
基于启发强化学习的大规模ADR任务优化方法
2021-07-05 11:07杨家男侯晓磊HUYuHen刘勇潘泉冯乾
航空学报 2021年4期
杨家男,侯晓磊,HU Yu Hen,刘勇,潘泉,冯乾
1. 西北工业大学 自动化学院,西安 710129 2.美国威斯康星大学麦迪逊分校 电气与计算机工程系,麦迪逊 53706
低轨(Low Earth Orbit,LEO)空间碎片是当下世界航天所共同面临的问题和挑战[1-2],随着空间碎片数量的持续增加,其对未来在轨任务产生的威胁也在不断增加[3]。根据Kessler现象的预测,如果对空间环境不加以干预,未来低轨空间碎片碰撞会产生更多新的空间碎片,进而引发链式连锁效应,危害在轨运行的任务以及未来的航天发射[4]。即使各国航天器遵守任务末期自动离轨要求(Post-Mission Disposal,PMD),如果无法每年清除至少5个大型空间碎片,就无法阻止现阶段不断增长的趋势,并且无法避免失效航天器之间的相互碰撞所引发的连锁效应[5]。Cosmos 2251卫星与铱星33卫星碰撞即为典型案例,此次空间物体碰撞导致空间碎片数量呈爆炸式增长[6]。
现有低轨空间碎片主动清除方式多样,分为地基激光离轨、天基捕捉离轨两类[7-8]。其中,使用专用航天器的天基捕捉方式较为成熟,且拥有多种捕捉形式,如网爪、叉型、绳系、离轨包等。能够一次任务清除多个碎片的天基碎片清除航天器对完成多碎片主动清除任务(Active multi-Debris Removal,ADR)是非常高效的[9],而子母星空间碎片清除航天器是一种通用可行的航天器方案。其中,子星为离轨包载荷(Deorbiting Kit,DK),用以捕获空间碎片并将其离轨到再入轨道;母星为轨道转移航天器(Orbital Transfer Vehicle,OTV),携带剩余资源转移到下一个目标碎片附近[10],直到用尽其星上资源为止。
由于碎片间的轨道转移推力消耗(Δv)与变轨时刻、转移时间相关,所以多碎片主动清除任务规划可视为时关旅行商问题(Time-Dependent Traveling Salesman Problem,TDTSP)。相比传统TSP,时间维度的加入使问题变得更加复杂。而且当面对大规模空间碎片时,ADR任务规划问题的解空间巨大,数据相关性弱,给规划算法提出巨大挑战[11-13]。所以,本文面向子母星空间碎片清除平台建立空间碎片主动清除任务规划模型,针对大规模空间碎片集合设计快速有效的任务规划方法。
对于该任务优化问题,多数传统研究[14]关注于最小化轨道转移燃料消耗或总任务时间,或者同时最小化这两种损耗[10,14-18]。现逐渐向最大化任务收益方向发展[13,17],多采用传统优化方法求解上述模型,如穷举法[9,19-20]、剪枝法[10,16,21-22]、蚁群算法[17,23]、遗传算法[2,11-12,14]以及启发式算法[13,15,24]。现有研究都是在传统优化模型基础上直接使用随机优化算法或确定性算法,在搜索上往往会陷入局部最优或消耗很多算力,没有较好的机制来平衡探索与利用。随着人工智能的飞速发展,逐渐有研究探索了机器学习算法在空间任务中的应用[25-30]。其中强化学习作为一种任务决策框架也是通过寻找最优动作的方式逐渐达到目标[31-32],能够在利用历史信息的同时保持较好的探索能力。空间多碎片清除任务规划作为一个优化问题,可将任务的每一个清除阶段视为一次任务决策,则整个离线任务规划可描述为多个阶段的任务决策,那么强化学习模型就可以被用于提高其决策能力,高效完成离线任务规划。同时该过程也可以作为未来在轨自主规划的基础。
具体而言,强化学习能够选择指向最大化积累总收益的动作[33]。这适用于机器人[34]、多智能体系统[35]、博弈[36]以及最优控制[37]等领域。强化学习已经在AlphaGo Zero[38]上显示出非常优越的性能,并且ADR任务规划在很多方面都与围棋博弈规划过程相似。比如在走棋过程中,规划程序根据当前状态、未来可能的选择还有允许的落子空位,来决定能够胜利的动作。在ADR任务规划中,规划程序根据当前ADR航天器的状态以及剩下所有待清除空间碎片的状态,逐步选择目标碎片及清除时间,并纳入到产生的清除序列解中,以期获得更大收益。强化学习中的基于收益的动作选择模式令规划器倾向于能够获得更高收益的节点,这种收益导向分步执行的策略与最大收益模型[13]下的ADR任务规划是相同的。经过合理的设计,融合领域知识,就能有效利用强化学习框架在这类超大解空间中的优势,高效收敛出更优结果。
综上所述,本文意在针对ADR任务规划提出相应的强化学习模型,获得专用的强化学习框架与算法,并且根据领域实际情况,增加高效启发因子,提出基于启发的改进蒙特卡罗树搜索算法,以求解最大收益模型下的大规模ADR任务规划问题,并在完整铱星33碎片云上验证模型与算法有效性。
1 模型建立
在轨道转移理论中,碎片间转移消耗是跟随转移起始时间、转移时长的变化而变化的。假设空间碎片轨道在任务期间符合J2摄动轨道动力学模型推演,其位置为关于时间的确定函数。称这种动态确定性为时间相关特性,则多碎片主动清除任务规划可以建模为一种时关旅行商问题[10,13]。虽然这种时关函数为确定性函数,但仍然令传统旅行商问题搜索空间激增。模型中增加了时间变量,求解过程需采用跟随时间逐步选择的方式,才能够在解序列长度不确定的情况下完成规划问题的求解。
以任务的总收益为目标,建立ADR任务的最大收益模型。鉴于ADR任务规划仅是针对轨道转移的离线优化,所以假设ADR航天器采用J2摄动下的漂移轨道脉冲变轨转移策略[11],任务时间与转移消耗为任务约束主要考虑的因素,离轨包数量模型暂不考虑。
1.1 任务描述
假设碎片集合包含Ntotal个低轨空间碎片,以每个空间碎片在集合中的索引表示。任务计划完成n(≤Ntotal)个碎片的清除,n可变且由最终规划结果决定。在规划完成之后,获得碎片序列为n×1向量d=[d1,d2, …,dn]T,其中di(di∈ 1≤di≤Ntotal)代表第i(1 ≤i≤n)个要清除碎片的索引,清除时间序列的表达形式为n× 1向量t=[t1,t2, …,tn]T,其中T0≤t1 最大收益优化模型的目标是通过规划解d与t,获得在任务时间限制与推力限制下积累收益的最大值。模型数学表达为 (1) 式中:G(d)为任务的积累总收益;g(di)>0为di的收益;Cv和CVelocity分别为每段与整个任务的转移脉冲消耗;Cd和CDuration分别为每段与整个任务的转移时间间隔;ΔVmax为ADR航天器携带的总变轨能力。 基本的强化学习模型由状态空间、动作空间、状态转移方程组成。假设一个虚拟的智能体根据当前状态不断选择动作,然后该智能体达到下一个状态,并且通过环境模型推演获得收益,最终动作的选择策略会随着搜索过程而不断更新。强化学习模型的目标是最大化所选择动作序列的积累收益,与ADR最大收益优化模型对应,所以建成后的强化学习模型可以解决本问题。 1.2.1 状态向量 (2) 该状态向量理论上有NtotalΔVmaxTleft2N种情况。所有状态组成的状态空间一定程度反映了本ADR任务规划问题的复杂度。例如,如果脉冲消耗与任务时间分别离散为1 m/s与1 d,Ntotal=320,ΔVmax=3 000 m/s,Tmax=365 d,所有的状态数量为7.5×10104。 1.2.2 动作向量 在ADR任务规划过程中,动作ai代表虚拟智能体不断选择清除的目标和清除的时间,也是解向量的组成片段。如式(3)所示,ai即可表达所有可能的动作,并组成动作集合A。 ai=[di,Δti]T (3) 式中: (4) 其中:di为被选择的目标碎片;Δti=ti-ti-1为碎片间转移的时间间隔,且离散粒度为1 d。状态、动作均建模为与清除步骤相关,满足状态转换需求。 在采用漂移轨道转移策略的ADR任务规划问题中,ADR航天器会转移到漂移轨道等待升交点赤经(Right Ascension at Ascending Node,RAAN)与目标轨道重合。由于整个任务时间较长,ADR航天器在碎片附近停留的时间可忽略不计,即假设到达目标碎片的时间与前往下一个碎片的时间相同。为贴近实际并降低搜索难度,假设转移时间不超过30 d。 1.2.3 状态转移方程 给出当前状态和动作,下一个状态可以通过式(5)的状态转移方程T(si,ai+1)求得。T可视作一种运算,只改变状态向量的部分元素,未改变的标志位沿用上一状态。ADR航天器状态随着清除步骤逐步改变。通常在强化学习中,状态转移方程为概率形式,但是因ADR规划为离线优化,碎片位置时关可推演,清除离轨过程可靠,所以在本问题中智能体与环境交互的状态转移方程为确定的。 (5) 1.2.4 收益函数 由于本问题是离线规划问题,所以收益函数为状态-动作对的确定函数,如式(6)所示。在状态演化过程中,任务的单步收益通过函数R获得。 ri=R(si,ai+1) (6) 该收益函数直接与最大收益模型的目标函数式(1)对应,是其单步收益。每当任务优化算法给出一个完整解,优化模型所得到的最终目标是单步收益的总和。这与强化学习状态值函数式(7)在初始状态处、折扣因子γ=1时的含义相同。 (7) 式中:π表示选择动作的概率;a~π(s)为在状态s下动作a的选择依照策略π(s),a=[d, Δt]T,其中d为目标碎片,Δt为转移时间间隔。 同样的,在本文强化学习框架中,每个单步收益的期望与优化函数中单个碎片的收益相同,如式(8)所示。所以优化目标中的积累收益是强化学习状态值函数的一种特例。这也证明强化学习框架是一个契合ADR任务规划问题的求解方式。 E{R(s,a)|a=[d,Δt]T}=g(d) (8) 单个碎片的收益因为任务的不同而不同,它通过任务目标中的g(d)反映在强化学习框架的收益函数中。由于意在建立任务规划的强化学习框架,所以收益函数没有限定具体内容,而在仿真实验中假定清除序列总长度即为任务收益,此时所有g(di)=1,最终结果将从清除数量上反映该框架的可行性。其他形式的碎片收益函数可参照文献[10,13,39]。 1.2.5 搜索树 完成强化学习框架下的ADR任务规划状态、动作及收益函数后,优化搜索过程需要明确搜索树。如图1所示,搜索树的每个节点代表着一个状态,节点间的转移过程代表执行特定动作。虚拟的智能体在搜索树上不断重复着动作决策与状态转移,从初始状态向下一层探索,逐步完善搜索树。在每一次的尝试中,智能体作为规划器向着收益更大的方向搜索,直至终止状态,并总结本次搜索过程。终止状态的判断条件与优化模型约束集合对应,当状态向量显示剩余脉冲小于0或剩余任务时间小于0或剩余待清除碎片数小于0时,达到叶子节点的智能体会重置到初始节点,继而进行下一次尝试。 图1 ADR任务规划强化学习框架搜索树Fig.1 Search tree of ADR mission planning under reinforcement learning scheme 随着搜索过程的进展,基于每次迭代选择动作的收益,智能体通过更新搜索树的信息,在每个节点处总结出动作选择的概率分布,并以此为策略,以期获得更高的收益[36]。虽然每一步的转移脉冲消耗损失函数是已知的,但是只有访问到终止节点,形成了完整的解向量,才能获得完整的损耗与收益信息。 所以,搜索算法如果能够快速生成优质的解向量,就可以更快地收敛出最优策略,也就可以用较少的探索时间获得较优解。同时,也要避免过于利用历史信息,提高其鲁棒性,保持探索可能,使之不易落入局部最优。所以,在穷尽搜索树之前,搜索过程应该配合适当的评估方法,平衡探索与利用,使得最优解能够更快地找到。 现有很多强化学习方法以及相关变体,分为基于值函数的、基于策略梯度的、基于搜索与监督的强化学习方法,如Q学习、深度Q学习(Deep Q-Network,DQN)、异步优势行动者评论家算法(Asynchronous Advantage Actor-Critic,A3C)和蒙特卡罗树搜索(Monte Carlo Tree Search,MCTS)方法等[40-41]。其中MCTS在围棋机器人AlphaGo Zero中得到高效利用。它所使用的算法为上界置信树(Upper Condence bound Tree,UCT)搜索方法,是在MCTS加入上置信确界(Upper Confidence Bound,UCB)[42]平衡探索与利用,并以深度神经网络作为评估手段。 针对大规模空间碎片清除数据规模大、搜索空间大、全局最优解无法确定等问题,避免单纯通过重启搜索以及提高算力来解决问题,在ADR任务规划的强化学习框架上提出一种改进的MCTS方法(ADR-MCTS),以提高求解ADR任务规划问题的效率。该算法使用双层循环结构,内部循环以MCTS为基本结构,使用高效启发式完成探索,外部循环控制搜索进程以及执行动作决策、完成环境交互步骤。内环为外环提供搜索树,外环以搜索树指导决策。 内环仍然使用UCB保持选择的平衡性,不再使用神经网络模型作为评估方法,是因为其泛化特点在输入的大规模碎片数据离散且相关性较小时会误导搜索。在大规模ADR任务规划问题中,由于解的元素多,每一次清除步骤间环环相扣,高收益解往往是稀疏的,神经网络暂时无法较好地评估本问题的期望收益。而且在已知损失函数的条件下,训练所有数据显然是不明智的。除此之外,MCTS的roll-out模拟步骤以其优良的鲁棒性替换神经网络的作用,即在非终止状态的叶子节点处用随机选择动作策略模拟至终止状态,以此获得可供反馈的评估收益。 即便如此,现有通用智能优化算法在解决该大规模ADR问题时,仍会出现长时间无最优解、指标提升缓慢、陷入指标很差的局部解等现象。为了使搜索更加高效、更加接近全局最优,引入启发因子择优扩展策略,在虚拟智能体可获取本层所有可行的动作时,对比启发因子,择优选择少数可拓展的方案,提高效率。 ADR任务优化模型的解为d与t,他们可以由动作序列(a1,a2,…)表达,其下标为清除步骤。虚拟智能体每一次搜索的过程为(s1,a2,r1;s2,a3,r2;s3,a4,r3;…),其中假定(s0,a1)为ADR航天器被运抵首个碎片的过程,不计入优化范围。根据状态值函数,状态-动作值函数即为 Qπ(si,ai+1)=Eπ{R(si,ai+1)+γVπ(si+1)} (9) 式中:Vπ(si+1)为在策略π下的状态值函数。 AlphaGo Zero的基本搜索步骤如图2[38]所示,包括选择、扩展与评估、反推以及执行。图2中Q0为状态-动作值、V为状态值、U0为平衡搜索与利用的项、P0为动作选择概率、p与v为估神经网络fθ估计的动作选择概率与状态值。其优势在于状态值估计精确,可较好指导搜索。 图2 AlphaGo Zero的UCT算法框架图[38]Fig.2 UCT algorithm structure of AlphaGo Zero[38] 与之不同的是,本研究期望利用MCTS的搜索能力,为避免神经网络在相关度较小的空间碎片集合中无法发挥优势,使用roll-out模拟评估非终止叶子节点。并且,针对ADR任务规划问题高收益解的稀疏性,在选择步骤中引入适用于漂移轨道转移策略损失函数的启发式[13],以此获得高效的搜索进程。 2.2.1 节点信息与启发因子 节点信息的维护是搜索树连接内环外环的关键。节点存储了从上一步到达自身节点的推演过程,即上一步状态s、所执行动作a、到达本节点的状态s′。除此之外还需要定义MCTS需要的决策信息,以及引入的启发信息。 节点信息有访问次数N(s,a)、节点历史积累收益W(s,a)、节点Q值Q(s,a),新节点在创建之初,所有的参数都初始化为0。一旦某节点被重新访问,该节点的信息由如式(10)所示的规则更新: (10) 式中:z为由roll-out步骤更新的收益值,代表沿该路径时期望获得的总收益;N′(si,ai+1)、W′(si,ai+1)和Q′(si,ai+1)为更新后的参数值。 启发信息提供的是人类知识,反映该节点向下搜索达到更优结果的可能性。通过收益消耗比的形式给出。首先给出综合消耗CR,为考虑所有消耗的加权评估,特别之处在于按照当前对应剩余资源的比例完成组合: (11) 式中:(si,ai+1)为(di,di+1,ti,ti+1)在节点中的表达;α∈ [0,1]为表达重要程度的加权系数。 结合每一步的收益ri,则启发因子H如式(12) 所示。搜索树中的每一个节点都包含以上信息,用以完成内环搜索与外环推演。 (12) 2.2.2 外环结构 外环结构主要包含环境交互外循环以及决策过程,与蚁群算法(ACO)类似[31]。都有智能体在没有先验知识的情况下,在地图中完成路径寻优。随着搜索的继续,知识不断累积,蚁群算法通过信息素的形式体现,本算法是将该知识存储在搜索树中,以状态值函数的形式表达期望目标函数值。外环结构如算法1所示。 算法1 ADR-MCTS外环结构输入: 转移模型式(5)、初始状态输出: ADR任务规划结果1: while 迭代次数不到M do2: 设置虚拟智能体从初始节点出发,对应状态s03: while 当前节点状态s非终止 do4: 输入当前节点进入ADR-MCTS内环作为根节点5: 获得内环输出动作a6: 使用状态转移方程获得下一步状态s'7: end while8: 与历史解对比保留较优解9: end while 2.2.3 内环搜索算法 ADR-MCTS内环搜索从第一个节点开始,期望找到能够达到最高收益的子集。在这个过程中输出动作选择概率π,并且扩展搜索树。经过一定数量迭代,搜索树不断延伸,作为输入的根节点的信息也因为子树的扩展而更加接近真实情况。 流程如图3所示。智能体所在节点被视作根节点输入到内环搜索中。整体循环为4步:启发式选择、随机扩展、roll-out模拟、反推更新。启发式选择让搜索树的扩展方向限定在较少的几个引向高收益的动作上。在一些次内循环迭代后,ADR-MCTS建立的搜索树子树上的节点信息逐步完善,最终形成根节点处的策略,使用模拟退火的方法选择动作输出给外环。 图3 ADR-MCTS内环搜索流程图Fig.3 Inner loop searching structure of ADR-MCTS 核心步骤描述如下: U(ai+1)=βQ(si,ai+1)+(1-β)H(si,ai+1) (13) 式中:β∈ [0,1]为启发调节参数。 (14) 针对ADR问题最优解的出现比较稀疏,搜索方向落在有限的最有可能出现最优解的方向最为合理。该选择策略既保留了多个选择的可能,又避免了在显而易见的次优节点上浪费过多搜索。 2) 随机扩展:如果智能体到达节点不满足搜索树宽度条件,它将随机选择探索方向并扩展节点。由于启发选择步骤控制了每一层有资格被扩展的子树数量为X,搜索树宽度对搜索量影响不再显著。假设搜索树宽度为w,清除了n个碎片使搜索树下探n层,可能访问的节点数就从wn变为w+(n-1)Xw,适用于随机扩展。 3) Roll-out模拟:因为在随机扩展步骤后搜索树更深层情况未知,roll-out模拟步骤便不间断随机选择节点直至终止节点。该步骤不会扩展搜索树,也不会增加节点的访问次数。它仅仅给出当前已有路线上节点共同的期望总收益z。 4) 反推更新:在获得当前解的模拟收益z后,将该解路径上的所有节点都通过式(10)更新。 在足够多次迭代后,ADR-MCTS内环搜索提供根节点处的动作选择策略为 (15) 式中:τ为由外环控制的模拟退火温度,控制决策在搜索之初偏向探索,在温度下降的搜索末期偏向利用;b为遍历动作的标识符。所有符合式(16) 的合法动作均可作为决策对象。经过足够的迭代,最终将收敛的动作序列输出。 (16) 内环搜索细节如算法2所示。 算法2 ADR-MCTS内环搜索算法输入:s节点(包含子树)作为根节点1: while 迭代次数不到预设值T do2: 初始化智能体以根节点作为当前节点开始访问3: while 当前节点状态si非终止且满足搜索树宽度条件 do4: 启发地从aXi+1中选择节点5: end while6: if 当前节点状态si非终止 then7: 使用随机函数扩展节点si+18: 使用roll-out模拟直到到达终止状态,并获得期望总收益z9: end if10: 通过式(10)从si+1开始向所有母节点更新z11: end while12: 输出:依π(a|s)所决策的动作 使用铱星33碎片云的子集进行仿真实验,以测试ADR任务规划的强化学习框架及改进的MCTS方法。设置碎片清除序列的长度为目标函数,将其作为积累收益在终止节点处获取并反推更新给路径上所有节点。 由于穷举法在本大规模问题中无法完成,进行长时间的搜索也只能获得8个长度碎片解。因算力有限,穷举无法继续深入,也就无法以此作为全局最优点进行算法验证。所以ADR-MCTS算法将与AlphaGo Zero中的UCT方法以及启发贪婪算法[13]对比,检验框架和算法的有效性。 图4 铱星33碎片云概况Fig.4 Overview of Iridium 33 debris cloud 表1 铱星33碎片云实验数据集(部分) (17) ADR航天器假设拥有3 km/s的变轨能力,有1年的任务时间。目标碎片总数320枚,实验以清除序列总长度为任务收益,即假设碎片的清除收益相等且为1。算法可变参数设置γ=1,α=0.5,β=0.5,启发选择子节点个数X=5,外环最大迭代次数M=300,内环迭代最大次数T=3 500,搜索树宽度条件设置为本层无未访问的节点。 实验结果以动作序列形式呈现,碎片集合确定后,动作空间即可构建。动作由其在动作空间A中的索引代表。动作排序方式参照表2所示规律,先排列转移时间间隔(粒度设置为3 d,最大值不超过30 d),再排列目标碎片号。 表2 动作空间Table 2 Action space 因为该大规模的优化问题没有穷举法作为全局最优解的支撑,所以结果仅通过相关算法结果间的比较来说明本文算法有效性。 3.2.1 实验1:贪婪启发算法 对比单纯采用启发因子的贪婪算法[13]结果,都从动作1开始任务搜索,以0.5为启发因式参数获得解为[1, 2 472, 2 665, 303, 2 651, 1 243, 203, 1 074, 2 993, 2 093, 354, 3 163, 261, 2 186, 902, 1 662, 864, 776, 492, 2 573, 535, 2 618, 50, 1 960, 1 865, 2 855, 875, 2 223, 196, 724, 397, 2 124, 1 969, 2 756],该解的长度为34,实际规划清除33枚碎片,最后一个节点为终止状态。 尝试使用不同的启发参数,获得该方法下可能的更优解。但是α以0.01为粒度在区间[0.4, 0.5]间调节,都无法获得更加优秀的解。平均约700 s输出1次,34长度的解有8次,33长度的解有13次。 3.2.2 实验2:AlphaGo Zero中的UCT算法 使用该算法时,采用2层的残差网络分别模拟状态值函数以及动作决策概率,经过29 h的搜索,可获得最优解长度为13,其动作序列为[1, 268, 305, 2 170, 1 917, 130, 379, 2 467, 508, 2 068, 699, 2 500, 1 797],此时为存储所有搜索树节点信息及其他必要资源,128 G字节内存已耗尽,无法继续搜索。 表3给出的是该最优解路径上的节点信息及选择概率,其中W/N代表平均Q值,π(a|si)为对应动作选择概率。实际在每一层都有能量消耗较小且时间消耗也较小的节点。但是由于没有启发,该算法仅通过访问次数的积累而判断最优解方向。又由于单纯的收益导向,当没有尝试到更深的节点时算法收效甚微,仍然需要更多的算力进行试错。所以原算法解的优化效率很低。 表3 UCT算法最优解上各节点信息Table 3 Nodes information on solution of UCT 图5给出了UCT算法最终产生的搜索树形态,图中的毛刺代表在寻优过程出现的向各方向的探索,那些尝试均未达到更好的结果。节点总量非常巨大,但是仍然没有找到优于贪婪启发算法的结果。从图5可以看出,每深入一层都有非常多的同层节点不断被扩展,UCT在碎片间无收益差别时,只能通过不断尝试判断长远收益。而面对消耗较大的动作时,无法在有限的时间内准确推断其对长期收益的影响而减少该方向子树的访问,对于大规模问题来讲效率较低,但是很难收敛到较其他算法优秀的解。 图5 UCT搜索树节点深度Fig.5 Depth of nodes on search tree of UCT 3.2.3 实验3:ADR-MCTS结果 本算法以3.1节中参数运行24 h至第8个循环时,占用内存约20 G,得到当前最优解长度为43。搜索过程经历长度18的解1次,长度30的解1次,长度32的解3次,长度33的解1次,长度42的解3次,长度43的解1次。最终算法输出的长度43的最优解节点信息比本文算法ADR-MCTS在与UCT运行相似时间时获得的解收益更高,占用内存空间更小,与启发贪婪算法相比虽然运行时间长,但具有更强的扩展能力,能够获得贪婪启发算法无法获得的结果。 表4为ADR-MCTS算法最优解上各节点信息。值得注意的是该解的第3、6步骤面临着其他具有竞争性的节点,说明同层其他节点的子树也有相似程度的拓展。以第3步骤节点举例,存在两个有竞争力的节点动作为2 665(π(a|si)=26.06%,W/N=20.259 35)和854(π(a|si)=38.86%,W/N=24.847 95),其中动作854选择概率较动作855高,但是其平均Q值相对较低,其子树无法达到最优解的收益。如果继续搜索,则虚拟智能体会更加频繁访问最优子树而收敛至最优解,或者发现更加优秀的子树。改变搜索方向。 表4 ADR-MCTS算法最优解上各节点信息Table 4 Nodes information on optimal solution of ADR-MCTS 续表 实验搜索树中所有访问过的节点深度如图6所示,可以看出每次搜索都试图在加深搜索树深度,正对应任务收益目标。毛刺较少说明搜索方向性较强,且基本能够探索出附近通往更深层次的子树。每次程序外循环都可以将搜索树探至某个方向的局部最优。这也印证了选择概率相近的同层节点背后的子树同样是具有竞争力的。 图6 ADR-MCTS搜索树节点深度Fig.6 Depth of nodes on search tree of ADR-MCTS 可见,本文算法ADR-MCTS在与UCT运行相似时间时获得的解收益更高,占用内存空间更小,与启发贪婪算法相比虽然运行时间长,但具有更强的扩展能力,能够获得贪婪启发算法无法获得的结果。 三者对比结果如图7所示,三者均沿着RAAN漂移方向清除,符合漂移轨道策略,但是UCT的解跨度较大,不如具有启发因子的方法更加高效,而启发贪婪算法则不如本文算法扩展得更深,收益更高。由此可得本文改进MCTS算法效率更高,获得的解更加接近全局最优。 图7 最优解运行轨迹示意图Fig.7 Sketch moving trajectory of optimal solution 论述了强化学习框架在大规模多碎片主动清除任务规划问题中的应用,利用强化学习在任务决策中能有效平衡探索与利用的优势,建立了最大收益模型下的强化学习框架,提出了一种基于启发的改进MCTS算法,通过人类认知指导搜索,使探索更加高效。最终在大规模数据集对比实验中,提出的强化学习框架和算法具有良好可行性与高效性,能够利用较少时间得出更优的规划结果,并保持充足的探索能力。 未来将利用该框架,研究其在长期在轨自主航天器的任务决策以及多平台多目标任务规划中的可行性。1.2 强化学习建模



2 求解算法
2.1 基本定义
2.2 改进的MCTS算法






3 仿真实验
3.1 测试数据集
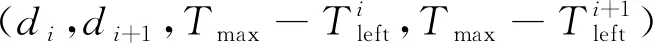




3.2 结果分析






4 结 论
猜你喜欢
导航定位学报(2022年4期)2022-08-15
现代电子技术(2022年4期)2022-02-21
计算机应用与软件(2021年10期)2021-10-15
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
领导文萃(2019年8期)2019-04-19
读友·少年文学(清雅版)(2018年12期)2018-04-04
澳门月刊(2016年6期)2016-06-15
中国经济信息(2015年8期)2015-05-05
时代英语·高三(2014年5期)2014-08-26
中学生数理化·八年级物理人教版(2014年2期)2014-04-02
