
基于GRW和FastText模型的电信用户投诉文本分类应用
2021-07-15 01:54赵进杨小军
电信科学 2021年6期
赵进,杨小军
(中国电信股份有限公司重庆分公司,重庆 401120)
1 引言
大数据和人工智能作为国家提出的新型基础设施,引发了新一轮的科技革命。中国电信作为国内三大电信运营商之一、三化(数字化、信息化、智能化)产业布局者,正着力于大数据和人工智能在其业务和服务上落地生根,实现数字化转型战略目标。中国电信始终将用户的良好体验和用户感知放在首位,对用户的投诉进行业务拆解和快速分析,以求及时准确地反馈用户,规避用户越级投诉的风险和提升用户良好体验和使用感知。但是电信的业务服务类别复杂多样,有效地识别用户投诉类型目前还处于人工分类阶段,在实际工作过程中,业务领域专家的经验起着主导作用[1],而培养一个业务领域专家需要大量的时间成本和人力成本,因此,需要建立科学合理的文本分类模型。通常用户投诉数据有多种来源,如10000、微信公众号、线下厅店等,最终都会以非结构化的文本信息记录在系统中,如何对这些用户的投诉信息进行有效、快速、准确的分类成为处理用户投诉、提升用户良好体验和使用感知的关键[2]。
文本分类属于自然语言处理(natural language processing,NLP)应用研究范畴中的一个分支[3],在文本分类方法上,目前已经有了很多有突破性的研究成果,比如基于朴素贝叶斯方法的文本分类方法[4]、基于条件随机场的分类方法[5]等,随着深度学习向文本挖掘领域发展,利用word2vec、LSTM、CNN、TextRNN、预训练模型Bert等深度学习模型对文本进行分类,也取得了比较好的分类效果,并且在部分人工智能产品中落地应用。在传统的文本分类方法中,需要将文本转换成高维向量,这一般会造成向量维度过大,无论计算内存还是计算时间,计算复杂度将会非常大。为了避免高维风险,需要借助特征工程的相关方法或模型对文本的关键特征进行有效的提取,实现降低文本特征向量的维度数。目前文本特征提取有基于词频(TF-IDF)的方法、基于互信息(mutual information,MI)的方法、基于(Chi-square)统计量的方法、基于信息增益(information gain,IG)的方法、基于WLLR(weighted log likelihood ration,WLLR)的方法和基于WFO(weighted frequency and odd,WFO)的方法等[6]。在电信用户投诉文本数据中,存在很多与分类结果无关的信息描述,同时电信业务的类别复杂,多达几十种。针对上述问题,本文提出基于GRW和FastText模型的方法,对用户投诉文本进行多分类,并且基于真实的生产系统数据进行相关验证性实验,验证了本文方法的有效性。
2 基于GRW模型的特征提取
文本数据的特征提取方式与传统的数值类型特征的提取方式不同。在数据表示上,传统机器学习的数据由一组结构化的数据组成,这些数据的特征一般表现为字符串型的类别性、数值的离散性、数值的连续性、数据的时间性或周期性等,而文本数据属于非结构化数据,由字、词、句组成。因此在对文本数据进行特征提取前,需要对文本进行预处理,将文本拆分成字粒度或词粒度,然后通过不同的方法对文本数据进行数学表示。第一种方法是将文本表示成离散型数据,如One-hot编码和Multi-hot编码等;第二种方法是将文本表示成分布式型数据,如矩阵表示法、降维表示法、聚类表示法、神经网络表示法。
中文文本数据由字、词、句组成的文本,将中文文本按字、词进行拆分后可以进行一些数学统计,其中TF-IDF用来评估一个字或词对一个文本集或语料库中的一条文本的重要程度。当一个字或词在一个文本数据中重复出现时,则认为该字或词具有比较高的重要性,但如果该字或词在所有的文本集或语料库中均出现,且统计其出现的次数比较高,则该字或词的重要性反而会下降,如一些介词、谓词等。词频(term frequency,TF),即字或词在文本中复现的频率;逆向文本频率指数(inverse document frequency,IDF),即一个字或词在所有的文本中复现的频率,如果一个字或词在很多文本中出现,那么IDF值较小,反之,如果一个词在比较少的文本中出现,那么它的IDF值较大。TF-IDF计算式如下:

其中,nij是该词在文本dj中出现的次数,是文本dj中的所有字或词出现的总次数,|D|是文本集或语料库中的总的文本数量。|{j:ti∈dj}|表示包含字或词ti的文本数目。
2011年Imambi提出特征加权方案GRW[7],赋予特征词TF-IDF不同的权重。GRW模型计算式如下:

其中,TFIDFj是字或词的T-FIDF值,P(Tij)是属于分类i的词j的概率,P(Ci)是属于分类i的文档的概率,然后选择字或词的最大GRW值确定属于某个分类类别的特征词:
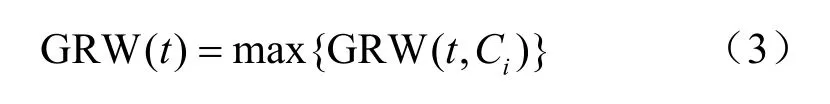
例如,如果GRW(t1,c1)=0.3,GRW(t1,c2)=0.4,则词t1被选择为类别c2的特征词。
SagarImambi在5 460份文档的数据集上,分别采用GRW、TFIDF、CFS、信息增益比(gain ratio,GR)、Chi-square和过滤子集(filtered subset,FS)对文档进行特征选择后,在贝叶斯网络、朴素贝叶斯、决策树等分类算法上进行相关实验,实验表明,用GRW模型进行特征选择后,具有较高的准确率(准确率比较见表1),因此文本也将使用GRW模型进行特征选择。
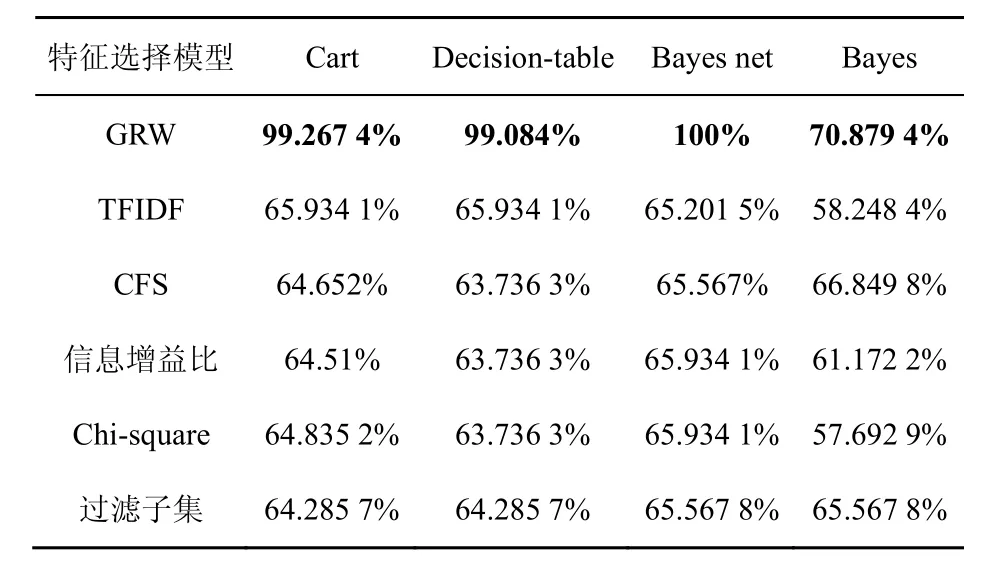
表1 准确率比较[7]
3 基于FastText模型的文本分类
FastText是FAIR(facebook AI research)提出的文本分类模型[8],该模型只有3层:输入层、隐含层和输出层。模型结构如图1所示。
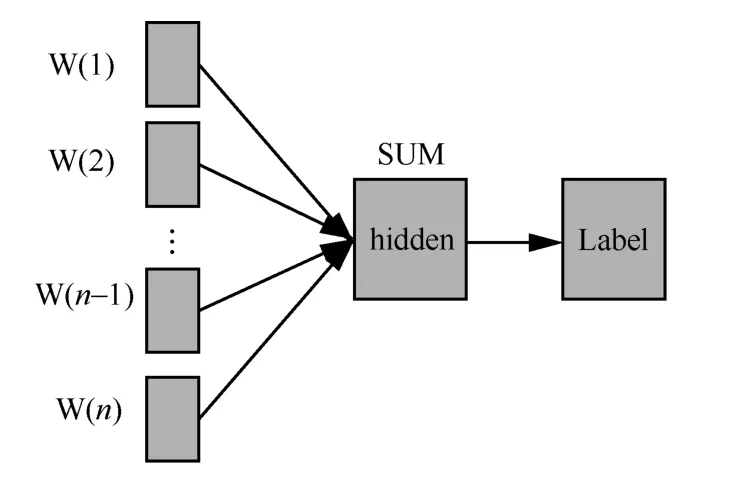
图1 FastText模型结构
其中,W(i)(1≤i≤n)表示文本数据中每个特征词的词嵌入,对每个特征词的词嵌入进行累加后求其均值,用以表示该文本,最后通过sigmoid函数得到输出层的标签。在训练该神经网络模型时,通过前向传播算法进行训练:
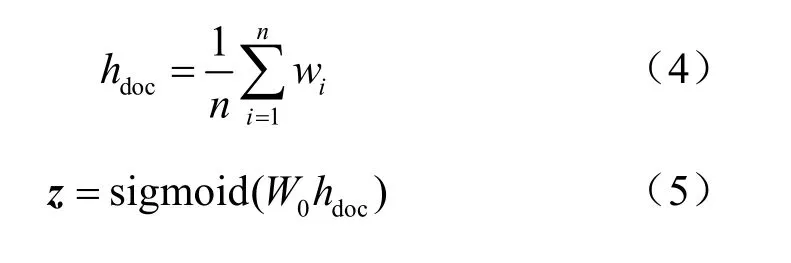
其中,z是一个向量,作为输出层的输入,W0是一个矩阵,存放模型隐含层到模型输出层的权重。
通常通过神经网络模型的输出层得到最终的分类类别时,采用softmax作为激活函数,将输出层的每个预测值压缩在0到1之间并归一化。但随着分类类别的增加,softmax计算量也逐渐增加,为了减少训练时间,加快模型的训练过程,FastText使用每个分类类别的权重和模型的参数构建一棵Huffman树,形成了层次softmax,由于具有Huffman树的特点,很大程度上提高了模型的训练效率。
FastText模型的隐含层对每个特征词的词嵌入进行累加后求均值,如果打乱词的顺序,该累加后求均值的方法并不影响隐含层的输出,但失去了语言模型的上下文关系,如:“马上”和“上马”实际含义并不相同。在统计学语言模型中,N-gram算法采用的是滑动窗口法,取一个长度为N的窗口,按照字或词依次滑过文本,生成片段序列,在FastText模型前向传播过程中,把采用N-gram生成的片段序列表示成向量,也参与到隐含层的累加求均值过程中。然后所有的N-gram被Hash到不同的桶中,但是同一个桶共享嵌入向量,如图2所示。
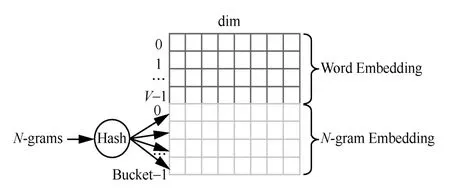
图2 Embedding矩阵
Embedding(嵌入)矩阵中的每一行代表了一个字、词或N-gram的嵌入向量,其中,前0到V-1行是词嵌入,后0到Bucket-1行是N-gram嵌入。经过大小为N的滑动窗口生成的片段序列被哈希函数作用后,被分散到0到Bucket-1的位置,得到每个片段序列的嵌入向量。
4 实验结果及分析
4.1 数据集预处理
本实验在公开数据集和私有数据集上进行。其中,公开数据集采用新浪新闻从2005年到2011年的历史数据,一共覆盖10类新闻,每类新闻包括65 000条样本。私有数据来源于某运营商已进行人工标注的29 084条投诉文本信息,这些投诉文本信息中包括了一些业务部门规定的基础的模板信息(如投诉时间、投诉事件、业务号码、投诉原因、用户要求、联系时间等),在对数据集进行特征提取前,需要对这些模板信息(如删除固定的符号、删除规定的规范用词等)进行初步的清理,投诉内容的原文以及对应的清理后的投诉内容见表2,这有利于初步降低特征词向量的维度、过滤无用符号等。

表2 用户投诉文本信息
由于投诉文本以最终分类到具体的业务类别为标准,进而供业务单位处理。某运营商在业务类别分类上采用多级标识,以“>”作为上下级分割符号,且各业务类别均表示得比较独立,因此将此投诉文本分类问题,定义为标签多分类问题而不是多标签分类问题。本实验样本已标记的数据分类类别共有89类,标签均为文本,需要对类别进行编码,部分类别编码后见表3。

表3 业务类别编码
从图3投诉数据集分类统计可以看出,本次实验数据集分布不均匀,业务类别记录数从51到3 546条,属于类别不均衡问题。此时,准确率不能作为最后分类模型效果评估的唯一标准,本文采用准确率(accuracy)、Kappa系数以及汉明损失(Hamming loss)作为评价模型好坏的指标。
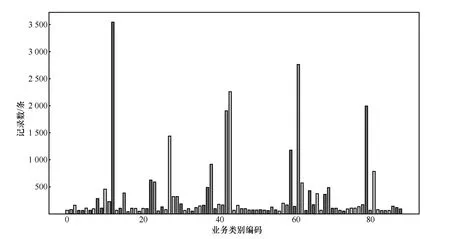
图3 投诉数据集分类统计
将实验样本数随机打乱顺序后,按7:3比例进行拆分,70%的数据作为训练集,用于模型训练;30%的数据作为测试集,用于模型验证。
4.2 特征提取
对中文文本数据进行特征提取前,需要对文本进行分词,本实验在采用jieba分词工具的精确模式对文本进行分词的同时,使用电信行业专用业务词汇作为用户词典和中文标准停用词,以提高分词的准确性。
使用GRW模型对用户投诉文本进行特征提取,提取出每个类别(标签)的特征词组,部分特征词组见表4。

表4 分类类别及对应特征词组
4.3 评价指标
二分类问题的评价指标通常为准确率、精确率、召回率、F1-score、AUC、ROC、P-R曲线等,多分类问题的模型评估方式有两种:第一种是将多分类的问题通过某种方式转化为N个二分类的问题;第二种是采用多分类指标。常见多分类问题评价指标如下。
(1)准确率
一般分类问题采用混淆矩阵来判断分类的效果,混淆矩阵如图4所示。
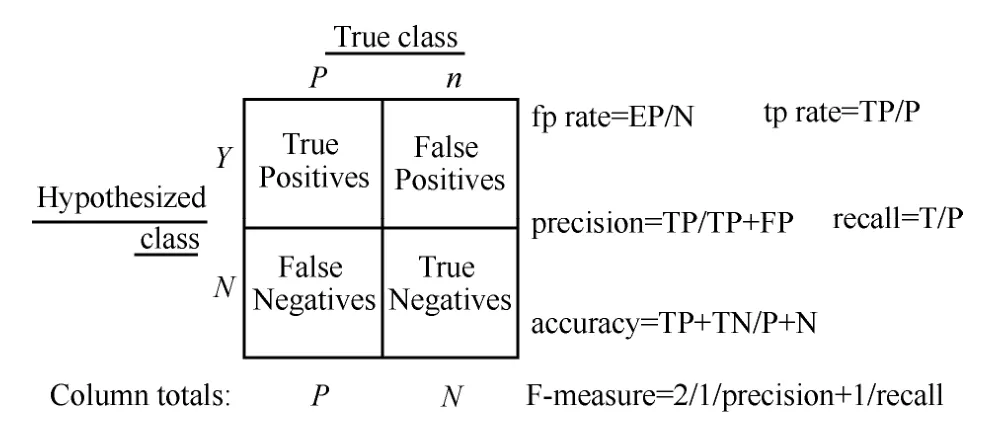
图4 混淆矩阵
其中,TP(true positives)表示预测对,实际也对;FP(false positives):表示预测为对,实际为错;TN(true negatives):预测为错,实际为错;FN(false negatives):预测为错,实际为对。准确率(accuracy)计算式如下:
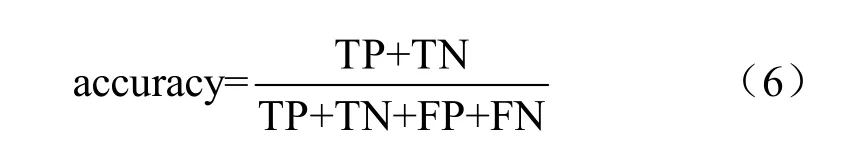
(2)Kappa系数
Kappa系数用于衡量多项独立指标的一致性(可靠性),表示具有有限范围的任何统计量的重新定标,形式为(S-SR)/ max(S-SR),其中SR是在随机性假设下的S值。Kappa系数取值范围为-1到+1,值越高,代表模型实现的分类准确度越高。
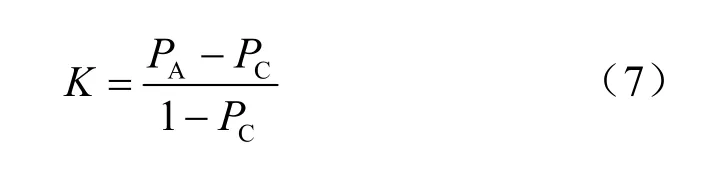
其中,PA是总体分类精度,PC=P2+P′2,P是所有分类的比例,和为1。Kappa系数及一致性等级对应关系见表5。

表5 Kappa系数及一致性等级对应关系
(3)汉明损失[10]
汉明损失考查实例标签被错误分类的情况。对于给定的向量f和预测函数F,汉明损失函数计算式如下:
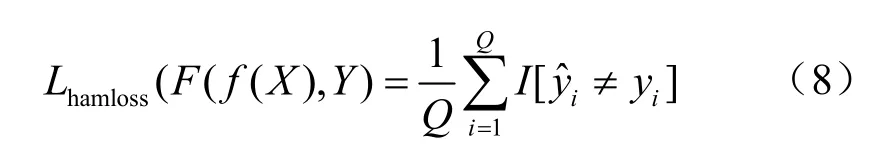
其中,

汉明损失计算可描述为相关的分类标签不在已预测的分类标签集合中,或者描述为无关的分类标签在已预测的分类标签集合中,因此,汉明损失指标值与模型的分类能力呈现正相关性。
4.4 结果分析
本实验分别采用词袋模型和朴素贝叶斯模型、Embedding和双向LSTM模型、预训练Bert模型、FastText模型作为基础模型在公开数据集和私有数据集上进行训练,再用GRW模型对特征进行提取后,结合FastText模型在训练集上进行训练,最后在同样的测试集上进行验证,结果见表6、表7。
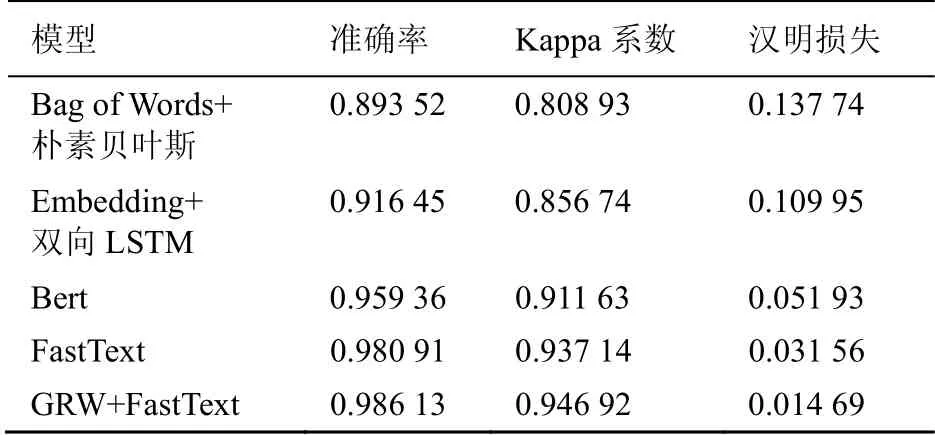
表6 模型对比(公开数据集)
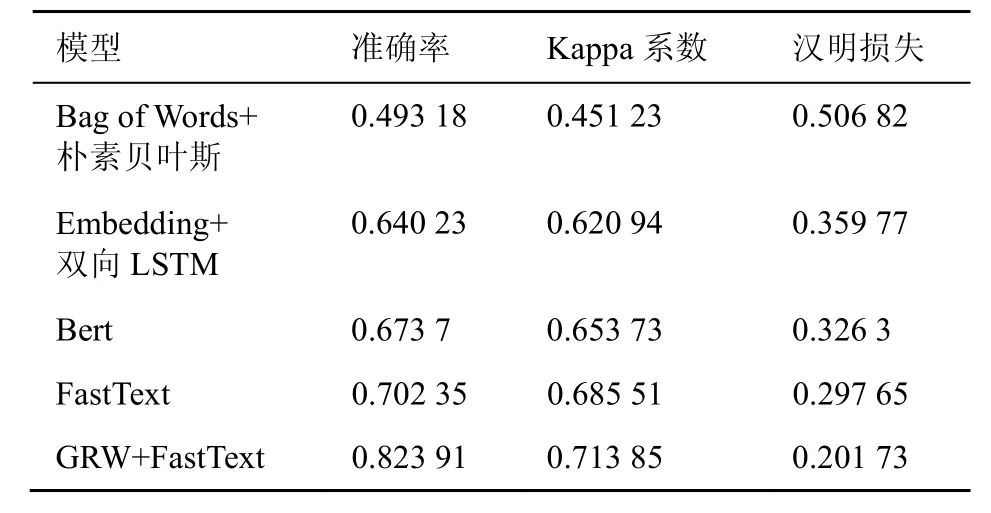
表7 模型对比(私有数据集)
对实验结果进行比较分析可以看出,本文提出的基于GRW模型和FastText模型的分类方法在准确率、Kappa系数、汉明损失等指标上,比其他几个模型有所提升,主要在于GRW模型在特征词的提取上,进一步优化了特征词的重要性。
4.5 应用效果
2020年10 月在某运营商采用本文提出的模型对电信用户投诉文本进行分类,分别从“5G”“携号转网”和“橙分期”3个专题投诉分析过程中验证模型。10月“5G”大类投诉共656件,“携号转网”大类投诉共508件,“橙分期”大类投诉140件,采用人工对这3类进行投诉类别细分,平均耗时1 min/件,准确率为90%。采用本文提出的模型进行自动分类后,总共耗时不到2 s,准确率达86%,接近人工分类准确率,提高了业务人员工作效率,缩短了投诉处理时长。
5 结束语
本文提出了一种基于GRW模型和FastText模型的文本分类方法,并应用于电信用户的投诉文本分类问题中,在实验结果对比上,基于GRW模型和FastText模型的方法比Bag of Words+朴素贝叶斯模型、Embedding+双向LSTM、Bert和Fast模型在准确率、Kappa系数、汉明损失上有所提升。GRW模型是加权的TF-IDF模型,在数据分析过程中有较好的准确性和解释性,使用FastText模型进行投诉文本分类具有较快的分类速度和较好的准确率。综上,使用本文提出的方法,有利于业务人员快速识别投诉业务类型,进行针对性的业务受理和用户服务,以提升用户感知。
猜你喜欢
计算机技术与发展(2018年8期)2018-08-21
民族古籍研究(2018年1期)2018-05-21
中国机械工程(2017年22期)2017-12-02
中国铁路文艺(2016年6期)2016-05-14
新校长(2016年8期)2016-01-10
中文信息学报(2015年4期)2015-04-21
浙江大学学报(工学版)(2015年1期)2015-03-01
应用数学与计算数学学报(2014年4期)2014-09-26
中国中医药现代远程教育(2014年16期)2014-03-01
武陵学刊(2011年5期)2011-03-20
