
数据驱动型智库研究理念及建设路径
2021-07-12 03:12欧阳剑周裕浩
智库理论与实践 2021年3期
关键词:大数据
欧阳剑 周裕浩
摘要:[目的/意义]传统的社会科学研究范式是理论驱动型的研究,随着大数据时代的来临,数据驱动研究成为一种新趋势,数据驱动的研究模式给传统领域的研究带来了新的研究方法与范式。大数据给当今的智库研究带来了挑战,同时也为以数据为驱动的智库研究提供了新的契机,数据驱动型智库建设是加强中国特色新型智库建设的方向之一,本文尝试从数据驱动型智库建设出发,探讨数据驱动型智库形成渊源、理念内涵,并对数据驱动型智库建设路径进行了分析,探索其建设思路。[方法/过程]本文通过对数据驱动型智库建设的渊源分析,探讨数据驱动型智库研究理念,从智库研究范式、数据建设、智库的组织结构及运行机制等角度对数据驱动型智库建设与智库服务等方面进行分析。[结果/结论]本文提出了转变传统研究范式、建立智库数据中台、健全智库大数据隐私保护体系以及提升智库影响力等建设路径,对我国传统智库建设和服务的转型具有一定的借鉴和参考意义。
关键词:数据驱动研究 特色智库 大数据 辅助决策
分类号:C932.4
DOI: 10.19318/j.cnki.issn.2096-1634.2021.03.03
1 引言
智库(think tank)是指由专家组成的为决策者处理社会、经济、科技、军事、外交等方面的问题出谋划策,并提供最佳理论、策略、方法、思想等的公共研究机构,是影响政府决策和推动社会发展的一支重要力量[1]。
传统的智库研究是理论驱动型的研究。随着大数据时代的来临,数据驱动研究成为一种新的趋势,数据驱动的研究模式给传统领域的研究带来了新的研究方法与范式。在大数据技术快速发展的背景下,树立数据驱动型智库研究理念与加强中国特色新型智库建设的方向是一致的,数据驱动型智库的建设以数据为支撑,以数据驱动为决策模型,其核心是描述数据内容,揭示数据内容之间的关联,发现数据内在规律,为智库决策者提供所需的信息和建设性结论。
2 数据驱动型智库渊源探析
美国智库学者詹姆斯·史密斯(James Smith)认为,1865年10月,来自全国各行各业近百名改革者聚集于波士顿的马萨诸塞州议会大厦探讨贫困救济、失业、公共卫生等诸多问题,标志现代智库的诞生[2]。随着科学技术的发展,电子计算机的出现为智库的决策服务提供了科学预测工具,20世纪50年代早期,美国兰德公司的威利斯·威尔自主设计出计算机JOHNNIAC,通过不断改进算法,引进并开发出配套的计算机软件、数据库,最终组成智库辅助决策系统,在当时冷战背景下,作为美国空军的智库大脑,兰德公司的决策服务有力地保障了美国的国家安全[3]。20世纪60年代以来,在系统工程学的迅速发展下,学者相继提出了福雷斯特-梅多斯模型(The Forrester-Meadows models)、梅萨罗维奇-佩斯特尔模型(The Mesarovic-Pestel model)、巴里洛切模型(The Bariloche model)、世界银行模型(The World Bank model)等多个定量分析模型[4],进而辅助决策研究,成为了现代数据驱动型智库服务的先驱。在早期的信息技术时代,智库仅仅实现决策信息化,数据处理在粒度层级上相对粗糙,无法进行更深层次的数据分析与挖掘。随着信息技术的快速发展,计算机处理能力得到极大的提升,数据处理的粒度层级精细化,同时,信息产业革命促进了数据急剧增长,大数据时代为数据挖掘等提供了足够的样本数据,数据处理技术的大规模应用保证了数据的快速性和准确性,这使得提供基于数据驱动的决策服务成为可能,基于数据驱动的决策服务被各类智库广泛应用。2004年,帕兰提尔科技公司(Palantir Technologies)向美国军方提供用于反恐的情报数据挖掘软件以及数据分析技术,通过分析政府提供的数据为美国反恐提供决策支持[5]。部分全球顶级智库目前也已建立较为完备的数据支撑体系,例如美国兰德公司近年来一直注重数据驱动型智库建设,兰德公司智库数据体系主要类型包括:自上而下建设的宽领域数据体系、自下而上建设的项目数据体系及双向综合参与型智库数据体系,保障兰德公司能够快速、准确地满足客户要求[6]。随着数据挖掘技术的快速发展和广泛应用,基于數据驱动的预测分析成为决策的必要步骤,数据驱动型智库服务已对商业运营、国际反恐、疾病应对、教育管理、国防建设等多个方面产生重要影响。
国内数据驱动型智库的发展从基于信息化决策向数据驱动决策方面演变。现代中国智库兴起于改革开放初期,1986年8月15日,时任国务院副总理万里在全国软科学研究工作座谈会上指出[7],“我们至今仍然没有建立起一整套严格的决策制度和决策程序,没有完善的决策支持系统、咨询系统、评价系统、监督系统和反馈系统。决策的科学性无从检验,决策的失误难以受到及时有效的监督”。这次讲话指出了当时国内智库服务存在的问题,标志着中国智库服务向科学化转型。20世纪80年代国务院发展研究中心利用可计算的一般均衡模型进行政策模拟分析,例如去预测世界贸易组织成员资格和养老金替代率改革的影响[8]。20世纪90年代DRC研发出宏观经济智能决策支持系统,用于预测经济发展趋势、监测经济系统运行和规划经济发展,为决策部门提供定量参考依据[9]。
进入21世纪,大数据技术的出现使得智库能够提供更多基于数据驱动决策的服务。广西大学通过建立中国-东盟大数据平台,将海量、动态、多样的数据有效集成为有价值的信息资源,服务于“一带一路”建设等国家决策需求[10]。华中农业大学宏观农业研究院通过建立宏观农业大数据平台,融合不同类型的大数据和整合数据驱动的多学科研究方法,实现对农业系统的预测、预警与监控以及风险管理,并支持个体与政府的决策[11]。国务院发展研究中心李望月等研究员将大数据乡村画像技术应用到乡村振兴的热点研究中,探索了大数据乡村画像未来的研究方向,为国家乡村振兴战略提供了技术支撑[12]。
党的十九届三中全会提出,要完善以科技支撑的社会治理体系,在此背景下,智库服务作为国家战略、公共政策、产业规划中不可或缺的一环,有必要转变传统的智库决策范式,以数据驱动作为决策支撑,不断提高智库服务的前瞻性和科学性。
3 数据驱动型智库研究理念及内涵
美国学者福斯特·普罗沃斯特(Foster Provost)和汤姆·福西特(Tom Fawcett)将数据驱动决策(data-driven decision)定义为“将决策建立在对数据的分析之上,而不是纯粹基于直觉的实践”[13]。张耀明认为数据驱动是通过移动互联网或者其他的相关软件为手段,对海量数据收集、整理、提炼并总结出一套规律,这一规律在数据的基础之上经过训练和拟合形成辅助决策模型[14]。数据是决策模型的基础,以原始状态保存,数据能否成为信息取决于人的理解,即在表达数据的意义后形成信息,信息尽管揭示了数据的意义,但是单独的信息难以对未来的行动产生有效影响,需经过分析模型的自动聚类分析,生成在特定情境下有针对性的情报,大量的情报在经过训练与筛选之后建立知识库,知识库作为有用信息的集合,可用于指导最终行动,决策模型根据实时知识库和已建立的决策规则产出可视化的决策参考,而每一个决策被实施之后的结果都会转化为新的数据,重新输入到决策模型中,这是一种自下而上的知识发现过程,是在没有理论假设的前提下去预知社会和洞察学术趋势[14]。
由此可见,数据驱动型智库是指运用大数据、云计算等技术,以数据为生产资料,以数据驱动为决策模型,将海量、动态、多样的数据有效集成为有价值的信息资源,推动精细化和科学化决策,其核心是描述数据内容,揭示数据内容之间的关联,发现数据内在规律,为智库决策者提供所需的信息和辅助参考结论。数据驱动型智库是传统智库研究的延伸与发展,是智库适应大数据背景下的发展趋势。
传统的智库研究范式是理论驱动型的研究,数据驱动型智库加入了以数据驱动为辅助决策模型的决策理念,这是区别于传统智库研究的根本标志。从研究方法论的角度上看,传统智库在提供智库服务的过程中,问题、假设、思路、方案等的提出是基于经验性的判断;数据驱动型研究则用严谨的数学模型、严密的逻辑推理去仿真和推演基于经验性的判断。只有定性分析会导致决策方案缺乏科学严谨性;只有定量分析会失去研究的方向,因为经验性的判断需要通过定性分析产生。因此,数据驱动型智库需采用定性定量相结合、人机协同的研究方法,数据能更好地帮助发现其中的规律和认知规律之间的关系,基于数据的方法为我们提供了感知研究对象的量化维度,智库可以借助数据挖掘出更多的因果解释机制,为决策者提供新方案、新视角、新思路。
实现数据驱动的前提条件是去人性化,即数据的不可篡改性以及决策规则的首要性。数据在被大量采集后必须进行原始保存,以保证辅助决策模型的决策精度不受人为影响,且数据的原始性决定了辅助决策模型不需要等待人为给定数据,从而提高了决策的速度和客观性。此外,辅助决策模型的核心是决策规则的建立,决策规则的首要性是指规则本身的重要性大于后续人为管理的重要性,盡管决策规则是人为建立的,但是在进行同类型的决策服务时决策规则不应随意改变,否则会导致决策精度出现较大偏差。决策规则必须基于已采集数据,即在分析海量数据的内容关联的基础之上建立决策规则。
IBM商业价值研究所(IBM Institute of Business Value)和牛津大学萨伊德商学院在2012年对来自26个行业、95个国家的1,144名专业人士进行研究发现,63%的公司认为基于信息(包括大数据)分析的使用正在为其组织创造竞争优势,而在两年前进行的一项类似研究中,这一比例仅仅为37%,仅仅两年就增长了70%[15]。在大数据迅速发展的背景下,智库开始朝着基于数据驱动的方向转型,突出决策科学化、决策快速化。2015年中共中央办公厅、国务院办公厅印发的《关于加强中国特色新型智库建设的意见》指出,随着形势发展,智库建设跟不上、不适应的问题也越来越突出[16]。在当今信息碎片化时代背景下,解决上述问题,需要采用新的研究范式,采用定性分析和定量分析相结合的研究方法,加强以科技创新、数据驱动为支撑的智库建设。
4 数据驱动型智库建设路径
进入大数据时代,数据生产、收集和存储的方式发生了根本性的变化,数据驱动型智库研究的主要任务是如何从大量信息资源中挖掘出有价值的信息,并通过科学的方法将信息转变成为决策建议,从而满足决策服务的需要,实现智库从理论驱动型到数据驱动型的迈进,探索合适的数据驱动型智库建设路径是其中重要的一环。
4.1 数据驱动型智库研究范式转变
经验性的研究范式是人类的思维、经验、知识的表达成果,作为智库服务顶层设计不可缺少的一环,融合了不同学科专家的思维和知识。经验性研究范式需要通过有针对性的数据模型去验证,实现从抽象思维到形象思维的转变,尽管可以通过验证的结果去推翻基于经验性的判断,但是这属于一个去伪存真的过程,通过否定一些判断,从而提炼出新的思维,这是从定量分析向定性分析的一种反馈,从而帮助改进顶层设计,保证从理论到实践这一过程的过渡。计算机技术快速发展,使得数据模型从由单纯的数学模型发展到数学模型和计算机模型高度耦合,分析模型建立在经验性判断的前提下,经验性的判断不具备普遍适用性,对于每一类问题,均需重新建立分析模型,然而分析是一个受各种因素影响的高度复杂的认知过程,这就意味着根据问题提供思路和方案的专家学者必须尽可能地考虑到作用于分析模型的影响因素,也意味着对定性分析的过程提出了更高的要求。
数据驱动型智库的研究是适应大数据的研究理念与新思维,是对传统智库研究范式的升级。大数据时代日益复杂的公共政策和区域安全等问题,使社会治理面临巨大挑战,智库服务作为社会治理决策的重要一环,需要创新智库研究思维,传统智库有必要打破原有以思想表达为主的经验性研究范式,迈向建立以客观事实为核心驱动力的大智库形态[17]。经验性研究范式尽管仍然遵循“数据—信息—知识—经验”的成长模型,但因为缺少实时反馈学习机制,从数据转换到经验需要时间成本,所以单纯的经验性研究范式无法跟上快速变化且日益复杂的社会治理需求。而所谓客观事实包含在大量的数据之中,这是由数据的原始性决定的,社会治理面临的问题可以透过数据看到本质。从定性分析上升到定量分析,并不意味着彻底放弃定性分析,因此,数据驱动型智库需采用定性定量相结合、人机协同的研究方法,在保留专家论证制度的基础上,必然朝着以数据为驱动、以技术为支撑的大数据解决方案转型。
4.2 数据驱动型智库数据平台建设
数据是数据驱动型研究的核心,数据建设是智库建设的重要内容,从智库数据建设现状上看,马普学会、兰德公司和美国农业部国家粮食与农业研究院都已建立了较为完善的数据资源库。然而,高咏先调研发现,国内高校智库数据库建设存在建库比例低、体系不完善、知识库建设缺乏、合作共享不足等多个问题[18],若不重视上述的问题,势必影响基于数据驱动的智库建设。数据驱动型智库需充分利用智能抓取、数据挖掘等信息技术对相关信息进行采集、筛选,扩大智库数据资源类型及数量,创新数据资源架构,优化提升基础设施保障水平,构建集数据采集、分析、展示与共享于一体的大数据平台。在数据的建设、处理、分析挖掘和推荐等环节,加强对大数据技术的引入和应用,实现对非结构化数据的处理和分析,提供切实可行的数据模型和算法及更多元化的研究成果展示方式,提高决策效率和咨政效果。
为了促进数据驱动型智库发展,有必要通过建立智库数据中台,打通智库内部数据孤岛,聚合和治理跨域数据,从而驱动智库服务的转型,匹配研究热点需求。数据中台核心思想是数据共享,阿里巴巴集团[19]、数澜科技等认为,数据中台是一套可持续“让企业的数据用起来”的机制,是一种战略选择和组织形式 [20]。数据中台作为智库各个团队所需要数据服务的提供方,不断整合和提高数据服务能力,将数据作为生产资料投入到智库服务的开发中,为智库实现服务价值提供源源不断的生产力。
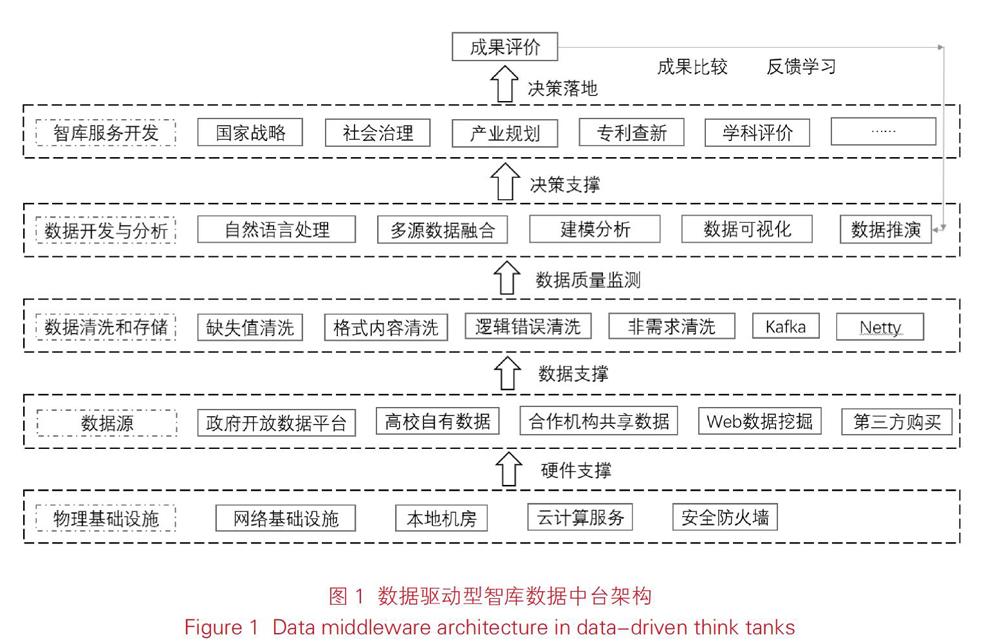
智库数据中台作为一个数据共享及分析平台,通过将文献、音频、图像等非结构化的数据资源进行结构化处理,进而聚合跨域多源数据,解决智库数据驱动型研究面临的数据孤岛问题,建立数据挖掘、数据管理、数据共享等机制,再结合智库自有的跨学科人才专业优势,最终实现在服务转变加快的情况下,数据开发准确对接服务开发。思特沃克(Thought Works)公司对数据中台提出精益创新数据体系:数据资产的规划和治理、数据资产的获取和存储、数据资产的共享和协作、数据业务价值的探索和分析、数据服务的构建和治理、数据服务的度量和运营[21]。笔者根据该数据体系,结合传统智库向数字化转型的实际需求,缩短智库从数据开发到服务落地的周期,提出了智库数据中台架构(见图1)。智库数据中台架构分为5层结构。第1层结构,物理基础设施提供了强大的数据存储和共享能力,在获取多源数据时,由于智库不同团队所关注的数据指标存在差异,要规划数据全景图,对智库服务有价值的数据先进行规划,统一各领域的智库服务标准。第2层结构,大数据经过清洗等步骤后,在数据中台采用大数据技术,利用Netty等网络通信库构造高性能的收集端网络通信处理服务进行数据传输和存储,剥离出网络通信业务中耗时操作并将数据推送至流式消息处理系统中,再由消息处理系统消费者负责后续数据持久化、实时分析工作[22]。第3层结构,对数据进行质量检测并建立数据质量评估体系,动态监测数据质量,降低大数据噪声,保证数据和后续智库服务的产出。第4层结构,进入数据开发与分析阶段,建立决策支撑系统,数据中台运用知识图谱等自然语言技术自动化处理多源数据,揭示数据内容之间的关联,建立数据模型,发现数据内在的发展规律,实现数据可视化,在提供智库决策支持的同时,还可实现基于数据的结果推演,与最后的落地成果进行比较。第5层结构,实现实时成果反馈功能,从实现数据驱动智库服务的视角看,项目产生数据,数据服务项目,形成闭环,可实时满足智库团队知识发现的要求。
4.3 数据驱动型智库组织结构及机制建设
数据驱动型智库的组织结构与传统智库的较大区别,首先在于加入了数据中台,通过数据中台提供数据服务,降低运营成本的同时提升研究效率,其次在于采用流程型组织结构,在运行机制上,项目团队拥有较大的自主决策权,团队负责人可决定研究方向和路径,以服务对象为中心,采用流程化的业务模式,一个团队负责一个服务对象,从而使得数据驱动的智库组织结构及机制有别于传统智库。
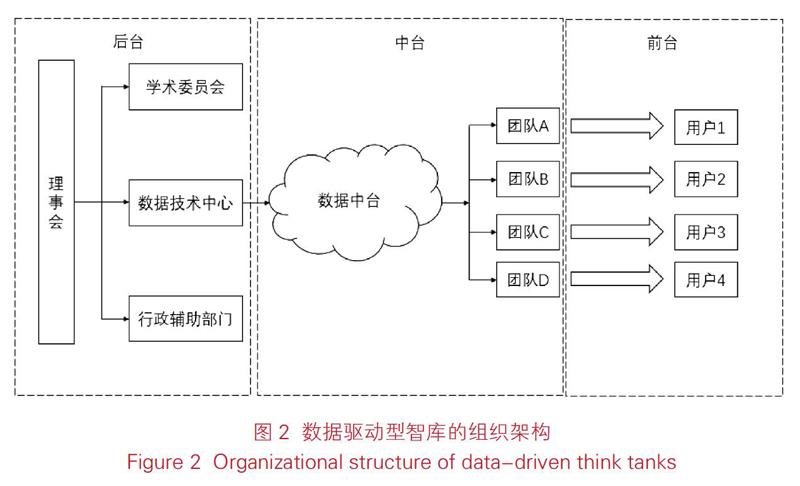
4.3.1 数据驱动型智库的组织架构 传统智库的组织架构主要由3大部分组成:管理监督部门、行政辅助部门,以及研究开发部门。例如北京大学国家发展研究院设有理事会、学术委员会、学院领导等管理监督部门,行政系统以及研究中心,研究中心下设11个专门研究团队[23]。笔者以北京大学国家发展研究院组织架构为基础,通过引入数据中台,构建数据驱动型智库组织架构。数据驱动型智库的组织架构分为前台、中台和后台(见图2)。后台部门由理事会统筹智库的定位、发展方向;行政辅助部门对智库财务、对内协调、对外联络、人力资源以及服务成果转化等方面提供支持;学术委员会审议团队研究成果,对项目团队起到监督作用;技术支撑则是数据驱动型智库组织结构的一大特点,数据技术中心负责数据中台的数据建设与维护,并及时为所有团队提供技术支持。在中台方面,数据中台为所有项目团队提供从数据收集处理到数据开发与分析的全部功能。此外,流程型组织拉近了项目团队与前台用户之间的距离,项目团队根据用户需求,提供基于数据驱动的全流程智库服务。
4.3.2 数据驱动型智库运行机制 智库后台的学术委员会、行政辅助部門以及数据技术中心实际上属于传统的职能部门,在用户需求转变的周期越来越短的情况下,必然会出现后台的数据开发与前台的服务开发不相匹配的情况。数据中台的加入,解决了智库前台和后台开发速度不一致的情况。智库数据中台的优势是实现数据共享,同时,以用户为中心的项目团队只需要专注于提供全流程智库服务,因此可以精简项目团队的规模,也方便快速重组成新团队以匹配新的用户需求。此外,轻量化的团队具备快速试错的能力,即从数据中发现用户需求,然后快速决策、快速攻关、快速把智库服务推向市场,当成果评价反馈智库服务并不能满足用户的需求后,迅速对项目在多维度上进行调整,再进行新的尝试。这一模式与斯坦福大学胡佛研究所的运行机制类似,每个项目的负责人都由该领域的权威专家担任,对于机构中的临时项目则由具有不同背景、不同技能、不同知识、不同部门的常任研究员组成临时项目组,一旦该项目完成,项目组的使命便结束,下一次任务又会重新组织项目组,这种长期项目人员和临时项目研究人员构成了机构的矩阵式研究队伍,保证了组织研究的灵活性和全面性[24]。
4.4 数据驱动的智库大数据隐私保护体系建设
基于数据驱动的智库决策服务发展过程中也面临一些新的问题:一方面智库大数据的内部或者外部共享对于数据驱动的智库服务是必要的;另一方面数据的共享可能会导致用户隐私数据泄露。面对数据共享与数据保护之间的矛盾,有必要从制度和技术两个维度上建立智库大数据隐私保护体系,以解决传统智库向数据驱动型智库转型所面临的问题。
4.4.1 技术是智库大数据隐私保护体系的基础 数据共享是数据中台数据利用的重要方式,也是数据驱动型智库的重要基础,而数据保护则成为重要议题,数据匿名及脱敏化处理等成为重要手段,常见解决的办法是引入差分隐私,通过对数据加入噪声,确保对数据库进行单一的数据删除或添加等操作不会影响数据分析的结果,从而提供了一种严格的数学方法来处理可能公开的数据[25]。查米卡拉(Chamikara)等学者基于切比雪夫(Chebyshev)插值和拉普拉斯(Laplacian)噪声,提出一种利用本地差分隐私的安全高效的数据扰动算法,可以在数据隐私和效用之间实现良好的平衡,并具有高效和可扩展的特性[26]。目前,差分隐私技术已广泛应用于数据收集[27]、数据挖掘[28]、数据分类(决策树)[29]等大数据隐私保护研究。智库服务发展中出现的问题需要用发展的技术去解决,差分隐私等技术的应用,为智库在面对数据隐私泄露或被窃取时提供了应对的手段,是智库大数据隐私保护体系的基础。
4.4.2 制度是智库大数据隐私保护体系的核心 技术手段的应用杜绝了客观数据隐私泄露的风险,人为主观泄露数据隐私的因素仍然存在。首先,在国家法律法规的指导下,智库应建立数据安全管理制度,通过接入ISO/IEC 27001信息安全管理体系国际认证,外部对政府监管机构以及客户实现智库在数据管理方面的安全承诺,内部实现智库各项目团队之间的管理制度透明化、标准化,使内部成员之间信任关系更加牢固;其次,智库内部的理事会成立数据安全团队,数据技术中心成立数据安全小组,可每一个项目团队指定一名兼任数据安全员,形成从决策层、管理层到执行层的三级数据安全组织架构,同时,学术委员会和行政辅助部门也参与到数据安全的建设中,目的是让每一位成员知悉数据保护的政策,明确不同部门的数据权限,以降低人为主观泄露数据隐私的可能。数据安全管理制度的建立,可提高智库的安全防护能力,是智库大数据隐私保护体系的核心。
4.5 数据驱动型智库影响力建设
智库影响力是指以直接或间接的方式作用于公共政策,使决策者或决策过程发生改变,最终影响政策输出的能力[30]。智库作为咨询研究机构,为满足跨领域的咨询需求,其角色位置逐渐向各领域边际融合,成为政府、企业、高校和社会之间的纽带和桥梁。从这一角度看,要想提高智库成果影响力,就必须尽可能地吸纳不同学科和领域的思想,才能提出各方均认可的政策方案。
4.5.1 大数据是智库影响力传播的保障 与传统智库相比,数据驱动型智库建立的时间较短,在前期智库影响力上处于弱势,但数据驱动型智库拥有后天技术优势,大数据技术是智库影响力传播的保障。随着国内的咨询需求向与公众密切相关的公共政策倾斜,智库也尝试通过社交媒体和民众进行互动、交流,从而宣传智库成果,提高智库影响力。在国家治理建设的进程中,党和国家越来越认可社会公众的地位,重视他们的“声音”[30],通过大数据技术,感知民众的需求热点,进而提供相匹配的互动内容,提升了智库的社会知名度,也为数据驱动型智库进入政府核心决策层打下基础。此外,对需求热点精准分类,自下向上引导智库服务与需求热点匹配,有利于提高数据驱动型智库影响力。
4.5.2 组建面向“政用产学研”的数据驱动型智库联合体 数据驱动型智库的核心是数据,数据流通环节还面临着数据格式不一致、来源不一致、质量不一致等难题,进而影响智庫服务,削弱智库影响力。数据驱动型智库联合体由各类智库(党政部门、社科院、科研院所、高校、企业、社会)单位组成,本质上数据驱动型智库联合体是一个数据协同创新平台,通过聚合各单位自有数据资源,打通“政用产学研”上、中、下游数据,实现数据驱动型研究与最终用户的对接与耦合。“政用产学研”是一种创新合作系统工程,智库联合体中各单位分工明确,政府引导政策落地,推动构建合作平台、数据交易平台;用户作为智库服务的对象,通过智库服务成果评价,反馈智库服务效果;企业属于生产环节,是智库服务落地的重要途径;高校在教学和科研领域提供智力支持和人才储备。因此,仅通过人才流动来支持数据流通是不够的,需联合不同类型的单位组建数据驱动型智库联合体,从政策、管理、技术等多个维度解决数据流通问题。数据驱动型智库联合体作为社会各方的桥梁和纽带,创新了一些合作模式。例如,2018年4月成立的国家信息中心数字中国研究院采用理事会制运作模式,由国家信息中心主导,多家高校院所、出版传媒单位、大数据企业和金融机构等单位组成,扩大智库成果的影响力。
5 结语
数据驱动型智库建设是加强中国特色新型智库建设的方向之一,是提升中国高端智库核心竞争力的重要途径,应该顺应信息环境的发展,转变传统智库研究思维模式,加强数据建设,建立智库大数据隐私保护体系,实现传统智库转型,健全数据驱动型智库的组织结构及运行机制,以智库数据中台为核心提供基于数据驱动的智库决策服务,最后通过提升数据驱动型智库影响力,使其成为实现社会创新治理、服务政府公共决策的中坚力量。
参考文献:
[1] 李建军, 崔树义. 世界各国智库研究[M]. 北京: 人民出版社, 2010.
[2] SMITH J A. Idea brokers: think tank and the rise of the new policy elite[M].New York: Simon and Schuster, 1993.
[3] [美]亚历克斯·阿贝拉. 兰德公司与美国的崛起[M]. 梁筱芸, 张小燕, 译. 北京: 新华出版社, 2011: 108.
[4] RICHARDSON J M. Global modelling 1. the models[J]. Futures, 1978, 10(5): 386-404.
[5] THIEL P A, MASTERS B. Zero to one: notes on startups, or how to build the future[M]. New York: Broadway Business, 2014: 108.
[6] 勇美菁, 鐘永恒, 刘佳, 等. 支撑兰德公司的智库数据体系建设研究[J]. 情报理论与实践, 2019, 42(9): 69-75.
[7] 万里. 决策民主化和科学化是政治体制改革的一个重要课题: 在全国软科学研究工作座谈会上的讲话[N]. 人民日报, 1986-08-15(1).
[8] BARRY N. Chinas economic think tanks: their changing role in the 1990s[J]. The China quarterly, 2002(171): 625-635.
[9] 于景元, 涂元季. 从定性到定量综合集成方法: 案例研究[J]. 系统工程理论与实践, 2002, 22(5): 1-7, 42.
[10] 中国-东盟信息港大数据研究院[EB/OL]. [2020-03-20]. http://cabd.gxu.edu.cn/?tdsourcetag=s_pctim_aiomsg#/summary.
[11] 宏观农业研究院[EB/OL]. [2020-03-20]. http://mari.hzau.edu.cn/about_us.htm.
[12] 李望月, 刘瑾, 陈娜. 大数据技术在乡村画像中的应用研究[J]. 大数据, 2020, 6(1): 99-118.
[13] PROVOST F, FAWCETT T. Data science and its relationship to big data and data-driven decision making[J]. Big Data, 2013, 1(1): 51-59.
[14] 张耀明. 人工智能驱动的人文社会科学研究转型[J]. 济南大学学报(社会科学版), 2019, 29(4): 20-28, 157.
[15] SCHROECK M, SHOCKLEY R, SMART J, et al. Analytics: the real-world use of big data: how innovative enterprises extract value from uncertain data[R]. IBM Institute for Business Value, 2012.
[16] 中国政府网. 中共中央办公厅、国务院办公厅印发《关于加强中国特色新型智库建设的意见》[EB/OL]. [2020-01-20]. http://www.gov.cn/xinwen/2015-01/20/content_2807126.htm.
[17] 陈潭. 从大数据到大智库: 大数据时代的智库建设[J]. 中国行政管理, 2017(12): 42-45.
[18] 高咏先. 国内高校智库数据库建设现状及图书馆服务策略研究[J]. 图书情报工作, 2017, 61(10): 43-49.
[19] 谭虎. 详解阿里云数据中台[N]. 中国信息化周报, 2019-10-28(14).
[20] 付登坡. 数据中台: 让数据用起来[M]. 北京: 机械工业出版社, 2019.
[21] 缪翀莺, 谭华, 易学明. 数据中台的定位和架构分析[J]. 广东通信技术, 2019, 39(12): 57-62, 70.
[22] 甄凯成, 黄河, 宋良图. 基于Netty和Kafka的物联网数据接入系统[J]. 计算机工程与应用, 2020, 56(5): 135-140.
[23] 北京大学国家发展研究院[EB/OL]. [2020-11-06]. http://nsd.pku.edu.cn/xygk/zzjg/gjfzyjylsk/index.htm.
[24] 方婷婷. 美国大学智库影响力和运行机制研究: 以斯坦福大学胡佛研究所为例[J]. 高校教育管理, 2014, 8(4): 37-40, 60.
[25] DWORK C. Differential privacy: a survey of results[C]//Proceeding of the 5th international conference on theory and applications of models of computation. Xian, China, 2008: 1-19.
[26] CHAMIKARA M, BERTOK P, LIU D, et al. An efficient and scalable privacy preserving algorithm for big data and data streams[J]. Computers & security, 2019(87): 101570.
[27] WANG T, MEI Y, JIA W, et al. Edge-based differential privacy computing for sensor-cloud systems[J]. Journal of parallel and distributed computing, 2020(136): 75-85.
[28] XIANG C, SU S, XU S, et al. DP-Apriori: a differentially private frequent itemset mining algorithm based on transaction splitting[J]. Computers & security, 2015(50): 74-90.
[29] FLETCHER S, ISLAM M Z. Differentially private random decision forests using smooth sensitivity[J]. Expert systems with applications, 2017(78): 16-31.
[30] 錢再见, 王力. 中国特色新型智库在政府决策中的影响力研究: 基于多维理论视角的学理分析[J]. 江汉学术, 2020, 39(2): 100-109.
作者贡献说明:
欧阳剑:论文构思、框架搭建、修改;
周裕浩:资料查找,论文初稿撰写。
Research on Path of the Construction of Data-driven Characteristic Think Tank in China
Ouyang Jian1,2 Zhou Yuhao3
1Shanghai International Studies University Library, Shanghai 201620
2School of Journalism and Communication, Shanghai International Studies University, Shanghai 201620
3School of Management, Guangxi University for Nationalities, Nanning 536000
Abstract: [Purpose/significance] The traditional paradigm of social science research is theory-driven research. With the advent of the big data era, data-driven research has become a new trend, which also brings new research methods and paradigms to the traditional field of study. Big data brings challenges to the current think tank research, and it provides new opportunities for data-driven think tank research, too. The construction of data-driven think tanks is one of the directions to strengthen the new think tanks with Chinese characteristics. Starting with the construction, this paper attempts to explore the origins and conceptual content of data-driven think tanks, and to demonstrate its construction path and construction ideas. [Method/process] By analyzing the origin of data-driven think tanks construction, this paper explores the research concept, and also analyzes its construction and think tank services from the research paradigm, data construction, organizational structure and operation mechanism. [Result/conclusion] This paper puts forward some construction path, such as transforming the traditional research paradigm, establishing the think tank data center, improving the think tank big data privacy protection system, and enhancing the influence of think tanks, which provides certain reference for the construction and services transformation of traditional think tank in China.
Keywords: data-driven research think tank with new characteristic big data assisted decision making
收稿日期:2020-12-29 修回日期:2021-01-22
本文系国家社科基金项目“ ‘一带一路战略的东盟信息资源支撑及开发策略”(项目编号:16BTQ023)、广西民族大学研究生教育创新计划项目“数据驱动型智库建设理念及实现路径研究”(项目编号:gxun-chxps202091)研究成果之一。
作者简介:欧阳剑(ORCID:0000-0001-5867-2852),硕士生导师,研究员,博士,E-mail:oyjjj@163.com;周裕浩,情报学硕士研究生。
猜你喜欢
中国市场(2016年36期)2016-10-19
中国市场(2016年36期)2016-10-19
商(2016年27期)2016-10-17
今传媒(2016年9期)2016-10-15
今传媒(2016年9期)2016-10-15
新闻世界(2016年10期)2016-10-11
科技视界(2016年20期)2016-09-29
中国记者(2016年6期)2016-08-26
