
基于机器学习的生长激素结合蛋白特征提取研究
2021-07-07 06:35范仕豪
电子乐园·下旬刊 2021年7期
范仕豪





摘要:本文收集生长激素结合蛋白序列信息数据集,将其分为训练集和测试集两部分。使用TF-IDF,One-hot和PCA方法提取训练集中的特征向量,构建决策树,梯度提升树,随机森林这三种预测模型,以及对这三种模型的预测性能,计算评价指标。根据特征重要性进行特征筛选,剔除掉重要性较低的特征,保留特征重要性高的特征构建预测模型,再次计算评价指标进行比较。通过比较得出,得出使用PCA方法提取特征,进行特征筛选后构建的梯度提升树预测模型性能最好,precision为0.82,recall为0.81,f1-score为0.80,accuracy为0.81。
关键词:生长激素结合蛋白;机器学习;特征筛选;TF-IDF;One-Hot;PCA;决策树;梯度提升树;随机森林
引言:随着现代人工智能技术的不断发展,机器学习作为当前人工智能的主要技术之一,不断产生突破性进展,我们可以把机器学习运用到各种领域,比如我们进出学校时的师生人脸识别系统[1],无人驾驶汽车的上路驾驶系统[2],家里的各种智能扫地机器人和各类智能家居,也可以精细到生物医学分子研究和医学影像,习近平总书记强调,“人工智能是新一轮科技革命和产业变革的重要驱动力量,加快发展新一代人工智能是事关我国能否抓住新一轮科技革命和产业变革机遇的战略问题”,因此为蛋白质识别的研究带来新的可能和机遇。
本文主要讲述如何利用已有获得的生长激素结合蛋白序列信息,进行数据挖掘信息,使用不同的方法提取特征向量,再分别对根据其特征的重要性进行筛选特征,构建决策树,梯度提升树,随机森林算法构建预测模型,在测试集上进行模型评估,计算不同特征提取方法下得到的预测模型的评价指标,并对其进行比较和分析。
1 数据集的收集
用收集到的原始生长激素结合蛋白序列信息全部数据集分为两类,一类是训练集,用来进行不同方法下的特征提取和构建预测模型,另一部分是测试集,在测试集上进行预测模型的评估,计算预测模型的评价指标。其中得到训练集的正样本和负样本分别有123个,测试集的正样本和负样本分别有31个。
2 特征提取方法
2.1 One-Hot
独热编码(One-Hot Encoding),也被称为一位有效编码,其方法是使用N位状态寄存器来对N个状态进行编码分析处理,每个寄存器位都代表一个独立的状态,并且不论何时,其中只有一位有效,即只有一位是1,剩下的位都是0。独热编码是利用0和1表示一些参数,使用N位状态寄存器来对N个状态进行编码。
2.2 TF-IDF
“词频——逆向文件频率”(Term Frequency - Inverse Document Frequency,简称TF-IDF),是一种统计方法,用来评判某个字对于一个文件集或一个语料库中的其中一份文件的重要度,这种方法广泛用于机器识别和文本挖掘技术中,是一种于咨询检索与咨询勘探的常用加权技术,某个字的重要度会与它在文件中出现的次数成正比,也同时会与它在语料库中出现的频率成反比。得到的特征向量命名为:
['A', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'K', 'L', 'M', 'N', 'P', 'Q', 'R', 'S', 'T', 'V', 'W', 'Y']
2.3 PCA
主成分分析(principal components analysis,简称PCA)是一种较为经典的数据降维方法。它的基本思想是从一组特征中计算出一组按照重要性的大小从大到小依次排列的新特征,它们是原有特征的线性组合,并且新特征之間不相关, 我们计算出原有特征在新特征上的映射值即为新的降维后的样本。也就是说PCA的目标是用一组正交向量来对原特征进行变换得到新特征,新特征是原有特征的线性组合。
通过PCA算法能够对原有20维的较长特征向量进行压缩,得到一个简单的四维特征向量:
3 对模型的评价
我们对预测模型的评价标准要用到这四个数据,在常用的评价预测二分类模型性能有四个指标,分别是准确率(accuracy),召回率(recall),精确率(precision),平衡F1分数(F1-Score)其表达式分别如下:
3.1 决策树预测模型评价
测试集对决策树预测模型进行测试,当使用One-Hot方法提取特征时,决策树预测模型评价指标precision为0.39,recall为0.40,f1-score为0.38,accuracy为0.40。当使用TF-IDF方法提取特征时,precision为0.48,recall为0.48,f1-score为0.47,accuracy为0.48。使用PCA方法提取特征时,precision为0.65,recall为0.63,f1-score为0.62,accuracy为0.62。
通过评价指标可以看出,预测模型的性能并不好。因此考虑对特征向量进行处理,剔除一些冗余特征。
在One-Hot方法和TF-IDF方法提取特征向量时,各个特征的重要性如下表:
根据特征的重要性进行筛选,筛选特征阈值为0.1,剔除特征重要性小于0.1的特征,两种方法分别保留[‘C’ , ’L’ , ’W’ , ’ Y ’]和[‘F’ , ’M’ , ’Q’ , ’ W ’]。
使用PCA提取特征向量时,得到各个特征的重要性如下表:
根据特征的重要性进行筛选,筛选特征阈值为0.1,剔除特征重要性小于0.1的特征,得到一个新的特征向量,保留[‘X2’ , ’X3’ , ’X4’ ]。
对进行剔除冗余特征后的特征向量重新构建决策树模型,再次用测试集对其进行模型测试,得到评价指标:当使用One-Hot方法提取特征时,评价指标precision为0.61,recall为0.58,f1-score为0.55,accuracy为0.58。当使用TF-IDF方法提取特征时,precision为0.52,recall为0.52,f1-score为0.48,accuracy为0.52。使用PCA提取特征时,precision为0.66,recall为0.60,f1-score为0.55,accuracy为0.60。
可以得出,在进行特征筛选,剔除冗余特征后构建的决策树模型,性能明显得到了优化,评价指标也有所提高。
3.2 随机森林预测模型评价
使用测试集对随机森林预测模型进行测试,当使用One-Hot方法提取特征时,评价指标precision为0.63,recall为0.63,f1-score为0.63,accuracy为0.63。当使用TF-IDF方法提取特征时,precision为0.52,recall为0.52,f1-score为0.50,accuracy为0.52。使用PCA提取特征时,precision为0.64,recall为0.63,f1-score为0.62,accuracy为0.63。
根据特征向量的特征重要性进行特征筛选,在随机森林中,使用One-Hot方法和TF-IDF方法提取特征的特征重要性如下表:
筛选特征阈值为0.05,剔除掉特征重要性低于0.05的特征,两种方法下分别保留[‘A’ , ’F’ , ’H’ , ’ I ’ , ‘L’ , ‘N’ , ‘W’]和[‘C’ , ’E’ , ’F’ , ’ H ’ , ‘I’ , ‘R’ , ‘V’ , ‘W’]
使用PCA方法提取特征向量,各个特征的重要性如下表:
筛选特征阈值为0.2,剔除掉特征重要性低于0.2的特征,保留[‘X2’ , ’X3’]
对进行剔除冗余特征后的特征向量重新构建随机森林模型,再次用测试集对其进行模型测试,得到评价指标:当使用One-Hot方法提取特征时,评价指标precision为0.65,recall为0.65,f1-score为0.64,accuracy为0.65。当使用TF-IDF方法提取特征时,precision为0.55,recall为0.55,f1-score为0.55,accuracy为0.55。使用PCA提取特征时,precision为0.64,recall为0.63,f1-score为0.62,accuracy为0.63。
可以得出,在进行特征筛选,剔除冗余特征后构建的随机森林模型,性能明显得到了优化,评价指标也有所提高。
3.3梯度提升树预测模型评价
使用测试集对梯度提升树预测模型进行测试,当使用One-Hot方法提取特征时,评价指标precision为0.52,recall为0.52,f1-score为0.52,accuracy为0.52。当使用TF-IDF方法提取特征时,precision为0.66,recall为0.65,f1-score为0.64,accuracy为0.62。使用PCA提取特征时,precision为0.82,recall为0.81,f1-score为0.80,accuracy为0.81。
根据特征向量的特征重要性进行特征筛选,在梯度提升树预测模型中,使用One-Hot和TF-IDF方法提取特征的特征重要性如下表:
One-Hot方法下筛选特征阈值为0.05,剔除掉特征重要性低于0.1的特征,保留[‘L’ , ’N’ ],使用TF-IDF方法筛选特征阈值为0.05,剔除掉特征重要性低于0.05的特征,保留[‘C’ , ’E’ , ’F’ , ’ H ’ , ’L’ , ’M’ , ‘N’ , ’P’ , ’Q’ , ‘R’ , ‘W’]
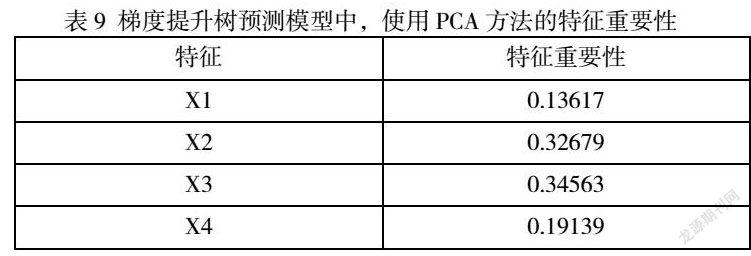
使用PCA方法提取特征向量,各个特征的重要性如下表:
由表可得,’X1’特征重要性明显小于其他几种特征,但当剔除掉’X1’特征时,梯度提升树预测模型性能反而降低了,所以’X1’不属于冗余特征,不作剔除处理。
对进行剔除冗余特征后的特征向量重新构建梯度提升树模型,再次用测试集对其进行模型测试,得到评价指标:当使用One-Hot方法提取特征时,评价指标precision为0.61,recall为0.61,f1-score为0.61,accuracy为0.61。当使用TF-IDF方法提取特征时,precision为0.71,recall为0.71,f1-score为0.71,accuracy為0.71。使用PCA提取特征时,precision为0.82,recall为0.81,f1-score为0.80,accuracy为0.81。
可以得出,在进行特征筛选,剔除冗余特征后构建的梯度提升树预测模型,性能明显得到了优化,评价指标也有所提高。
4 结论
通过对获得的生长激素结合蛋白序列信息数据集进行分类得到构建预测模型的训练集和用来判断预测模型性能优劣,计算评价指标的测试集,对训练集数据使用One-Hot,TF-IDF,PCA三种方法提取特征向量。再用决策树,梯度提升树,随机森林这几种算法进行构建预测模型。在测试集上对三种预测模型进行评估,得到预测指标。本文还对已提取的特征向量中的冗长特征进行处理,剔除掉特征重要性低的特征,根据保留剩下的特征再次构建三种预测模型,再次在测试集上进行预测模型的评估,计算评价指标,发现预测模型性能明显得到的提高。最终得出结论,在预测生长激素结合蛋白这种二分类问题时,使用PCA方法提取特征向量,构建的梯度提升树预测模型性能最好。
参考文献
[1]韦大欢.基于疫情防控下人脸识别在宿舍管理系统中的应用[J].现代计算机,2022,28(03):82-86.
[2]黄东风.人工智能在汽车驾驶技术领域的应用与发展[J].时代汽车,2022(01):42-43.
猜你喜欢
中学生数理化·高二版(2022年4期)2022-05-09
中学生数理化·高二版(2022年4期)2022-05-09
中学生理科应试(2021年11期)2021-12-09
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
福建基础教育研究(2019年3期)2019-05-28
数学学习与研究(2018年15期)2018-11-12
西部资源(2018年1期)2018-11-01
电脑知识与技术(2016年22期)2016-10-31
中学生数理化·高三版(2016年9期)2016-05-14
金点子生意(2014年4期)2014-04-10
