
基于语音识别及自然语言处理对话流的人机智能交互方法研究
2021-07-22 03:13许士锦范展滔邱生敏
机械与电子 2021年7期
许士锦,范展滔,邱生敏,张 坤
(中国南方电网有限责任公司电力调度控制中心,广东 广州 510600)
0 引言
人工智能技术在电力系统中的应用逐渐扩大,通过传统方法的智能化,提供关键技术的延伸和创新,融合多种智能方案,可以实现电力系统乃至整个能源行业的商业模式的变革。人机语音交互是电力系统中推动数字化和网络化运行的重要手段之一,因此人机语音交互是人工智能技术中的重要应用。利用人机语音交互技术,能够实施计划检修申请单批复、网络化下发指令、电子公告牌、故障汇报和生产信息汇报等关于调度指挥内容的具体工作。
目前,针对语音识别在电力系统人机交互中的应用研究较少。文献[1]提出了变电站二次测试中智能语音控制关键技术;文献[2]提出了基于人工智能深度学习的语音识别方法;文献[3]针对基于卷积神经网络的语音识别研究进行了研究;文献[4]提出了智能语音识别方法在电力移动作业平台中的应用;文献[5]针对深度学习在语音识别中的研究进展进行了分析;文献[6]分析了关键词识别中语音确认技术。
为此,本文提出了基于语音识别及自然语言处理的人机对话智能交互方法。
1 人机语音交互及其在电力系统中的应用
1.1 人机语音交互和人工智能技术
人工智能技术是用于模拟、延伸和扩展人类智能思维和解决方式的一种新兴科学技术,主要包括机器人、自然语言处理、图像识别、语音识别和专家系统等。人工智能技术的实现主要是通过基于现有逻辑方法和统计运算等技术的仿生模拟。
目前,人类进行的交流是基于事实、真实感受到的事物进行的,因此,利用人机交互实现人类和机器之间的通信也需要将自然语言进行解析,从而将人类语言转换成机器能够真实感受到的语言。因此,语境解析是人机交互中的重要手段,利用相关的知识图谱、事物组合图谱可以实现在语境解析的基础上进行人类语言的深度剖析,从而为计算机提供强有力的解析数据。
自然语言处理是计算机科学中的主要内容之一,其研究方向在于机器和人类语言之间的相互作用。因此,自然语言处理与人际交互具有密切相关性。在自然语言处理中,主要体现为自然语言理解和执行。因此,自然语言处理是实现人机交互的基本过程。在自然语言处理中,需要对自然语言进行深度学习和语意剖析,让计算机读懂人类语言以及人类行为的意思,并且与其他涉及的语言进行比对。
1.2 人机语音交互在电力调度中的应用
人机语音交互技术在电力系统调度中的应用,主要体现在将调度运行人员的专业调度数据转化为计算机能够理解识别的机器语言,从而实现人类指令下发至计算机得到有效执行。电力系统调度信息包括结构化数据和非结构化数据。对于非结构化数据的语义分析,需要建立结构化数据和非结构化数据统一的数据索引方式,这也是机器识别人类语言进行进一步分析的关键难点。
由于电网设备信息较多,又涉及到检修信息、设备故障信息、调度日志信息、设备缺陷信息、组织机构信息、调度规程信息、运行细则信息和投入审批信息等电网调控信息,因此,首先需要利用自然语言处理技术,结合电力调控的关键性业务,将自然语言处理的结果映射到电网调度操作的流程中,对电力相关业务的文档和信息进行归纳,实现分词的数据库建立。结合现有电力业务知识库模型,对分词的拆分结果进行语义分析,将自然语言解析分解,并针对电网业务的语义重构,实现人机交互的语音识别和语义分析。
2 人机语音交互技术
2.1 自然语言处理技术
自然语言处理技术是实现人机语音交互的重要手段,其主要技术包括分词、词性标注、命名实体识别、依存句法分析、语义角色标注和特定语境语义解析。处理技术如图1所示。

图1 自然语言处理技术
分词是将人类的语音输出序列划分成计算机能够批量处理的词语序列的过程。在多种语言中,词语是承载话语含义的基本单元。因此,将重要的词语进行信息检索、信息分类和语义分析,有助于实现机器理解人类语言的功能和任务。由于某些单词在不同的语境中具有一定歧义,因此,切分歧义是分词任务中的主要难题,需要将分词模块置于机器学习框架中,通过广泛读取历史数据,形成分词数据库,形成词典策略来解决同一词语在不同语境中的含义分析。
词性标注是赋予语句中单词词性的过程。词性是语义分析中的基本内容,通过辨别词性能够快速、有效地分解语句中的词语,理解语句中的语言形式和词语构成,从而更准确地理解句子含义。
命名实体识别是指从语言文本中提取具有特定类别的实体名词。实体命名识别是机器语言信息检索、语义查询、语义分析等基本过程,其处理效果直接影响到整体的语义理解和分析。针对电力系统调度,命名实体识别主要的对象是电网设备名称、操作票主要内容、网络和设备运行状态变化等名词,方便人机语音沟通及交互后的指令下发和对象处理等。
依存语法是通过对单词成分理解基础上的更高层次的语言成分关系分析,可以直接揭示不同语句之间句法结构的关系。通过研究复杂语句可以实现依存语法的良好感知和识别,从而更加准确地识别较长、较复杂的人类语言。
语义角色标注是一种浅层的语义分析技术,根据给定句子中的某些短语为分析内容,判断句子成分的语义角色,包括主语、谓语、宾语、时间和地点等。语义角色标注是实现语言灵活化和丰富化处理的重要技术,能够对问答系统、信息抽取和机器翻译等应用提供相关的决策性支撑。
语义依存分析能够实现不同句子之间的语言单位间的语义关联,并且清晰地呈现关联的依存结构。利用语义依存分析能够省去对抽象词汇的分析和理解,利用语言所承载的语义框架来描绘抽象词语与其他词语之间的联系,减少语义依存分析的时间,提高跨越句子表层句法结构的分析效率,从而直接获取句子的深层语义信息。
2.2 基于具体应用语境的自然语言处理
基于具体应用语境的自然语言处理,主要包括基于事物组合图谱寻找语言语境中的类似事物组合场景、用类似事物场景的属性理解相应话语场景、调取知识图谱或事物组合图谱进行深入数据分析。处理流程如图2所示。

图2 基于具体语境的自然语言处理
通过应用语境的分析,可以对语义图画所展现的内容进行联想,这类联想会扩展语义的数量,如果将语境所有事物按照可能性组合进行分类,可以提取相关类似场景,进行归纳分析后,得到最有可能表达的含义,从而实现人类语言到机器语言的筛选和识别过程。在语境中的事物出现多种组合时,应当具体分析每一种语义的组合形式,通过纠错机制,对具有理解失误的语言进行纠正,替换成正确的语义,可以实现语境分析引擎的快速搜索和智能识别。
3 基于语音识别的人机交互模型
3.1 关键算法
人机语音交互的过程是复杂的,需要多项技术融合完成。归一化是其中的关键技术之一,通过对多种特性进行平均值抽取,并且分离得到标准偏差,用于进一步分析和计算。将收集到的人类自然语言进行特征提取和分析,通过归一化就可以应用于人机交互的具体分析流程。
3.1.1 梯度提升
梯度提升能够生成弱预测模型,包括损失函数、弱学习器和附加模型[7]。梯度提升的框架是利用差分化的损失函数。弱学习器能够生成决策树。为了减少损失,通过贪婪法则将得分最佳的数进行分类组合,实现过拟合算法。弱学习器还可以为节点、树枝和树叶节点等提供约束条件。
附加模型需要每次加载至生成树。梯度提升的过程是在扩大数的同时减少损失。因此,在每一步骤中需要计算损失,计算完成后,对损失削减贡献最大的数被选中,并且更新权重。对于梯度提升分类器,应用scikit-learn模型实现语音识别。通过过拟合算法实现对样本的数据训练,数据样本越大,训练效果越好。未找到最佳估计器时,需要对训练数据进行测试。找到最佳值之后,将分类器与训练数据匹配。
3.1.2 支持向量机
支持向量机是一种机器学习算法,能够解决回归和分类问题。支持向量机是一种由分隔超平面定义的分类器,其本质是选择合适的分割超平面来对数据进行分类,分类的结果是二值决策结果。由于大部分分类任务都较为复杂,因此很难找到完美的超平面。支持向量机则利用核函数将数据映射到另一维度,更好地求取数据的边距。放射核可以生成复杂的空间区域来更好地对数据进行分类。另外,还有规则化等其他方法来代替核函数法。
3.1.3k最近邻
k最近邻是另一种机器学习方法,也可以求解回归预测问题。k最近邻能够存储整个数据集,不需要对数据进行训练。对于新的样本,在部分样本数据的情况下便可对k最近邻值进行预测,并求出结果。为了实现历史数据的k值能够应用于新的样本,需要计算距离量测值。一般使用欧几里得距离,并且还需要对训练数据进行部分测试来进行评估。找到最佳值后,将测试数据的需要信息整理成相关文件。
利用上述算法的语音识别流程如图3所示。

图3 语音识别流程
语音训练过程如图4所示。
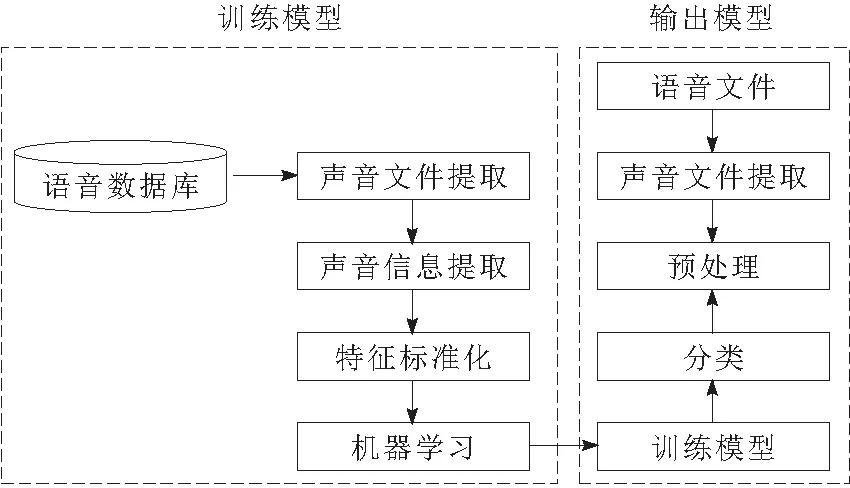
图4 语音训练过程
3.2 模型架构
本文构建的基于语音识别的人机交互架构如图5所示。

图5 系统架构
本文所提系统构架包括数据融合层、数据分析层、应用管理层和移动终端。数据融合层是将电力系统基础数据和调度人员、运维人员声音库、历史数据和外部数据进行融合的层级。其中,电力系统数据主要包括设备参数和拓扑结构。
数据分析层是针对融合后的数据进行分析,包括公共模型和电力系统模型,对应的算法是通用算法和特殊算法,其中由于电力系统模型的特殊性需要,采用具有针对性的算法,对电力系统人机智能交互进行处理。
管理应用层是针对数据分析结果的应用,包括语音应用管理、数据分析共享、电网态势维护和运维信息交互等应用管理,能够充分利用智能人机交互的方式,体现大数据和语音识别背景下的人机交互动态过程,对电网信息进行展示和维护。
移动端是针对调度人员和运维人员特殊制定的语音识别和信息展示的移动终端,能够直接识别运行人员的语音,并将其转化为可直接下发的指令。
3.3 人机语音交互方法
人机语音交互中的语义理解是问题的关键,一般利用自动语音识别和语言理解技术,即将语音信号转化为可执行指令的过程。如果语义理解出现问题,则系统执行出现问题。
首先,自动语音识别识别得到用户语音信号序列。通过提取语音信号中的关键信息,得到t=1至t=T时段的语音序列x。接着,解码器对语音序列进行解码,可以利用贝叶斯决策规则,公式为
(1)
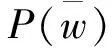
自动语音识别能够对语句中的关键词语进行组合,能够最小化误字率。但是对于训练样本不足的情况,需要应用词语模型,而非单字模型,这样可以提高语音识别正确率。自动语音识别过程如图6所示。
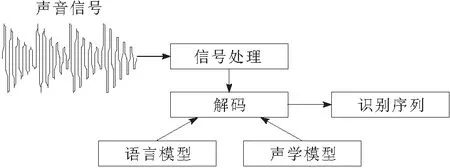
图6 自动语音识别过程
交互过程中应用的模型包括层次语言模型和声学模型。
a.层次语言模型。n-gram是一种基于统计语言模型的算法。它的基本思想是将文本里面的内容按照字节进行大小为n的滑动窗口操作,形成长度是n的字节片段序列。n-gram预测仅仅捕捉词类之间的关系,并且默认词语间的转换概率仅取决于词类。该特点降低了自动语音识别的性能。目前有较多技术可以避免这一问题。可以将词组和词序嵌入n-gram词类,而不是嵌入孤立的字词。这样,可以利用层次语言模型对语义进行预测。在最高层,n-gram语言模型可以用于学习句子结构,并对未来语句进行预测。第2层中,在每一类中生成单字n-gram语言模型,抓取字与字之间的关系。
b.声学模型。目前声学模型一般基于隐马尔可夫链。隐马尔可夫模型是利用马尔科夫模型的一种统计预测方法[8]。被观测事件序列的参数由声学信号进行提取,并假设一系列隐藏状态可以生成这类信号。单词的隐马尔可夫模型如图7所示。
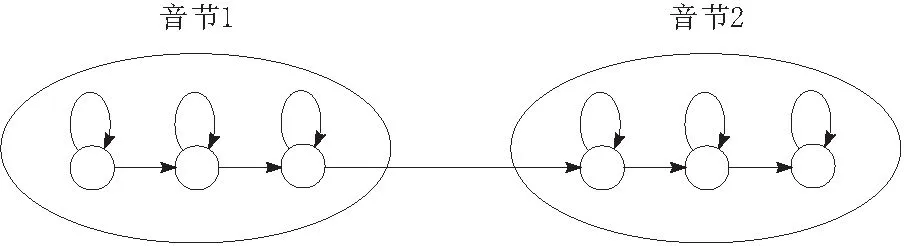
图7 隐马尔科夫模型
3.4 实验分析
以某地区调度人机交互指令下发为背景,对传统电话调度和人机交互调度结果进行对比,实验数据如表1所示。
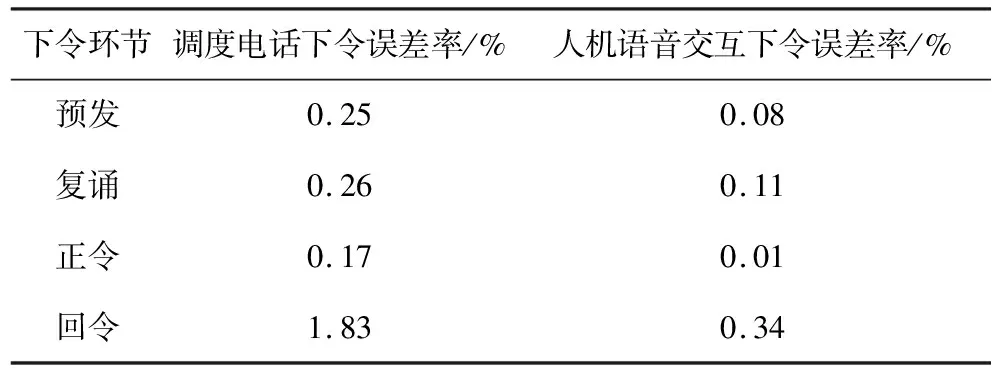
表1 人机交互下令与传统下令数据对比
由表1可以看出,本文所提的人机语音交互方法,在很大程度上提高调度指令下发各环节的准确率,有效提高了工作效率。
4 结束语
本文重点分析了人机语音交互技术,建立了人机语音交互的模型和算法。针对梯度提升、支持向量机和k最近邻等算法进行了详细说明,并分析了语音识别流程和语音训练过程。针对人际语音交互方法,提出了自动语音识别技术,利用语言模型和声学模型实现交互的过程。
猜你喜欢
青少年科技博览(中学版)(2022年6期)2022-08-31
南都周刊(2021年3期)2021-04-22
开放教育研究(2020年2期)2020-03-31
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
电子制作(2019年9期)2019-05-30
小说界(2018年5期)2018-11-26
海外星云(2016年7期)2016-12-01
太空探索(2016年5期)2016-07-12
现代语文(2016年21期)2016-05-25
