
基于AdaBoost 与RusBoost 的水声目标杂波分类研究与应用
2021-07-26 05:54何荣钦胡鹏冯金鹿
声学与电子工程 2021年2期
何荣钦 胡鹏 冯金鹿
(第七一五研究所,杭州,310023)
对水声目标、杂波进行分类在渔业生产、海洋信息产业、科学调查研究以及国防军事中有着重要作用[1],可以更好的从杂波中将目标区分出来,为后续声呐信息处理提供重要帮助[2]。水声目标的识别总体框架一般包括目标获取、特征提取、分类识别三大部分。在目标获取部分,海洋试验不够多,一般数据积累较少,优质数据集不容易获取。特征提取部分,常规特征提取较成熟,基本上能够反映目标真实特性[3]。
传统的水声目标和杂波的分类是通过人工观察声呐画面来区分,将杂波剔除,选择目标。因此仅停留在表面特征上,工作量大,不能很好的完成分类工作。人工智能分类方法可以提高分类准确率和自动化。当水声数据集样本中目标数量较少、杂波较多时,采用一种能够适应不平衡数据集的方法尤为重要。集成方法的基分类器相对简单,通过boost 之后又能表现出很好的效果,且对样本集数量没有太大要求。本文采用AdaBoost 和RusBoost 方法,对数量有限的不平衡水声目标数据进行交叉验证实验,对比分析两类算法识别效果。
1 Adaboost 算法
Boost 是一类可将弱学习器提升为强学习器的算法[4]。先从训练集训练出一个基学习器,再根据基学习器的表现对样本分布进行调整,使得先前基学习器做错的训练样本在后续受到更多关注,然后基于调整后的样本分布来训练下一个基学习器。如此循环进行,直至基学习器数目达到事先指定的值T,最后将T个基学习器进行加权结合。其中AdaBoost[5]就是常用方法。随着T的增加,集成错误率将指数级下降,最终趋于零。因此AdaBoost对分类有较好的效果。但是当目标较少、杂波较多时,杂波类对误差损失函数贡献较大,因此,AdaBoost 模型更容易倾向于数量较多的杂波,更可能将目标分类成杂波,不能准确地将目标从杂波区分出来。


图1 AdaBoost 算法流程
(1)初始化
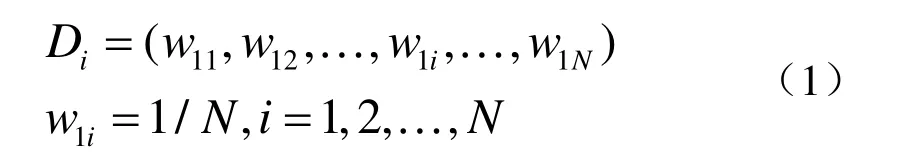
(2)迭代
● 基分类器
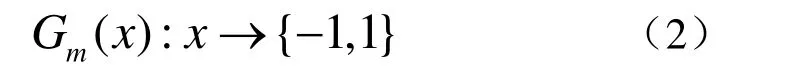
式中,m为迭代计数。
● 分类误差

2 RusBoost 算法
2.1 不平衡数据集处理
当目标数据少、杂波多,整个数据集存在较大不平衡问题,因此从数据角度出发,对样本进行抽样[6-9]。随机采样是较常见的方法,主要分为随机上采样和随机下采样。前者从少数样本中有放回的进行抽样,重复多次,组合成新的与多数样本数量相近的样本集。而随机下采样则相反,在多数样本中有放回或者无放回的重复采样,抽取与少数样本数量相近的样本集。本文中因为目标较少且杂波较多,需要多次重复上采样才能使得样本相对平衡分布。杂波对应的样本数量较大,通过重复上采样会使得目标被重复采样次数过多,生成目标上采样也不能保证与真实目标特征一致且与杂波特征不一样。人工随机下采样对数据集预处理,虽然表面上看解决了数据不平衡问题,但杂波可能是由多种原因造成,本身就存在不均衡的问题,因此实际送给Boost 的训练数已经去除了部分杂波,每个基分类器获得的子数据集来源于同一人为下采样后数据集,使得被去除的杂波信息丢失。因此,本文采样应用RusBoost 方法,它使用完整数据集,对基学习器独立下采样训练集成,这样能够尽量保证杂波被全部利用,避免采样造成的信息丢失[10]。
2.2 RusBoost 算法
RusBoost 即随机欠采样提升算法。基本原理与AdaBoost 类似。只是对训练集预处理时,使用RUS(Random Under-Sampling)方法进行抽取,将随机下采样抽取后的训练集子集输入boost 方法中,最终得到训练模型。该算法区别在于:先将所有样本设置归一化的样本权重。
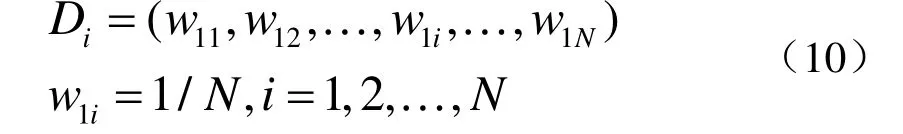
第i次迭代时,从多数类样本中随机下采样得到m个样本,与少数类样本组成随机下采样训练子集Si,并重新归一化权重Sd。此时得到了第i次迭代的训练集Si和权重Sd。然后进行Boost 迭代。
3 实验验证
3.1 数据集
数据为海试获得的主动水声目标数据。从目标中提取出关于几何特征和回波信号特征。水声目标特征提取是通过信号分析和图像分析得到。一般从信号发射、信号传播和接收回波信号并处理分析后得到目标的材料特征、几何特征以及运动特征[1,11]。本文提取4 类特征共12 个,分别是扩展类特征4个、信噪比特征1 个、统计特征2 个和形状特征5个。扩展类特征是根据主动声呐回波信号的距离角度等扩展,比如距离扩展;信噪比特征是能量信噪比相关的特征,比如能量密度;统计特征是回波中过门限点的统计学特征,比如峰度;形状特征是回波中过门限点形状分布特征,比如点密度。
本次水声目标数据集A 共有目标176 个,杂波43 036 个。随机划分为训练集A_train 和测试集A_test,其中训练集包含105 个目标,25 863 个杂波;测试集包含71 个目标,17 173 个杂波。数据集B 目标67 个,杂波8929 个。数据集A 和B 为不同时间不同海域试验数据。
3.2 实验设计
训练采用交叉验证法,进行5 折交叉验证。迭代次数为50。采用决策树作为具体基分类器,并将决策树最大深度设置为20。分别使用AdaBoost 和RusBoost 进行训练,得到训练验证结果。最后分别对测试集A_test 和数据集B 进行测试。
3.3 训练验证
图2 为AdaBoost 和RusBoost 的ROC(Receiver Operating Characteristic)曲线。可以看到两者ROC曲线较为相近,但是预测结果相差较大。对于验证结果,设定目标为正例,杂波为反例,那么AdaBoost的真正例率(真实正例被预测为正例的比例,用TPR表示)为0.44,假正例率(真实的反例被预测为正例的比例,用FPR表示)为0.00,对目标滤除较多。RusBoost 的TPR为0.92,FPR为0.02,即90%以上的目标被正确分类,被错误分类为目标的杂波的比例也很低。
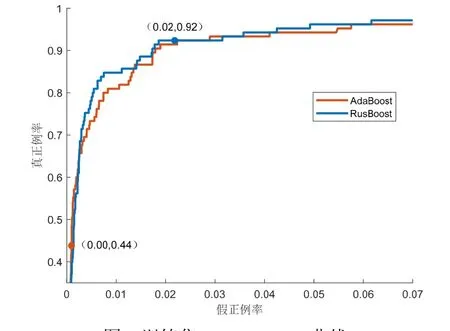
图2 训练集A_train ROC 曲线
图3 和图4 分别为AdaBoost 和RusBoost 数据集A 目标预测概率值的频率分布直方图。很明显可以看出,前者杂波较为集中,目标分散在0.2~0.9之间,但是一部分目标预测概率低于0.5,无法被正确分类。后者杂波预测概率虽然往0.5 偏移,但是目标基本上集中到了0.5 右侧。根据预测概率,能够较好地将目标分类出来。这也就解释了ROC曲线相近,但是概率分布存在差异,使得后者分类效果较好。
3.4 测试结果
测试集A_test 和数据集B 分别进行测试,结果见表1~3。从表1、2 可以看出, AdaBoost 虽然FPR很低,但TPR仅0.5 左右,一半真实目标未被正确分类。应用RusBoost 方法后,虽然杂波被分类成目标是数量略有升高,但是TPR超过了0.9。使用相近的数据集B 进行测试(表3)后,仍旧可以接近0.9 的目标分类正确率,由于B 数据集杂波相对较少,因此FPR有所上升,但实际留下的杂波数量变化不大。
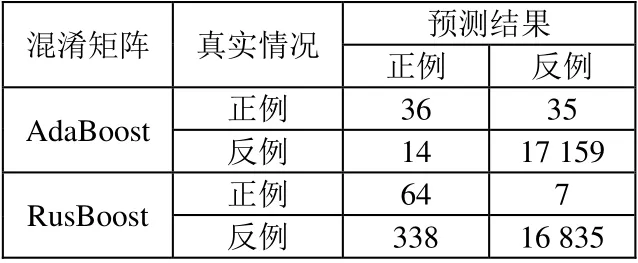
表2 测试集A_test 混淆矩阵

表3 数据集B TPR-FPR 表
4 结束语
经过研究对比,RusBoost 较AdaBoost 更好地处理水声目标不平衡数据,使得目标被正确分类,杂波也尽可能被正确分类。通过数据集A 训练得到的模型在数据集B 上进行测试也能有较好的效果,模型具有一定的泛化能力。因此在有限的不平衡水声目标数据集下,训练速度较快且能够应对不平衡数据的RusBoost 方法在目标杂波分类中效果较好,能够胜任诸多科研生产任务。未来随着数据集的扩充与数据集质量的提高,可以引入更多的机器学习方法,以寻求更好的结果。
猜你喜欢
舰船科学技术(2022年21期)2022-12-12
舰船科学技术(2022年20期)2022-11-28
科学与信息化(2021年30期)2021-12-24
数学小灵通(1-2年级)(2021年4期)2021-06-09
雷达与对抗(2020年2期)2020-12-25
火控雷达技术(2020年2期)2020-10-16
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
电子制作(2017年22期)2017-02-02
