
基于GPU 的车辆-轨道-地基土耦合系统3D 随机振动并行计算方法
2021-07-25 08:47:18朱志辉夏禹涛王力东刘禹兵
湖南大学学报(自然科学版) 2021年7期
朱志辉,夏禹涛,王力东,刘禹兵
(1.中南大学 土木工程学院,湖南 长沙 410075;2.中南大学 高速铁路建造技术国家工程实验室,湖南 长沙 410075;3.长沙理工大学 土木工程学院,湖南 长沙 410114)
随着列车速度、轴重、路网密度和行车密度的提高,铁路运输引起的振动对周围环境的影响问题日渐突出.计算机性能的不断提升使得有限元法[1-2]、有限元/无限元法[3]、边界元法[4]等数值计算方法能够广泛用于研究车辆引起的周围环境振动问题;根据所建立的模型维度可将数值模型分为2D 模型[5]、2.5D 模型[3]和3D 模型[2].与3D 模型相比,2D 和2.5D模型假设轨道-地基土模型的几何形状和材料特性沿车辆运动方向保持不变或周期性变化,计算中只需建立线路的横截面模型,具有计算效率高的优点.但车致环境振动实质上是3D 空间上的工程问题,3D 模型可以考虑地基土的不连续性及与附近结构的耦合[6],因此仍具有不可替代的普适性.
同时,轨道不平顺的随机性导致轮轨相互作用力具有随机性,移动车辆引起的任何特定地面位置的振动均是一个非平稳的随机过程[7].采用蒙特卡罗法等常规方法分析随机响应时由于样本过多导致计算效率较低.针对随机振动计算效率低的问题,林家浩等提出了高效的虚拟激励法,该法已被广泛地用于分析平稳或非平稳随机激励下线性系统的随机响应[8].虚拟激励法将平稳随机振动分析转化为谐响应分析,将非平稳随机振动分析转化为可用数值积分方法求解的确定性瞬态分析,与蒙特卡罗方法相比,其计算效率提高了1~2 个数量级[9-10].Wang 等[2]采用虚拟激励法分析车辆-轨道-地基土的随机振动,基于填充元优化与多波前法提出了一种求解大型稀疏线性方程组的多点同步算法,进一步节省了计算时间.这些方法大部分都在传统CPU 串行平台上开展并实施.由于车辆-轨道-地基土耦合系统3D 有限元模型的自由度数量庞大,且使用虚拟激励法进行随机振动分析时仍需求解一系列大型稀疏线性方程组,因此计算效率低仍然是基于3D 模型开展随机振动分析面临的主要问题.
近年来,并行计算等高性能计算技术的发展为大规模的工程计算问题提供了高效的解决方案.在随机振动领域,聂旭涛等[11]结合有限元EBE 并行策略和虚拟激励法实现了结构随机振动的并行计算,其中通过消息传递接口(MPI)实现多CPU 节点间的通讯,并证明了该算法的准确性和高效性.张健[12]利用虚拟激励法中每个频点的随机响应计算相互独立的特点,采用包含8 个CPU 的工作站实现虚拟激励法的并行计算,每个CPU 平均分配各频点的计算任务,结果表明计算加速比几乎与CPU 数目成线性关系.这些方法通过CPU 集群实现程序的并行化加速,但是CPU 集群平台搭建与维护的成本较高.随着GPU 通用计算的发展,CUDA 等统一计算架构和编程环境的出现为GPU 并行计算提供了易用的编程接口.相对于传统的CPU 串行计算,GPU 的浮点计算能力更强、内存带宽更大,具有低功耗和高性价比的特点,因此越来越广泛地应用于科学研究和工程计算中.陈曦等[13]通过使用CPU-GPU 混合计算构架加速了预处理Krylov 子空间迭代法,从而提升了岩土工程有限元分析的效率;蔡勇等[14]基于GPU 并行计算平台CUDA,使用多重网格法加快Jacobi 迭代的收敛速度,在采用GTX 460 显卡的个人计算机上有效提高了大规模壳结构有限元分析的效率.
综上所述,针对轨道不平顺随机特征导致车辆-轨道-地基土耦合系统随机分析计算效率低的问题,采用虚拟激励法降低大样本分析的计算量;针对车辆-轨道-地基土耦合系统等效刚度矩阵的稀疏特性,采用行压缩格式存储大型稀疏矩阵,采用预处理共轭梯度法并行求解等效静力平衡方程,最后通过MATLAB-CUDA 混合平台开发并行计算程序.通过数值算例验证了该并行计算方法的高效性,并给出了使用该法进行车致场地振动分析时迭代收敛精度选取的建议.
1 车辆-轨道-地基土耦合系统的3D 随机振动分析模型
1.1 车辆-轨道-地基土耦合振动模型
车辆-无砟轨道-路堤-地基土系统可分为车辆子系统和轨道-地基土子系统,两个子系统通过轮轨相互作用耦合为一个整体,如图1 所示.
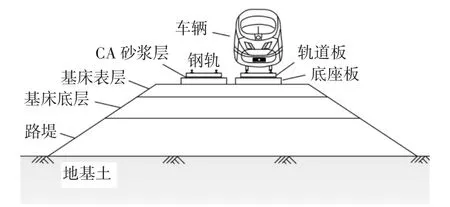
图1 车辆-轨道-地基土耦合模型Fig.1 Train-track-soil coupled model
通常铁路车辆可视为一系列相同的四轴车辆,由于车辆引起的地基土振动以竖向振动为主,每节车辆可简化模拟为竖向2D 的10 自由度模型[15].采用多体系统动力学理论建立车辆子系统的动力平衡方程

式中:Mv,Cv和Kv分别为车辆的质量、阻尼和刚度矩阵;分别为车辆的位移、速度和加速度向量;Fvs为作用于车辆的轮轨相互作用力向量.
考虑到3D 模型的普适性,本文采用有限元法建立了轨道-地基土子系统的3D 模型.根据直接刚度法建立轨道-地基土子系统动力平衡方程

式中:Ms,Cs和Ks分别为轨道-地基土子系统的质量矩阵、阻尼矩阵和刚度矩阵,分别为轨道-地基土系统的位移向量、速度向量和加速度向量,Fsv为轨道-地基土系统的轮轨相互作用力向量.
基于线性赫兹轮轨接触模型[16],联立车辆系统动力方程(1)和轨道-地基土动力方程(2),可建立车辆-轨道-地基土系统的耦合时变动力方程.

式中:Kvs和Ksv为系统刚度矩阵的耦合部分,表征车辆子系统和轨道-地基土子系统的耦合作用.Fv和Fs为两个子系统之间的相互作用力向量.其中,车辆子系统的荷载向量Fv可表示为

式中:Fvg为车辆自重引起的确定性荷载;Fvr为轨道不平顺引起的随机荷载向量.
1.2 基于虚拟激励法的时变系统随机振动分析
由式(3)、式(4)可知,车辆-轨道-地基土耦合系统的荷载向量由车辆自重引起的确定载荷FG(t)=[0]T及轨道不平顺引起的随机载荷FR(t)=[]T两部分组成,根据随机振动理论,随机激励FR(t)可表示为

式中:Γ(t)为作用力指示向量;x(t)为轨道不平顺引起的多点异相位平稳随机激励向量;d 为车辆子系统轮对总数.
假设时间积分开始时车辆的初始状态为静平衡状态,根据杜哈梅积分,车辆-轨道-地基土系统的位移向量U(t)可表示为

式中:H(t,τ)为系统的脉冲反应函数.假定轨道不平顺为零均值高斯随机过程[9],则

式中:E[·]为期望算子;μU(t)为仅由车辆重力荷载FG(τ)引起的位移U(t)的均值向量.
根据虚拟激励法,车辆-轨道-地基土系统的随机激励FR(τ)可以构造为均匀调制多点异相位非平稳随机响应的虚拟激励:

式中:Ω 表示激励圆频率,单位为rad/s;Sxx(Ω)为x(t)的自谱密度矩阵;tj为第1 个轮对和第j 个轮对之间的时滞.根据杜哈梅积分,由引起的虚拟响应可表示为

响应的功率谱密度矩阵SUU(Ω,t)可表示为
式中:上标“*”表示复共轭,则随机响应的标准差为

假定轨道不平顺功率谱密度的频域范围(Ω∈[Ωmin,Ωmax])被平均离散成m 个频点,在该频域范围内对每个频点进行计算.第j 个频点的功率谱密度SUU(Ωj,t)和标准差σU(t)响应可表示为

式中:ΔΩ 是频率的增量.
1.3 影响效率的核心计算步骤
由上述分析可知,每一时间步中计算由确定载荷FG(t)引起的均值μU(t)与随机载荷FR(t)引起的标准差σU(t)时,共需求解2m+1 个车辆-轨道-地基土耦合系统时变运动方程.
对于自由度数量庞大(设自由度总数为n)的车辆-轨道-地基土3D 有限元系统,采用逐步积分法中的隐式方法求解时变运动方程时,每一时间步的计算耗时主要集中在求解如(17)所示的系统等效静力平衡方程[13]上.

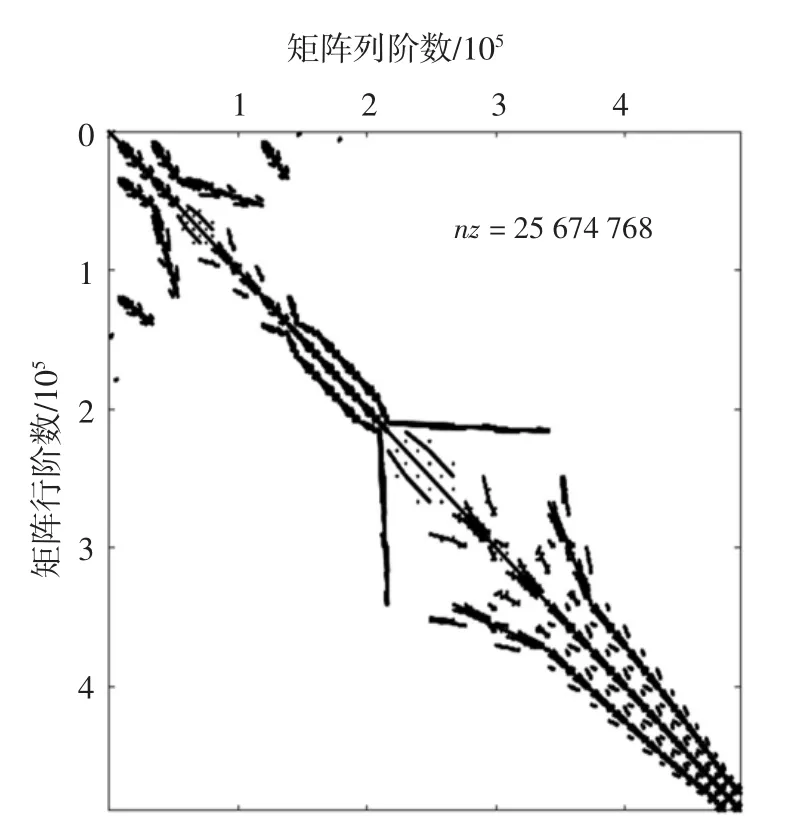
图2 等效刚度矩阵的非零元素分布Fig.2 Distribution of nonzero element of equivalent stiffness matrix
2 基于GPU 的耦合时变系统随机振动并行求解方法
使用虚拟激励法分析随机振动时,仍需求解一系列形如式(17)的等效静力平衡方程,该步骤巨大的计算耗时是3D 模型难以广泛用于随机振动分析的重要原因.根据并行系统的安姆达尔加速定律[17](Amdahl’s law),对该步骤进行并行化加速能获得更大的加速比.
2.1 基于GPU 的统一计算架构
CUDA(Compute Unified Device Architecture)平台是NVIDIA 公司于2006 年提出的GPU 通用计算编程接口,它大大简化了通用计算向GPU 上移植的难度,缩短了程序开发的周期.CUDA 称CPU 为主机(Host),称GPU 为设备(Device),使用GPU 设备进行并行计算主要包括3 个步骤:①在主机端与设备端分别分配计算数据所需的内存,将数据从主机端复制到设备端;②由设备端执行并行计算程序;③将计算结果数据从设备端复制到主机端.
基于CUDA 的并行计算是建立在CPU 和GPU协同工作的异构并行计算.如图3 所示,其中CPU主要负责程序中逻辑流程的控制及执行部分串行代码,GPU 负责执行大规模数据的并行计算部分.每个GPU 设备由若干个流处理器簇(SM)组成,每个SM配备多个流处理器(SP),在GPU 上执行的并行程序称为核函数(Kernel),其中规定了线程(Thread)的组织和内存的管理.线程是并行计算的基本构建块,CUDA 的编程模型将线程组合形成了线程束(Warp)、线程块(Block)以及线程网格(Grid).GPU 多线程的计算构架适合于大型3D 有限元模型分析中涉及的大规模矩阵运算等操作.

图3 基于CUDA 的异构并行计算示意图Fig.3 Heterogeneous parallel computing based on CUDA
2.2 等效静力平衡方程的并行求解
耦合系统随机振动分析中的等效静力平衡方程为大型稀疏线性方程组.线性方程组的解法一般分为直接法和迭代法,直接法经过有限步计算可得到方程组的精确解,但矩阵分解产生的大量填充元导致直接法的存储量较大.迭代法可利用矩阵稀疏的特性,因此所需的内存占用小且易于编程实现,被广泛用于大型稀疏线性方程组的求解,但需考虑计算精度和收敛速度的问题,一般来说,迭代循环的次数和计算时间随收敛精度取值的减小而增大.考虑到GPU 内存的限制和并行编程的难度,本文选用迭代法求解等效静力平衡方程.
3D 有限元方法形成的大型稀疏矩阵中含有大量不参与矩阵运算的零元素,图2 所示矩阵的稀疏度达到0.107‰,采用压缩存储的方式存储稀疏矩阵可大大减少迭代求解时的内存占用、避免额外的计算开销.为了满足3D 有限元法生成的无规则的系数矩阵,本文采用对矩阵结构无要求且适合并行编程的CSR 格式[18]存储等效刚度矩阵,该法对稀疏矩阵进行逐行压缩处理,只存储非零元素及其位置索引.对于一个包含nz 个非零元素的n×n 维稀疏矩阵,分别使用三个一维数组存储矩阵信息,如图4 所示.其中,Val 数组含nz 个元素,用于存储所有非零元素的值;RowPtr 数组含(n+1)个元素,用于存储矩阵每行首个非零元素在数组Val 中的位置;ColInd 数组含nz 个元素,用于存储每个非零元素所在列位置.程序中,Val 数组的数据类型设为双精度浮点型(double),RowPtr 和ColInd 数组的数据类型设为整型(int).
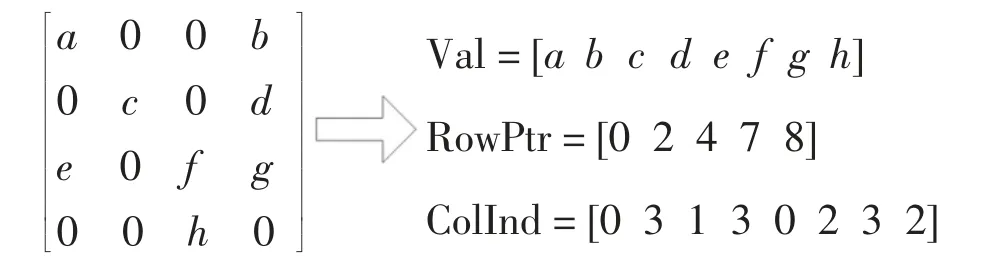
图4 行压缩存储格式Fig.4 Compressed sparse row format
针对图2 所示的系数矩阵对称正定的特征,采用Krylov 子空间迭代法中的共轭梯度法进行求解.为了改善迭代求解的收敛性能,采用矩阵预处理技术减少系数矩阵条件数、改善其病态特征从而加快收敛速度.常用的预处理技术包括Jacobi 预处理、不完全Cholesky 分解预处理(IC)、多项式预处理和对称超松弛预处理(SSOR)[19]等.本文采用的Jacobi 预处理是一种简单易行的预处理方法,能在不增加额外内存需求、通信开销小的前提下达到较好的收敛性能,从而提高计算效率.对于线性方程组Ax=b,取系数矩阵的对角项形成对角预处理矩阵,如(18)式所示:

采用预处理技术的共轭梯度法称为预处理共轭梯度法(PreconditionedConjugateGradientMethod,PCG).
PCG 法将等效静力平衡方程的求解转化为矩阵和向量间的运算,其中主要包括稀疏矩阵向量乘、向量更新和向量内积运算,它们都适合于利用GPU 进行的细粒度并行计算.基于CUDA 的并行PCG 法计算流程如表1 所示,其中Jacobi 预处理通过自编核函数实现,其余的矩阵向量运算通过调用CUBLAS和CUSPARSE 函数库实现.

表1 基于CUDA 的PCG 法计算流程Tab.1 PCG algorithms based on CUDA
2.3 耦合时变系统随机振动并行计算流程
采用耦合时变方法建立车辆-轨道-地基土耦合系统的动力方程,采用Newmark-β 法进行动力方程的数值求解.由于耦合系统的时变特征,等效刚度矩阵与等效荷载向量随时间步不断更新,每一时间步内,需将新生成的和采用CSR 格式压缩的传输至GPU 端,在GPU 端使用并行PCG 法求解等效静力平衡方程,然后将得到的位移矩阵U 传输回CPU端供其他响应和下一时间步的计算.车辆-轨道-地基土耦合时变系统随机振动分析的并行计算流程如图5 所示,其中虚线框内为每一时间步中CPU 和GPU 间数据交互的部分.

图5 基于GPU 的车辆-轨道-地基土耦合时变系统随机振动的并行计算流程图Fig.5 A parallel computing flow chart for random vibration of train-track-soil coupled time-varying system based on GPU
通过MATLAB-CUDA 混合平台开发了计算程序,其中CPU 端的程序在擅长矩阵数值运算的MATLAB 平台上编制,通过调用CUDA 程序在GPU端实现并行PCG 法求解等效静力平衡方程.其中,采用cudaMemcpy 函数实现CPU 和GPU 间的数据传输,通过NVIDIA Visual Profiler 软件进行CUDA程序的耗时分析.结果表明:对于本文研究对象,每一时间步内CPU 和GPU 间的数据传输时间小于0.5 s,占该步总计算时间的1%以内,因此数据传输对计算效率的影响较小,该并行计算流程适合本文耦合时变系统的随机动力分析.
MATLAB 中调用CUDA 并行程序的步骤如下:利用nvcc 编译器将CUDA 代码(.cu)编译成目标文件(.obj),使用mex 命令编译C++代码(.cpp)并将其链接到CUDA 目标文件(.obj),最终得到可执行的动态链接库文件(.mexw64).其中,CUDA 代码(.cu)完成了主机端和设备端间的数据传输和PCG 法的并行求解流程.C++代码(.cpp)中定义了被MATLAB 调用的外部子程序的入口地址、MATLAB 系统和子程序间传递的参数.
3 数值算例
3.1 有限元模型和计算参数
以京沪高铁某路基段试验场地为例,建立了如图6 所示的有限元模型,模型参数通过现场实测获得[20].为控制有限元模型的尺寸,除地表外的其他五个边界面采用3D 黏弹性人工边界[21]模拟半无限域场地.地基土参数、有限元模型横截面几何参数、有限元模型单元尺寸及车辆参数,参考文献[2]中数据.整个3D 有限元模型由210 686 个单元、193 135 个节点和542 002 个自由度组成,采用CSR 格式存储后的等效刚度矩阵所占内存仅为296.7 MB.

图6 轨道-路堤-地基土3D 有限元模型[2]Fig.6 3D finite element model of track-embankment-ground subsystem
本文算例仅考虑单线行车,车辆选取8 车编组的CRH3 型高速列车组,车速设为316 km/h.选取德国低干扰高低不平顺轨道谱作为随机激励,如图7所示取其空间频域范围为0.0125×2π~1×2π,并在该范围内等间距离散为100 个频点(即m=100).轨道-地基土系统有限元模型采用瑞利阻尼,阻尼比取0.05.时间积分步长为0.002 s,当考虑车辆的运行时间为4 s 时,总时间步为2 000.
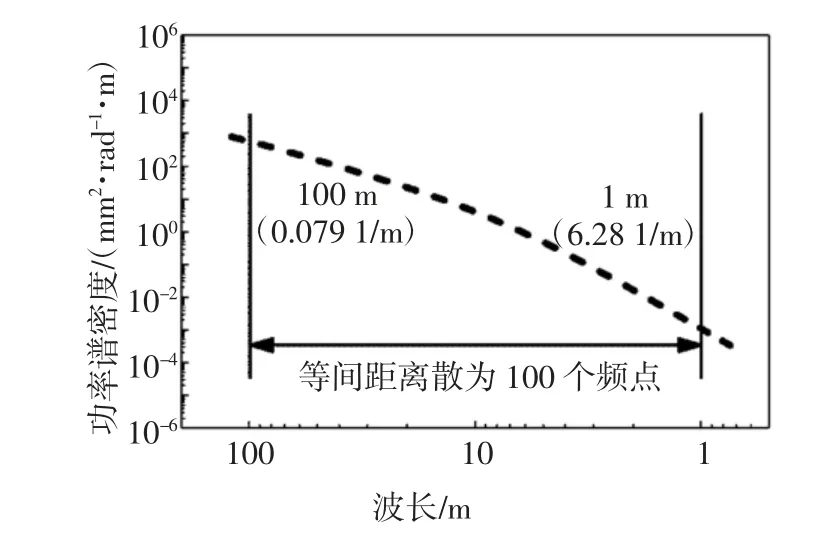
图7 所取的轨道不平顺功率谱密度及其空间频率截断范围Fig.7 The power spectrum density of track irregularity and its truncation range of spatial frequency
3.2 计算精度分析
为了验证本文方法的计算精度,考虑到PCG 法中迭代收敛精度ε 对车辆-轨道-地基土耦合系统3D 随机振动计算精度的影响,分别取ε 为10-7和10-6进行计算,并与文献[2]中串行的ANSYS 求解所得结果进行对比.选取了如图8 所示的A、B、C 和D四个采样点,它们与轨道中心线的距离分别是0 m、7.5 m、20 m 和40 m.本文所采用的计算平台参数如表2 所示.图9 和图10 分别给出了四个采样点竖向速度和竖向加速度标准差的ANSYS 求解和不同精度下本文方法计算的结果.

图8 采样点位置示意图[2]Fig.8 Diagram of sampling point location

表2 计算平台Tab.2 Computing platform
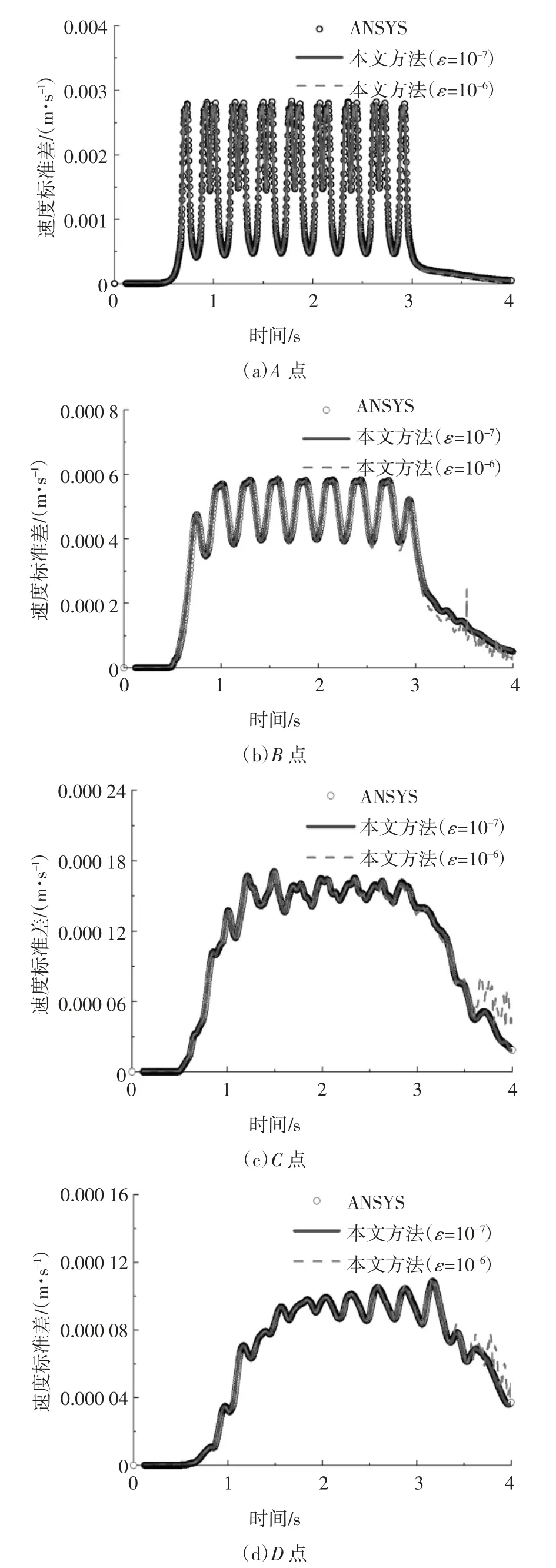
图9 不同方法的采样点竖向速度标准差计算结果对比Fig.9 Comparison of different methods of vertical velocity standard deviation of the sampling points
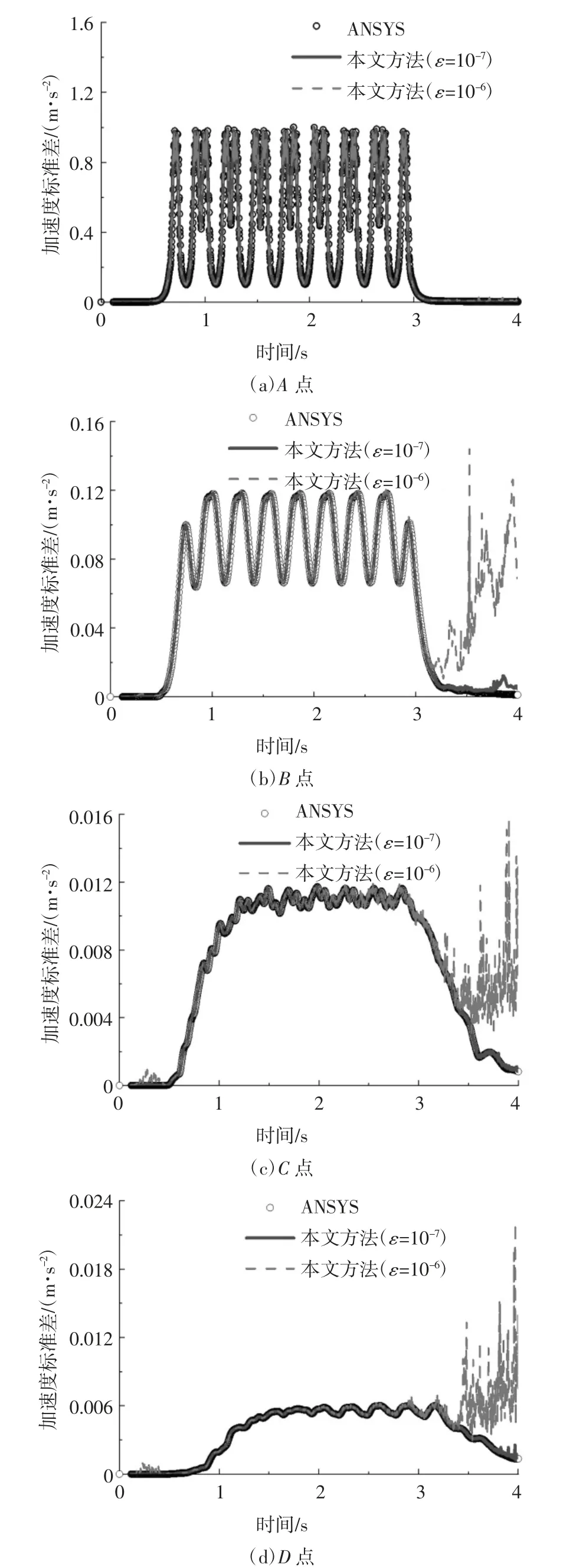
图10 不同方法的采样点竖向加速度标准差计算结果对比Fig.10 Comparison of different methods of vertical acceleration standard deviation of the sampling points
结果表明:
1)当收敛精度ε 取10-7时,本文方法所得四个采样点的计算结果与ANSYS 所得结果均吻合良好,具有较高的精度.
2)当收敛精度ε 取10-6时,A 点的计算结果吻合良好;3 s 后离轨道中心线较远的B、C 和D 点的竖向速度标准差轻微偏离,竖向加速度标准差严重偏离.经过分析,造成该现象的主要原因包括:①每一步的计算精度下降导致PCG 算法的截断误差随着时间步的积累效应逐渐显著.②3 s 之后振动响应的数值减小,同时距离轨道中心线越远的振动响应数值越小,此时计算机字长限制导致的舍入误差愈发明显.
3)加速度指标对收敛精度ε 的敏感性更高,采用PCG 法求解车辆-轨道-地基土耦合系统形成的大型稀疏线性方程组时,建议以加速度指标作为迭代收敛精度的控制指标;可通过选取适当的迭代收敛精度,以达到计算精度和计算效率的平衡,如当关注的振动范围较小时,取较大的ε 可减少迭代次数、缩短求解时间.
3.3 计算效率分析
为验证本文方法的高效性,采用表3 所示的3种不同方法求解车辆-轨道-地基土耦合系统3D 随机动力分析中的等效静力平衡方程.其中,Case 1 与Case 2 的计算方法相同,均采用文献[2]中填充元优化的串行多点同步算法;Case 3 采用本文提出的MATLAB-CUDA 混合编程的并行PCG 方法,迭代收敛精度ε 取10-7.Case 1 和Case 3 均在如表2 所示的计算平台上实施;Case 2 的计算平台硬件环境[2]为Intel Xeon E5-2620 CPU,内存为64 G.

表3 计算工况Tab.3 Calculation conditions
表4 给出了不同方法的计算效率对比结果,其中计算加速比以Case 1 一个时间步的计算耗时为基准计算得到.考虑到该算例完整的随机振动计算包含2 000 个时间步,而Case 1 的总计算时间预计可达180 d 左右,故未开展Case 1 的全过程计算.
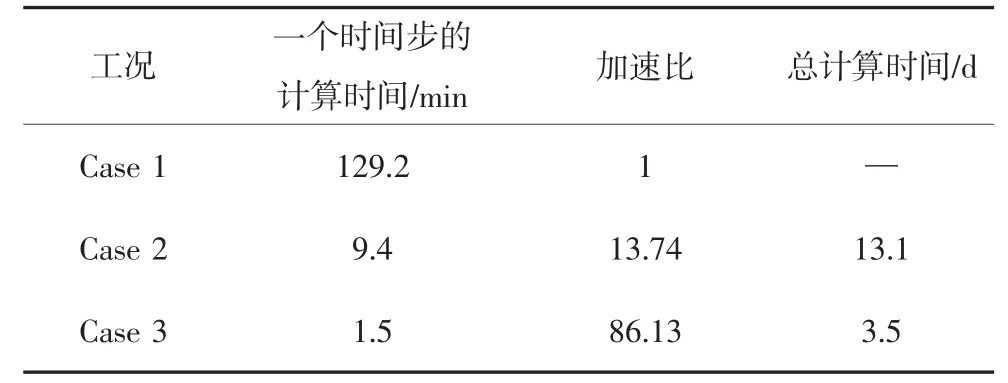
表4 计算效率对比Tab.4 Comparison of calculation efficiency
由表4 数据可得以下结论:
1)对比Case 1 和Case 3 可知,相同计算平台下计算一个时间步,本文方法的计算效率是多点同步算法的86.13 倍,大大减少了计算耗时,并将总计算时间减少到可接受的3.5 d.
2)对比Case 1 和Case 2 可知,多点同步算法在不同的计算平台实施时,Case 2 的计算效率是Case 1 的13.74 倍.主要原因是多点同步法[2]属于线性方程组解法中的直接法,对内存的需求大,在内存较小的计算机上使用直接法进行大规模3D 有限元方程求解时,会导致计算效率大幅降低.
3)对比Case 1、Case 2 和Case 3 可知,本文方法采用的稀疏矩阵CSR 压缩存储格式和预处理共轭梯度法有效降低了算法的内存需求、提高了计算效率,易于在一般个人计算机上实施计算分析.
4 结论
本文结合虚拟激励法与并行的预处理共轭梯度法两种高效算法,提出了一种基于GPU 求解车辆-轨道-地基土耦合系统3D 随机振动的并行计算方法.通过不同工况的对比分析,得出以下结论与建议:
1)本文方法将GPU 并行计算技术应用于车辆-轨道-地基土耦合系统3D 随机振动分析,在保证精度的前提下大大提升了计算效率,且对计算机内存的需求小,在一般个人计算机的硬件配置下就能达到较好的计算效率提升,有利于3D 模型在随机振动分析中的推广应用.
2)在工程设计中,本文方法有助于更快速地对铁路运输引起的环境振动问题进行评估.例如,使用本文所得结果同时结合3σ 法则可高效地确定车辆-轨道-地基土耦合系统随机响应的上下限值.
3)本文方法结合了不同计算平台的优势,采用商业数学软件MATLAB 串行处理随机振动计算涉及的大部分运算及计算流程中的各种逻辑控制,通过CUDA 调用GPU 实现系统等效静力方程的高效并行求解.
4)采用PCG 法求解车辆-轨道-地基土耦合系统形成的大型稀疏线性方程组时,建议以加速度指标作为计算精度的控制指标.同时可通过选取适当的迭代收敛精度ε,以达到计算精度和计算效率的平衡.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28 07:02:46
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19 08:28:36
空间科学学报(2020年6期)2020-07-21 05:37:04
空间科学学报(2020年6期)2020-01-08 16:50:22
环球时报(2019-12-05)2019-12-05 05:13:15
制导与引信(2017年3期)2017-11-02 05:16:56
高中生学习·高三版(2016年9期)2016-05-14 09:12:05
工业设计(2016年11期)2016-04-16 02:50:19
新高考·高二数学(2015年11期)2015-12-23 18:17:44
环境科技(2015年6期)2015-11-08 11:14:26
