
基于部分加权损失函数的RefineDet
2021-07-30 10:33:20肖振远王逸涵罗建桥李柏林
计算机应用 2021年7期
肖振远,王逸涵,罗建桥,熊 鹰,李柏林
(西南交通大学机械工程学院,成都 610031)
0 引言
目标检测作为计算机视觉研究的热点,在图像识别和目标追踪等领域得到了广泛的应用。近年来随着卷积神经网络(Convolutional Neural Network,CNN)的发展,涌现出了诸多优秀的目标检测网络算法:基于锚框的检测算法[1-5]和基于无锚框的检测算法[6,7]。基于锚框的算法又可分为基于两阶的目标检测算法(如区域卷积网络(Regions with Convolutional Neural Network,R-CNN)[1]、快速区域卷积神经网络(Faster Regions with Convolutional Neural Network,Faster-RCNN)[2]等)和基于一阶的目标检测性算法(如单阶多框检测器(Single Shot multibox Detector,SSD)[3]、单阶改进目标检测器(Single-Shot Refinement Neural Network for Object Detection,RefineDet)[4]以 及YOLOv3(You Only Look Once version 3)[5]等)。基于无锚框的算法又可分为基于角点的目标检测算法[6]和基于中心点的目标检测算法[7]。在模型训练过程中,这些目标检测算法通常会遇到一个共同的问题:类间样本不平衡[8]。类间样本不平衡即某些类别样本数目远大于其他类别的情况,包括前景和背景间的不平衡以及前景类间样本不平衡。不平衡问题如不解决,会导致检测器对小类样本检测准确度低下,最终降低模型的性能。
针对类间样本的不平衡问题,许多学者进行了研究[9-16]。在基于锚框的检测器中,两阶检测器通常利用二阶级联和启发式抽样方法来解决类间样本不平衡:在第一阶段通过生成特定候选目标的方式过滤大量冗余的背景样本,如学习分割候选目标[9,10]、选择性搜索[11]、基于边缘的目标建议[12]等;在第二阶段采用启发式抽样方法平衡前景和背景之间的样本数量,如固定前景和背景的比例1∶3[3]、在线难样本挖掘[13]等;单阶检测器通常采用启发式抽样或难样本挖掘[14]方法从稠密的锚框中有规律地进行抽样,以平衡前景和背景之间的样本数量。以上方法有效缓解了前景和背景之间类的不平衡,但未考虑前景类间的不平衡问题。此外,焦点损失(Focal Loss)[15]对单阶检测器中的交叉熵损失函数进行改进,通过控制正负样本的权重和难易样本的权重,增大难学习的小类样本在损失函数中所占比重,使算法更偏重难学习的小类样本;但它并未考虑背景样本的影响。基于无锚框的检测器的检测准确率高于基于锚框的检测器,主要原因在于学习过程中产生了与基于锚框检测器不同的类间样本数量。自适应样本选择方法(Adaptive Training Sample Selection,ATSS)[16]对基于锚框的检测器和基于无锚框的检测器进行了详细的分析,通过对样本进行统计,自适应选择正负样本,控制类间样本数量,有效缓解了类间样本的不平衡,缩小了无锚框的检测器和有锚框的检测器的性能差异。总之,上述解决不平衡问题的方法,只考虑了前景类与背景类间的不平衡或者前景类间的不平衡,并没有综合考虑前景类与背景类不平衡和前景类间样本不平衡。
目前流行的目标检测网络一般采用分类损失和位置/尺寸回归损失来完成多任务学习(如Faset-RCNN、SSD)。RefineDet 沿用了经典的分类和回归损失,是一种有代表性的目标检测方法,而且它在性能上超过了大部分其他目标检测方法[1-5],具有先进性;但RefineDet 在使用损失函数进行权重更新时,存在上述提到的前景类与背景类不平衡和前景类间样本不平衡问题,并且由于是多任务学习,RefineDet 还存在多任务间的不平衡(分类任务和回归任务间的不平衡)[17]。因此,RefineDet的性能仍然具有提升的潜力。
本文针对RefineDet 损失函数,提出了一种改进的部分加权损失函数(Subsection Weighted Loss,SWLoss),以缓解类间不平衡数据集中小样本类别检测性能低的问题,它的主要组成如图1所示。
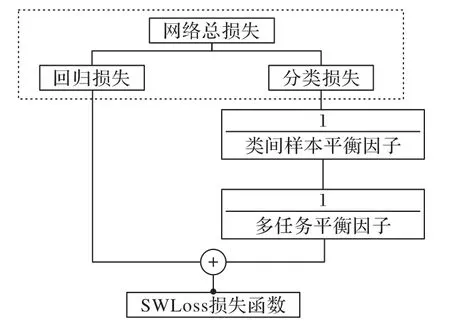
图1 SWLoss组成Fig.1 Composition of SWLoss
SWLoss主要有以下内容:1)在RefineDet目标检测损失函数中引入类间样本平衡因子,并以每个训练批量中不同类别样本数量的倒数作为启发式的平衡因子,对分类损失中的不同类别进行加权,从而提高对小样本类别学习的关注程度;2)在分类损失和回归损失中引入多任务平衡因子,对分类损失进行加权量化,缩小两个任务学习速率的差异。
1 RefineDet
RefineDet 在训练时,损失函数主要由三个模块构成:1)锚框调整模块(Anchor Refinement Module,ARM),将最初生成的锚框分为前景和背景,并对锚框的位置进行粗略的调整;2)目标检测模块(Object Detection Module,ODM),对ARM 模块粗调后的锚框进行多分类,并对锚框的位置进行精确的调整;3)连接模块(Transfer Connection Block,TCB),将ARM 模块输出的特征图进行特征金字塔(Feature Pyramid Network,FPN)[18]操作,变换成ODM 需要的特征图。其中ARM 和ODM提供了整个模型权重更新所需的损失。RefineDet 进行了两次分类和回归调整,在训练时采用难样本挖掘策略使得前景-背景不平衡问题得到了改善,同时兼顾了两阶检测器的准确率和一阶检测器的速率,因此在目标检测任务中获得了较高的检测性能。
RefineDet 损失函数Ltotal如式(1),主要由两部分构成:1)锚框调整模块ARM 的损失Larm,包括前期二分类的损失Lb和先验框粗调整的损失Lr,如式(2);2)目标检测模块ODM 的损失Lodm,包括多分类损失Lm和准确回归目标位置的损失Lr,如式(3)。
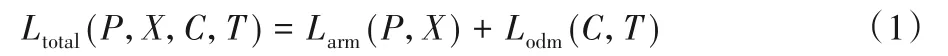
其中:P为锚框i在ARM 中对应的预测置信度,P={pi|i∈锚框索引值};X为锚框i在ARM 中粗调后的位置信息X={xi|i∈锚框索引值};C为锚框i在ODM 中对应的预测置信度,C={ci|i∈锚框索引值};T为锚框i在ODM 中精调后的位置信息,T={ti|i∈锚框索引值};Larm和Lodm如式(2)、(3)。
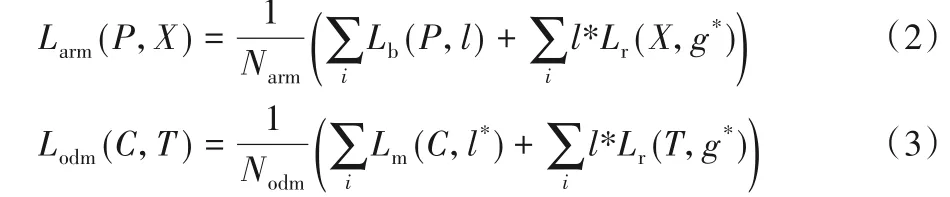
式中:i为锚框的标签索引;Narm为ARM 中对应的正样本的数量,Nodm为ODM 中对应的正样本的数量;Lb、Lm、Lr分别代表二分类损失、多分类损失和回归损失;l*i表示锚框i对应的真实框的类别标签,l*=;l为二分类损失对前景的编码值,l=或l=为锚框i对应的真实框的位置信息,g*=
尽管RefineDet 已经改善了前景和背景的类别不平衡,但它仍没有考虑前景类间样本的不平衡问题。在ODM 中,多分类损失是所有样本的平均损失,并以此来更新梯度,这种全局损失会使得样本数目越少的小类的关注度越低,进而导致网络模型对小类的检测准确率越低。此外,ODM 中存在着多任务不平衡问题,会导致分类任务与回归任务的权重更新速率不同,也会影响检测准确率。本文针对RefineDet 存在的上述缺陷,提出了部分加权损失函数SWLoss,以提高网络的检测性能。
2 部分加权损失函数SWLoss
在对模型训练时,由式(3)可以看出,在Lodm阶段,损失函数由分类损失Lcla和回归损失Lreg组成,如式(4):
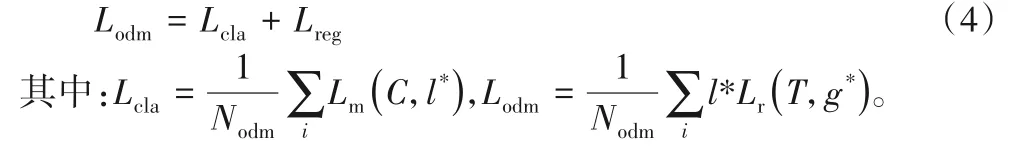
从式(4)中可得,分类损失是所有样本分类损失的平均值,在反向传播过程中,模型参数通过以下公式进行调整:
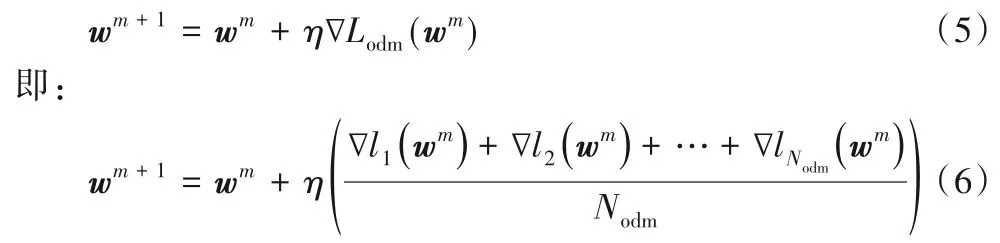
其中:η为学习率lNodm为第Nodm个样本的损失;wm是第m次更新的权重。
如式(4)所示,每个样本在权值调整过程中贡献相同,这会导致前景中样本数较大的类别在权值更新过程中占主导作用,从而使模型权重更新的速率偏向于该类,导致小类样本识别率降低。这种前景类间不平衡现象在工业检测应用中经常发生,例如缺陷检测[19],正常样本占绝大多数,而缺陷样本却非常少。
为缓解类间样本不平衡问题(前景类与背景类不平衡和前景类间样本不平衡),本文针对目标检测模块ODM 的损失Lodm提出一种部分加权损失函数SWLoss。SWLoss首先在Lodm中引入类间样本平衡因子,增加小类样本在损失函数中所占的比重,提高小类样本的检测效果,如式(7)所示:
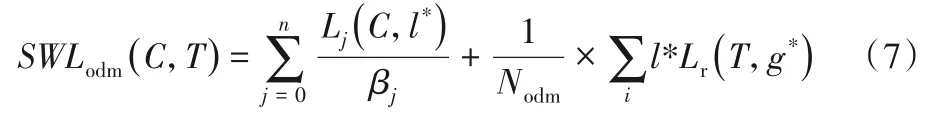
其中:n为每批量训练样本类别的总数;j为样本的类别,j=0时表示背景类;Lj对应每批量训练样本中每种类别的总样本损失;1/βj为第j类引入的类间样本平衡因子,是一个具有启发性的代表类间样本不平衡的值,βj为每批量训练样本中每种类别的样本数,即以每批量训练样本中每种类别的样本数作为各类的惩罚因子,其中背景类选为设置正负样本比例倍的平衡因子。如式(7)所示,总损失SWLoss 为每种类别损失的加权和,当βj选为每批量训练样本中每种类别j的样本数时,每种类别的损失相当于取该类的平均损失,间接使得小类总样本损失在总损失中所占比重增加,大类损失总样本损失在总损失中所占比重减少,从而平衡了类间样本不均衡的问题。
此外,Lodm误差函数并没有考虑多任务间的不平衡问题。不同任务之间的难度、损失大小各不相同,最优化损失函数时,不同任务之间的最佳区间不相容,会导致不同任务权重更新速率不同。为解决上述问题,SWLoss 引入多任务平衡因子对不同任务进行加权量化,使两者更新速率尽量同步。最终的损失函数SWLoss如式(8)所示:
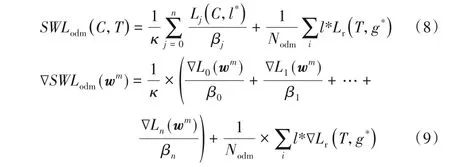
其中:κ为动态多任务平衡因子,决定着分类损失在整个损失的比重。如式(9)所示,κ越大意味着分类损失更新得越快,κ越小意味着分类损失更新得越慢。取κ=n,n为每批量训练样本类别的总数。
在反向传播中,SWLoss 的权重更新如式(9)所示。相比式(5)和(6)中∇Lodm(wm),由于每个类别的损失惩罚因子不同,使得每个类在权值调整过程中贡献不同,权重更新速率也会不同,也就意味着每个类拥有不同的学习率。因此,该损失保持了原始类间样本数量不平衡的同时,提高了网络对小类的关注度。此外,多任务平衡因子κ的引入,使分类和回归任务之间的更新速率变得可调节。
3 实验对比与分析
为分析SWLoss在不平衡数据集上的目标检测性能,在两个有代表性的数据集上进行实验,并与其他损失函数的目标检测效果进行对比。
3.1 实验设置
分别在公开数据集(Pattern Analysis,Statical Modeling and Computational Learning,Visual Object Classes Challenge 2007,Pascal VOC2007)和人工采集的包装盒点阵字符数据集上进行实验。VOC2007 数据集覆盖了20 个目标类别的9 963张图片。按9∶1 比例在VOC2007 上划分训练和测试集,具体数量信息如图2 所示,图中横坐标缩写了部分目标类别名称,包 括:Aerop(Aero Plane),Bicyc(Bicycle),DinT(Dining Table),Motor(Motor Bike),Potted(Potted Plant),TVmon(Tv Monitor)。图2中的直方图展示了训练集中各类目标的数量。可以看到,Person、Car 等类别的样本数量大幅超过Sheep、Chair 等类别的样本数量,因此,VOC2007 中不同目标的样本数量严重不平衡。点阵字符数据集记录了食品包装盒上的生产日期,包括12个目标类别,如图3所示的类别名称。为体现SWLoss 损失函数的适应性,在不同时间段分别收集训练和测试样本共500 张图片,9 000 个点阵字符。训练集来自时间跨度为2018-07-02T12:11:00—12:15:00 的200 张有效样本,训练集中的字符标注信息通过图像处理软件Halcon[20]自动获得。人工剔除标注不准确的失效样本后,训练集中各类字符数量如图3 所示。由于字符6 和9 仅出现在训练集时间跨度的秒单位上,因此图3 中字符6 和9 的数量相对其他字符较少,各类字符样本数量严重不平衡。测试集来自时间跨度为2018-07-02T13:55:00—13:59:59 的300 张有效样本,该时间跨度内字符6 和9 较多,因而可以验证网络对6 和9 的检测能力。同样,采用Halcon标注测试集字符,用于计算检测精度。
网络优化器采用随机梯度下降法,动量和权重衰减分别设置为0.9、0.000 5。以32批量在VOC2007上训练,前80 000次迭代学习率为10-3,后20 000 次学习率为10-4,最后20 000次学习率为10-5。由于点阵字符图像尺寸较大(1 296×966),以8批量在点阵字符上迭代训练7 500次,初始学习率为10-3,每迭代10次,学习率衰减0.05。
选用其他损失函数替换SWLoss 进行实验,对比方法包括:1)RefineDet中原有的损失函数,记为Loss0;2)按类别数量比例对输出概率进行加权的概率期望损失[21],记为PELoss;3)基于曲线下面积(Area Under Curves,AUC)优化的加权成对损失[22],记为WPLoss;4)同时考虑类间不平衡和难样本挖掘的Focal Loss,记为Floss。所有算法参数均采用对应文献中推荐的配置。
由于Focal Loss同时考虑类间不平衡和难样本挖掘,可采用SWLoss 损失函数中的类别不平衡因子1/βi替换Focal Loss中的类别系数。基于SWLoss的实验包括:1)本文提出的部分加权损失函数SWLoss,记为SWLoss1;2)忽略不平衡因子的损失函数,即κ=1 时,记为SWLoss0;3)Focal Loss 中的类别系数替换为1/β,记为SWLoss0+Floss;4)Focal Loss 中的类别系数替换为1/β,同时考虑不平衡因子,记为SWLoss1+Floss。
实验结果采用平均精度均值(mean Average Precision,mAP)进行评价,如式(13)所示,其中:TP(True Positives)为预测框与标签框正确的匹配;FP(False Positives)为预测框将背景预测为目标;FN(False Negatives)指需要模型检测出的物体,没有检测出;P(Precision)为测试精度;R(Recall)为召回率。
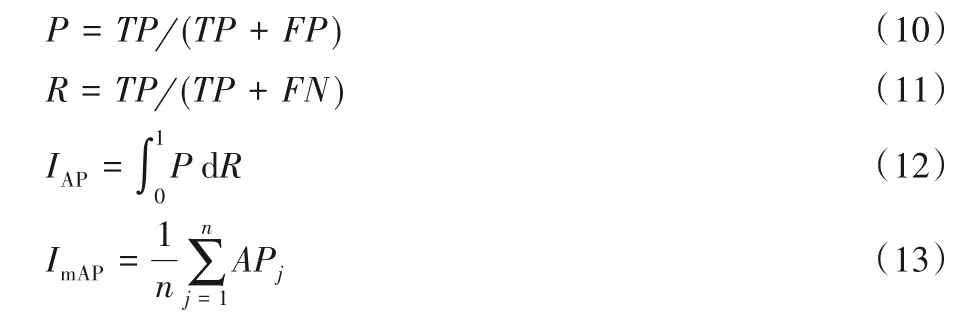
3.2 VOC2007对比实验
图2 对比了SWLoss 与RefineDet 原始损失Loss0 在VOC2007上的检测结果。由图2可知,相比原始损失函数,在SWLoss 损失函数中,样本严重不平衡的小类Sheep、Cow 的准确度得到了提升,大类Person的准确度略微下降,整体的准确度由表1 可知,提升了1.01 个百分点,原因是SWLoss 损失函数引入了类间样本平衡因子,增加了小类样本在整体损失函数中的权重,降低了大类样本的权重,从而在梯度更新中,使得小类样本的更新速度得到提升。这说明本文引入的类间样本平衡因子能够提高网络关注小类样本的能力,改善大类样本对小类样本权重更新的覆盖,缓解类间样本的不平衡。
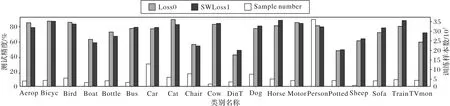
图2 VOC2007数据集上各类样本数量及测试精度Fig.2 Numbers and test accuracies of different classes of samples in VOC2007 dataset
表1还列出了SWLoss与其他对比方法的mAP。由表1可知:1)SWLoss0 明显超过Loss0,SWLoss1 进一步提高了性能,说明提升主要来自分类损失,平衡多任务能进一步提高性能。2)FLoss 超过SWLoss1,说明考虑难样本挖掘能够提高性能。3)Floss+SWLoss0 和Floss+SWLoss1 均超过Floss,原因是Focal loss 类别系数是全局类别比例,SWLoss 损失函数基于批量中的类别比例,能更准确保证每次更新时类间样本的平衡,因此SWLoss 损失函数在处理类间样本不平衡问题上超过Floss。4)SWLoss1 超过PEloss 和WPloss,原因是PEloss 通过加权系数直接调整输出概率,小类样本损失占比依然很小;WPloss 通过AUC 损失更多关注难分类样本,对小类样本的关注程度不足,而SWLoss损失函数直接提高小类样本损失的占比,因此SWLoss 损失函数在处理类别不平衡问题时具有优势。
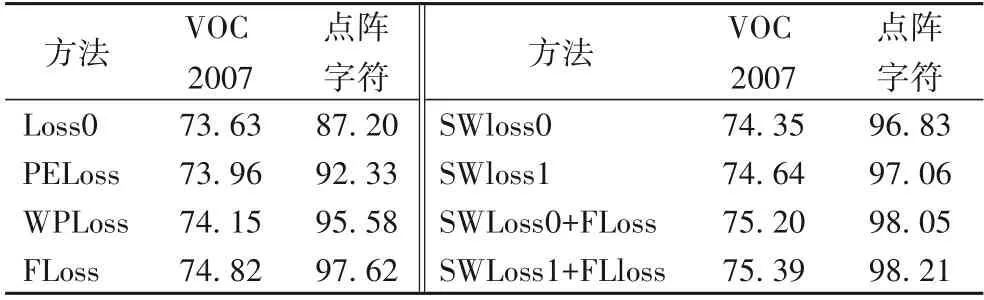
表1 采用不同损失函数时的mA 单位:%Tab.1 mAP when using different loss functions unit:%
3.3 点阵字符对比实验
图3 和表1 展示了包装盒点阵字符上的实验结果。由图3 可以看出:小样本字符类别6 和9 的精度大幅提高,原因是SWLoss 损失函数提高了6 和9 的损失在整体损失的占比,在梯度更新时使得网络权重的更新偏向于6和9的相关权重,因此对于该种存在较大不平衡的类间不平衡,SWLoss 损失函数的改善效果较明显。由表1 可以看出:点阵字符数据集的检测结果展现了与VOC2007 数据集类似的对比趋势,说明了SWLoss 损失函数对不同类间不平衡数据集的适应性。具体来说:首先,大幅提高了原始RefineDet 性能;然后,优于对比损失函数PEloss、WPLoss;最后,结合Focal Loss获得的最好结果,表明基于批量类别比例的有效性。
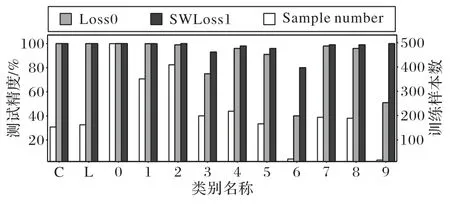
图3 点阵字符数据集上各类样本数量及测试精度Fig.3 Numbers and test accuracies of different classes of samples in dot-matrix character dataset
为直观分析所提算法效果,图4 展示了点阵字符上的检测效果。可以看到,原始网络RefineDet 在检测时产生了部分多余的检测框如图4(a)和(b),并且对数字6 和9 产生了误检和漏检现象;图4(c)和(d)为SWLoss损失函数的检测结果,它在获得高准确率的同时没有产生多余的检测框,且检测框的位置相对准确,这是由于SWLoss损失函数在对网络反向传播更新权重时引入了多任务平衡因子权重进行加权量化,缩小了分类任务和回归任务的差距。

图4 字符检测结果Fig.4 Character detection results
4 结语
本文针对RefineDet 目标检测网络对类间不平衡数据集检测时,存在小样本类别检测性能低的问题,提出SWLoss 损失函数。该损失函数在目标检测模块的损失函数中引入了类间样本平衡因子和多任务平衡因子,分别解决类间样本不平衡问题以及多任务间不平衡问题。实验表明SWLoss 损失函数有效地缓解了RefineDet 检测网络中的不平衡问题,能够明显提高小类样本的检测精度。
本文虽然关注了类间数据不平衡问题,但未考虑同类样本的数据变化,即如何区分简单样本和复杂样本。合理的损失函数应该更加侧重难分类的复杂样本,因此,今后将研究能够关注复杂样本的损失函数,进一步提高网络特征学习的鲁棒性。
猜你喜欢
信号处理(2022年11期)2022-12-26 13:22:06
计算机与生活(2022年11期)2022-11-15 16:17:48
计算机工程与科学(2022年8期)2022-08-20 01:39:22
中南民族大学学报(自然科学版)(2022年3期)2022-05-08 03:51:12
无线互联科技(2020年22期)2021-01-11 13:52:34
弹箭与制导学报(2020年2期)2020-09-01 02:08:56
传感器与微系统(2018年7期)2018-08-29 00:44:42
自动化学报(2017年4期)2017-06-15 20:28:55
物流技术(2017年4期)2017-06-05 15:13:46
大学(2008年10期)2008-10-31 12:51:10
