
基于ICP-MS和机器学习的速食面识别研究
2021-07-20 05:53:44吕铷麟何洪源贾镇王书樾何伟文
应用化工 2021年6期
吕铷麟,何洪源,贾镇,王书樾,何伟文
(中国人民公安大学 侦查学院,北京 100083)
速食面是一种烹制方便、省时的深加工食品,由于其原材料、加工方式和生产设备的不同,微量元素的含量常常具有显著差异[1]。根据速食面中微量元素指纹快速识别品牌,可以对速食品质量监管带来很大的便利。
常见的食品微量元素检测方法有原子吸收光谱法、原子荧光光谱法、X射线荧光光谱法和电感耦合等离子体质谱法(ICP-MS)[2-5]。其中ICP-MS检测限低,是目前食品微量元素分析中最常用的检测方法[6-7]。本研究使用ICP-MS检测16种品牌速食面中的5种微量元素,使用3种降维方法对结果进行可视化分析,对比了5种机器学习算法的分类识别准确率,为速食面品牌识别提供了可行性方法。
1 实验部分
1.1 试剂与仪器
浓硝酸(68%)、双氧水(30%)均为UPS级;高纯氦He(≥99.999%);高纯氩Ar(≥99.999%); ICP-MS混合内标储备液、ICP-MS多元素混合标准品均为安捷伦科技有限公司。
7800型电感耦合等离子体质谱仪(ICP-MS);DKQ-1800 智能控温电加热器;Synergy超纯水系统。
1.2 速食面样品采集和前处理
购买市面上常见品牌的速食面16种,品牌和对应编号见表1。

表1 速食面品牌信息Table 1 Instant noodle brand information
主要原料为小麦。准确称取每种品牌的速食面0.2 g,碾碎后置于50 mL离心管中,加入4 mL 68%硝酸和1 mL 30%过氧化氢[8],置于电加热器中80 ℃恒温消解2 h,后冷却至室温。每种品牌的检材采集7份,其中6份用于可视化分析和训练集样本,1份用作测试集样本。每份样品平行测定3次。
1.3 标准溶液配制
使用超纯水将10 μg/mL Cr、Mn、As、Cd、Pb多元素混合标准品逐级稀释至0,0.1,0.5,2,5,10,50,100 ng/mL的标准使用液。使用超纯水将100 μg/mL 混合内标稀释至10 μg/mL的内标使用液。
1.4 ICP-MS仪器工作参数
射频功率1 500 W,冷却气流量15.0 L/min,载气流量1.0 L/min,辅助气流量1.0 L/min,采样深度8.5 mm,分析模式为碰撞反应池,重复采样3次,数据采集模式为跳峰采集,内标元素选择72Ge、103Rh和209Bi。
1.5 数据分析和分类模型建立
数据降维和特征提取能够对冗杂的数据进行精简和可视化分析[9-10]。有监督的机器学习分类识别方法在农作物品种鉴定、产地溯源等方面应用广泛[11-12]。本研究中可视化分析和化学计量学建模使用Matlab 2019b软件实现。使用该软件对实验数据进行主成分分析降维、非负矩阵分解和t-SNE降维,并将降维结果可视化。朴素贝叶斯模型[13]的预测参数分布选择高斯分布;K-最近邻模型[14]距离度量方式选择欧氏距离,临近点个数为1;支持向量机[15]核函数选择二次多项式,多类分类方法为一对一;集成学习的集成方法为子空间判别(ESM),学习器数量为30,子空间维度为3;决策树判别模型[16]最大分类数设定为100,分裂准则为基尼系数。所有模型训练集交叉验证折数为7折。
2 结果与讨论
2.1 速食面中5种元素测定结果
使用0,0.1,0.5,2,5,10,50,100 ng/mL 8个浓度梯度的Cr、Mn、As、Cd、Pb混合标准使用液依次进样,以浓度为横坐标,响应强度为纵坐标建立回归曲线,结果见表2。

表2 5种元素的线性方程及相关系数Table 2 Linear equation and correlation coefficient of five elements
由表2可知,线性拟合效果良好,相关系数均达到0.999 9。
使用ICP-MS检测16种品牌速食面中的5种元素,每个品牌采集7份样品,其中6份用于可视化分析和训练集样本,1份用作测试集样本,其中每份样品测定3次,所得数据的相对标准偏差均小于15%,检测结果具有准确性。将每个品牌速食面的6份分析样品求平均,结果见表3。
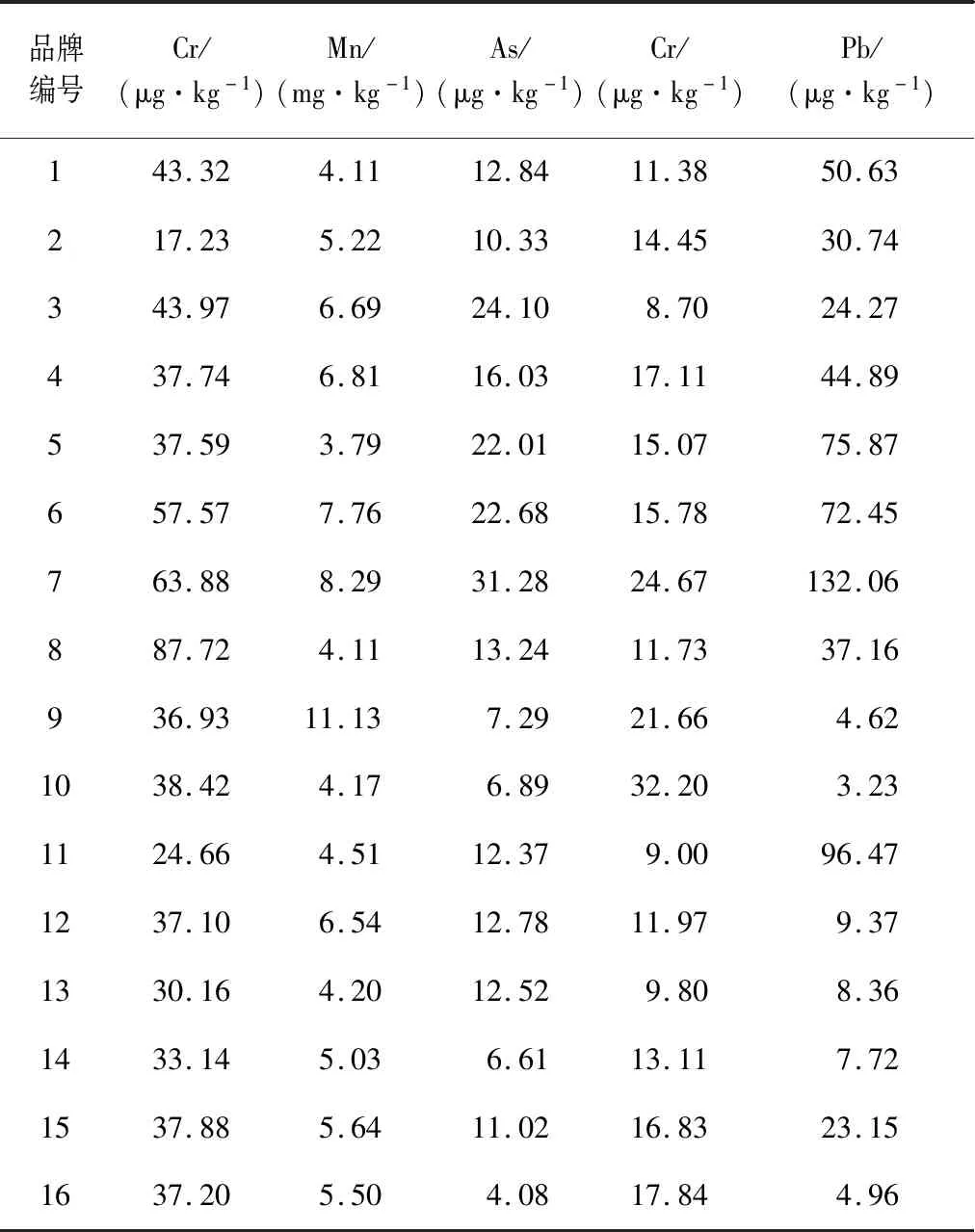
表3 各品牌速食面5种元素平均浓度Table 3 Average concentrations of five elements in instant noodles of different brands
2.2 数据降维及可视化分析
为了更加直观的观察16种品牌的速食面之间5种元素浓度的差异,使用了3种数据降维方法并将结果可视化表示。
使用MATLAB 2019b软件对数据进行主成分分析降维,各主成分的贡献率及累计贡献率见表4。
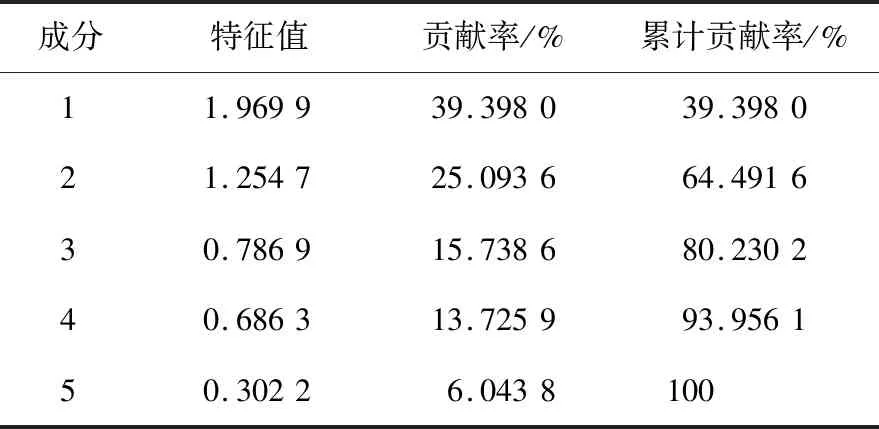
表4 各主成分的贡献率和累计贡献率Table 4 The contribution rate and cumulative contribution rate of each principal component
由表4可知,选取前3个主成分后,能够保留80.230 2%的数据信息,如果选取4个主成分,累计贡献率能达到93.956 1%。5种元素的主成分载荷见表5。
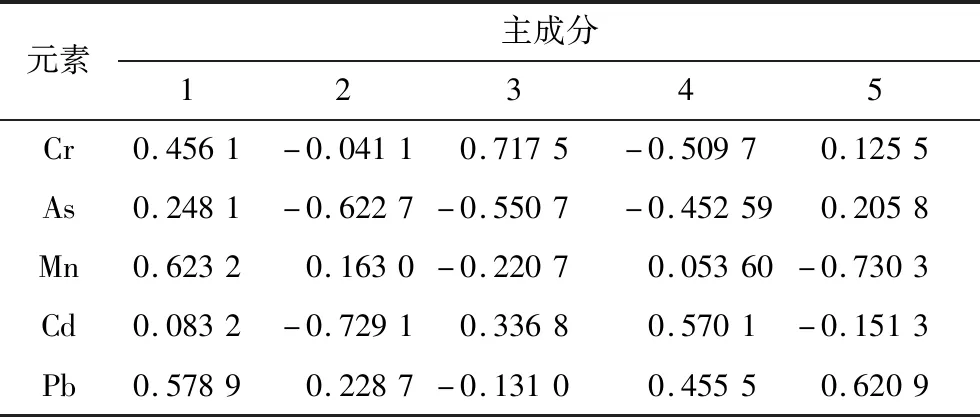
表5 5种元素的主成分载荷Table 5 Principal component loads of five elements
由表4和表5可知,第一主成分主要反映了Mn和Pb元素浓度的差异信息,与Mn、Pb浓度均呈正相关,方差贡献率为39.398 0%;第二主成分主要反映了As和Cd的数据信息,与As浓度呈负相关、与Cd浓度呈正相关,方差贡献率为25.093 6%;主成分3主要反应了Cr元素的元素浓度信息,方差贡献率为15.738 6%。取前3组主成分,绘制三维分布图,可以直观看出16种品牌大多存在明显差异,见图1。
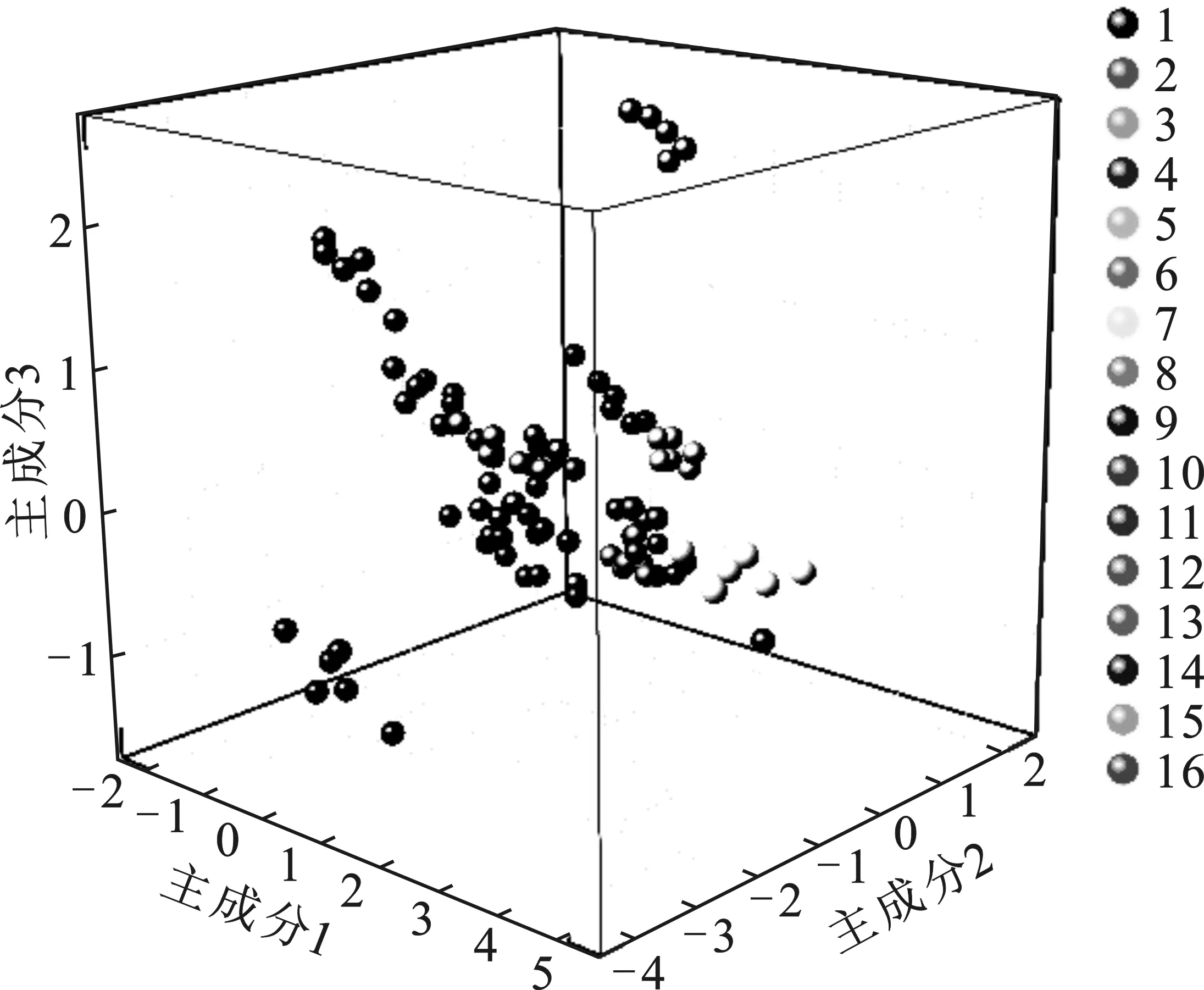
图1 PCA降维结果可视化Fig.1 PCA dimensionality reduction visualization classification result
再尝试使用以各种距离度量为标准的t-SNE降维方法对元素数据进行处理,以获得更好的分离效果。4种距离度量标准分别为:欧几里得距离(Euclidean Distance)、切比雪夫距离(Chebyshev Distance)、余弦距离(Cosine Distance)和马氏距离(Mahalanobis Distance)。对于同类数据维度差异较大的数据集,常使用马氏距离和余弦距离度量标准进行t-SNE降维。4种度量标准下的t-SNE降维结果见图2。
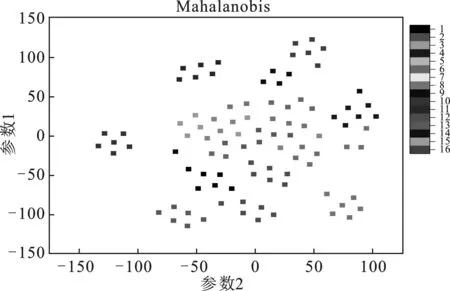
图2 4种度量标准下的t-SNE降维结果Fig.2 t-SNE dimension reduction results under four metrics
由图2可知,马氏距离与余弦距离度量标准能获得更好的分离效果。
最后使用非负矩阵分解法进行数据降维[17],其主要理论依据是每一个矩阵V(F×N)都可以表示为两个较小矩阵的乘积,如公式:
V(F×N)≈W(F×K)×H(K×N)
F、N、K是这些矩阵的维度。两个较小矩阵分别包括特征和权重,也就是说,原始矩阵被分解为特征矩阵及其对应的权重矩阵。保留特征矩阵结果作为数据降维结果,见图3。
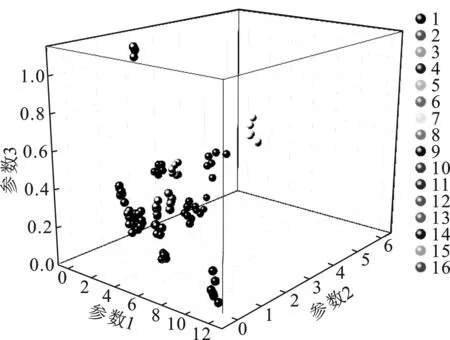
图3 NMF降维结果可视化Fig.3 Dimension reduction results of NMF
由图3可知,非负矩阵分解法可以对16种品牌的速食面进行很好的区分,可视化分类结果比主成分分析法和t-SNE法更佳。
2.3 不同分类模型分析
使用朴素贝叶斯判别模型、K-最近邻模型、支持向量机模型、子空间判别模型和决策树模型对速食面品牌进行分类,ACC(train)、ACC(CV)和ACC(test)分别代表训练集准确率、交叉验证准确率和测试集准确率,结果见表6。
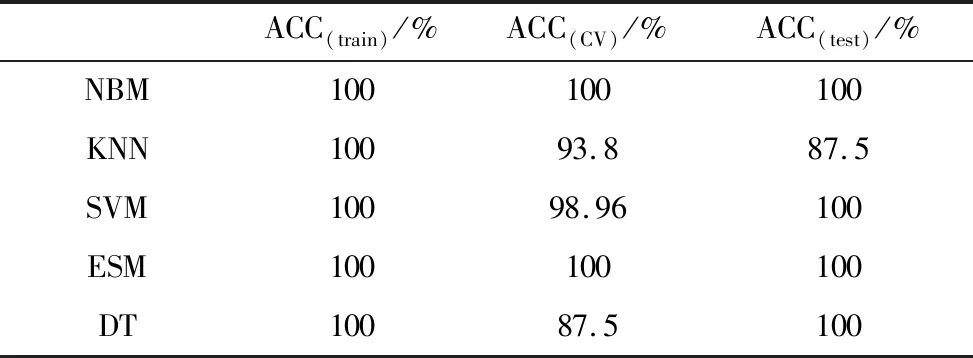
表6 5种分类模型识别准确率Table 6 Recognition accuray of five classification models
由表6可知,5种判别模型的ACC(train)都达到了100%,贝叶斯判别模型、子空间判别模型的ACC(CV)达到了100%。使用外部测试集进行预测时,除K-最近邻模型外,4种分类模型均达到了100%预测准确率,说明5种分类模型均能达到较好的分类识别效果,其中贝叶斯判别模型和子空间判别模型分类识别能力最佳,K-最近邻模型和决策树模型分类识别能力稍弱。
KNN模型和DT模型交叉验证的分类情况见图4、图5。
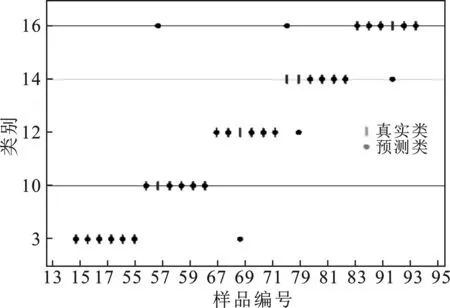
图4 KNN模型交叉验证结果错配情况Fig.4 Cross validation mismatch results of KNN model
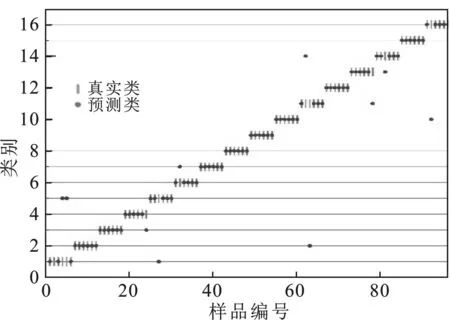
图5 DT模型交叉验证结果错配情况Fig.5 Cross validation mismatch results of DT model
由图4、图5可知,KNN模型中,96个训练集样本在交叉验证过程中有5个发生了错配;DT模型中,有12个样本在交叉验证过程中发生了错配。这两种分类模型在该实验中识别准确率较低。
将3种降维结果结合5种分类模型进行速食面品牌识别,交叉验证准确率见表7。
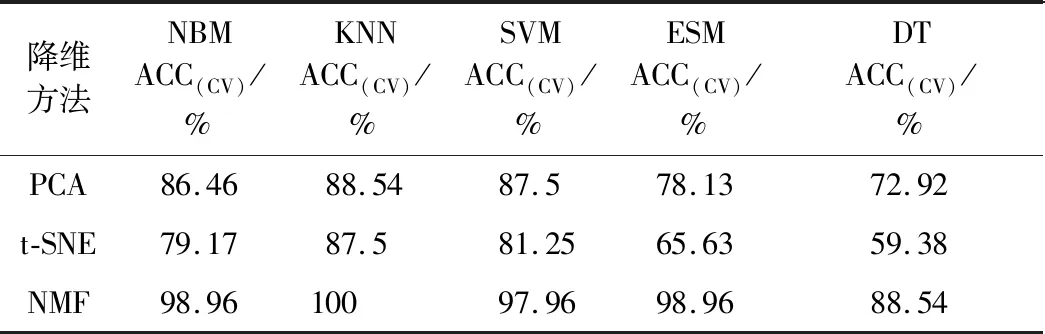
表7 3种降维方法结合5种分类模型的交叉验证准确率Table 7 Cross validation accuracy of three dimensionality reduction methods combined with five classification models
由表7可知,非负矩阵分解法降维对比其他两种降维方法有显著的分类识别优势。与原始模型相比,非负矩阵分解后的数据与KNN模型结合提高了识别准确率。
下一步应扩大样本容量,尝试对更多的食品进行溯源研究。
3 结论
测定16种市售速食面中5种微量元素的分布,结合多元统计学降维方法,进行了可视化分析和基于机器学习的分类识别。可视化结果显示,非负矩阵分解法降维效果最好,t-SNE降维与主成分分析降维方法次之。分类识别结果表明,K-最近邻模型、决策树模型识别能力较差,ACC(CV)分别为了93.8%和87.5%;贝叶斯判别模型和自空间判别效果最好,ACC(train)、ACC(CV)和ACC(test)均达到了100%,可以实现对市售速食面品牌的准确识别。对使用3种降维方法后的数据进行分类识别,结果表明使用非负矩阵分解法降维后,仍能保持较高的分类识别准确率,其中非负矩阵分解降维与K-最近邻模型结合,交叉验证识别率达到100%。说明使用ICP-MS测定速食面中微量元素分布,结合机器学习分类识别方法,可以准确、有效的识别市售速食面品牌,为食品安全监测过程中未知来源的速食面溯源提供了思路和方法。
猜你喜欢
车主之友(2022年4期)2022-08-27 00:57:12
世界科学技术-中医药现代化(2022年3期)2022-08-22 00:32:50
云南化工(2021年8期)2021-12-21 06:37:54
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
海洋信息技术与应用(2020年1期)2020-06-11 12:43:56
海峡姐妹(2019年12期)2020-01-14 03:24:40
传媒评论(2019年4期)2019-07-13 05:49:14
中国交通信息化(2018年5期)2018-08-21 03:37:40
