
非约束环境下的实时人脸检测方法
2021-07-03 05:45:36段燕飞刘胤田王瑞祥咬登国张航
应用科技 2021年3期
段燕飞,刘胤田,王瑞祥,咬登国,张航
成都信息工程大学 软件工程学院,四川 成都 610225
近年来卷积神经网络(CNN)取得了巨大的发展,各种优秀的目标检测网络模型层出不穷。人脸检测是目标检测的一个分支,与一般目标检测有很大相似之处,又有一定的差异。先前的目标检测大多是基于锚框(anchor-based)类型,需要经过滑动窗口产生大量的anchor作为候选框(对于640×640输入图像,RetinaFace[1]中有超过10万个锚框),还可以细分为:one-stage检测器,典型的有YOLO和SSD系 列(YOLOV1-V3[2−4],SSD[5]和RetinaNet[6]),这些都是全卷积网络直接输出目标的类别和位置坐标;two-stage检测器,典型的是R-CNN系列(Fast R-CNN[7],Faster R-CNN[8]),其模型的第一阶段输出粗糙的物体候选框(proposal),第二阶段进一步回归物体坐标和分类物体类别。最近无锚框(anchor-free)型检测器表现出非常优异的性能,不需要生成大量的候选框,降低了计算开销,模型更简单,在精度不降低的情况下,极大地提升了检测速度。无锚(anchor-free)的检测器随着网络结构(如:特征金字塔网络FPN、可形变卷积DeformConv)和损失函数(如:Focal Loss、IOU Loss)的发展逐渐焕发出新的生机。如尺度鲁棒的网络结构增强模型的表达能力、训练鲁棒的损失函数解决样本的平衡和度量问题。Anchor-free 方法以 YOLOV1-V2及 其 衍 生(FCOS[9]、ConerNet[10]、CenterNet[11]等)为代表,抛开候选框的形状先验,直接分类物体的类别和回归物体的坐标。其中CenterNet模型优于一系列最新算法,在速度和精度上都取得了优异的成绩。CenterNet是一种anchor-free型检测器,结构简单,直接检测目标的中心点和大小,并且没有非极大值抑制(non maximum suppression,NMS)。
本文基于CenterNet模型思想,主要研究: 在多任务损失中,以人脸为目标,加入面部标志点损失,把人脸检测转换为关键点估计问题,通过全卷积网络得到中心点,同时预测人脸中心点位置,人脸框和5个面部关键点; 针对边缘设备和移动设备的又快又精确的人脸检测需求,把CenterNet的主干网络ResNet18替换为轻量级的ShuffleNetV2[12]; 为了尽可能减少轻型网络降低的精度,需要对ShuffleNetV2进行改进。增大感受野,改进检测头。
1 CenterNet算法原理
先前的目标检测往往在图像上将目标用矩形框形式框出,穷举出潜在目标位置,然后对该位置进行分类,这种做法浪费时间,低效,还需要额外的后处理。CenterNet采用不同的方法,构建模型时将目标作为一个点,即目标边界框的中心点,采用关键点估计来找到中心点,并回归目标尺寸,相比较于anchor-based检测器,此模型是端到端的,更简单、更快、更精确。CenterNet类似基于锚点的one-stage方法,中心点可看成形状未知的锚点,但又有区别,分配的锚点仅仅是放在位置上,没有尺寸框,没有手动设置的阈值做前后景分类,像Faster RCNN会与GT IOU>0.7的作为前景,IOU<0.3的作为背景,其他不管。CenterNet每个目标仅仅有一个正的锚点,因此不会用非极大值抑制,只提取关键点特征图上局部峰值点。如图1所示。
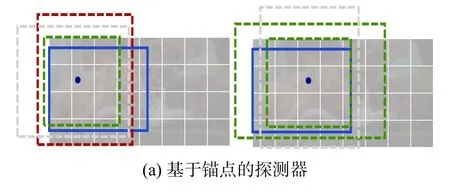

图1 提取关键点特征
多任务总损失函数为
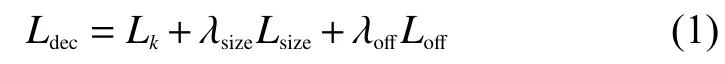
式中:Ldec为 总损失;λsize为 目标大小损失的权重;λoあ为 局部偏移损失的权重;Lsize为目标大小损失;Loあ为局部偏移损失;Lk为中心点预测损失,类型是Focal Loss交叉熵损失函数,把目标中心点当成关键点来回归,具体表示为

式中:N为图像中的关键点数量,用于将所有的Positive Focal Loss标 准化为1;α和β是超 参 数,实验中分别设置为2和4,令I∈RW×H×3为输入图像,其宽为W,高为H;∈[0,1](W/R)×(H/R)×3是生成的目标关键点热力图;R是缩放比例,取4;为检测到的关键点,表示背景;对于真实(Ground Truth,GT)的关键点C,其位置为P∈R2,计算得到低分辨率(经过下采样)上对应的关键点,再将 GT关键点通过高斯核Yxyc=分散到热力图Y∈[0,1](W/R)×(H/R)×3上,其中o'p是目标尺度自适应的标准方差。
Loff为局部偏移损失,类型为L1损失函数,作用是恢复由下采样时,GT的关键点位置数据离散后产生的误差,具体表示为
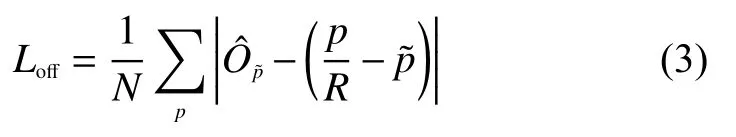
Lsize是目标大小损失,类型为L1损失函数,具体表示为
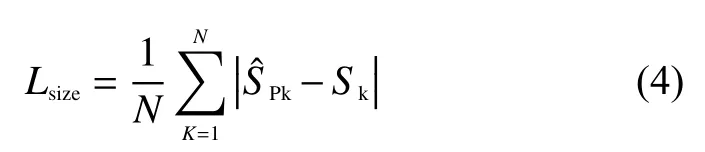
2 实现人脸检测
为了把CenterNet用于人脸检测,让模型能够部署在移动设备或者边缘设备上,要求算法模型能实现精度和速度上的平衡[13]。本文在CenterNet算法上进行了改进,修改其损失函数,增加5个面部标志点损失,以检测5个面部标志点,实现人脸检测和人脸对齐[14]。把重型主干网络resenet18替换为ShuffleNetV2,ShuffleNetV2是轻量级网络,对计算力低且存储空间小的设备更友好。最后是对ShuffleNetV2进行改进,增大感受野,提升模型性能。图2是本文模型的整体结构。

图2 模型整体结构
2.1 特征提取网络
本文采用ShuffleNetV2作为构建特征金字塔的主干网络,提取特征。由于CenterNet是采用热力图来进行回归,模型的感受野显得非常重要,而ShuffleNetV2相对于resenet18,模型更小,深度变浅,但是感受野也变小。为了使模型具有更好的性能,则需要增大感受野,把所有的3×3的深度卷积(depth-wise)卷积改为5×5的depth-wise 卷积,这样就能获得2倍的感受野,只增加了极少的计算量,如图3所示)。
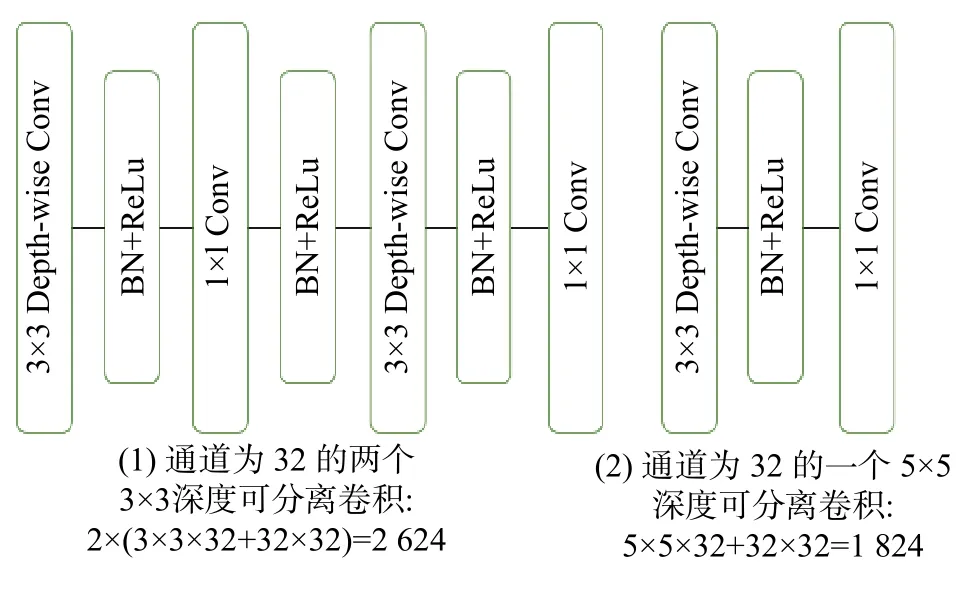
图3 不同卷积核大小的计算量
2.2 改进检测头
CenterNet的检测头使用类U-Net的上采样结构,可有效地融合低层细节信息,从而提高对小物体的检测性能。然而,CenterNet的检测头并未针对移动端进行优化,因此需要对其进行ShuffleNet化改造。首先,将检测头的所有普通3×3卷积替换为5×5的depth-wise卷积。其次,参照ShuffleNet通道压缩的技巧,将CenterNet中多层特征的残差融合改造为通道压缩的连接融合。通过大感受野和轻检测头,优化后的模型具有优异的性能。
2.3 多任务损失
参考CenterNet的多任务损失,并进行了相应的改进,使之适用于人脸检测和对齐任务。保留相关的中心点损失,目标(目标只有人脸一个类别)大小是损失和目标中心偏置损失,增加5个面部标志点损失。总损失函数为
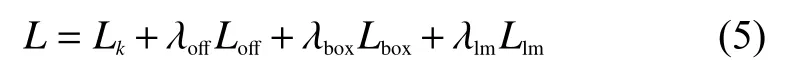
式中:Lk为人脸中心点损失;Loff为中心点偏置损失,皆与CenterNet保持一致;Lbox为人脸框大小损失,与CenterNet的Lsize略有不同,是学习人脸框大小的一种变换,具体公式表示为
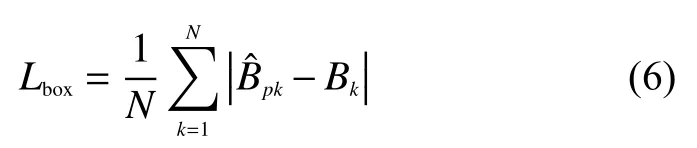
Llm是增加的面部标志点损失,与边框(Box)回归不同,5个面部标志的回归采用基于中心位置的目标归一化方法
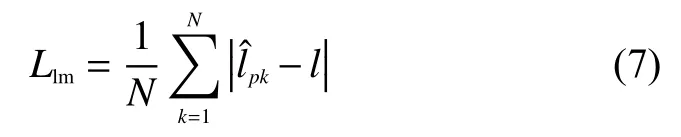
实验中设置λoff=1、λbox=0.1和λlm=0.1,使用单个网络来预测关键点、偏移量、大小和标志点,网络预测每个位置总共有15个输出,所有输出共享一个通用的全卷积骨干网络。
3 实验分析
3.1 数据集
使用公开数据集WIDER FACE[15]的训练子集来训练模型,WIDER FACE数据集由32 203张图像和393 703个面部边界框组成,在比例、姿势、表情、遮挡和照明方面具有高度的可变性。通过从61个场景类别中随机采样,将WIDER FACE数据集分为训练(40%)、验证(10%)和测试(50%)子集,验证集和测试集又分为3个难度等级,分别是 简 单(easy)、中 等(medium)和 困 难(hard)。RetinaFace引入了5个级别的面部图像质量,并注释了训练和验证子集中面部上的5个标志点(即眼中心,鼻尖和嘴角)。
3.2 数据扩充
为了提高模型的泛化能力和鲁棒性,使用原始图像的随机翻转、随机缩放、色彩抖动和随机剪裁正方形补丁来增强数据。把输入分辨率重新修订为800×800,以生成更大的训练脸。
3.3 训练参数
实验环境为python3.6,深度学习框架为pytorch1.1,GPU为NVIDIA GTX1080T@11GB,RAM为32 GB,使用Adam optimiser优化训练网络。批量大小(batch-size)为8,学习速率(learning rate)为5×10−4,持续140个epochs,学习速率分别在90和120个时期下降了10倍,总训练时常为38 h。并随机初始化网络参数。
3.4 运行效率
由于RetinaFace 模型太大,无法在单个CPU平台上运行,因此本文仅以CPU上的VGA分辨率图像来评估Faceboxes[16],MTCNN[17],CasCNN[18]和本文方法的速度效率。选择经典的评估基准FDDB来评估算法性能,AP表示平均精度值。如表1所示,本文的方法可以在CPU上以27 f/s的速度运行,并且具有最高的精度。
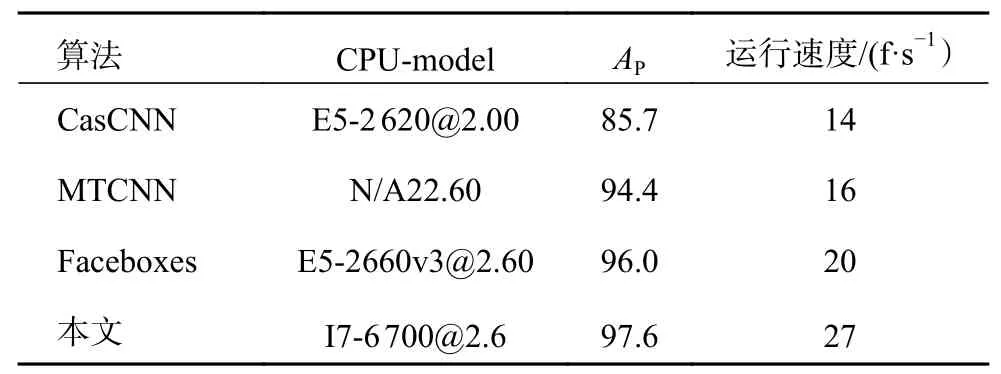
表1 CPU上的运行效率 %
3.5 在基准上评估
到目前为止,WIDER FACE是人脸检测应用最广泛的基准。所有比较的方法都在训练集上进行训练。为了在WIDER FACE上进行测试,遵循官方提供的标准做法,并采用了翻转以及多尺度策略。使用0.4的IOU阈值对预测的面部边框的集合应用边框投票。在表2列出有关验证和测试集的3个难度等级的结果。本方法具有相当高的平均精度(AP,average precision),在验证集达到94.1%(Easy)、92.3%(Medium)和88.4%(Hard)。可见本文提出的方法在精度和速度上都取得了优异的成绩。

表2 WIDER FACE验证集上的AP %
图4是在WIDER FACE的验证集上画出的准确率—召回率(PR)曲线图,其中准确率(precession,P)的计算方法为P=TP/(TP+FP),召回率(recall,R)的计算方法为R=TP/(TP+FN)。在hard子集下的PR曲线中,提出的检测模型效果远远好于其他算法。说明本文的方法在低分辨率小人脸检测上具有很大的优势。图5是对比了MTCNN、Faceboxes和本文的方法的检测示例,图中人脸较为密集且人脸小,还存在严重遮挡的情况,本文方法的检测效果明显优于其他算法。
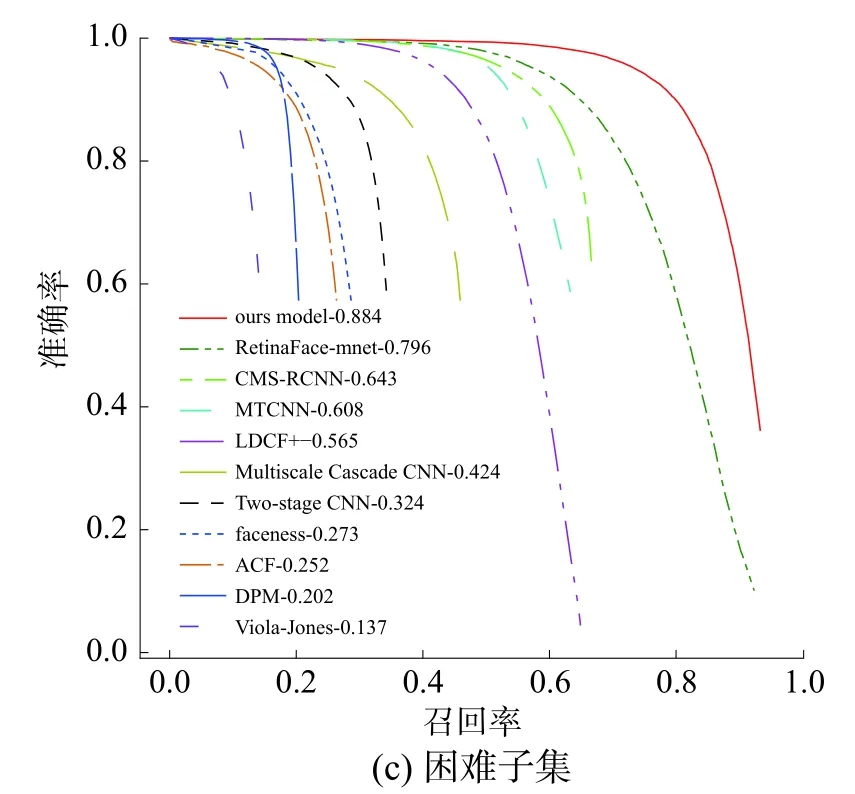
图4 在WIDER FACE验证集上的PR曲线

图5 算法检测对比示例

4 结束语
本文基于目标检测算法CenterNet,通过替换骨干网络,并修改损失函数,提出了一种能实时运行在移动设备或者边缘检测设备上的人脸检测算法,做到了检测精度和速度的平衡,可以同时预测人脸框和5个面部标志点。引入无锚检测思想,把人脸检测和对齐问题转换为关键点估计问题,直接预测人脸中心点、大小和5个界标,没有NMS后处理,克服了基于锚方法需要预先设计锚框的缺点。在具有挑战性的人脸检测基准中,此方法具有优异的性能。
猜你喜欢
计算机测量与控制(2024年2期)2024-02-29 04:22:22
中学生数理化·中考版(2022年12期)2022-02-16 07:36:56
今日农业(2021年8期)2021-11-28 05:07:50
电脑报(2020年12期)2020-06-30 19:56:42
电脑报(2019年4期)2019-09-10 07:22:44
测控技术(2018年12期)2018-11-25 09:37:20
传感器与微系统(2018年7期)2018-08-29 00:44:24
少儿美术·书法版(2016年1期)2016-02-06 00:59:39
大众摄影(2015年9期)2015-09-06 17:05:41
计算机工程与设计(2014年9期)2014-12-23 01:16:00
