_in; cnt_en=1; wait(40,SC_NS); cnt_en=0; wait(s2p_done.posedge_event()); t.data_in=data_out; cout << sc_time_stamp() << " SC consumer packet executed:" << endl << " " << t << endl; delay=SC_ZERO_TIME; } 本设计使用synopsys公司的VCS软件进行最后的仿真验证,查看波形和计分板的打印输出来判断DUT的功能实现情况,并根据代码覆盖率和功能覆盖率来判断验证的完整性。 图5为发送50个随机数据产生的DUT顶层波形图。在图中随机选取一时间点分析数据,如图所示,选取时间为82418316451ns,在此时间点读写器发送数据data_in为128’h008d_7334_626e_67ad_60db_4cb6_d1d3_536f,标签接收到数据寄存在rx_buf中,可见接收到的数据为128’h8d73_3462_6e67_ad60_db4c_b6d1_d35d_6f78,接收数据末八位8’h78指的是发送数据长度,换算成10进制为120,其余位为发送数据,经对比数据及数据长度与实际发送数据一致,DUT功能正确。 图5 仿真波形 任意截取一个数据包的仿真对比结果报告如图6所示。图中expect pkt是由SC参考模型输出的数据,其数值为128’he005_30e2_8907_2fa5_7f0a_0e90_f420_4078,actual pkt是由输出数据monitor监测DUT标签接收模块输出最终传递到scoreboard的数据,其数值为128’h e005_30e2_8907_2fa5_7f0a_0e90_f420_4078,可见DUT得到的数据和参考模型相同。经过scoreboard自动比对,最终通过并在报告中打印Compare SUCCESSFULLY,DUT功能正确。 图6 仿真报告 仿真的代码覆盖率如图7所示,可以看出DUT各个模块的行(Line)覆盖率、状态机(FSM)覆盖率、分支(Branch)覆盖率均达到100%,满足验证要求。 图7 代码覆盖率 图8为仿真的整体功能覆盖率图,功能覆盖率达到100%,在该验证环境中共包含两个覆盖组,分别是发送数据功能覆盖组trans_cg和接收数据功能覆盖组rcv_cg。由于发送数据位宽较大,覆盖所有可能的数据比较困难,所以在覆盖组中,对数据的范围进行了划分,共分为16个仓,并添加特殊数据情况下的覆盖,16个仓以及特殊数据均被覆盖,覆盖率达到100%。功能覆盖组rsv_cg中共包含三个覆盖点,覆盖点均被覆盖,覆盖率达到100%,满足了功能验证要求。 图8 功能覆盖率 随着芯片产业的快速发展,打造越来越多的中国芯是历史的必然选择,其中芯片验证的作用不可忽视。该文提出了一种基于SystemC和UVM的验证平台设计方法,实现了SystemC和SystemVerilog之间的联合仿真。选用高层次的System C语言进行建模,建模时间短,仿真速度快,虽然前期搭建验证平台可能需要耗费的时间较长,但相对于整个验证周期,无疑极大地缩短了验证时间,提高了验证效率。设计的复杂程度越高,就越能看出该文提出的验证平台设计方法所带来的便利。3 验证平台设计
3.1 实现基础
3.2 验证组件设计

4 仿真结果



5 结束语
猜你喜欢
今日农业(2022年15期)2022-09-20
计算机与数字工程(2022年3期)2022-04-07
物联网技术(2018年8期)2018-12-06
价值工程(2018年3期)2018-01-23
中国新通信(2016年2期)2016-03-11
物联网技术(2015年10期)2015-11-10
物联网技术(2015年2期)2015-04-07
物联网技术(2015年3期)2015-03-31
意林(2010年13期)2010-05-14
现代电子技术(2009年6期)2009-05-31
