
基于深度学习的荔枝虫害识别方法
2021-07-27 06:26邱文杰易万茂马仲辉
实验室研究与探索 2021年6期
叶 进, 邱文杰, 杨 娟, 易万茂, 马仲辉
(广西大学a.计算机与电子信息学院;b.农学院,植物科学国家级实验教学示范中心,南宁530000)
0 引 言
荔枝是广西的主要经济作物之一,目前广西荔枝栽培面积240多万亩,产量60多万t,广西荔枝生产规模仅次于广东,位居全国第二。荔枝虫害种类繁多,主要包括荔枝蝽、龙眼鸡、蛀蒂虫等。因此对荔枝虫害的识别与防治工作至关重要。目前国内学者针对病虫害图像识别这一领域已经做了不少研究,例如,Cheng等[1]设计了一种利用深度残差学习的害虫识别方法,该方法在复杂农田背景下对于10类农作物害虫图像识别准确度达到98.67%。Rani等[2]使用基于聚类的图像分割算法和SVM分类器,对蚜虫等3种害虫的识别准确度达到98.38%。Mishratffu[3]在大米的几种常见害虫上对几种常见分类器做了对比,其中CNN的准确率最高,达到94.44%。Liu等[4]构建了一个基于BP神经网络和K近邻算法的多分类器,并用加权平均的方式融合成员分类器的输出,达到了不错的分类性能。现有的对虫害识别的研究虽然已经达到了不错的效果,但目前国内对与荔枝虫害识别的研究还不够深入,基于特征融合的荔枝虫害识别技术还不成熟,针对复杂背景下的荔枝虫害识别还存在特征选择的随机性和识别结果的不稳定性等问题。本文采用中值滤波对原图像进行降噪处理,采用自适应阈值分割算法[5]进行病斑图像的提取与分离,使样本质量明显提升。使用OpenCV提取病斑图像的15个颜色特征值,2个轮廓特征值,使用灰度共生矩阵[6]提取经过数据清洗后的病斑图像的15个纹理特征值。根据皮尔逊相关系数[7]挑选与识别结果线性关联程度大的特征向量,剔除冗余特征,实现特征参数的优化组合。将重组后的特征向量输入预先训练好的神经网络模型,经过多次迭代,实现了对荔枝蝽、卷叶蛾、龙眼鸡3种荔枝主要虫害的识别,并通过不断模型超参数,进一步将识别精度提高到95%以上。
1 研究数据
使用Canon单镜头高分辨率数码相机(有效像素约2 230万,使用佳能EF系列镜头)和网络爬虫进行图片采集,拍摄图片时间均匀覆盖各个时段,同时保证在害虫生长的不同时期连续拍摄。拍照时,虫体体积在整张照片中所占体积比尽量不低于50%,拍摄角度采用俯拍,拍摄时间选择在光线充足的白天。拍摄照片时,相机模式设置为手动对焦,并关闭闪光灯和白平衡。图1展示了荔枝蝽不同生长发育期的形态。

图1 荔枝蝽的各个生长发育期形态
在拍摄照片过程中由于相机自身或与外部噪声干扰,往往会产生噪声。为了将噪声消除的同时保留虫害图像的细节、边缘等特征,本文对比了4种常见滤波器,发现中值滤波器[8]对脉冲干扰的抑制效果最好,在抑制随机噪声的同时能有效保护边缘少受模糊,同时过滤了虫害图像的大部分高斯噪声、脉冲噪声。4种滤波器的对比如图2所示。
背景分割的目的是前景和背景互相分离[9]。目前图像分割方法大体可分为4类,其中以基于聚类的方法最为常见。由于本试验中的图片大多拍摄自野外,背景具有相对复杂性,因此选用对微弱边缘有良好反应的分水岭算法[10]进行背景分割。图3给出了图像分割前后的对比图。

图3 图像分割结果

图24 种滤波器处理图像的对比
2 特征提取与降维
特征选择对模型性能的提升具有重要的作用,如何在提取到的32个颜色、纹理、轮廓特征值中选择对分类结果影响最大的前n个特征值将直接影响到模型的预测性能。特征降维[11]不仅可以大幅降低神经网络训练所需时间,更能提高模型的泛化能力。在特征选择之前,首先要对图像进行特征提取。本文使用OpenCV提取了病害图片的32个特征属性,包括形态学特征、颜色特征和纹理特征[12],其中形态学特征包括面积、周长2个特征;颜色特征包括RGB平均值、峰值、标准差、方差和偏度等15个特征;纹理特征使用灰度共生矩阵提取,包括能量等15个特征。
采用Pearson积矩相关系数来衡量每一特征值对分类结果的影响程度大小[13]。系数越大代表对分类结果的影响程度越大;反之亦然,系数为0代表该特征值对于分类结果没有影响。通过计算各个特征值的Pearson系数,按照相关性从高到低进行特征属性的排序。公式(1)给出了任意2个特征值之间的积矩相关系数的计算方法:
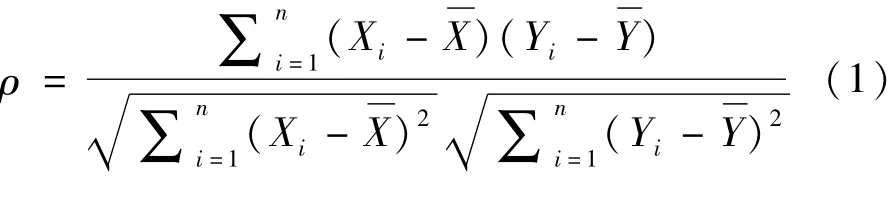
3 BP神经网络设计
实验过程中,首先留出20%的样本作为神经网络的验证集,作为神经网络训练过程中没有遇到过的新样本,测试模型的泛化能力[14]。另外,分别随机抽取剩余数据集中80%的样本作为训练集和20%样本作为测试集,测试集和训练集用于模型的训练过程。初次进行训练时,根据输入特征向量维度确定构建输入层节点个数为26,隐藏层节点个数为10,输出层节点个数为3的误差反向传播神经网络。输入层的26个神经元分别代表一种特征属性。输出层的3个神经元分别表示荔枝蝽、卷叶蛾、龙眼鸡3种害虫,选取输出概率最高的神经元作为识别结果,并将输出值作为判断置信度。初始学习率设置为0.01,设置批处理大小为256,迭代次数500次。图4给出了神经网络结构图。
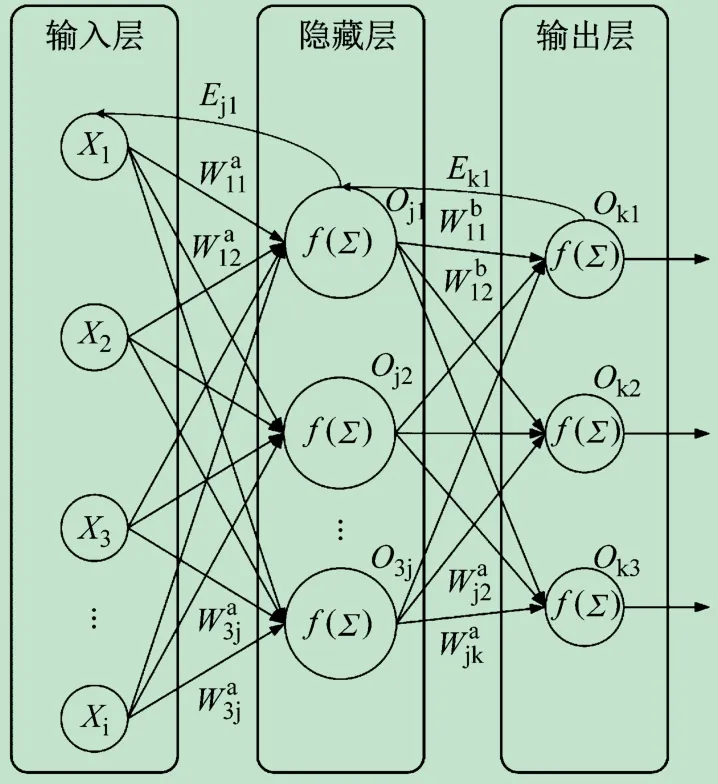
图4 神经网络结构图
图中:Xi(i=1,2,…,i,i=26)代表26个颜色、纹理、颜色特征值中的某个特征属性代表输入层第i个节点和隐藏层第j个节点之间的权重,初始权重为(-1,1)区间上的随机值表示隐藏层第j个节点和输出层第k个节点之间的权重,初始权重同为(-1,1)区间上的随机值;Oj,m(m=1,2,…,10)代表隐藏层第m个节点的输出;Ok,n(n=1,2,3)代表输出层第n个节点的输出;f(Σ)表示将该节点的输入求和后经过激活函数输出。本文采用在(0,1)区间内平滑取值的非线性函数Sigmoid[15]作为激活函数,
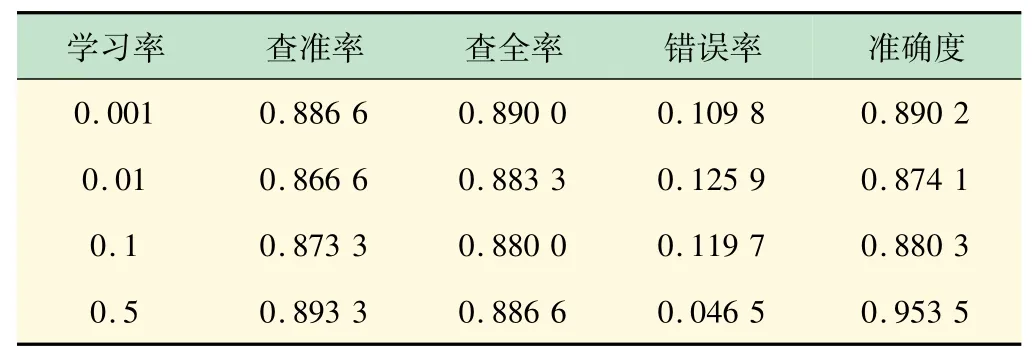
表2 神经网络学习率对比
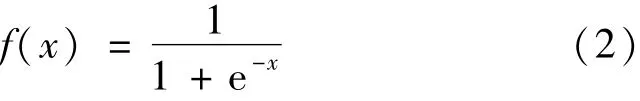
输出层使用Softmax[16]作为激活函数,
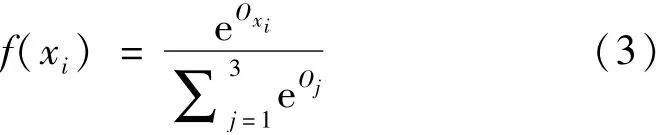
通过复合函数求导的链式法则[17],利用梯度下降原理得出输出层和隐藏层误差反向传播算法的误差梯度,根据误差梯度即可找出误差下降最快的方向。通过这种方式,使得不同神经元之间的权重快速、正确地更新。同理可以得出隐藏层和输入层之间的误差梯度,给出了如何根据误差梯度进行下一步权值更新的计算:
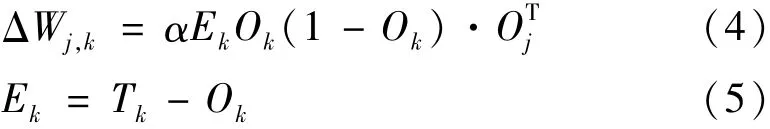
为了探究全连接神经网络层数和学习率对模型性能的影响,在其他超参数不变的情况下,依次调整神经网络结构和学习率的大小,提升模型预测性能。
4 结果与分析
4.1 模型评价指标
用来评估模型泛化能力的性能指标有很多种[18],由于本文为三分类问题,所以选择查准率、查全率、准确率、错误率作为模型的性能度量。设神经网络的分类结果中,真正例(true positive)的个数为TP,真反例(true negative)的个数为TN,假正例(false positive)的个数为FP,假反例(false negative)的个数为FN。
查准率(Precision):反映模型输出结果中真实正例占全部正例的比例
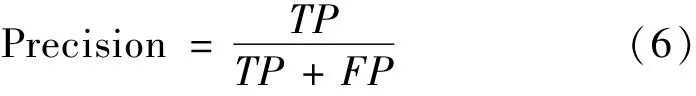
查全率(Recall):反映模型输出结果中有多少正样本被准确预测
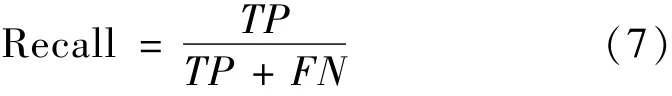
精确度(Accuracy):设样本预测结果为yi,正确结果为y^,样本数量为n
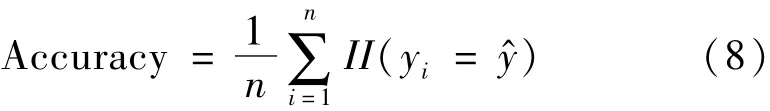
错误率(Error):分类错误的样本占样本总数的比例
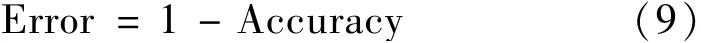
4.2 实验结果分析
表1 列出了BP神经网络在测试集中的不同测试指标,并将不同网络结构的神经网络进行横向对比。结果表明,拥有2个隐藏层,每个隐藏层20个节点的神经网络准确度最高,达到92.74%。在确定神经网络结构后,本文通过调整学习率的大小进一步优化神经网络。
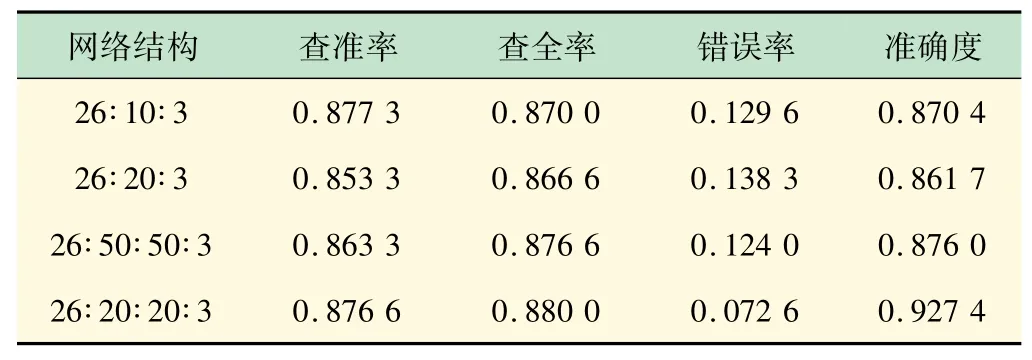
表1 神经网络结构对比
实验结果表明,神经网络在不同学习率下的表现略有不同。由于本试验在神经网络的训练过程中采用500次迭代,导致低学习率下的模型难以收敛。综上所述,输入神经元个数为26,隐藏层节点个数为10,层数为2,输出层节点个数为3的神经网络,在学习率为0.5下的表现最优,识别准确率达到95.35%。
5 结 语
本文针对自然条件下的荔枝虫害识别问题,提出了一种多模态特征的识别方法。通过提取虫害的形态学、纹理、颜色等32种特征信息,通过特征降维的方法,进一步提高分类的准确度。本方法的各项指标相较于传统分类器均有了明显提升,对荔枝蝽、卷叶蛾、龙眼鸡3种常见虫害的总体识别率为95.35%,基本达到了实用化水平。
同时,本方法具有拓展性,仅需稍作调整,即可推广到其他作物的病害识别任务中。本方法填补了目前虫害识别领域尚未形成一种统一的特征提取方法的空白,为荔枝的虫害识别提供了新的思路。
猜你喜欢
岭南音乐(2022年4期)2022-09-15
数学物理学报(2021年6期)2021-12-21
数学物理学报(2021年5期)2021-11-19
烟台大学学报(自然科学与工程版)(2021年1期)2021-03-19
四川蚕业(2021年2期)2021-03-09
河北果树(2020年4期)2020-11-26
凯里学院学报(2020年3期)2020-06-28
中国(俄文)(2019年8期)2019-08-24
今日农业(2019年13期)2019-08-12
意林·全彩Color(2019年4期)2019-05-11
