
基于SentencePiece的中医学分词模型建模研究
2021-07-09 13:56刘双巧周璐李彩艳袁慧敏张异卓李昱达刘锦钢郑丰杰孙燕李宇航
世界中医药 2021年6期
刘双巧 周璐 李彩艳 袁慧敏 张异卓 李昱达 刘锦钢 郑丰杰 孙燕 李宇航

摘要 目的:探索构建适用于中医学领域的分词模型。方法:采用基于SentencePiece的无监督学习分词方法,提出利用出版教材、名家著作及中医临床病历这3种不同类型的文献构建中医学分词模型;选择中医临床病历、名医医案作为测试集进行模型测试。结果:中医学分词模型在测试集中的Kappa系数为0.79(一致性程度很高),准确率为0.84,宏观精确率为0.84,宏观召回率为0.83,宏观f1得分为0.83。结论:所构建的分词模型对于中医学专业术语有着较好的切分效果,表明该方法可运用于中医学领域的分词模型的构建,可为进一步地研究中医学分词提供方法学参考。
关键词 分词;中文分词;分词模型;无监督学习;无监督分词;SentencePiece
Research on Modeling of Traditional Chinese Medicine Word Segmentation Model Based on SentencePiece
LIU Shuangqiao,ZHOU Lu,LI Caiyan,YUAN Huimin,ZHANG Yizhuo,LI Yuda,LIU Jingang,ZHENG Fengjie,SUN Yan,LI Yuhang
(School of Traditional Chinese Medicine,Beijing University of Chinese Medicine,Beijing 100029,China)
Abstract Objective:To explore the construction of word segmentation model suitable for the field of traditional Chinese medicine (TCM).Methods:Using the unsupervised learning word segmentation method based on SentencePiece,we proposed to use 3 different types of documents,such as published textbooks,famous works and clinical medical records of TCM,to construct a word segmentation model of TCM; choosed the clinical records of TCM and medical records of famous doctors as the test set for model testing.Results:The Kappa coefficient of the word segmentation model of TCM established in this study was 0.79 (with substantial consistency),the accuracy rate was 0.84,the macro precision rate was 0.84,the macro recall rate was 0.83,and the macro f1 score was 0.83.Conclusion:The word segmentation model constructed by this study has a good segmentation effect on the terminology of TCM,indicating that this method can be applied to the construction of the word segmentation model in the field of TCM,and can provide a methodological reference for further study of TCM word segmentation.
Keywords Word segmentation; Chinese word segmentation; Word segmentation model; Unsupervised learning; Unsupervised word segmentation; Sentence piece
中圖分类号:R2-03文献标识码:Adoi:10.3969/j.issn.1673-7202.2021.06.024
中医学发展历程中产生了众多的医学文献,这些文献中蕴含着丰富的医药知识及临证经验,如何快速有效地从这些文献中提取信息并加以利用,是中医现代化研究过程中面临的一大难题。中文分词是信息处理过程中的基础与关键[1],词是最小的能够独立活动的有意义的语言成分[2],中文分词即是将没有天然分隔符号(如英文的空格)的汉字序列切分成词序列,如将“患者发热头痛三天”利用分词工具切分为“患者”“发热”“头痛”“三天”“。”,即提取句子中的词汇,以便于进一步实现LDA主题挖掘[3]、命名实体识别[4]、信息提取[5]、文本分类[6]等研究。因此,在中医学文献挖掘研究的过程中,对其文本作分词处理,可以为下一步研究工作打下基础。
在大众领域,已有多种开源且成熟运用的分词工具,代表性的如结巴中文分词[7]、语言技术平台(LTP)[8]、NLPIR-ICTCLAS汉语分词系统[9]等;除此之外,研究者们根据其研究领域的特色,运用条件随机场[10-11]、隐马尔可夫模型[12]、神经网络[10-11]、N-gram模型[13]等方式,对相关的中文文本进行切分,都取得了较好的分词效果。然而,对于具有众多专业术语的中医学而言,大众领域的分词工具在其专业性词汇的切分效果上存在不同的差异[14];并且也有学者发现,由于现有的分词工具对中药、方剂名词切分不准确,会影响下游作品的质量[15]。因此,研发适合于中医学专业领域的分词工具就显得尤为重要了。张帆等[1]运用层叠隐马模型,结合中医领域词典,提高了中医医案文献词语切分的准确率。许林涛等[16]则基于最大正向匹配分词算法,在中医临床四诊信息的词语切分上,得出最大分词数为5时的切分效果较好。付璐等[17]构建了一个小型的清代医籍人工分词语料库,并提出中医古籍分词规范建议,是对中医学分词标准的一个探索。虽然,中医学领域已有学者对中医分词展开相关研究,但还没有开发出针对性的分词工具。因此,本研究提出了一种基于SentencePiece的无监督学习的分词方法,探索构建适用于中医学领域的分词模型,为开发中医学专业领域的分词工具做准备。
1 基于SentencePiece的无监督学习分词方法
SentencePiece是一种简单且独立于语言的文本标记器和去标记器,主要用于基于神经网络的文本生成系统,其中在神经模型训练之前预先确定了词汇量。SentencePiece集合了字节对编码(BPE)和一元语言模型这2种算法,可以直接对原始语句进行训练。其特点是无需预先对源数据进行人工标注,可实现对模型参数的自动学习;可直接由源数据生成词汇表,清晰展示所学习到的词汇;对于无空格的源数据语言,有较好的分词效率;语言独立,具有多个分词模式;自动进行子词正则化,运行速度快[18]。自这种无监督学习的分词方法问世以来,已被成功运用于蛋白质序列切分[19]、机器翻译[20]等研究,可见,这是一种不区分语言类型的序列语言切分方法。将SentencePiece引入中医分词领域,研究构建中医学专业领域的分词模型,可以有效地提高中医文本的词语切分效果,可为中医分词工具的研发提供方法学参考。
2 资料采集
2.1 资料来源 本研究所用资料来源于录入计算机的全国中医药行业高等教育“十二五”规划教材《中医诊断学》《方剂学》《中医内科学》,名家著作《伤寒论诠解》《肝病证治概要》《经方临证指南》《伤寒论十四讲》《伤寒论通俗讲话》《新编伤寒论类方》《伤寒论临证指要》和《刘渡舟临证验案精选》,以及中国中医科学院“名医名家传承”项目管理平台[21]内的众多中医临证验案。
2.2 数据集 将收集的资料分为训练集、开发集、测试集这3个数据集。临证验案是中医理法方药信息的具体体现,且中医临床信息记录较为完善。因此,开发集与测试集的资料选择上,以医案为主,兼顾资料的公开性,选择《伤寒论临证指要》与《刘渡舟临证验案精选》中的名家医案205篇,中医临证验案173篇,共计378篇文档,作为模型测试数据,并随机分为开发集、测试集各189篇文档;其余资料归为训练集,做模型构建使用。各集字数及所占比例如表1所示。
3 实验方法
3.1 模型构建 1)程序准备:下载并安装Python 3.7.0(https://www.python.org/)、SentencePiece算法包(https://pypi.org/project/sentencepiece/),构建基于SentencePiece分词的Python程序环境,设计将模型分词结果保存为brat文本标注系统(http://brat.nlplab.org/)的存储格式,包括.txt格式文档和对应的.ann格式文档。2)模型训练:本研究基于SentencePiece构建中医分词模型,对包含出版教材、名家著作及中医临床病历这3种不同类型的文献所形成的数据集进行训练;其中,建模参数主要参照SentencePiece所推荐的建模参数,character_coverage(模型中覆盖的字符数)设置为0.999 5,model_type(训练使用的模型)设置为unigram,根据本研究实际情况,只调整“vocab_size(训练出的词库大小)”这一个参数值。模型训练包含2种方法:a.不对文本做去停用词处理,直接以构建的模型对未经加工的训练集原始数据作模型训练。b.在模型训练之前,通过调整参数,构建多个中医分词模型。预先设置从1万词汇量开始,每训练一次增加2万词汇量。根据以上2种方法,依赖训练集数据,共训练出11个分词模型,对应生成11个可视化分词词汇表。3)筛选建模参数:利用开发集评价不通模型的分词效果,筛选出最佳的建模参数,共包含4个步骤。第1步:运用不同的分词模型,同样不对文本进行去停用词处理,直接以开发集原始数据进行文本切分。第2步:利用brat文本标注系统对分词结果进行校正,以形成人工分词标准。人工校正参考文献[22]中的分词规范对模型分词结果进行校正,结合此次研究建模文献的实际情况,对分词规范作部分调整:对于规范中提到的以“欧阳修”类全名称出现的人名,切分为一个词语,若以“欧阳某”类出现的人名,则切分为“欧阳/某”;医学专业术语以词语能够表达一个基本的医学概念(如疾病、病机、症状、方剂、药物、治法等)为标准进行切分,例如“胸痹”表达一个中医疾病概念,不进行切分;建模文献中涉及少量的医古文内容,由于古代汉语单音词、复音词夹杂,对于医古文部分,以汉字表达一个词语概念为标准進行切分,如“伤于风者”“伤”可以理解为“侵袭”“于”可以理解为“受到”,“风”可以理解为“风邪”,“者”为助词,那么“伤于风者”则切分为“伤/于/风/者/”[22]。第3步:将开发集各模型分词结果与人工标准转写为标准的BIOES前缀形式的数据格式(B即Begin,I即Intermediate,O即Other,E即End,S即Single)[23-24]。在本研究中,B表示切分词汇的第一个文字,I表示切分词汇的中间文字,O表示未被切分的文字,E表示切分词汇的最后一个文字,S表示切分词汇仅有一个文字。由于模型分词是针对文本内所有数据进行的,所以本研究中无“O”字格式的数据。第4步:以各模型对开发集文本分词的准确率、宏观精确率、宏观召回率和宏观f1得分来评价不同参数所建模型的表现,确定建模参数,并以召回率为最终参数选择标准,优先选择召回率最高的模型,以使内容获取更为全面;同时,比较其与人工校正分词间的一致性,综合筛选出最佳的建模参数。
3.2 模型测试 将构建的中医分词模型设置为最佳的建模参数,对测试集文本进行切分,验证模型的有效性。文本分词步骤同开发集前3步,最后与人工校正结果相比较,计算模型切分词语的准确率、宏观精确率、宏观召回率、宏观f1得分。
3.3 评价方法 本研究通过scikit-learn 0.19(https://scikit-learn.org/stable/)计算模型分词结果的准确率、宏观精确率、宏观召回率、宏观f1得分,运用IBM SPSS Statistics 26计算模型分词结果与人工标准间的Kappa系数(Kappa系数小于0.2,说明一致性程度较差;在0.2~0.4之间,说明一致性程度一般;在0.4~0.6之间,说明一致性程度中等;在0.6~0.8之间,说明一致性程度很高;在0.8~1.0之间,说明几乎完全一致),比较其一致性。
4 实验结果
4.1 开发集实验结果
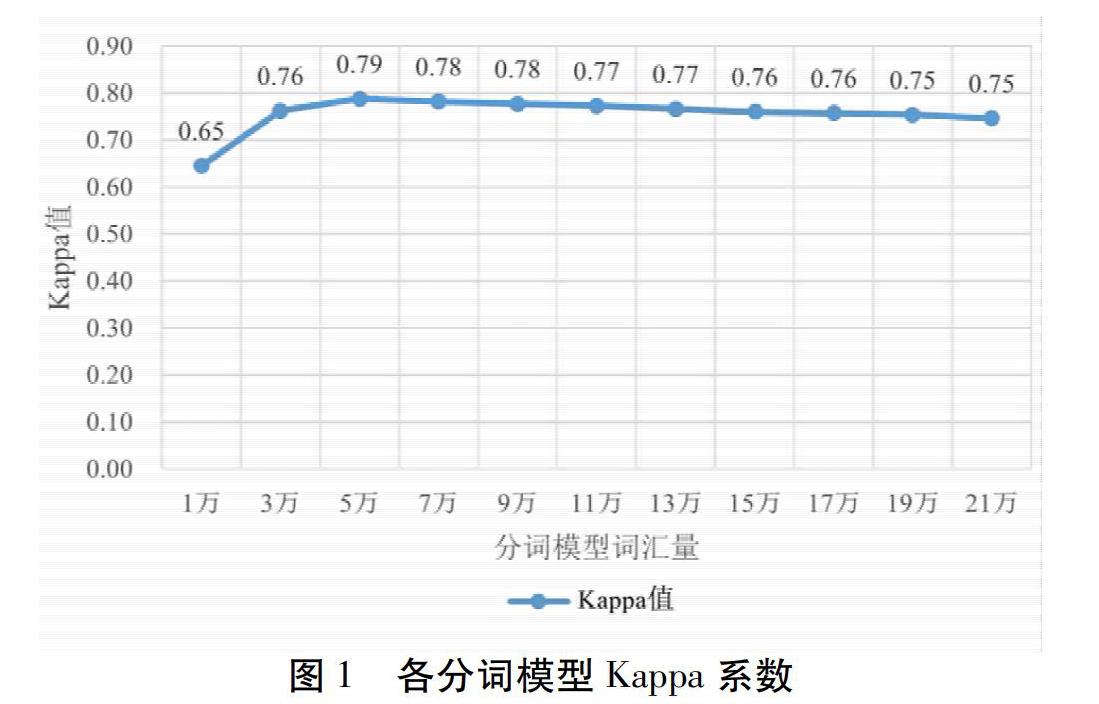
4.1.1 各分词模型一致性检验 各分词模型一致性检验结果如图1所示。结果表明,11个分词模型中,词汇量设置为5万时的分词模型与人工校正分词结果的一致性程度很高,提示当“vocab_size”设置为5万时的分词模型具有最好的分词能力。
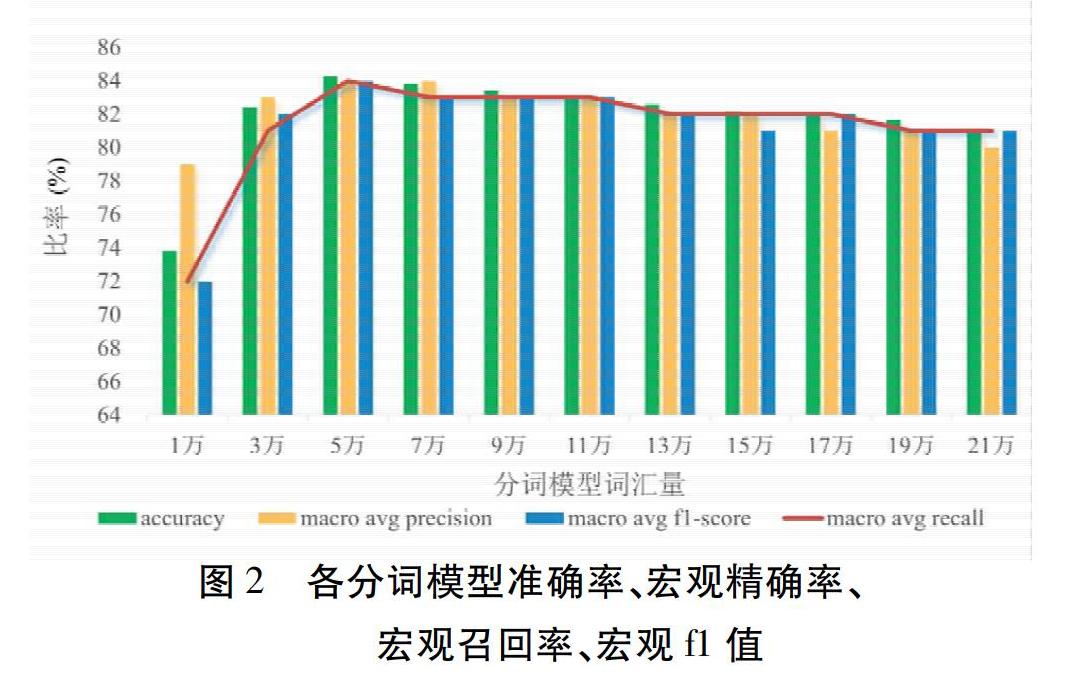
4.1.2 各分词模型的准确率、宏观精确率、宏观召回率、宏观f1得分 不同分词模型的准确率、宏观精确率、宏观召回率、宏观f1得分如图2所示。纵观11个分词模型中,当词汇量设置为5万时,分词模型的宏观召回率得分最高,表明该模型具有最佳的分词效果;同时,比较分词的准确率、宏观精确率、和宏观f1得分,亦可以看出词汇量预设为5万时,模型分词效果最好,这正好与一致性检验结果相呼应。其中,该模型开发集BIOES数据结构切分字符数如表2所示,精确率、召回率、f1得分如表3所示。综合4.1.1和4.1.2结果,可以看出当模型生成的词汇量设置为5万时,建模模型分词效果最好,为最佳的分词模型。此时,所建模型的最佳参数设置如表4所示。
4.2 测试集实验结果 利用最佳建模参数所构建的分词模型对测试集文本进行切分,其准确率为0.84、宏观精确率为0.84、宏观召回率为0.83、宏观f1得分为0.83、Kappa系数为0.79(一致性程度很高)。结果显示,最佳分词模型在测试集与开发集的分词效果上基本相同,提示所构建的分词模型具有较好的分词效果。其中,该模型在测试集上BIOES数据结构切分字符数如表5所示,精确率、召回率、f1得分如表6所示。从这2个表格可以看出,该模型对B类、I类、E类、S类数据结构的分词效果同开发集相似,都是I类数据切分效果较差,S类数据切分效果最好,将表5结果以混合矩阵图(图3)的形式显示,可以清晰地展现出各类数据结构间的差异。
5 讨论
现今的中医学知识多以非结构化形式被存储于各类型的文本中,使得这些文本成为为科研、教学以及临证提供丰富的理论知识与实践经验的知识载体。然而,中医学文献眾多,信息庞杂,这就为知识的准确提取利用带来了难题,单纯依靠人力去获取这些有效信息便是一项既耗时又复杂的工程,所以,运用计算机技术提取信息便成为当今研究的热点与难点。对中医学文本进行分词处理,可以使计算机能够识别相关信息,达到计算机较为精确地提取信息的目的,为LDA主题挖掘、命名实体识别、信息提取、文本分类等研究提供基础性的支撑。
SentencePiece是一种有效的文本分词方法,依赖字节对编码(BPE)和一元语言模型这2种算法,可以有效实现汉字序列的切分。本研究基于SentencePiece子词切分算法,以出版教材、名家著作和中医临床病历为模型构建数据,构建出适合于中医电子文本的分词模型。运用这种算法所构建的中医分词模型,无需对文本去停用词处理,无需加入自定义词典,无需预先对训练文本进行人工分词,纯粹依赖数据驱动,大为提升研究效率。并且,由于SentencePiece分词方法是针对汉字序列的切分,即是针对字与字的组合的切分,因此,当出现一个固定汉字组合时,计算机则把这个固定组合当做一个词语来切分。例如,“处方:瓜蒌薤白半夏汤”。这句话,模型在训练时已经学习到汉字“处”“方”所组成的固定词语“处方”“瓜”“蒌”“薤”“白”“半”“夏”“汤”所组成的固定词语“瓜蒌薤白半夏汤”,因此,计算机在分词时会自动将其作为一个单独的词语来切分,切分结果为:“处方/:/瓜蒌薤白半夏汤/。/”。采用这种方式构建的中医分词模型,对疾病、病机、症状、中药、方剂等专业医学词汇都具有较好的切分效果,非常适用于专业术语较多的医学文本分词,使得专业术语的切分结果可有效的运用于数据提取研究工作。
就本研究而言,从文本切分的准确率、宏观精确率、宏观召回率和宏观f1得分看,构建的模型在开发集与测试集的文本分词上,都取得了较好的分词效果,与人工校正结果比较,都具有较强一致性;并且,开发集和测试集的BIOES数据结构的精确率、召回率和f1得分显示,二者差距甚小,表明本研究模型成功构建。但是,就分词结果的BIOES数据结构而言,以人工校正结果为参照,比较其他类别的数据结构,表5、表6中的结果显示出S-Segment类数据切分的效果最好,其召回率达到91%,考虑为本研究以原始数据的形式进行切分,文本中有较多的标点符号,模型会将其当做一个单独的汉字进行切分,这就会提高模型对于S-Segment类数据的切分效果。然而,模型预测的I-Segment类数据切分效果较差,从图3可以看出,分词模型错将I-Segment类预测为8%的B-Segment类、12%的E-Segment类和6%的S-Segment类。
之所以出现这种情况,回顾模型分词结果发现,虽然此模型对于医学专业术语具有较好的切分效果,但是出现如“胸闷心慌”“胸闷憋气”这类无标点符号或连词分隔的医学术语,计算机在学习时会自动将其作为一个词语进行切分;对于医案中出现的某些药物名称,如“强的松”,当出现“服强的松”这种汉字序列时,由于计算机学习时错误地将其当做一个词语来学习,因此在模型分词时不会对其切分。在非医学术语的识别上,对于人名、地名或常用词语等的识别,由于出现的频率较低,计算机没有学习到该类词语,在切分时则会将其切分为单独的文字,例如对于刘渡舟教授的别称“刘老”二字,计算机将其切分为2个单独的文字“刘”和“老”;并且,依据分词切分标准来看,分词模型对于“某年某月某日”这种格式的时间词语,识别效果较差,例如“1991年5月25日”会将其切分为“1991/年/5/月/25/日/”。
分词模型出现上述某类词语切分不理想的现象,考虑为建模数据内包含较多的医学词汇,所以对医学词汇的识别效果较好,而对人名、地名、时间词等的识别效果较差。针对这些现象,1)可以增加非医学类训练样本,丰富模型学习的人名、地名、时间词等词汇量,例如加入诸如人民日报这种包含较多人名、地名及时间词等的数据样本,以供模型学习使用,提高其识别效率;2)可以在人工校正的基础上,将其作为训练文本,结合条件随机场(CRF)、双向长短时记忆网络(Bi-LSTM)等方法,构建一个有监督学习的分词模型,以提高模型分词的准确性。
6 结论
本研究基于SentencePiece子词切分算法所构建的中医分词模型,直接以原始数据的形式达到词语切分的目的,在中医学专业术语的切分上有着较大的优势,可为中医学分词模型的构建提供新的建模方法。使用这种算法所构建的无监督学习的中医学分词模型,由于对疾病、病机、症状、中药、方剂等专业医学词汇具有较好的切分效果,其分词结果可以有效地运用于下一步研究过程中,并且,还可以在此基础上辅助人工分词,很大程度地节省人工分词的时间;其次,还可以以此为基础,建立一个更为专业的中医学分词模型。此次建立的中医分词模型将分享于https://github.com/网站,名为TCM-Word Segmentation。
参考文献
[1]张帆,刘晓峰,孙燕.中医医案文献自动分词研究[J].中国中医药信息杂志,2015,22(2):38-41.
[2]朱德熙.语法讲义[M].北京:商务印书馆,1982:11.
[3]刘子晴.邓铁涛学术理论文献传播复杂网络构建及文本主题分析[D].广州:广州中医药大学,2017.
[4]原旎,卢克治,袁玉虎,等.基于深度表示的中医病历症状表型命名实体抽取研究[J].世界科学技术-中医药现代化,2018,20(3):355-362.
[5]梁礼铿,黎敬波.基于最大概率法探讨中医症状信息提取与标准化[J].中华中医药杂志,2017,32(5):2159-2162.
[6]赵汉青,王志国.基于机器学习的中医学派文本分类研究[J].中华医学图书情报杂志,2018,27(12):7-11.
[7]石凤贵.基于jieba中文分词的中文文本语料预处理模块实现[J].电脑知识与技术,2020,16(14):248-251,257.
[8]Wanxiang Che,Zhenghua Li,Ting Liu.LTP:A Chinese Language Technology Platform.In Proceedings of the Coling 2010:Demonstrations[C].Beijing,China.2010.Beijing:Tsinghua University Press,2010.
[9]Zhang HP,Yu HK,Xiong D,et al.HHMM-based Chinese lexical analyzer ICTCLAS.Proceedings of the second SIGHAN workshop on Chinese language processing[C].Sapporo,Japan.2003.Stroudsburg,PA:Association for Computational Linguistics,2003.
[10]車金立,唐力伟,邓士杰,等.基于BI-GRU-CRF模型的中文分词法[J].火力与指挥控制,2019,44(9):66-71,77.
[11]程博,李卫红,童昊昕.基于BiLSTM-CRF的中文层级地址分词[J].地球信息科学学报,2019,21(8):1143-1151.
[12]蒋卫丽,陈振华,邵党国,等.基于领域词典的动态规划分词算法[J].南京理工大学学报,2019,43(1):63-71.
[13]凤丽洲,杨贵军,徐雪,等.基于N-gram的双向匹配中文分词方法[J].数理统计与管理,2020,39(4):633-643.
[14]杨海丰,陈明亮,赵臻.常用中文分词软件在中医文本文献研究领域的适用性研究[J].世界科学技术-中医药现代化,2017,19(3):536-541.
[15]龚德山,梁文昱,张冰珠,等.命名实体识别在中药名词和方剂名词识别中的应用[J].中国药事,2019,33(6):710-716.
[16]许林涛,叶欣欣,裴成飞,等.中文分词模型在中医病症语义理解中的研究与应用[J].软件工程,2020,23(4):15-18.
[17]付璐,李思,李明正,等.以清代医籍为例探讨中医古籍分词规范标准[J].中华中医药杂志,2018,33(10):4700-4705.
[18]Kudo T,Richardson J.SentencePiece:A simple and language independent subword tokenizer and detokenizer for Neural Text Processing.Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing:System Demonstrations[C].Brussels,Belgium.2018.Stroudsburg,PA:Association for Computational Linguistics,2018.
[19]Wang Y,You Z H,Yang S,et al.A high efficient biological language model for predicting protein-protein interactions[J].Cells,2019,8(2):122.
[20]项青宇.基于子词切分的句子级别神经机器译文质量估计方法[D].南昌:江西师范大学,2019.
[21]张润顺,谢琪,李鲲,等.中国中医科学院“名医名家传承”项目管理平台设计及应用[J].世界科学技术-中医药现代化,2016,18(5):761-768.
[22]俞士汶,段慧明,朱学锋,等.北京大学现代汉语语料库基本加工规范[J].中文信息学报,2002,16(5):49-64.
[23]Ratinov L,Roth D.Design challenges and misconceptions in named entity recognition.Proceedings of the Thirteenth Conference on Computational Natural Language Learning(CoNLL-2009)[C].Boulder,Colorado.2009.Stroudsburg,PA:Association for Computational Linguistics,2009.
[24]Legrand J,Collobert R.Recurrent Greedy Parsing with Neural Networks.Joint European Conference on Machine Learning and Knowledge Discovery in Databases[C].Nancy,France.2014.Berlin,Heidelberg:Springer,2014.
(2020-07-07收稿 责任编辑:王明)
猜你喜欢
银行家(2022年5期)2022-05-24
大学教育(2022年3期)2022-05-16
校园英语·月末(2021年13期)2021-03-15
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
求知导刊(2017年19期)2017-09-13
中国民族民间医药·上半月(2016年11期)2016-12-26
数理化学习·初中版(2011年9期)2011-11-14
中学生英语·外语教学与研究(2008年4期)2008-03-18
青年文摘·上半月(1991年4期)1991-01-01
