
基于Web信息的物联网设备指纹生成方法研究
2021-07-20 00:05张莉红
现代计算机 2021年15期
张莉红
(1.四川大学计算机学院,成都610065;2.西藏藏医药大学,拉萨850000)
0 引言
物联网技术的飞速发展给我们的工作、生活和学习等都带来了新的变革。据研究发现到2030年物联网设备的数量将达到1250亿[1],物联网设备穿插于社会各个层面,为改善生活和加快社会发展做贡献,但同时也带来了新的安全问题[2-4]。为了减少物联网设备接入风险,必须对设备进行访问安全控制。但是,传统的互联网安全访问控制必须依赖复杂的认证和加密协议机制来完成,不适用于计算资源有限且功能比较单一的物联网设备。设备指纹识别等技术则为解决上述问题提供了新思路,通过网络流量或协议报文的方式获取设备指纹特征,能唯一标识某一品牌类型及型号的物联网设备。
机器学习算法被广泛用于设备识别中,常常关注于提升分类模型识别的准确率,而在发现新设备上却没多少进展,本文针对上述问题,提出了一种基于Web响应信息的物联网设备指纹生成方法,能大大提升对物联网设备识别的准确性,并在此基础上结合监督数据提取距离阈值利用层次聚类算法发现新设备,适合用于大规模物联网识别。
1 相关工作
设备识别起源于上世纪90年代,依据获取方式的划分主要有被动指纹识别和主动指纹识别两种方式,被动指纹识别流量数据来源于监听,由于不向网络发送数据包所以入侵小不易被发现,但受监听网络大小控制,识别设备仅限于监听网络。主动指纹识别方式主要运用探测手段,需要发送探测数据包,会对网络造成一定影响,但由于其目的性强,准确度高越来越受研究人员的青睐。
Shah等人[5]提出通过服务标识Banner来识别Web服务器软件信息和版本信息的方法,但由于某些设备HTTP响应包中并不包含此信息,因此该方法在识别上有局限性。赵建军等人[6]提出一种综合的网络空间终端识别设备框架,从Banner和Web指纹两个角度来提取设备识别指纹,但没有验证其准确性。Li Q等人[7]通过设备登录页面的特征,提出一种GUIDE的设备识别框架,能对视频监控设备进行识别,但未对识别方法和效果进行详细讨论。Yang等人[8]通过对大量网络流量分析总结出一系列特征来进行设备识别,但由于涉及多层报文的提取不适用于大规模物联网识别。
随着设备识别方法的不断总结提出,如何用最简单有效的特征提取方法在有线标的设备中发现无标的设备是本文研究的重点。本文从物联网设备为方便用户使用都会开放Web管理服务这一前提出发,采集HTTP报文响应信息提取有效特征的方法进行物联网设备分类识别,分类准确率达到99.6%,并结合带阈值的层次聚类来发现新设备。
2 基于Web信息的物联网设备指纹生成识别框架
2.1 方案概述
本文提出的基于Web信息的物联网设备指纹生成识别框架如图1所示。

图1 基于Web信息的物联网设备指纹生成框架
(1)特征提取模块。特征提取模块从本地网络向远端网络发送探测包获取开放端口及协议的远端IP地址及端口号存入数据库,向数据库中的所有地址发送HTTP-get请求,获取到每个地址的响应信息,同时随机提取一部分地址设备进行物联网设备和非物联网设备标记并用人工方式进行验证。通过卡方校验物联网设备和非物联网设备的响应信息,提取固定格式的特征向量作为设备指纹,为后续分类识别打好基础。
(2)分类器选择模块。分析现有机器学习中的多分类器,对于不同特征提取适用的分类器不一样,因此我们在这个模块中选取四类常用多分类器来对标记设备进行分类识别,最终选择分类器效果最好的分类器作为我们的目标多分类器,并比较其他文献采集特征的分类准确性,证明我们特征提取的有效性。
(3)发现新设备模块。利用有监督的数据设置阈值用层次聚类的方法在导入的数据集中又发现上百种新设备类型。
2.2 特征提取
(1)设备发现数据获取:负责在指定IPv4地址空间内进行端口扫描,获得开放Web服务的无标记设备的IP地址集,向地址集中所有地址发送HTTP-get请求,获得响应状态码为200ok的完整的响应信息作为原始待处理样本信息。具体采集到两部分信息,形式如图2所示。
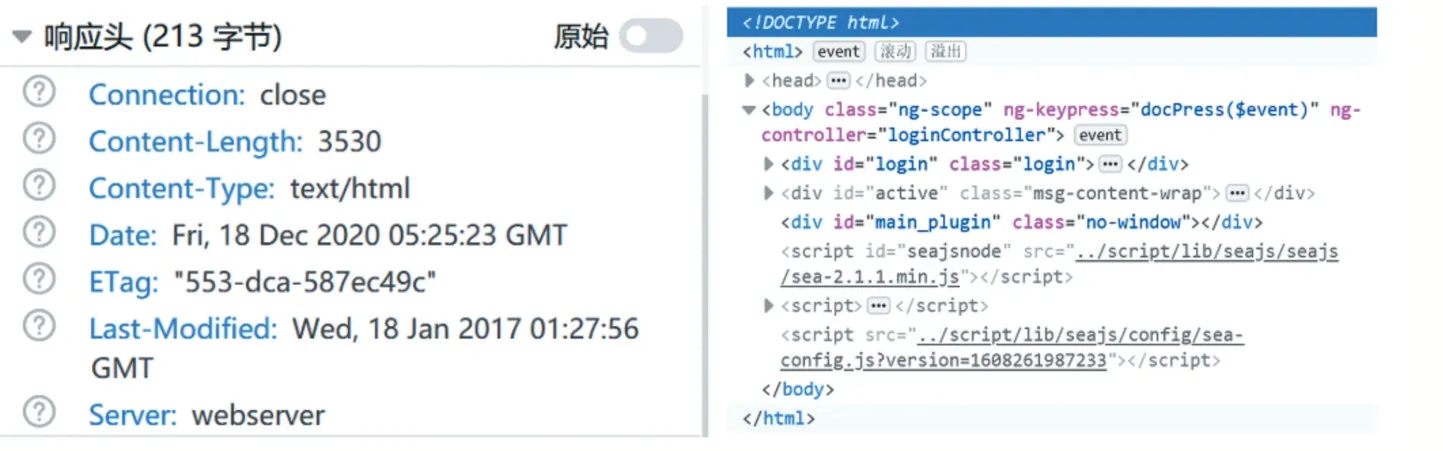
图2 左部为响应头部信息右部为响应主体信息
(2)提取统计特征:物联网设备服务器经常采用一些公用的轻型网络服务器,如micro_httpd、lighttpd、Boa/0.93.15等,而某些物联网设备厂商则会在此嵌入与设备品牌型号相关的信息,因此可以通过Server字段初略的判定某些设备的品牌类型或排除掉一些非物联网设备,利用正则表达式提取头部Server字段、主体title信息以及页面版权信息等标识物联网和非物联网设备集,随机提取物联网设备集中部分设备通过人工鉴定的方式为其打上品牌类型型号标签,完成有标记设备采集。通过观察比较物联网设备响应头部字节长度,响应头部属性字段数目和响应主体的<head>...</head>及<body>...</body>内字节长度,发现不同品牌设备类型所显示的这四个值都不尽相同,而相同品牌设备类型所显示的这四个值都大致相同。因此提取此四个统计特征作为第一部分特征。如图3所示,用PCA在二维平面上进行降维分析此四个特征可以看出能够很好地区分设备品牌类型。

图3 部分带标签设备统计特征向量分布
(3)提取协议特征:观察协议响应报文的Header属性值,我们发现相同设备一般具有相同属性值,不同设备属性值则不完全相同,因此在这部分中我们提取Header属性中的每一个键名作为研究对象,通过图4四格图表法和卡方校验的方法选取已标记的物联网和非物联网设备各一万个,我们先假设某键名M不属于物联网设备,然后通过四格表观察值确定p行q列的理论值,见公式(1),带入卡方公式计算偏差值,见公式(2),通过公式(3)自由度查卡方分布表查概率值大小来验证假设是否成立,成立则属于非物联网设备属性,否则为物联网设备属性。通过卡方比对每一个键名获得属于物联网设备的所有键名属性特征,计算属性特征出现的频率最终选择33个键名作为协议部分特征。

图4 四格图表法

(4)整合特征:整合统计特征和协议特征,形成特征向量集,如表1所示。

表1 统计和协议特征集合
提取物联网地址集里面所有地址的统计特征和协议特征。对统计特征进行归一化,对协议特征进行one-hot编码,即设备特征头部字段中有协议特征字段则标为1,没有协议特征字段则标为0,最终形成具有37维特征的物联网设备特征向量,部分设备特征集提取处理后效果如图5所示。

图5 部分设备特征集提取处理集合
2.3 相似性度量及新设备发现
通过对比决策树(DT)、随机森林(RF)、K近邻(KNN)和逻辑回归(LR)四类分类器对标注物联网设备进行分类,并对比文献[9]特征提取方法,证明我们特征提取的有效性。
由于我们的特征向量是基于响应报文提取的偏向于用文本相似性去度量两个样本的异同,因此本文采用余弦距离作为相似性度量。结合文献[10]可知余弦距离也可表达与欧氏距离一样的意义,欧氏距离d(x,y)、余弦相似度cos(x,y)、余弦距离D(x,y)三者关系如公式(4)所示:

每一类设备代表一个分类簇,用余弦距离找出各簇已标记设备品牌类型中心点,每一个簇代表一类设备,计算各簇中心到簇内最远点余弦距离D,计算平均余弦距离Dˉ。导入新数据集用Dˉ作为阈值进行层次聚类来发现新设备。
2.4 算法描述
根据Web信息的物联网设备指纹生成框架,给出实验的相应算法步骤如下:
(1)扫描IPv4空间中开放web端口服务的IP地址,形成IP地址集;
(2)获取IP地址集的原始响应信息,包括响应头部信息和响应主体信息;
(3)随机选出样本集进行物联网和非物联网标记并通过人工验证的方式为物联网设备打上品牌类型标签;
(4)对原始响应信息中物联网和非物联网设备头部信息进行卡方校验提取适合物联网设备使用的协议特征并加入统计特征形成总体样本集I={a1,a2,…,an},其中ai代表第i个样本的37维特征向量;
(5)对样本集进行特征提取、预处理和归一化;
(6)对比决策树(DT)、随机森林(RF)、K近邻(KNN)和逻辑回归(LR)四类分类器,选择分类准确率最高的KNN分类器作为设备分类器,并比较其他文献提取特征的分类准确率;
(7)输入已知设备集合X,按品牌类型划分为k簇,在每簇中间利用公式(4)代入计算簇内余弦相似度的和,则和值为极大时表示此点为本簇中心O,得到K簇中心为Y;
(8)计算各簇中心到各簇点的余弦距离,并记录下各簇余弦距离最大值D,求出余弦平均值Dˉ:

(9)导入新数据集M个,其中包含已标注数据集N个,设置当前聚类簇个数为M,计算两两之间的余弦距离,设置距离阈值为2Dˉ,选择AGENS算法进行聚类,当余弦距离小于2Dˉ则合并,直到所有距离都大于2Dˉ时停止聚类。
3 实验与评估
3.1 数据采集
本文采用主动采集的方式,为避免对IP网段造成干扰,通过对在线设备运用了IP随机化探测的方式向网络中一段IP地址进行随机化端口开放探测,探测到开放IP地址端口的设备上百万个,并对探测到的特定端口(如80-85、8080、8090等)发送HTTP-get访问请求,获取到如图6所示的响应状态码分布情况信息,其中200ok表示请求已成功,请求所希望的响应头或响应体将随此响应返回,出现此状态码是表示正常状态,基于只有直接暴露在互联网中的设备才容易被利用和攻击的假设,我们提取响应状态码为200ok的设备响应信息作为我们的研究对象,我们提取了占采集数据46.11%的响应信息。

图6 响应状态码基本分布情况
3.2 实验结果分析
本实验基于“相同品牌相同类型相同型号的设备的响应信息会大致相同”作为假设来进行,通过随机提取部分响应状态码为200ok的设备数据124708个作为我们的实验数据,经筛选字段后用人工校验的方式为目标设备添加品牌类型标签,标记后有标签的品牌类型设备有二十几种,如表2所示。其中包含路由器、网络摄像头、网络电源交换机、网络存储器、工控设备等多种物联网设备,结合标签设备数目选择其中标记数目大于500的11种品牌设备每种取样500个作为下一步机器学习的数据集,至此完成有监督设备数据集的提取。

表2 标记的带标签品牌和数目
选择决策树(DT)、随机森林(RF)、K近邻(KNN)和逻辑回归(LR)分类器来做分类器对比实验,并设置其参数在其分类器上表现最优,经过十折交叉验证后的F1-Score值分别为RF-99.82%、DT:99.70%、KNN:99.91%、LR:93.06%,图7混淆矩阵清楚的展示了四类分类器的分类效果,可以看出KNN分类器效果最佳。
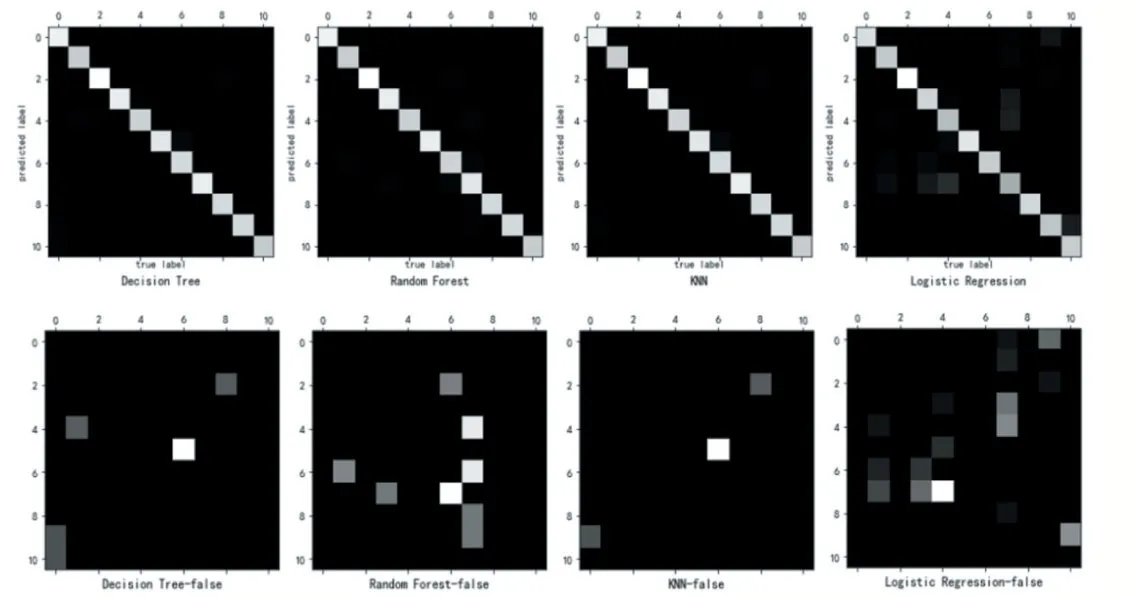
图7 DT、RF、KNN、LR各分类器混淆矩阵
利用KNN分类器对比文献[9]提出的特征方法,如表3所示,经对比在各品牌上的召回率、准确率和F1-Score值,本文提取的特征都更加有效。针对分类器错误分类的品牌设备进行分析,导致分类错误的原因主要有两个:一是某些品牌设备在后期会被其他品牌收购兼并冠上新设备品牌名称;二是我们在标记的时候笼统的把品牌类型作为主要目的而没有去关注型号。
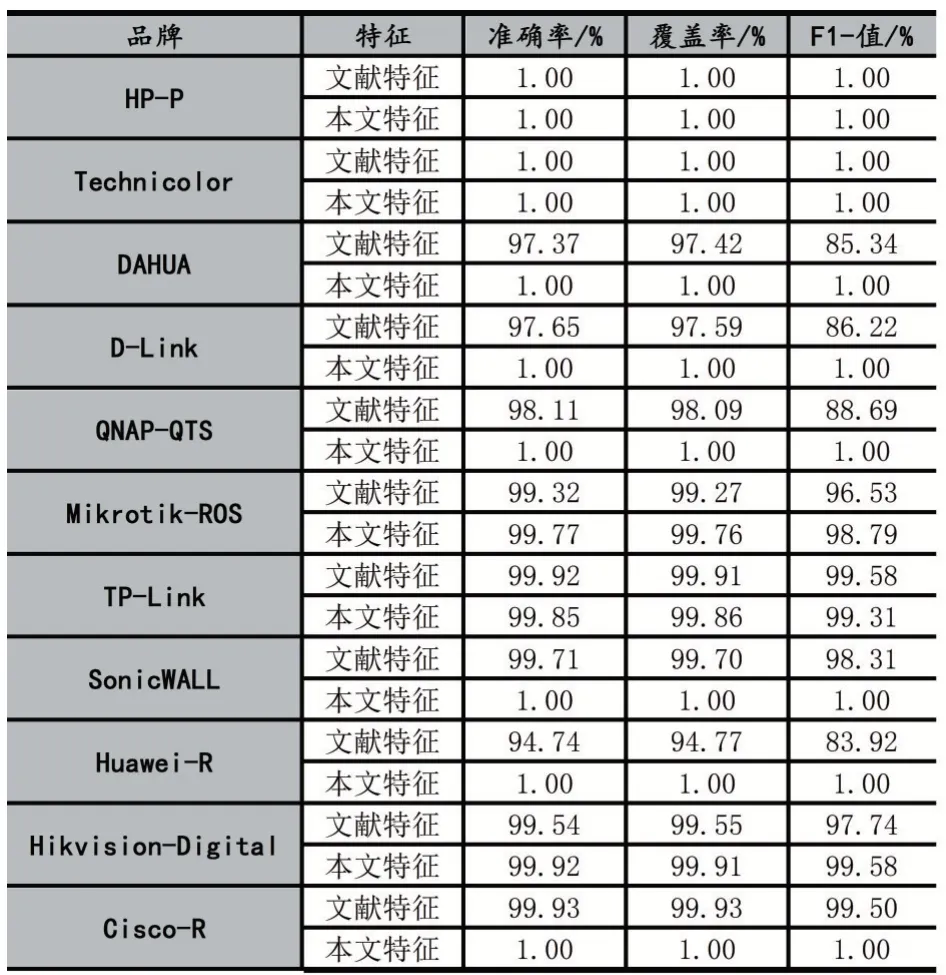
表3 文献[9]与本文特征提取算法的设备分类效果
计算距离阈值,用带阈值的层次聚类算法在未标记的数据集中进行新设备类型发现,经人工校验后发现上百种新品牌类型,经人工检验后部分新设备品牌类型如图8所示。

图8 新发现部分设备品牌
4 结语
本文提出了一种基于头部字段Header和统计相结合的设备指纹特征生成方法。该方法便于提取,易于实现。通过比较分类器,实验结果表明此方法在设备品牌类型上能很好进行设备品牌及类型的提取和分类,最后应用基于距离阈值的层次聚类方法发现诸多新品牌类型设备,便于开展大规模设备探测。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
计算机辅助工程(2018年2期)2018-06-03
电机与控制学报(2018年9期)2018-05-14
软件导刊(2017年4期)2017-06-20
计算机应用(2016年10期)2017-05-12
中学数学杂志(高中版)(2016年6期)2017-03-01
福建中学数学(2016年7期)2016-12-03
智能制造(2015年7期)2015-11-20
