
基于动态双子种群的差分进化K中心点聚类算法
2021-07-27 02:59邓斌涛徐胜超
计算机与现代化 2021年7期
邓斌涛,徐胜超
(广州华商学院数据科学学院,广东 广州 511300)
0 引 言
随着云计算及大数据技术的发展,近年来因特网上的数据量急剧增加,基于机器学习方法的数据挖掘技术也随之发展用来处理这些海量的大数据。聚类算法可以针对样本或者个体的数据完成数据的分类,是数据挖掘中的一个大类分支。
聚类分析按照功能划分包括分区聚类、层次聚类、基于网格的聚类等[1-4]。经典的聚类算法针对无标签的数据可以很好地分类,但是针对大规模的海量数据处理效率低、耗时,已经不能满足近年来实时数据平台的要求。
用实现方式划分,聚类算法又可以分为K最近邻聚类算法KNN clustering、K均值聚类算法K-means clustering、K中心点聚类算法K-medoids clustering等。相关研究表明,K最近邻聚类算法和K均值聚类算法在处理小规模的数据时效率比较高[5-6];K中心点聚类算法比较适合于大规模的数据。因此本文选择K中心点聚类算法完成大数据处理。但K中心点聚类仍然存在可扩展性差、收敛速度慢、容易陷入局部最优解的不足。
差分进化(Differential Evolution, DE)是一个简单和高效的算法,它经常用来解决真实变量的最优化问题,特别是在非线性问题最优化问题上,它拥有强健的全局最优能力,可以很好地提高聚类算法的精确度,是近年来数据挖掘领域比较有前景的算法。例如文献[7]提出了基于差分进化的模糊聚类算法,解决了错误诊断问题。近年来有很多文献对差分进化进行了改进,克服了差分进化算法的一些不足[8-10]。
针对上述问题,为了改善聚类算法的处理速度和分类精确度问题,本文首先结合差分进化算法和K中心点聚类算法;其次,采用动态双子种群(Dynamic Gemini Population, DGP)模式来解决在维持种群密度的时候避免陷入局部最优的问题;最后,本文以网络入侵检测这种大规模的大数据处理问题为案例,通过配置云计算下的Hapdoop平台来并行处理基于动态双子种群的差分进化的K中心点聚类算法DGP-DE-K-mediods。实验结果表明,与现在常见的聚类算法比较起来,并行化的差分进化的K中心点聚类具有更好的分类精度和更少的运行时间。
1 基于动态双子种群的差分进化算法
1.1 差分进化算法概况
差分进化算法是一个基于群智能的新型启发式算法,它具有很强的全局最优解的寻找能力[8]。
假设X为初始种群,N为种群的尺寸,Xi(t)(t=1,2,…,N)是当前种群条件下的进化种群序列。t为算法进化过程的迭代次数。种群的个体交叉操作的处理过程如公式(1)[11]:
Vi(t)=(vi1(t),vi2(t),…,viD(t))
=Xp1(t)+F(Xp2(t)-Xp3(t))
(1)
其中,Xp1(t)、Xp2(t)、Xp3(t)是随机从当前的进化种群中选择出来的3个不同的个体。F是一个规模参数。
D表示种群中个体的维度,这就是说交叉的个体是由D个不同的部分组成。进化的个体Xi(t)和Vi(t)是在当前的种群完成交叉操作来竞争的个体Ui(t)=(ui1(t),ui2(t),…,uiD(t))的时候产生,Ui(t)由D个不同的部分组成。
在竞争的个体Ui(t)的第j个组成部分可以按照公式(2)完成计算[9]。
(2)
其中,z是一个随机的整数,CR∈[0,1]是交叉操作的概率。针对种群的更新,可以按照下面的公式(3)来完成。
(3)
其中,f(Ui(t))是个体Ui(t)的适应度函数,f(Xi(t))是个体Xi(t)的适应度函数。对于每个个体,Xi(t+1)要好于或持平于Xi(t),通过变异、交叉,选择达到全部最优。
1.2 基于差分进化的K中心点聚类
K中心点聚类算法是一个常见的聚类数据挖掘算法[12]。很多聚类算法的模型都起源于该原始算法。它的运行流程如下:
步骤1 待处理的样本数据被清洗和标准化;
步骤2 在所有数据集合中,选择K个点作为各个聚类的中心点;
步骤3 计算其余所有样本点到K个中心点的距离;
步骤4 用最小的距离来完成针对训练样本的分类;
步骤5 在每个类型目录中,从每个样本点中计算出绝对最小误差距离,并将其设置为新的中心点;
步骤6 判断该新的中心点是否与原始的中心点一致,如果它们不一致,返回到步骤3继续执行;
步骤7 达到循环结束条件后停止,输出分类的结果。
在划分聚类后,每个样本点都需要与所有的分类目录计算距离远近并判断,与此同时,也需要完成所有分类目录的所有点的距离计算然后进行比较;也需要在聚类中的所有点完成一个实例操作。因此,该聚类算法的聚类时间是十分长的。为了提高计算速度,使用前面提到的基于差分进化技术的K中心点聚类算法可解决这个问题。下面是关于聚类算法的分类过程的数学描述:假设有n个d维的数据样本x(x1,x2,…,xd),它的聚类特征CF通过公式(4)表示:
CF=〈n,LS,SS〉
(4)
关于LS和SS的计算公式如公式(5)和公式(6):
(5)
(6)
那么聚类算法的聚集中心x0通过公式(7)完成计算:
(7)
根据公式(7),从聚集的所有点到聚集的中心点的平均距离通过公式(8)进行计算:
(8)
除了聚集的所有点到聚集的中心点的平均距离外任何2点之间的平均距离按照公式(9)计算:
(9)
假设参数α和β分别描述在聚类中心的样本点的属性度和聚集度,则差分进化算法的适应度可以描述为公式(10):
(10)
其中,xid表示第i个样本在第j个维度上的属性,利用差分进化算法的规则来寻找函数g(x)的最大值:
G(Xb)=Max(g(x))
(11)
G(Xb)值的获取是从差分进化算法寻找最优解的过程中得到的,最后聚类算法的最终结果就完成了。
1.3 动态双子种群的差分进化方法
在DGP-DE-K-mediods聚类算法中,为了改善DE算法容易陷入局部最优解的问题,本节还采用动态的双子种群策略,这样操作后种群的多样性可以保持,同时种群的进化速度可以加快。
在每一代种群开始的时候,种群中的个体都按照其适应度值(fitness value)从小到大进行排序,在排序操作完成后,种群中具有比较高的个体数量的,就具有更加高的适应度函数值。在这个时候,种群个体的第一个λ将建立带精英组合的局部最优解,剩余的个体将组成普通的带一般组合的局部最优解。
在每一代种群的个体进化过程中,λ按照公式(12)进行更新:
λ=λmin+rand·(λmax-λmin)
(12)
其中,λmax和λmin分别表示参数λ的最大值和最小值;在精英的局部最优解的每个个体中,使用公式(13)交叉策略来完成:
Vi,G=Xi,G+Fi,G·(Xr1,G-Xr2,G)+Fi,G·(Xr3,G-Xr4,G)
(13)
其中,Fi,G表示针对其相应的个体Xi,G的规模参数,r1、r2、r3、r4这些下标分别表示不同的随机整数变量,并且它们与区间[0,1]的参数i不相等,N表示种群的尺寸。在局部种群中采用公式(14)的策略来完成个体交叉操作:
Vi,G=Xi,G+Fi,G·(λbest-Xi,G)+Fi,G·(Xr5,G-Xr6,G)
(14)
其中,参数λbest表示一个个体,它由局部种群中的精英个体来选择产生。r5、r6这些下标分别表示不同的随机整数变量,并且它们与区间[0,1]的参数i不相等。Xr5,G和Xr6,G分别表示适应度函数值,Xr5,G的值优于Xr6,G。
2 云环境下的并行K中心点聚类
2.1 Hadoop云计算框架
本文的DGP-DE-K-mediods聚类算法的实现采用云计算平台,这样可以并行处理基于动态双子种群的差分进化聚类算法,更进一步地提高大数据分类的速度与效率[13]。
Hadoop是一种开源并行大数据处理的总体支撑平台,它由HDFS分布式文件系统、Hbase分布式数据库、MapReduce并行模型等模块组成[14-18]。Hadoop中最关键的是MapReduce。DGP-DE-K-mediods聚类算法中采用了6个步骤来表示MapReduce任务流Job stream,如图1所示。
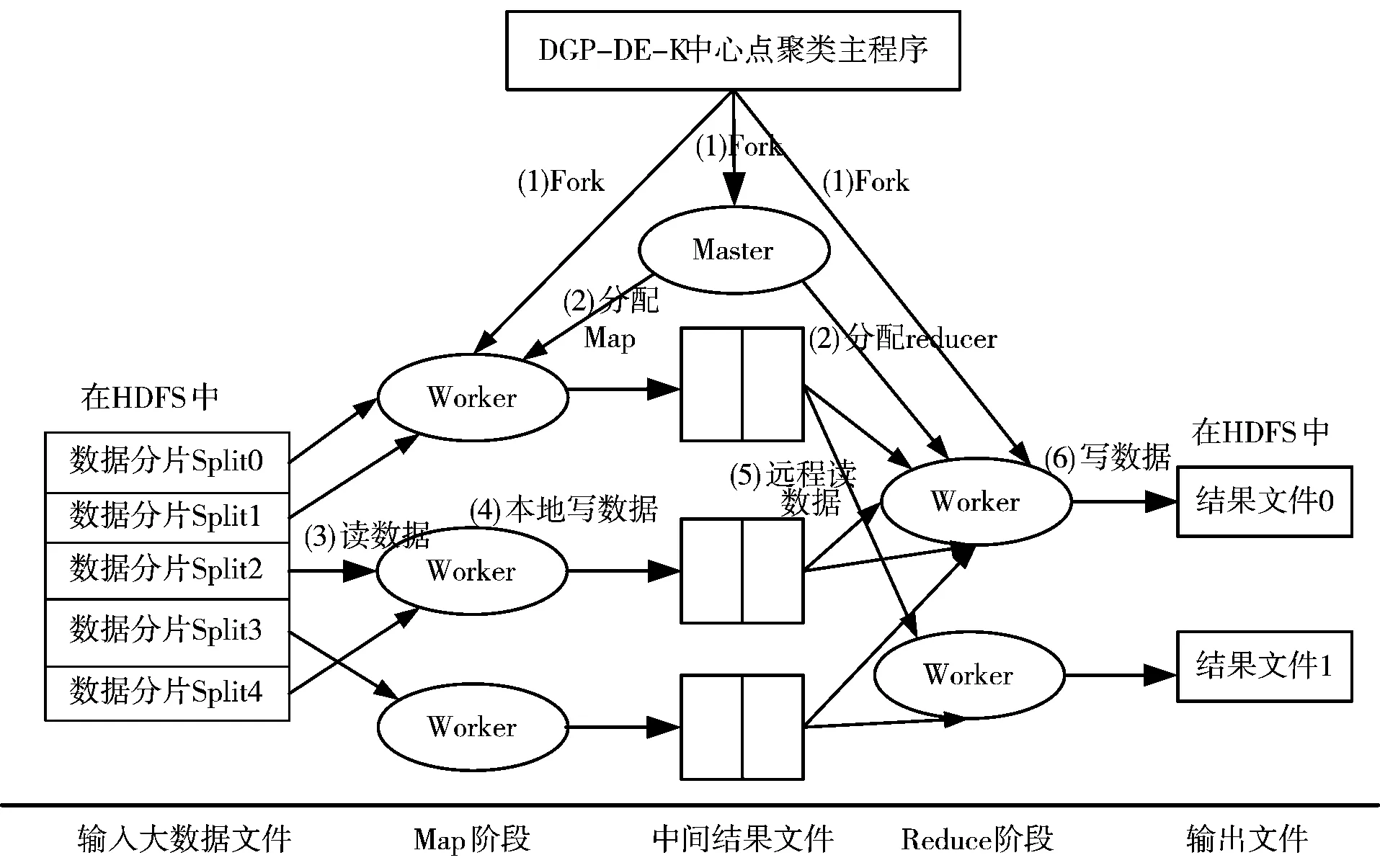
图1 基于MapReduce的大数据聚类任务流
Map操作和Reduce操作是MapReduce并行编程模型的关键操作,所有的任务流必须经过这2个阶段。每个任务流都表示为一系列的Map任务或者Reduce任务,DGP-DE-K-mediods聚类算法作为一个应用程序,其包括的所有子任务组成了一个有向无环图,因特网上有很多关于Hadoop的文献,由于篇幅原因这里不再赘述。这6个具体步骤如下[19]:
1)对输入的大数据的样本数据集文件进行设置与切片;
2)主节点(Master)调度从属节点(Worker)执行Map子任务;
3)从属节点读取输入源片段;
4)从属节点执行Map子任务,并将临时结果文件保存在本地;
5)主节点调度从节点执行Reduce子任务,Reduce阶段的从属节点读取Map子任务的输出文件;
6)执行Reduce子任务,将最后的结果保存到HDFS分布式文件系统中。
有了这6个步骤,K中心点聚类的编程人员就可以摆脱本身分布式计算的编程细节,能够在很短的时间内使用高级语言完成大规模的K中心点聚类。
2.2 动态双子种群聚类的并行处理
本节主要描述DGP-DE-K-mediods聚类算法的实现,采用MapReduce可以使数据分布式存储和并行计算,MapReduce编程容易,程序员没必要有MPI或者OpenMP等早期的并行编程的专业知识。
在使用Hadoop来完成大数据处理的时候,文件里的每行代码都可以作为一个交易记录来对待,每行代码的入口都被一个空格字符分离开来。
在用户提交了数据文件到HDFS中后,文件中的数据将被划分为一系列的数据块,这些数据块的默认大小为64 MB。
在每次循环和迭代不停执行Map操作和Reduce操作的过程中,每个Map节点都同时处理多个数据块并输出一个临时的中间结果,该结果可能是差分进化算法等的局部最优解的临时解。Map操作的伪代码如下:
Map_Class{
1. map(key,value){
2. Sort=0;
3.Dis=Max_Value;
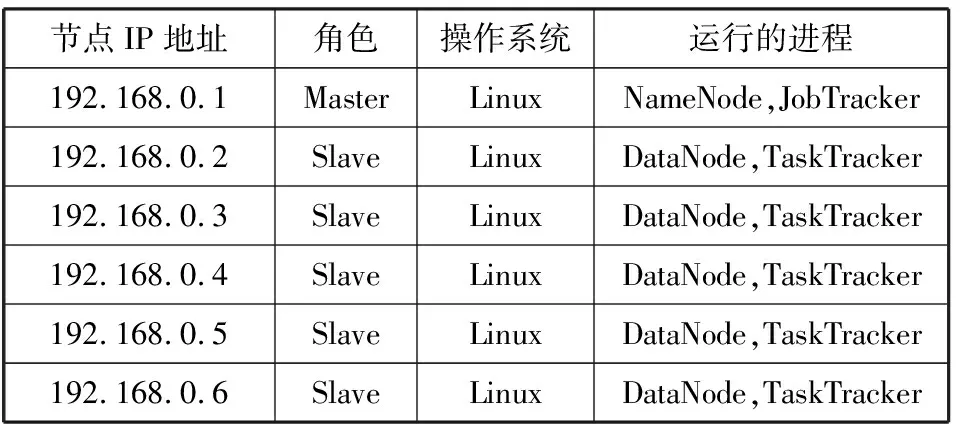
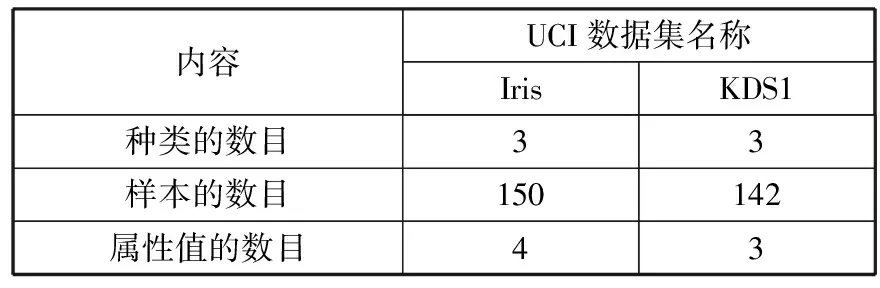
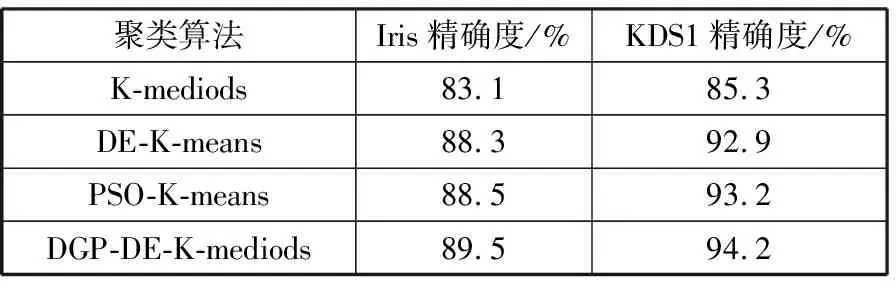
4. for(inti=1;i 5. RecordsDis=dis(i, pointer); 6. if(RecordsDis 7. Sort=i; 8. minDis=RecordsDis; 9. } 10. } 11. produce<"Sort", value>; 12. } 13. } Reduce任务继续处理从Map任务中输出的中间数据,通过归约和比较所有具有相同的关键值的key-value对,并最终获得支持数据项集的完整结果数据。MapReduce采用主-从模式的结构编程模式,即Master-Slave结构模式。主控Master节点负责收集与汇总,从节点Slave负责完成临时数据的聚类处理。Reduce任务的伪代码如下: Reduce_Class{ 1. reduce(key,value){ 2.D1=0; 3. Sort=k; 4. Temps=new int[D1]; 5. for(inti=0;i 6. for(intD1=0;D1 7.D1++){ 8. Temps[i]=value[D1][i]; 9. } 10. } 11. for(intj=0;j 12. pointer+=Temps[j]; 13. } 14. produce 15. } 16. } 有了上面的代码例程和MapReduce的专业知识,本文基于动态双子种群的差分进化K中心点聚类DGP-DE-K-mediods就可以高效地、并行地、快速地处理和适应现代大数据技术容量海量增加的需求。 DGP-DE-K-mediods聚类算法的测试条件如下:6台高档PC机,Intel的i7 3.2 GHz主频处理器、8 GB内存,所有节点之间的通信经过1 GB/s带宽的双网卡。采用Hadoop2.2版的平台,Java环境的JDK版本为1.8.0。共有6台物理主机,其中一台配置Jobtracker,其他5台配置Tasktracker,在局域网内的IP地址配置如表1所示。 表1 Hadoop云平台的物理主机的配置 本节分析在差分进化算法和动态双子种群模式中各个参数的设置。有经验显示,当规模因子F=0.6的时候差分进化算法运行比较好[11],所以设置规模因子F=0.6。有文献研究显示,交叉操作概率变量的选择在设置到[0.3,0.9]之间性能比较优异[9],所以本文将交叉概率变量设置为CR=0.5,规则更新参数λmax=0.5,λmin=0.3。种群大小N=30;种群大小主要反映算法中种群信息量的大小,进化次数值越大种群信息包含得越丰富,但是带来的后果就是计算量变大,不利于求解。反之进化次数较小,使种群多样性受到限制,不利于算法求得全局最优解,甚至会导致搜索停滞。所以本文将进化次数的最大值设置为Tmax=1500。 为了验证本文的DGP-DE-K-mediods聚类算法的高效性和高性能,使用大数据处理的案例数据,UCI机器学习的Iris数据库http://archive.ics.uci.edu/ml/datasets/和人工的KDS1数据库来做仿真实验。UCI机器学习数据是由加州大学提供的,当前具有335个数据集[20]。把K-mediods[12]算法、DE-K-means[13]算法、PSO-K-means[18]算法和本文的DGP-DE-K-mediods算法作为性能比较对象。Iris和KDS1这2个数据集的参数设置如表2所示。 表2 聚类算法的数据设置 由于聚类算法的索引会影响到聚类算法的应用性,所以本文把聚类算法针对大数据的分类精确度作为性能指标之一,精确度的计算公式如下: (15) 其中,Ni表示数据集中类的所有样本数,Nia表示数据集中所有被正确分类后的数量,K表示聚类算法的种类数,也是中心点的数量。通过上面搭建的Hadoop云平台完成MapReduce编程与大数据处理,实验后得到DGP-DE-K-mediods聚类算法的结果如表3所示。 表3 4个聚类算法的分类精确度结果比较 从表3的实验结果可以看出,DGP-DE-K-mediods聚类算法的分类精确度比其他3个算法的分类精确度更高,最高分别可以在Iris数据集上达到89.5%和在KDS1数据集上达到94.2%。因此可以看出,本文的DGP-DE-K-mediods可以获得分类算法的全局最优性能,在智能优化的过程中离最优解最接近。 3.4.1 网络入侵检测环境设置 为了更好地体现DGP-DE-K-mediods聚类算法大数据应用的优势,本节选择网络入侵检测这种大数据应用,网络入侵检测是网络安全中的一种主动防御行为,它主要靠通过发送TCP RST消息包来与入侵行为进行判断[21-23]。基于中心点聚类的K-mediods方法的网络入侵检测系统的处理流程如图2所示。 图2 基于K-mediods的网络入侵检测流程 K-mediods网络入侵检测覆盖的数据源包括许多类型:日志信息、异常的目录与文件变化、网络信息、程序执行异常行为、主机的入侵行为等。本文的DGP-DE-K-mediods聚类分析方法可以很好地处理这些网络入侵检测的数据分析[23],网络攻击的数据包设置如表4所示,软硬件测试环境还是按照表1的Hadoop集群的配置方式。 表4 K-mediods网络入侵检测的分类测试数据 3.4.2 精确度比较 公式(16)很好地体现了网络入侵检测系统的错误检测率(Error Detection Rate, EDR)[12]。 (16) 其中,MP表示丢弃的攻击包的数量,DP表示网络入侵中的所有攻击包的数量。本文的DGP-DE-K-mediods聚类算法完成网络入侵检测的结果如表5所示。 表5 网络入侵检测结果性能比较 从表5的结果可以看出,相对于K-mediods的网络入侵检测,基于DGP-DE-K-mediods的网络入侵检测具有更高的检测精度,这是因为K中心点算法能够聚集到入侵检测模型的结构,当数据规则扩大的时候,这样就克服了早期的入侵检测模型过于依赖于检测规则的不足,同时,K中心点聚类算法可以检测和处理新型的攻击行为。DGP-DE-K-mediods基于动态双子种群的差分进化方法可以改善局部最优解的问题,在种群多样化更新的时候可以更好地改进分类的精度。 3.4.3 运行时间分析 K-mediods的入侵检测和基于云计算的并行DGP-DE-K-mediods聚类算法的运行时间分析如表6所示。从实验结果可以看出,当数据容量比较小的时候,DGP-DE-K-mediods聚类算法运行时间的减少还不明显,甚至运行时间还多于K-mediods的网络入侵检测算法。 表6 DGP-DE-K-mediods聚类算法执行时间 但是随着它处理的数量容量增加,DGP-DE-K-mediods聚类算法显示出它明显的速度优势。特别是在数据容量规模特别大的时候,DGP-DE-K-mediods聚类算法速度提高特别快,这表示大数据聚类可以通过Hadoop云计算并行处理很好地提高效率。 表5和表6的结果也表明,当处理大数据聚类应用的时候,需要处理数据的容量将十分影响整体计算速度,通过云计算、智能算法的优化都可以改进数据挖掘的速度与效果。 本文提出了云环境下基于动态双子种群的差分进化K中心点聚类算法DGP-DE-K-mediods,利用典型的大数据分类的案例数据和网络入侵检测这种大数据应用来仿真算法的效果。实验结果表明,DGP-DE-K-mediods算法比K-mediods聚类算法有更好的分类精度和更少的运行时间。尽管这样,Hadoop是一个比较低版本的开源的云平台,下一步的工作是将DGP-DE-K-mediods算法移植到更加高级别的云计算平台,进一步提高大数据聚类算法的速度与效率。3 仿真实验与性能分析
3.1 仿真软硬件环境
3.2 参数设置与数据选取
3.3 聚类算法精确度分析
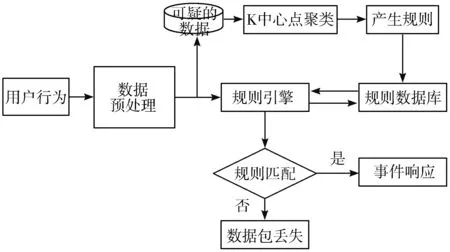
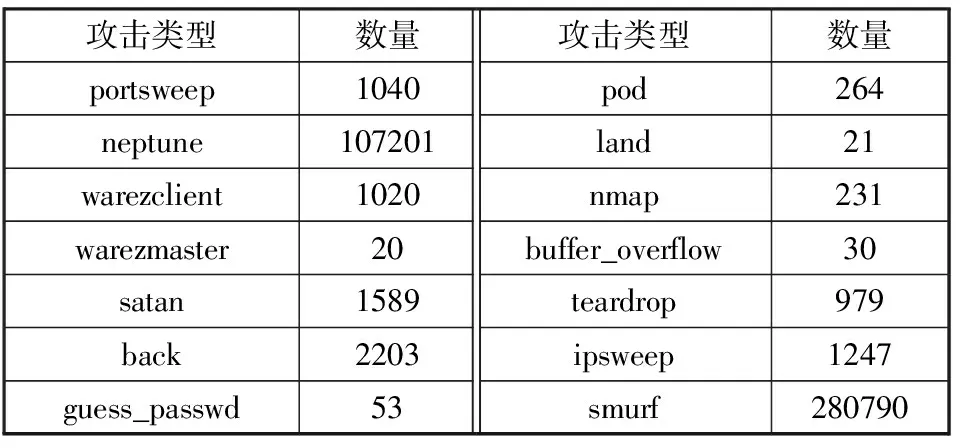
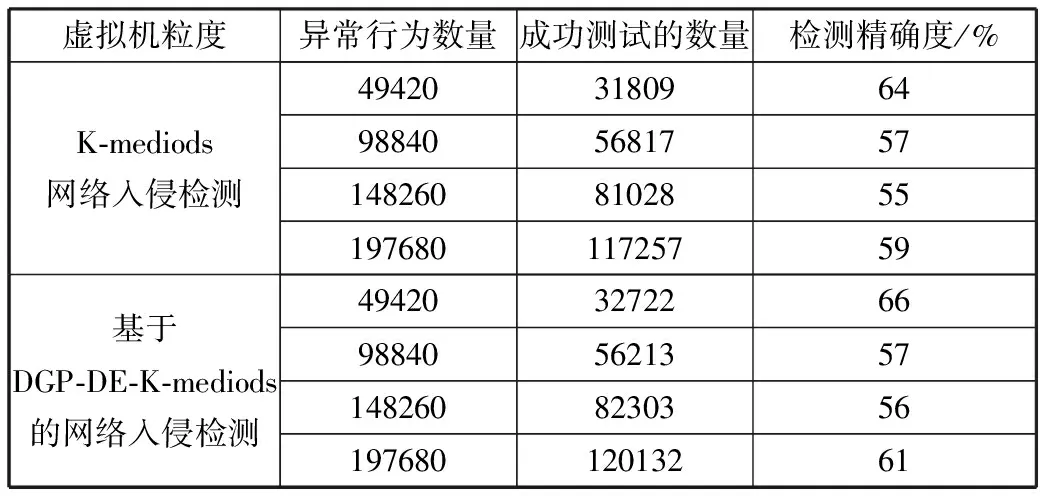
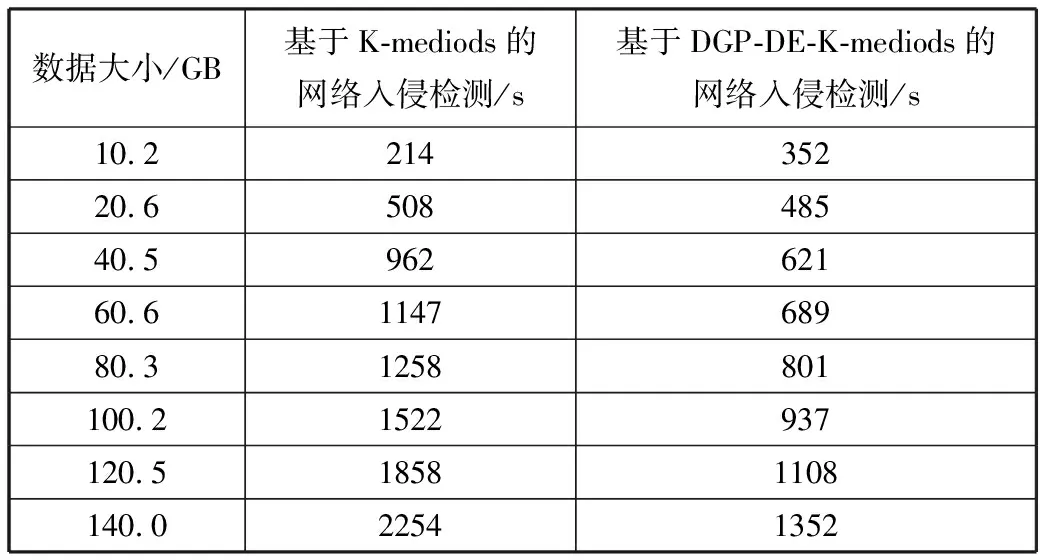
3.4 网络入侵检测性能分析
4 结束语
猜你喜欢
新世纪智能(数学备考)(2021年5期)2021-07-28计算机技术与发展(2020年8期)2020-08-12电脑报(2020年12期)2020-06-30电脑报(2019年4期)2019-09-10学生天地(2017年20期)2017-11-07看小说(2017年5期)2017-06-30大众摄影(2015年9期)2015-09-06信息安全研究(2015年3期)2015-02-28应用化工(2014年1期)2014-08-16太空探索(2014年1期)2014-07-10
