
基于数据平衡和深度学习的开心果品质视觉检测方法
2021-07-30 01:38高霁月倪建功杨昊岩韩仲志
农业机械学报 2021年7期
高霁月 倪建功 杨昊岩 韩仲志
(青岛农业大学理学与信息科学学院, 青岛 266109)
0 引言
开心果味香、营养丰富,具有很高的经济价值,但其果壳坚硬,人工难以将开口过小或者不开口的开心果剥开,开口与否直接关系到开心果的品质、经济价值和消费者对品牌的评价。开心果果壳的开口率低、表面褐斑、果壳畸形和混入杂物(如石子、树枝)等现象会大大降低开心果产品的品质,所以在产品上架前对开心果进行开口检测非常必要。理想的果壳开口程度是消费者能用手指轻易取出核仁,因此未开裂的开心果需要在产品上架前分拣出来,加工出理想的开口[1]。
目前,对开心果开口品质的检测绝大多数是通过声音判断[2-5]。钟晨玉等[4]设计了开心果碰撞声分拣试验装置,分析传声器位置、开心果下落高度及碰撞块倾斜角对碰撞声特征的影响;臧富瑶等[5]根据开心果撞击大理石的声音信息,测得开心果闭口、半开口、开口3种声音状态,获得80个不同样本开心果的碰撞声信号,经处理得到信号的时域和频域图形,从中提取分拣特征。郭晓伟[6]通过开心果的质心位置以及两条辅助线,开壳果正确分类率为93%,但此研究只检测了开口和闭口,并未提及褐斑、杂质、畸形等其他缺陷。
为验证图像检测农产品品质的可行性,韩仲志等[7]测量每个花生籽粒外观图像的形态、纹理、颜色共3大类54个特征,采用主分量分析(PCA)进行特征优化,然后导入神经网络(ANN)和支持向量机(SVM)模型进行比较,最终能够鉴别95%以上的不完善粒、霉变、杂质、异品种等不同品质的籽粒。近年来,图像处理技术已广泛应用于农产品品质检测中,特别是深度学习算法出现后,品质识别不需要人为定义特征,深度学习的简便性和准确性使其在图像检测领域得以快速发展。卷积神经网络(Convolutional neural network,CNN)是一类包含卷积计算且具有深度结构的前馈神经网络,是深度学习的代表算法之一,其设计灵感来自生物体的自然视觉感知机制,可以自动提取最具有代表性的图像特征[8-9]。图像分类是计算机视觉领域中的基本任务, 通常指将图像分类到几个预定义的类中,构成其他计算机视觉任务的基础[10]。卷积神经网络在图像分类和目标检测领域应用广泛[11-12],农业图像检测也越来越多运用了卷积神经网络的方法[13-17]。
基于深度学习的图像识别技术在理论上能更精确地识别开口程度和杂物,并进一步定位到开心果的位置,配合喷气装置可以精准挑拣出开口不合格和外观缺陷的开心果。然而,网络模型训练时数据量的平衡性会影响训练模型的性能,且数据不平衡现象经常发生[18-19]。传统分类方法通常假设数据类别分布均衡,但由于多数类和少数类在数量上的倾斜,以总体分类精度最大为目标,会使分类模型偏向于多数类而忽略少数类,从而造成少数类的分类精度较低[20]。同样在使用神经网络分类时,训练网络所用的数据集样本不均衡会影响神经网络的分类效率和准确率。针对上述问题,本文提出一种数据自动平衡检测方法,并采用6种不同的深度网络探究数据平衡算法对分类准确率的影响。
1 材料与方法
1.1 开心果图像数据库构建
按照中国食品工业协会坚果炒货专业委员会发布的《生干坚果质量等级要求》,将数据集分为3类:开口、闭口和外观缺陷及杂物(以下简称缺陷),其中开口标准为开口程度不小于2 mm×6 mm的开心果,闭口的标准为开口小于2 mm×6 mm的开心果,缺陷包括果壳表面褐斑以及混入杂物。
图1为开心果的图像采集环境,其中包括:摄像头及支架、光源、黑色背景板、开心果以及计算机。图像采集流程为:首先将市场上购买的未漂白开心果平铺于黑色背景板之上,固定摄像头位置和光源;然后通过摄像头拍摄开心果图像;最后导入计算机进行分类训练。图2是开心果感兴趣区域提取流程,图2a为原始图像,通过二值处理、膨胀、阈值分割得到图2b,然后设定连通区域面积,框选开心果轮廓得到图2c,再将红框坐标对应到原始图像对单个籽粒进行裁剪,最终得到单粒开心果的数据集。
图3为不同类型开心果示例图,经过数据预处理后,获得单粒开心果图像,包含开口图像1 331幅,闭口图像415幅,缺陷图像92幅,共1 838幅图像,各类数据数量相差很大,各个分类之间的数据量极不平衡,需要设计数据集平衡方法。
1.2 数据自动平衡算法
针对上述数据不平衡的问题,本文提出一种数据自动平衡的算法,目的是在数据导入网络分类模型之前将训练集数据集类别数量进行平衡,提高网络的准确率。基本流程为先获得每个分类的原始数量,再依次将所有数值小的分类集向数值最大的分类集数量扩增,具体方法为:
(1)输入:数据集S=[M1,M2,…,Mi][N1,N2,…,Nj]T,输入中的Mi为数据集中样本种类,Nj为每一类样本的数量。
(2)比较数据集中每一类的最大值MiNj,找到所有类中最大值MiNjmax。
(3)用所得最大值MiNjmax依次除以剩余类的最大值MiNj,得到除数C=[{c1,c2,…,ci-1}]。
(4)按照除数C对剩余类进行扩增,得MiN′j=MiNjC,使所有类数量向MiNjmax靠拢。
(5)输出:得到扩增后的数据集T=[M1,M2,…,Mi][N′1,N′2,…,N′jmax]T。
以此开心果数据集为例,原始数据中开口图像1 331幅,闭口图像415幅,缺陷图像92幅,共1 838幅图像,取出最大值1 331,将闭口组的数量与最大值1 331相除,除数向下取整,最大值为12(超过12的值按照12运算)。将闭口的415幅图像旋转3次得到1 245幅图像,缺陷组也与最大值1 331相除得到数值14,但是为了方便旋转,最大扩增值只能为12,通过12次旋转将缺陷扩增为1 104幅图像,合格的开口开心果原始图像保持1 331幅不变,至此,平衡后的图像共3 680幅。
所用的2组数据集的来源为:将1.1节中获得的未经过数据平衡的1 838幅图像通过保留原图、7次旋转、水平镜像和垂直镜像,扩充为原先的10倍,得到18 380幅图像,形成未平衡数据集A。平衡数据集B的构成是将以上所述的3 680幅图像扩增至原来的5倍,扩增方法包括原图、水平镜像、垂直镜像、尺寸缩小至原图3/5以及尺寸扩张为原图的1.4倍,数据集B共包含18 400幅开心果图像,A、B2个数据集之间只相差20幅图像,但在各组分类数量的比例上差别很大,A组开口、闭口和缺陷的图像数比例约为100∶30∶7,而数据平衡后的B组接近于1∶1∶1。
1.3 分类模型
表1为实验所用6种网络,其中SqueezeNet和ShuffleNet为轻量型网络,各个网络之间存在一定的差异性,使用数据平衡算法对不同神经网络的稳定性进行了验证。

表1 实验所用6种网络
2 实验与结果分析
2.1 数据平衡对模型准确率的影响
神经网络选取AlexNet、GoogLeNet、ResNet50、SqueezeNet、ShuffleNet和Xception训练网络进行迁移学习。将数据集按照70∶15∶15的比例随机划分为训练集、验证集和测试集。其中,训练集和验证集用于网络模型的训练,测试集数据未用于网络模型训练,而是用来测试网络的准确率。
表2是未平衡数据集A和平衡数据集B的分类准确率,分别记录了AlexNet、GoogLeNet、ResNet50、SqueezeNet、ShuffleNet和Xception这6种网络在验证集、测试集的准确率以及网络训练时间。
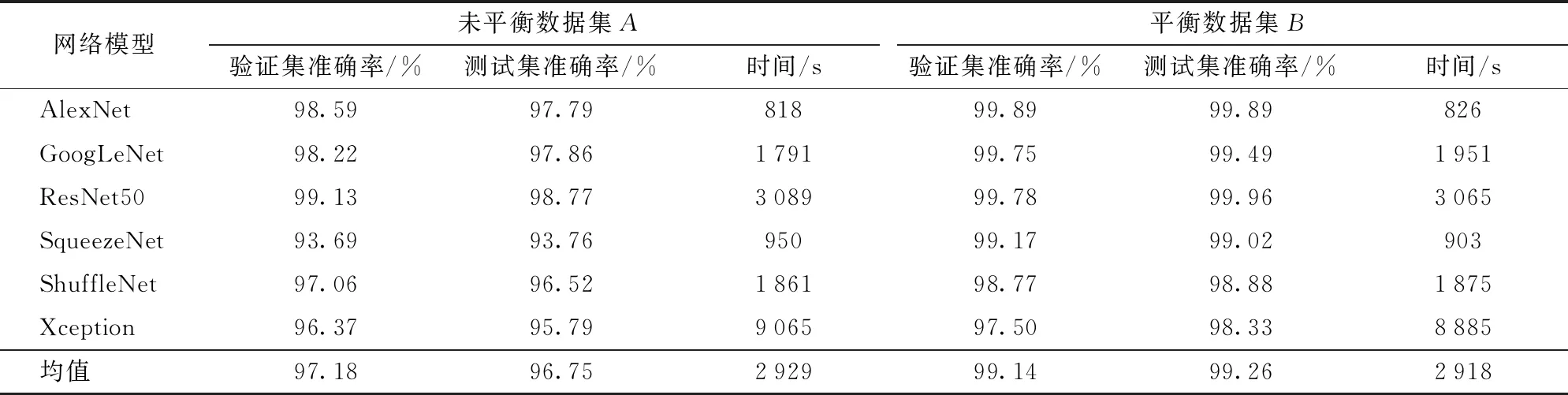
表2 未平衡数据集A和平衡数据集B的分类准确率
对于未平衡数据集A, ResNet50网络的分类效果最好,验证集准确率最高达到99.13%,在测试集上也达到98.77%;SqueezeNet在验证集的准确率为93.69%,测试集准确率为93.76%,在6种网络中准确率最低。除SqueezeNet之外,其他网络验证集的准确率均在96%之上,6种网络验证集平均准确率为97.18%,测试集平均准确率为96.75%。AlexNet在未平衡数据的验证集上,准确率高于SqueezeNet 4.9个百分点,在测试集上AlexNet准确率也比SqueezeNet高4.03个百分点。AlexNet、ResNet50和GoogLeNet在未平衡数据集A上性能优越,而SqueezeNet、ShuffleNet和Xception网络分类准确率可以接受但相对较差。从训练时间来看,AlexNet与SqueezeNet用时最短约15 min,Xception运行时间最长,为151 min,因此如果想用最少的训练时间得到一个性能高的网络,AlexNet最佳。
经过平衡的数据集B在每个网络上的验证集和测试集的准确率都有提升,而且对原先分类效果欠佳的网络准确率提升非常明显。平衡数据集B的验证集的平均准确率为99.14%,测试集的平均准确率为99.26%,验证和测试准确率均高于99%。在未平衡数据集中分类效果欠佳的SqueezeNet网络准确率提升最明显,其验证集准确率由93.69%提升到了99.17%,测试集的准确率从93.76%提升至99.02%。相对于数据集A,数据集B的测试集平均准确率提高了2.51个百分点,验证集平均准确率提高了1.96个百分点, AlexNet、ResNet50和GoogLeNet这3种网络在验证集和测试集上的准确率接近1,SqueezeNet、ShuffleNet和Xception的验证集准确率都在98%以上,明显优于未平衡前的准确率。数据集A和B的训练时间在同一网络下无明显差异,训练时间与网络模型的结构、参数量以及训练数据量有关。
2.2 数据平衡前后的混淆矩阵
数据平衡前后测试集的混淆矩阵如表3和表4所示,表3展示了未平衡数据集A的开口、闭口以及缺陷图像在测试集的预测结果,数据集A的测试集共有2 756幅图像,其中标记为开口的图像1 996幅,闭口图像622幅、缺陷图像138幅。从表3中可以看出GoogLeNet和SqueezeNet网络的主要错误是将开口预测为缺陷,这是因为开口图像中有的果壳表面有面积较小的褐斑,神经网络会误将其归类为外表缺陷。和前者相反,AlexNet、ResNet50、ShuffleNet和Xception网络的主要错误之一是将缺陷预测为开口,说明ShuffleNet和Xception网络在分类时,对开口特征的权重大于缺陷特征的权重。在所有网络中将闭口预测为开口也是一种常见错误预测,这是因为有的闭口开心果开口接近开口标准2 mm×6 mm,而各组分类数据不平衡,网络无法学习足够多的闭口训练样本实现精确分类。
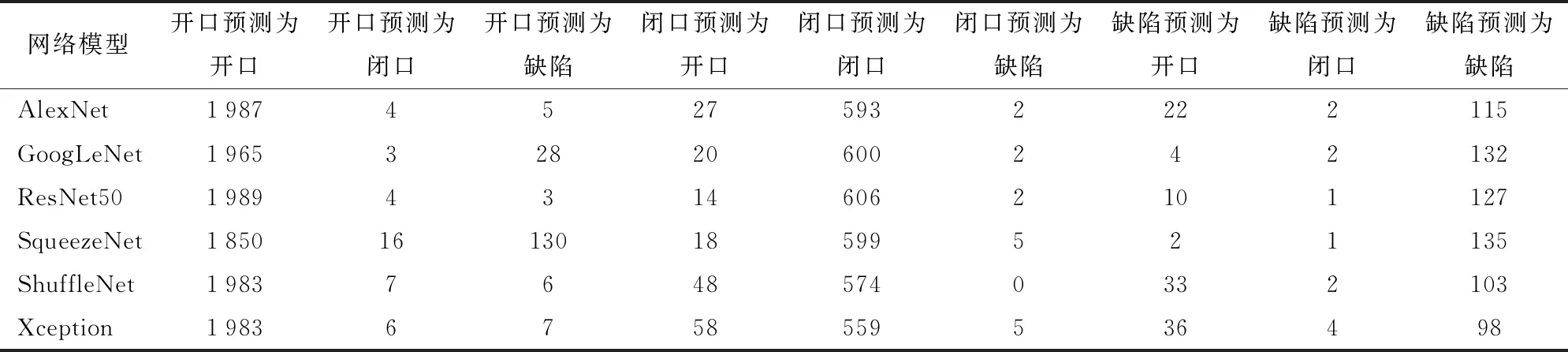
表3 未平衡数据集A对于开口、闭口以及缺陷图像在测试集的预测结果
表4为平衡数据集B的开口、闭口以及缺陷图像在测试集上的预测结果,数据集B中共有2 760幅测试图像,其中标记为开口的图像共998幅,闭口图像934幅、缺陷图像828幅。从表现结果来看,使用ResNet50分类后的开心果其网络准确率最高,达到了99.9%, ResNet50网络在这2 760幅图像中只将1个开口图像错误分类为闭口,这就最大程度保证了开心果的品质,减少开心果分类时误判造成的浪费。SqueezeNet与GoogLeNet相比,分类效果较差,分别有12个和10个缺陷开心果分类为开口开心果。ShuffleNet和Xception是准确率最低的2种网络,与其他网络相比,分类错误的情况较为明显。
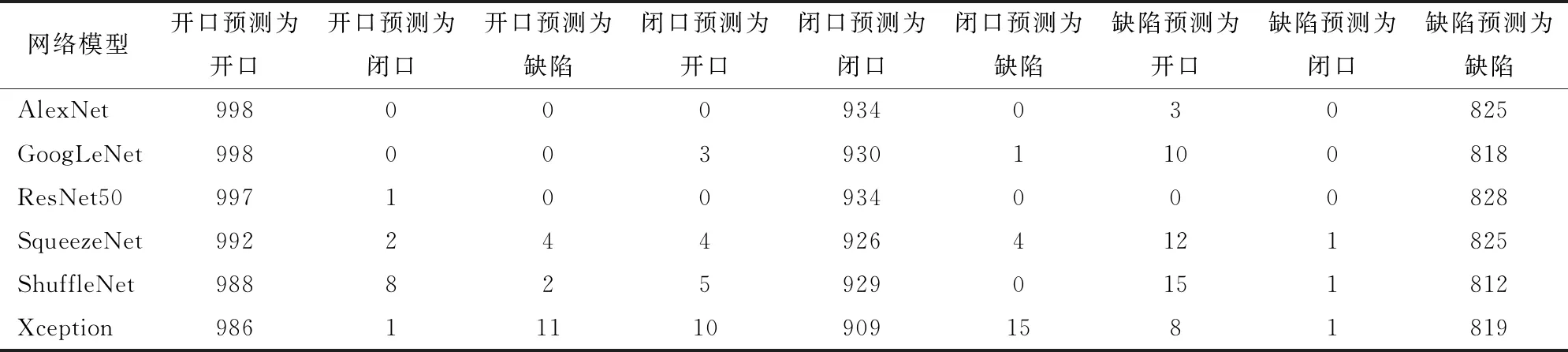
表4 平衡数据集B对于开口、闭口以及缺陷图像在测试集的预测结果
2.3 数据可视化
图4是利用Grad-CAM算法将网络判断模型可视化,Grad-CAM(类激活热力图)将最后一层特征图所有像素的权值计算,最后按照每个像素的权值可视化[27],在本实验中,最后输出的特征图分辨率不一定与输入图像一致,无论输入图像的尺寸大小,所有经过Grad-CAM算法后的特征图都统一尺寸。特征图中红色表示神经网络判定开心果类别的高权重区域,蓝色表示网络分类低权重的区域,色彩越红表示这块区域对分类结果的影响越大。可以看出,网络在分类为开口时的重要部位在开口处及周围,分类为闭口图像时会找到大面积的白色果壳区域,分类为缺陷和异物时网络的关注点在于检测目标物的形状、畸形区域或者是褐斑的位置。
3 结论
(1)数据平衡方法可以提高网络准确率,其平均测试准确率提高了2.51个百分点,平均验证准确率提高了1.96个百分点,其中SqueezeNet网络提高幅度最大,分别提高了5.26个百分点和5.48个百分点。
(2)神经网络可适用于开心果品质检测分类,本实验6种网络平均测试准确率为99.26%,平均验证准确率为99.14%,其中ResNet50的测试准确率达到99.96%,可作为开心果检测分类的首选网络。
(3)可视化网络分类高权重的区域与人工判别开心果所关注的区域基本一致,从而验证了网络分类的合理性。
猜你喜欢
山花(2020年6期)2020-06-19
小读者(2020年4期)2020-06-16
科技视界(2019年10期)2019-09-02
VOGUE服饰与美容(2018年11期)2018-05-14
中老年健康(2017年9期)2017-12-13
科技创新导报(2016年9期)2016-05-14
读者·校园版(2015年3期)2015-05-14
意林(2009年12期)2009-02-11
今日中学生(初三版)(2006年2期)2006-02-20
