
基于新闻时效性模型的协同过滤推荐算法研究
2021-07-19 07:53:24李薇程科
科学与信息化 2021年19期
李薇 程科
江苏科技大学 江苏 镇江 212008
引言
信息时代,网络新闻的生产和传播速度都呈爆炸式增长。通过个性化新闻推荐系统[1],用户可以在更少的时间里得到更感兴趣的新闻。
协同过滤算法[2]分为基于用户的协同过滤算法[4]和基于商品的协同过滤算法[5]。新闻系统中的用户数变化相对固定,所以基于用户的推荐算法的性能较好。但是新闻内容特点需要不断调整同类用户的新闻信息表[8]。当数据量较大时,算法的时间复杂度[8]过大。
针对以上问题,本文提出了一种基于新闻时效性的方法,通过建立新闻的时效性模型[9],结合新闻时效性特点改进了基于用户的协同过滤算法[5]中对于最近邻用户的选择。在维护用户相似度矩阵时,为了保持新闻信息的高及时性,对新闻集进行过滤。这样新闻数据量大也能保持算法的高性能。本文利用改进的算法对南京日报网上新闻系统的新闻和用户行为数据集进行了仿真,验证了该方法的有效性。
1 新闻时效性模型和基于用户的协同过滤推荐算法
1.1 新闻时效性模型
1.1.1 信息老化。贝尔纳在1959年提出了信息老化的负指数模型,用以确定文献信息的价值与时间的关系,下式(1)为基于信息老化的负指数模型[10]公式:

1.1.2 新闻时效性模型。为了研究网络新闻信息的老化过程,通过引入文献信息老化模型辅助分析,可以给出一种定量判断新闻时效性的方法。本文对网络新闻时效性模型做出界定:
1.1.2.4 定义4(新闻所属主题簇S,主题簇新闻平均最高访问效果时刻):在新闻的实际传播中,初始时刻可能会出现由于新上架而导致的低访问量问题,从而导致与负指数模型拟合效果差问题;而通过引入相近主题的新闻平均最高访问效果时刻参数,可以从此时刻起开始计算负指数模型中的老化系数,提高模型的准确性。
将贝尔纳的负指数模型[12]引入模型,可以用下式定义:

其中,t为当前时刻,推荐输入集合[11]的更新时为该主题簇中新闻到达最高访问平均所需要的时间[12],表示新闻在t时刻的新增用户反馈[8]数量,需要根据新闻系统[1]来调整设定合适的时间粒度,统计这一分段时刻的用户反馈[8]数量。老化系数[13]a指的是这条新闻随着时间推移访问效果[2]的衰减系数,a越小,说明这条新闻的时效性[10]越强。b是与新闻发布后的初始统计时间粒度内用户反馈统计数量有关的常数[13],即第一个统计时间段,模型有较好的匹配时,时间粒度内用户反馈统计数量参数易受新闻初始阅读量影响,但不会表现新闻时效性的变化趋势,b较大,则新闻初始阅读量较大[13]。本文研究的时效性改进算法,就新闻本身的时效性变化趋势进行线性回归分析,计算出b,b参数后,主要考虑将老化率a作为推荐算法的输入,对上面的公式变形改进,可以更清楚地认识到老化参数与时间推移的联系:

变形后,对老化曲线拟合,近似于常见的负指数模型,直观地只要求出老化系数a即可。
对于某一特定的新闻,通过老化系数a代表其发布后传播效果的衰减速度,衰减不明显即为时效性[11]较强的新闻,对于新闻阅读者[3]而言,该新闻时效价值[4]较高;当到达生命周期后,时效价值为0。
为了保证模型的健壮性[2],统计各时段内的网络新闻反馈数量时,根据系统分时段的总体阅读量,作归一化处理来降低读者不同空闲时段带来的影响。
根据公式与网络新闻信息的统计数据进行拟合[3],计算出网络新闻的老化率[13]。同时,通过线性回归分析判断新闻与时效性模型的最终拟合效果。
1.2 基于用户的协同过滤算法
基于用户的协同过滤算法(User CF算法)首先通过寻找与目标用户兴趣度相似的用户集合,找出在这个用户集合中的用户喜欢但目标用户尚未关注的物品信息,再将其推荐给目标用户。
根据用户间兴趣相似度可以给用户推荐兴趣最相似的K个用户喜欢的新闻,公式(4)表示了User CF算法中用户u对新闻n的感兴趣程度预测评分。

2 基于新闻时效性模型的协同过滤推荐算法
2.1 算法设计
在传统的基于用户的协同过滤推荐算法中,没有考虑信息本身老化与时效性的问题,这种做法可能适合对项目时效性不敏感的内容系统,但不适合网络新闻系统,因为新闻本身对时效性要求较高。所以本文先过滤掉老化新闻,降低了输入数据的规模,再结合新闻衰老系数与生命周期,基于新闻时效性模型,对推荐结果预测评分进行加权平均,从而提高了推荐的效果。
2.2 数据模型
2.2.2 推荐系统输入新闻集合Ⅰ。选取推荐新闻时的输入集合,用来计算新闻时效性。公式(5)表示集合。由于UserCF算法既要进行较复杂的用户偏好度计算又要进行时效性模型的检验,为了大幅降低算法复杂度,所以将输入集选取在生命周期内的新闻。
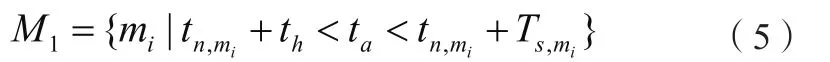
2.2.3 推荐系统输入新闻集合Ⅱ。保存刚刚发布的新闻,由于尚处于传播的上升期,可认为这些新闻当前没有老化的趋势,所以将其老化系数设置为0,时效性仍然很强。公式(6)为集合。
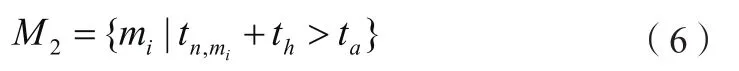
2.2.4 用户信息集合。随着系统用户的增加自动更新,用集合表示k个用户的集合,因变化很缓慢可认为算法更新集合U不变。
2.2.5 用户-新闻兴趣矩阵 用户对新闻做出阅读、点赞、分享及评论等各种各样的行为,则通过用户行为偏好向量空间模型计算出用户对新闻兴趣数值。
2.2.6 新闻访问表。统计用户反馈新闻的操作数量随时间变化状况,体现时效性。
2.3 通过时效性参数改进推荐算法
为了获取用户的完整历史兴趣爱好,计算用户相似兴趣度的输入集合要包含整个新闻集合N与用户集合U,不能只选取新闻子集合。最后,本文选取的是杰卡德相似度[3]公式来计算用户相似度,即公式(7):

基于时效性参数改良预测评分结果,得到最终推荐计算公式(8):

3 实验分析
本文对南京日报网络新闻数据与用户数据进行实验,共计7684条新闻,53264个用户。2021年02月04日部分新闻数据如表1所示,该表表示某新闻的阅读情况。

表1 实验数据集中部分新闻访问数据
t表示抽样时间,Readnum表示当前时刻阅读数量,Delta_readnum表示每间隔时间内的新闻阅读增长情况,阅读数量已经根据系统整体情况作归一化处理。
3.1 时效性模型实验
先对新闻集合进行时效性模型检验,根据其阅读量变化利用负指数模型进行拟合,拟合结果如表2所示,包含了新闻的时效性模型检验结果,单条新闻阅读变化量拟合结果如图1所示。

图1 单挑新闻阅读变化量拟合结果

表2 单条新闻拟合结果
时效性模型输入数量级与SSE及RMSE有关[15]。R-square与Adjusted R-square表达的是拟合结果与目标模型的效果,越近似于1说明模型效果越好[11]。表2中单条新闻浏览量变化相对拟合[11]时效性模型,说明阅读量与时间相关联[12],将拟合得到的老化系数a作为推荐模型的输入。即说明改进后的时效性模型[13]更适合。
对于热门新闻,阅读量较大,适用时效性模型,提高正确率与精度。对于非热门新闻,从新闻输入集合中去除,只对订阅用户定点推送。
3.2 基于时效性模型改进UserCF算法的实验
由实验(1)得出了时效性模型的新闻老化系数[13],利用改进UserCF算法,基于时效性模型中老化系数的影响,在计算用户兴趣度时,将实验(1)中R-square超过0.80 的新闻集单独分类,形成一个新的新闻数据集。和原新闻集N分别作为新闻总集,分别进行两次实验,步骤相同,参数一致,仅仅输入不同。最后与传统的UserCF算法[4]作为对照比较。
本实验中,将用户行为数据集随机分成8等份,6份作为训练集,2份作为测试集,通过准确率与召回率来评价推荐算法的效果:
公式(9)为计算推荐准确率的方法:

公式(10)为计算推荐召回率的方法:


表3 推荐算法实验结果
不同的输入集合[8],SubN是与时效性模型高拟合度的新闻数据集,热门新闻,平均阅读数量较高,抗噪声能力强。在实际推荐系统中,通常热门新闻受推荐的可能性更大,准确率与召回率都会更高。在传统的UserCF算法中,SubN集合与N集合前者推荐准确率与召回率更高,不过相差不大,UserCF算法没有考虑到时间推移的影响,只满足了高阅读量的特性,提高推荐准确率与召回率效果不明显。
聚类后在簇内部使用推荐算法,最后得出实际的推荐新闻列表,可以进一步提高性能。由表4可知,时效性模型与聚类算法都有效提高新闻推荐算法的效果。

表4 聚类推荐实验结果
相同的输入下,改进后的UserCF算法,基于时效性模型[11],考虑到了新闻时效性衰减的因素,较好地利用了老化系数,降低了衰减较快新闻的权重;和时效性模型高拟合的新闻集合,不仅衰减速度慢,时效性强,自身阅读量高,所以改进后的UserCF推荐效果还会有所增强[16]。
4 结束语
自媒体时代,在信息过载的情境下为新闻读者提供合理推荐日趋重要。本文将文献信息老化模型[9]应用于新闻信息,引入时效性模型[11]中老化参数改进了基于用户的协同过滤算法。实验结果表明,改进后的算法对于抗噪能力强的热门新闻能有效地提高算法的准确率和召回率。不过本文只是针对兴趣评分处理与新闻时效性进行的改进,对于冷启动以及初始状态下用户稀疏等问题未考虑,所以未来还需进一步研究。
猜你喜欢
保健医苑(2023年2期)2023-03-15 09:03:36
科技传播(2019年22期)2020-01-14 03:06:22
新闻传播(2018年14期)2018-11-13 01:12:52
电子制作(2018年10期)2018-08-04 03:24:30
水科学与工程技术(2016年3期)2016-07-10 15:12:44
Coco薇(2016年2期)2016-03-22 02:40:06
煤炭学报(2015年10期)2015-12-21 01:55:41
新闻传播(2015年10期)2015-07-18 11:05:40
新闻传播(2015年9期)2015-07-18 11:04:12
新闻传播(2015年3期)2015-07-12 12:22:35
