
基于深度卷积神经网络的多字体印刷体汉字识别
2021-07-23 13:07杨艳华
三明学院学报 2021年3期
杨艳华
(集美大学 计算机工程学院,福建 厦门 361021)
文字识别在信件包裹的分拣、统计报表的录入分析、各类证件识别、车牌识别、道路识别等实际场景中有着广泛的应用。如何让计算机高效地理解图片上的文字信息,尤其是印刷体汉字信息,是文字识别领域的重要问题。
印刷体汉字识别技术源于国外,最早是1966年由美国的IBM公司运用模板匹配法完成了1000个印刷体汉字的识别[1]。20世纪70年代末,我国开始汉字识别的研究,从最初的仅局限于有限的、规则汉字的识别,到利用计算机实现对各种文字、各种印刷体和复杂图文版面的自动识别和理解,经过几十年的深入研究,已经取得了丰硕的成果[2-3]。然而,由于汉字内部结构复杂、字体多样、字符笔画相似度高等特点,使得对其识别研究工作仍然面临巨大的挑战。
2006年,加拿大学者杰弗里·辛顿和他的学生鲁斯兰提出深度学习的概念,近几年其在语音识别、文本检测和识别、图像识别等多类应用中取得了显著的进展。深度学习以原始样本数据为基础,通过特定的训练方法得到一个由多个非线性处理层构成的深度网络的机器学习过程[4],它是人工神经网络的一种延伸,通过低级到高级逐层提取数据特征的过程找到所述特征数据的分布式表示。与传统的神经网络不同,深度神经网络采用自下而上的无监督学习特征的方式来优化网络权重的初值,然后再自顶而下对权重进行微调,这样就避免了局部最小值的收敛问题[5]。卷积神经网络(convolutional neural network,CNN)是常见的深度神经网之一,比较适合二维图像的处理。
卷积神经网络自动提取输入的原始图像的特征,它提取的特征不受旋转、平移和缩放等形变的影响,被广泛应用在文字识别上。2012年Ciregan等人在文献[6]中提出了一种多列卷积神经网络模型,该模型对脱机手写体汉字的识别率达到了93.50%,但该样本库只包含手写体汉字,且网络模型较复杂,参数调整难度大。2013年Lan Goodfellow提出的基于CNN模型的算法将文字定位、分割和识别结合在一起,能够不受约束地识别自然照片中的字符[7],然而该模型需要提前选定可预测序列的最大长度,且对字体的大小和文字的质量要求较高,当字符数量较多时算法性能显著下降。文献[8]采用多尺度滑动窗提取文字特征,再结合深度神经网络的方法对印刷体汉字进行识别,该方法需要进行繁琐的特征提取和降维预处理。Shi等[9]提出CRNN(convolution recurrent neural network)模型,通过深度卷积神经网络学习文字特征,再结合BiLSTM(bi-directional long shot-term memory)循环网络预测序列标签,在文字识别率上有极大的提高,然而该模型需要占用更多的内存空间等资源,且训练时间较长。
上述这些方法都不能很好地解决印刷体汉字识别的应用问题。因此,本文定义了一种改进的卷积神经网络模型对多字体印刷体汉字进行训练分类。为了获得大规模训练的样本数据,避免过拟合现象出现,采用了多种数据增广方式;为有效缓解训练中数据分布改变的情况、加快网络收敛速度,并对中间数据进行批标准化(batch normalization,BN)处理。此外,为了更好地优化网络的训练过程,运用了自适应矩估计(adaptive moment estimation,Adam)优化算法。通过一系列实验,验证了本文定义的模型在多字体印刷体汉字识别中的有效性。
1 字符集生成
模型的训练需要足够大量的数据,本文对国标一级字库共3755个汉字进行识别,使用一系列措施增加训练样本。训练样本数据是用Python和OpenCV编写程序让计算机自动生成的单个汉字图像。为进一步增强泛化能力,本文对每个汉字生成了黑体、仿宋、隶书、幼圆、华文隶书、华文细黑、华文新魏、方正姚体、方正粗黑宋简体等十二种字体的图片,同时再设置±30°的旋转角度,使用Python中 PIL(python image library)库的Image模块中的汉字生成函数生成字体源图片。源图片生成过程如图1所示。
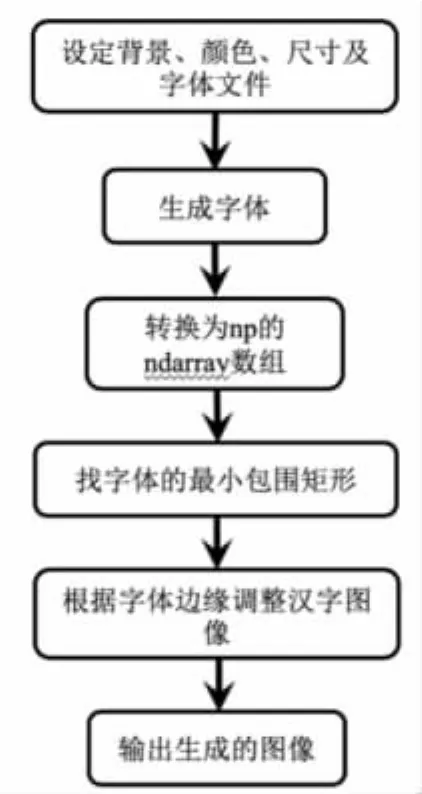
图1 字体源图片生成流程
上述每种字体只生成了一张图片,单个汉字只有12张图片,这样的数量还远远不够。因此,需要在该数据集上进行数据增广,以扩充训练数据集。本文采用的数据增广方法具体如下。
(1)扭曲增广,是对原图像做透视变换,用一个3×3的变换矩阵进行矩阵乘法运算来变换原图像的坐标,透视变换矩阵如式(1)

其中,A为变换矩阵,如式(2)

对图像进行扭曲操作,就是对像素坐标进行透视变换。令a33=1,源像素点坐标(x,y)经变换后的目标点坐标(X',Y')的计算公式如式(3)和式(4)。
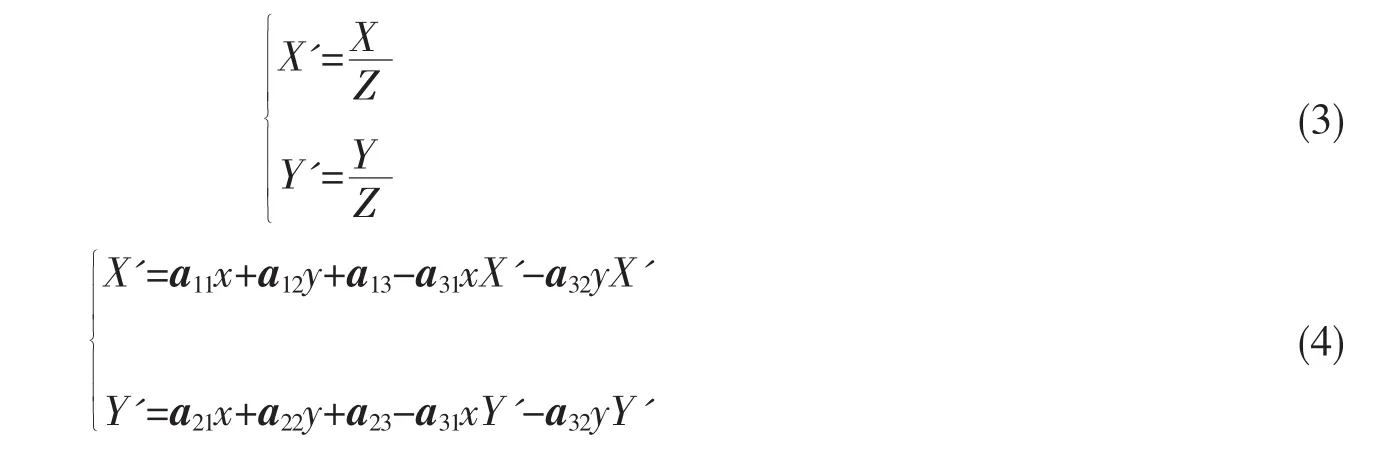
先求出变换矩阵A,需要给出源图像的4个固定点(xi,yi)(i=1,2,3,4)和目标图像的4个固定点(X'j,Y'j)(j=1,2,3,4),调用 OpenCV的 cv. getPerspectiveTransform()函数求解矩阵 A,再使用 cv.wrapPerspective()函数实现扭曲操作。
(2)噪点增加,先设置添加的椒盐噪声比例20%~30%,然后再调用随机函数np.random.randint()生成噪声点的坐标,最后将该坐标点的像素赋值为噪声像素值。
(3)波纹变换,通过改变正弦函数x=Asin(2πx/T)和余弦函数y=Acos(2πy/T)的幅值 A、周期T等参数实现。
(4)腐蚀和膨胀,通过一个3×3的正方形蒙板内核对源图像进行卷积运算。膨胀和腐蚀运算分别如式(5)和式(6)。

其中膨胀运算时,A是源图像,B是蒙板内核,先求出B关于其中心点的反射集合B,再用B在图像A上平移y,如果的像素与A至少有一个像素相交,则保留中心点对应的像素点,以达到边界外扩的效果,调用cv.dilate()函数实现。腐蚀运算时,用B在图像A上平移y,如果B的中心点对应的像素完全相同,则保留A图上的像素点,否则全部删除,以达到边界内收的效果,调用cv.erode()函数实现。
以“啊”字为例,数据增广后的示例如图2所示。本文一共生成5 497 320张100×100像素大小的样本图片,抽取其中的20%构成test集合,剩下的构成train集合。

图2 数据增广后的示例
2 深度卷积神经网络模型
在经典LeNet-5模型基础上,本文通过增加卷积层和池化层,扩展得到的印刷体汉字识别网络模型结构如图3所示,主要由5个卷积层、4个池化层、2个全连接层和一个Softmax回归层组成。

图3 深度卷积神经网络模型
整个模型进行特征提取和分类的过程如下:
(1)输入层是一幅100×100像素大小的汉字样本图片。
(2)卷积层使用了3×3的卷积核对图片进行固定步长的卷积操作,通过图片像素和卷积核权重值做乘法,并逐层增加卷积核深度,得到相应的特征输出。卷积操作的计算如式(7)。

(3)接入2×2的正方形池化窗口的最大池化层,取图像每个窗口区域的最大值,避免过拟合现象,并简化整个网络的计算复杂度。计算过程如式(8)。

其中,N是池化窗口大小,u(n,n)为池化窗口。
以上(2)~(3)的一系列卷积和池化操作后,得到512幅4×4像素大小的特征图。
(4)经过两个全连接层将图片不同位置的特征进行整合后,接入Softmax层分类输出。对于有K类分类的情况,设每类有n个样本的训练集合为{(x(1),y(1)),(x(2),y(2)),…,(x(n),y(n))},其中,x(i)为特征向量,y(i)∈{1,2,…,K}为样本类别标签。首先,定义回归函数如式(9)。

其中,wk为第k类的模型参数。
然后,计算每个样本的所属类别概率p(y(i)=k|x(i);w1,…,wK)。用一个K维的标签向量表示这k类概率值,即样本x(i)概率为。 其中,y(i)=(yi1,…,yik,…,yiK)T为 x 的标签向量。 注意,在式(9)中采用对概率分布进行归一化处理,使得所有概率之和为1。
接着用极大似然估计法估计模型参数wi,定义目标函数如式(10)。

用Adam优化算法求该目标函数的最优解,并在传播中不断调整网络权值,实现训练。
两个全连接层分别采用1 024个神经元和3 755个神经元提取输入图片高层特征表示,整个网络的参数有16 200 208个。完整网络配置参数如表1所示。

表1 网络配置的详细参数
由于本文模型层次较深,因此在所有卷积层和全连接层之后都加入了批标准化处理层,这样可以有效纠正中间输入分布的偏移情况,加速模型收敛。设每一层的输入是一个d维向量,即x=(x(1),x(2),…,x(d)),并且一个mini-batch包含有m个训练实例,即B={x1,….,xm}。BN的处理过程如下:
(1)对每一个输入激活x(k)进行变换。首先计算mini-batch的平均值和方差,然后进行变换。 经过这一变换后,每个输入激活就形成了均值为0,方差为1的正态分布。
从表1的配置可知,本文网络中BN层设置在激活函数之前,并且BN层也采用共享权重的策略,把一张特征图当做一个神经元处理。则整个网络隐藏层前向传播算法的计算如式(11)。

其中:W、b分别为当前层的权重和偏置;g(·)为激活函数;u为BN层的输入;z为当前层的输出。
3 实验与分析
3.1 模型训练
本文实验系统是基于TensorFlow[10]深度学习框架,用Python语言构建的。硬件环境为Intel CoreTMi5-4210M、NVIDIA GeForce GTX 960M GPU;操作系统为Windows7 64位;软件配置为CUDA 8.0、TensorFlow 1.14、Python 3.6.2、OpenCV 2.4.2.0。
模型训练采取分步法进行,将前面生成的样本图片集分为训练集、验证集、测试集三部分,验证集图片数量为训练集图片中随机挑选出的四分之一。设定验证步数为100步,模型的存储步数为500 步,最大训练迭代步数 16 000 步;Adam 优化器的参数[11]为:b1=0.9,b2=0.999,h=0.01,e=10-8。经过多次实验,最终确定batch_size为128,学习率为0.1,训练过程中loss和accuracy变化曲线如图4所示。
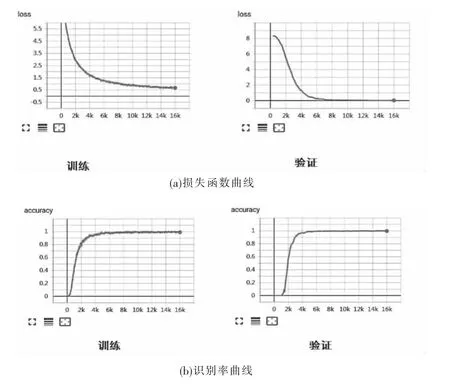
图4 训练集和验证集上loss和accuracy变化曲线
从图4可以看出,训练的accuracy曲线和验证的accuracy曲线趋势基本一致,准确率(分对的样本数/总的样本数)都接近1;训练的loss曲线和验证的loss曲线也相差无几,验证loss曲线接近于0。表明模型训练超参数设置得不错,该模型已经可以很好拟合汉字识别训练集。
3.2 算法验证及结果分析
为了确定模型的准确性,本文从3个方面进行验证:测试集、不同模型和不同算法。实验评价指标采用Top1准确率、Top5准确率、识别率和训练时间。
(1)在测试集上验证
将本文模型在测试集数据上进行性能评估,计算Top1(即准确率)和Top5(测试集中正确标签包含在前5个分类概率中的个数/总的测试集),对模型的正确性进行验证。测试集图片是裁剪出来的单字图片,使用本文训练的模型进行识别,通过统计识别正确的字符和识别错误的字符的数量,得到Top1准确率为99.864%,Top 5准确率为99.948%。评估结果如表2所示。

表2 测试集上本文模型的验证结果
(2)不同模型的识别率对比
将本文模型与其他深度学习汉字识别模型对比,各模型识别率如表3所示。其中文献[8]以卷积神经网络为分类器,通过提取文字图像的多尺度梯度特征,网络的识别率达到了98.292%。文献[12]采用7层卷积神经网络,减少了特征提取的过程,识别率达到98.336%。文献[13]中采用暗区域文字图像增强算法免去文字分割,再结合CTC(connectionist temporal classification)解码预测字符串序列,系统识别率达到98.71%。文献[14]以MNIST(mixed national institute of standards and technology database)网络为基础,经过参数调制和SGD(stochastic gradient descent)优化算法设计的卷积神经网络,在测试集上的识别率高达99.955%,但是该模型对多字体的识别率只有98.85%。本文采用了更深的12层卷积神经网络模型,并且在训练中加入了优化算法,对多字体的识别率显著提高。
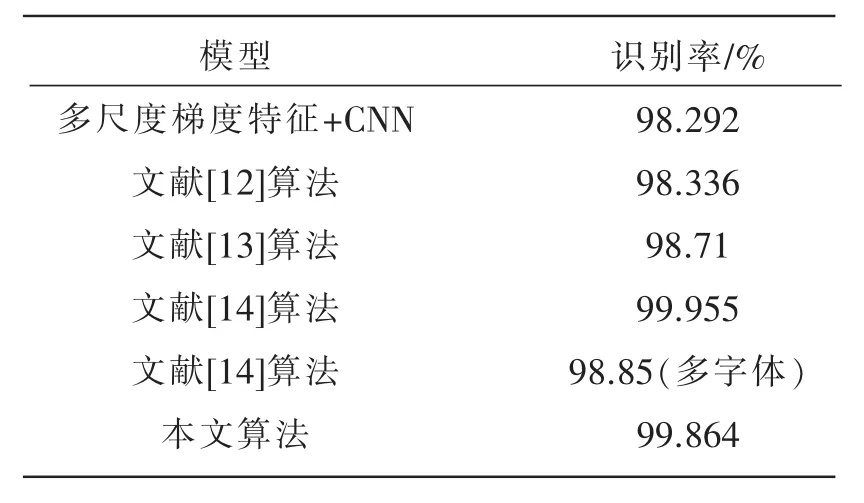
表3 不同模型的识别率比较
(3)不同算法验证
本实验中,为了讨论批标准化、不同优化算法、和数据增广对模型识别率和时间的影响,分别做了几组对比实验,设置训练的batch_size为128。实验结果如表4所示。
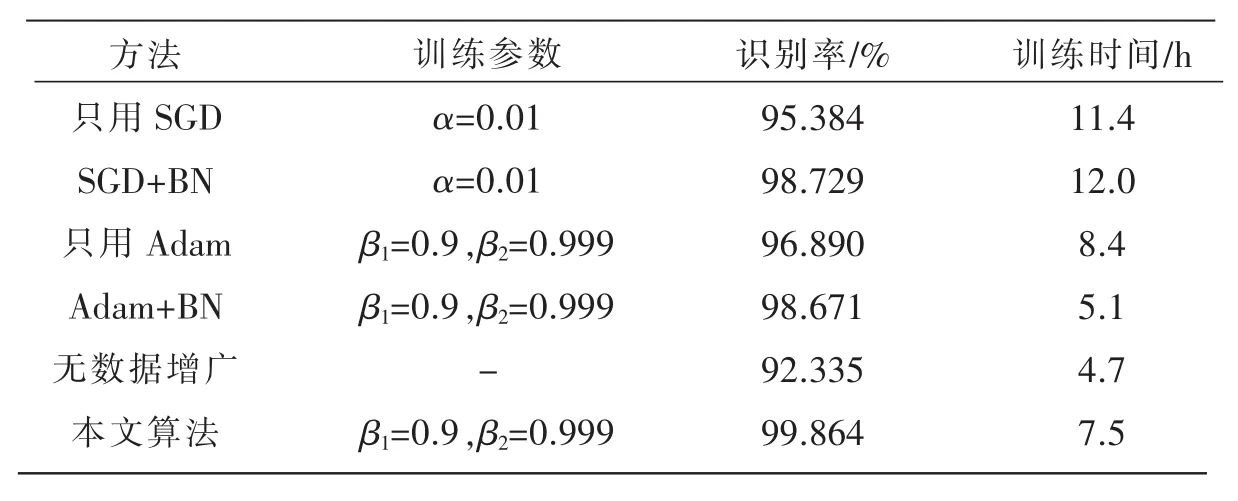
表4 不同算法的训练结果对比
从表4的结果可以看出,不使用数据增广的情况下,训练的时间最短,但是由于样本数量不充分,识别率较低。只使用SGD时需要设置好的学习率和初始化调整方案,能达到较好的识别效果,但是很耗时。使用自适应矩估计优化算法的训练时间较短些,但是识别效果欠佳。批标准化的引入减少了迭代的次数,使得训练时间显著减少,并且能够在整体上提升识别率和模型的泛化能力;使用数据增广对样本数据进行扩充,能够有效防止网络过拟合、提高识别率。本文模型在保证较高的识别率前提下,训练时间也有较大缩短。
4 结论
本文基于印刷体汉字的识别特点,对经典的LeNet-5模型进行一系列的改良,构建了一个12层的深度卷积神经网络模型,使用该模型可以很好地识别多种字体的印刷体汉字。在本文的模型中综合运用数据增广、批标准化处理和Adam优化算法等策略进行训练,通过各种实验验证了网络模型的有效性。实验结果表明,越深的网络结构在提高识别率上有很大的作用,但是训练的时间也会延长;运用批标准化处理可以减少迭代次数,这样整体上加快了训练速度;优化方法的运用也很重要。本文模型可以应用于身份证汉字的识别、车牌识别、盲人阅读器等应用场景。
今后研究需要改进和提高的主要有四个方面:(1)引入迁移学习和微调方法,先通过预训练模型进行数据特征的提取,再对训练模型进行微调,以提高汉字数据集的识别率;(2)增加二级字库中的3008个汉字到源图片库,扩大训练样本的数量,研究识别率提高的效果;(3)尝试更深的训练网络和深度学习框架,如Inception-ResNet和Pytorch等;(4)结合嵌入式系统进行移动场景中的识别研究。
猜你喜欢
小哥白尼(军事科学)(2022年2期)2022-05-25
美与时代·美术学刊(2020年7期)2020-10-13
校园英语·月末(2020年4期)2020-06-08
红领巾·萌芽(2019年8期)2019-08-27
中国听力语言康复科学杂志(2019年3期)2019-06-24
听力学及言语疾病杂志(2019年3期)2019-05-24
中国交通信息化(2018年3期)2018-06-13
中国与非洲(法文版)(2017年10期)2017-11-23
中学生天地·高中学习版(2016年4期)2016-11-19
中国交通信息化(2016年2期)2016-06-06
